Map的key是否可重复
我们都知道Map的一大特性是key唯一不可重复,可是真的是这样的吗?
我们来试验一下:

运行结果:
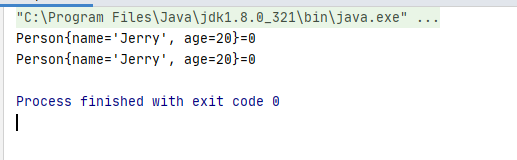
我们可以看到在map里有两个同样的person作为key,打破了map的key不可重复的特性。
我们平时操作map一般不会出现这样的结果,怎样操作会出现上述的现象呢?
1、首先有前提条件,作为key的person必须重写hashCode与equals这两个方法保证我们在改变person的属性之后,该person的hash值发生变化。
2、其次是我们在map中put一个以person对象作为key的元素,然后我们修改该person对象的某一个属性,再次把该person对象作为key值put到map中,就得到了上述结果。
为什么会出现上述的问题呢?
我们要明白map的数据结构以及数据是如何存储到map中的
JDK1.7 HashMap是数组+链表的结构
JDK8之后HashMap是数组+链表+红黑树的结构
tips:当然这里我们就不过多的讨论7与8结构的区别
我们在put一个元素的时候,(其余逻辑省略,这里只关注元素如何定位到数组的桶位置),先拿到key对象的hash值h1,h1无符号右移16位得到h2,
再把h1与h2进行异或运算得到h3,h3与数组的(length-1)进行与运算得到元素在数组上的最终位置

tips:如果数组长度较小的时候(大多数情况下map的长度不大),key产生的hash值如果高位变化较大很大,而地位变化很小时,
如果直接拿key的hash值与上(length-1)很容易产生hash冲突,所以无符号右移16位在异或低16位使得高混乱区域与低混乱区域做一个中和,提高hash高低位的一个随机性,减少hash冲突
上面我们讲述了map是如何把元素放入到数组中的,我们再回到上面的问题,第一次把person作为key放入map之后,修改了person的name属性之后,person的hash值发生变化,从而计算出的
桶位置也随之而改变(大概率会改变,不是绝对的)再次put到map中就得到两个相同key值的map。
那么在生产应用中我们要避免使用类似于person这样的对象作为key值存储在Map中,可以使用Integer、String这样一些不可变的对象来作为key就可以避免上述情况的发生。
插一句题外话,HashSet是无序不可重复的,它其实也存在上面的情况,原因很简单HashSet的底层就是HashMap
附HashSet相关代码截图

Map的key是否可重复的更多相关文章
- Java集合篇六:Map中key值不可重复的测试
package com.test.collection; import java.util.HashMap; import java.util.Map; //Map中key值不可重复的测试 publi ...
- java中key值可以重复的map:IdentityHashMap
在Java中,有一种key值可以重复的map,就是IdentityHashMap.在IdentityHashMap中,判断两个键值k1和 k2相等的条件是 k1 == k2 .在正常的Map 实现(如 ...
- java8 stream初试,map排序,list去重,统计重复元素个数,获取map的key集合和value集合
//定义一个100元素的集合,包含A-Z List<String> list = new LinkedList<>(); for (int i =0;i<100;i++) ...
- C++ map通过key获取value
c++的map中通过key获取value的方法 一般是value =map[key],或者另一种迭代器的方式 1.在map中,由key查找value时,首先要判断map中是否包含key. 2.如果不 ...
- map的key排序
java map的key排序吗 java为数据结构中的映射定义了一个接口java.util.Map,他实现了四个类,分别是:HashMap,HashTable,LinkedHashMapTreeMap ...
- 理解ThreadLocal —— 一个map的key
作用: 当工作于多线程中的对象使用ThreadLocal维护变量时,threadLocal为每个使用该变量的线程分配一个独立的变量副本. 接口方法: protected T initialValue( ...
- Java Map按键(Key)排序和按值(Value)排序
Map排序的方式有很多种,两种比较常用的方式:按键排序(sort by key), 按值排序(sort by value).1.按键排序jdk内置的java.util包下的TreeMap<K,V ...
- Android 对Map按key和value分别排序
一.理论准备 Map是键值对的集合接口,它的实现类主要包括:HashMap,TreeMap,Hashtable以及LinkedHashMap等. TreeMap:基于红黑树(Red-Black tre ...
- Java Map 按Key排序和按Value排序
Map排序的方式有很多种,这里记录下自己总结的两种比较常用的方式:按键排序(sort by key), 按值排序(sort by value). 1.按键排序 jdk内置的java.util包下的Tr ...
随机推荐
- BM 学习笔记
两个 BM 哟 1.Bostan-Mori 常系数其次线性递推. 实际上这个算法是用来计算 \([x^n]\frac {F(x)}{G(x)}\) 的... 我们考虑一个神奇的多项式:\(F(x)F( ...
- G1垃圾回收器在并发场景调优
一.序言 目前企业级主流使用的Java版本是8,垃圾回收器支持手动修改为G1,G1垃圾回收器是Java 11的默认设置,因此G1垃圾回收器可以用很长时间,现阶段垃圾回收器优化意味着针对G1垃圾回收器优 ...
- Window7环境下安装Scrapy 方法
Window7环境下安装Scrapy Scrapy在CPython(默认Python实现)和PyPy(从PyPy 5.9开始)下运行Python 2.7和Python 3.4或更高版本. 如果您使用的 ...
- Floyd算法 解决多元汇最短路问题
接下来是图论问题求解最短路问题的最后一个,求解多元汇最短路问题 我们之前一般都是问1-n的最短路径,这里我们要能随便去问i到j的最短路径: 这里介绍一下Floyd算法:我们只有一个d[maxn][ma ...
- 领域驱动模型DDD(一)——服务拆分策略
前言 领域驱动模型设计在业界也喊了几年口号了,但是对于很多"务实"的程序员来说,纸上谈"术"远比敲代码难得太多太多.本人能力有限,在拜读相关作品时既要隐忍书中晦 ...
- Linux下swap(交换分区)的增删改
swap介绍 Linux 的交换分区(swap),或者叫内存置换空间(swap space),是磁盘上的一块区域,可以是一个分区,也可以是一个文件,或者是他们的组合.交换分区的作用是,当系统物理内存吃 ...
- 面试问题之C++语言:C++中指针和引用的区别
转载于:https://blog.csdn.net/gcc2018/article/details/82285940 1.指针是一个变量,只不过这个变量存储的是一个地址,指向内存的一个存储单元:而引用 ...
- springmvc对参数接收的两个注解@RequestParam和@RequestBody
@RequestParam 作用:将请求参数绑定到控制器的方法参数上,主要用于接收几班类型参数 语法:@RequestParam(value="参数名",required=&quo ...
- MySQL 如何优化 DISTINCT?
DISTINCT 在所有列上转换为 GROUP BY,并与 ORDER BY 子句结合使用. SELECT DISTINCT t1.a FROM t1,t2 where t1.a=t2.a;
- Redis 最适合的场景?
1.会话缓存(Session Cache) 最常用的一种使用 Redis 的情景是会话缓存(session cache).用 Redis 缓存会 话比其他存储(如 Memcached)的优势在于:Re ...