Control Flow in Tensorflow TF中的控制流解析
执行器遵循了如下的执行规则(注意,某个节点的所有输入都必须包含同样的tag)
Switch(p,d) = (r1,r2)
r1 = (value(d), p || is_dead(d),tag(d))
r2 = (value(d), !p || is_dead(d),tag(d))
Merge(d1,d2) = r
r = if is_dead(d1) then d2 else d写在前面
本文翻译自Tensorflow团队的文章Tensorflow Control Flow Implementation,部分内容加入了笔者自己的理解,如有不妥之处还望各位指教。
目录
- 概览
- 控制流核心概念
- 控制流结构的编译
- 条件表达式
- while循环
- 实现
- 分布式条件表达式
- 分布式while循环
- 自动微分
概览
本文将会介绍当前在Tensorflow中控制流操作的设计和实现。这是一篇基于原始设计的描述性文档,设计的细节还请参考源代码。
本文将要讲述的内容是:
- 介绍Tensorflow为了处理控制流加入的5个核心的操作;
- 展示高层的控制流是如何通过5个基础操作融入数据流图的;
- 解释加入了控制流的数据流图是怎样被Tensorflow运行时执行的,包括融合了多种设备(CPU,GPU,TPU)的分布式执行方式;
- 描述了对控制流结构如何自动求导;
控制流核心概念
Tensorflow中控制流的基础设计理念是,通过引入少量的简单基础操作,为多样的Tensorflow应用提供丰富的控制流表达。我们期望这些操作灵活且富有表现力,能够作为高层的领域专用语言(DSL,Domain Specific Language)的编译目标。它们需要很方便的嵌入Tensorflow目前的数据流模型中,并且可以方便的进行并行的、分布式的执行以及自动求导。本节将介绍这5种控制流相关的基本操作。它们与Dennis和Arvind在数据流机(dataflow machines)中引入的控制流操作很像。使用Switch和Merge可以使我们事先条件控制,将这5种基础操作组合起来,可以使我们实现while循环。

在Tensorflow中,每一个op都会在一个执行帧(execution frame)中被执行,控制流操作负责创建和管理这些执行帧。比如,对于while循环,Tensorflow的运行时会创建一个执行帧,然后将所有属于该while循环的操作放在这个执行帧中执行。不同执行帧中的操作可以并行执行,只要它们之间没有数据依赖。
Switch:一个Switch操作根据控制输入p的布尔值,将一个输入张量d推进到某一个输出(二选一)。只有到Switch操作的两个输入都准备好之后,它才会执行。
Merge:Merge操作将它的其中一个输入推向输出。当一个Merge操作的任意一个输入准备好之后,Merge操作就会执行。在多个输入都准备好的情况下,Merge操作的输出不确定。
Enter(name):Enter操作将它的输入推向名为name的执行帧。Enter操作实际上是把一个执行帧的张量推向它的子执行帧。同一个子执行帧上可能会有多个Enter操作,它们将不同的张量推向子执行帧。当输入准备好之后,Enter操作就会执行。一个新的执行帧在它的第一个Enter操作执行之后开始执行。
Exit:Exit操作,将一个张量从一个子执行帧推向它的父执行帧。它的作用是将张量从子执行帧返回给父执行帧。一个子执行帧可能有多个Exit操作指向父执行帧,每个操作都会异步的将一个张量返回给父执行帧。当它的输入准备好之后,Exit操作开始执行。
NextIteration:NextIteration操作将一个张量从当前执行帧的一轮迭代传递到下一轮迭代。Tensorflow的运行时在执行帧内部保存了一个迭代轮数。任何一个在执行帧中执行的操作都有唯一的一个迭代轮数的属性,它可以帮助我们分辨一个迭代运算中不同的执行轮次。注意在一个执行帧中可能会有多个NextIteration操作。当执行帧的第N轮执行的第一个NextIteration操作开始执行时,Tensorflow的运行时开始执行第N+1轮的迭代。当更多的张量通过了NextIteration操作进入新的执行轮次时,新执行轮次中更多的操作就会开始运行。当输入准备完成之后,NextIteration操作开始执行。
控制流结构的编译
有了这5种基础的操作,高级的程序部件,例如条件表达式和whiile循环就可以被编译进入数据流图,然后被Tensorflow的运行时执行。下面我们来看一下条件表达式和while循环是如何在Tensorflow内部实现的。
条件表达式
以下是构建条件表达式cond(pred, fn1, fn2)的数据流图的高层伪代码。为了简化,我们忽略了实际使用中的细节,读者可以在control_flow_ops.py中找到实现细节:
//构建true分支图
context_t = CondContext(pred, branch=1)
res_t = context_t.Call(fn1)
//构建false分支图
context_t = CondContext(pred, branch=0)
res_f = context_f.Call(fn2)
//为输出添加Merge节点
merges = [Merge([f,t]) for (f,t) in zip(res_f, res_t)]
return merges
对于条件表达式的每一个分支,我们创建了一个新的控制流上下文,并且在上下文中调用了图构建的函数(fn1或者fn2)。条件上下文允许我们获取任意的外部张量(不在上下文中创建的),并且插入一个合适的Switch操作来保证它会进入一个分支。这就保证了,只有当这个分支被选择时,它对应的操作才会被执行。由于Tensorflow是异步执行的,外部的张量可能在不同的时间到达,因此我们为每一个外部张量准备了一个Switch操作来最大化并行度。
每个分支都返回了张量的列表(res_t或者res_f),因此我们又添加了一个Merge操作来对结果进行合并,这样只要任何一个分支执行成功了,就能得到输出(前面讲到,对于Merge操作,只要其中一个输入准备好了,就会产生输出)。
让我们来看一个简单的例子:
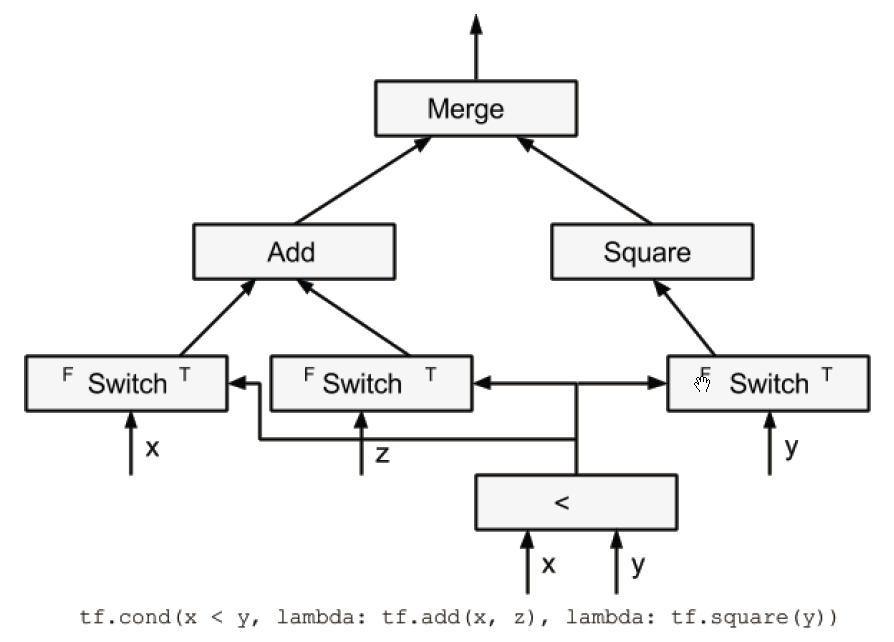
tf.cond(x<y, lambda: tf.add(x,z), lambda: tf.square(y))
在生成的数据流图中,Switch操作的插入是为了控制x,y,z张量的流动。在true/false分支,只有Switch操作的true/false的输出才会被使用。由于Add操作的输入来自Switch操作的true分支,因此只有x小于y时,Add操作才会被执行。同样的,只有x大于等于y时,Square操作才会被执行。最终Merge操作发送Add或者Square的结果。如果条件表达式有多个结果,那么将会有多个Merge操作,每个结果对应一个Merge操作。
当然,利用Switch和Merge操作实现条件表达式还有很多方法,我们选择当前的实现,主要是因为它更容易进行自动求导。
while循环
以下是构建数据流图中while循环的高层伪代码:
while_context = WhileContext()
while_context.Enter()
//为每一个循环变量添加Enter节点
enter_vars = [Enter(x, frame_name) for x in loop_vars]
//添加Merge节点,注意input[1]将会在后面被迭代
merge_vars = [Merge([x,x]) for x in enter_vars]
//构建循环条件子图
pred_result = pred(*merge_vars)
//添加Switch节点
switch_vars = [Switch(x, pred_result) for x in merge_vars]
//构建循环体子图
body_result = body(*[x[1] for x in switch_vars])
//添加NextIteration节点
next_vars = [NextIteration(x) for x in body_result]
//构建循环
for m,v in zip(merge_vars, next_vars):
m.op._update_input(1,v)
//添加Exit节点
exit_vars = [Exit(x[0]) for x in switch_vars]
while_context.Exit()
return exit_vars
整个while循环图创建在while循环的控制流上下文中。整个思路比较简单。
从循环变量开始,我们为它们分别添加一个Enter操作和一个Merge操作。我们使用它们的结果(merge_vars)来构建判断子图,从而计算循环终止条件。
在添加了Switch操作之后,我们使用Switch操作的true分支来构建循环体子图。循环体的结果需要进入下一轮迭代,因此我们添加了一个NextIteration操作,并且将其输出指向Merge操作的第二个输入,这样就形成了循环,允许我们在执行图是不断的运行同样的一组操作。
Switch操作的false输出是整个while循环的输出,因此我们在它后面加入了Exit操作,来返回运算结果。与条件表达式类似,while循环的上下文被用来追踪在pred和lambda中使用的外部张量。这些外部张量被看做是循环常数,我们自动为每一个外部张量插入了一个Enter操作,使它在while循环的上下文内部能够被访问。嵌套的循环需要添加嵌套的Enter操作。
同样的,让我们看一个简单的例子:

tf.while_loop(lambda i:i<10, lambda i: tf.add(i,1),[0])
如上图所示,我们只有一个循环变量。如果有多个循环变量,我们需要添加多个Enter,Merge,Switch,NextIteration和Exit操作。这使得跨循环和跨迭代轮次的执行成为可能。你可能注意到我们省略了常量的表示方法,如果你想要理解更深层次的细节,请查看源代码。
这种对于条件表达式和while循环的支持,使得我们可以表达任意嵌套的条件和循环。例如,一个循环体内可能嵌套着另外一个循环体。TF保证每个循环被赋予了一个唯一的帧名称。
实现
Tensorflow的运行时负责对数据流图进行执行。下面我们先来对此做一个快速的概览。
为了在多台设备上运行,TF自动将计算操作分配到不同的设备上。基于设备分配,TF自动的将数据流图划分成子图,每台设备有一个子图对应。当数据流图的一条边被图分割切段时(边两侧的节点分配在两台不同的设备上),我们自动的插入一对send和recv节点,以便在设备间传输数据。一对send和recv节点通过一个唯一的键实现通信,recv节点主动的从send节点拉取数据。例如,以下就是将原图分割到两台设备后的结果。TF对于分割没有添加任何限制,只要一个节点能够在一台设备上进行运算,就可以被分配到这台设备。
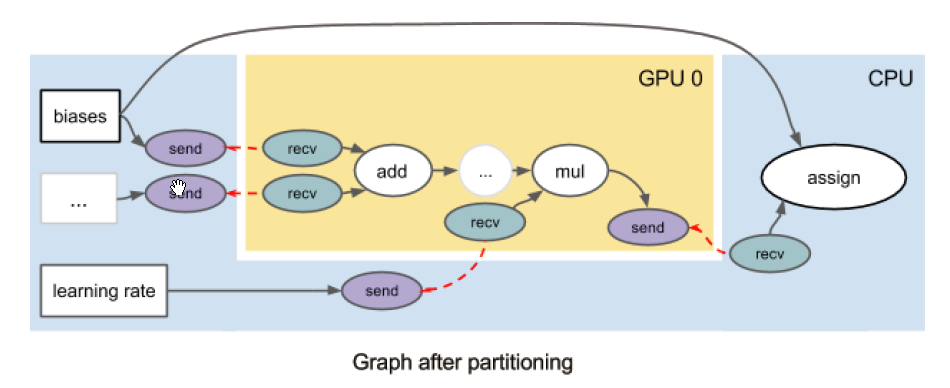
如果一个子图被分配到一个设备上运行,那么这个设备将会使用隶属于它的执行器来执行这个子图。执行器从source节点开始,依次执行已经准备好的节点。除了Merge节点之外,对于任何一个其他节点来说,只要它的输入准备好了,这个节点就可以开始执行了。注意一张子图中所有的recv节点都被认为是source节点。
如果没有控制流,图执行的过程会非常的直接:每个节点仅被执行一次,并且当所有节点都执行结束之后,整个图的执行就完成了。控制流的引入带来了一定的复杂性。有了控制流,一个节点可能被执行任意次(甚至包括0次)。执行器需要管理对于同一个节点的多个同时存在的执行实例,并且决定计算图合适执行结束。
为了追踪计算中产生的张量,执行器中的张量被使用一个形如(value, is_dead, tag)的元组来标识,value是张量值,is_dead是一个布尔值,用来标识这个张量是否在一个未执行的条件分支上,tag是这个张量的唯一标识(产生张量的节点的执行实例)。本质上,tag定义了执行的上下文,在同一个执行上下文下,一个操作最多被执行一次。tag是send/recv之间通信的键的一部分,用来辨识同一对send/recv节点的不同执行。
执行器遵循了如下的执行规则(注意,某个节点的所有输入都必须包含同样的tag)
Switch(p,d) = (r1,r2)
r1 = (value(d), p || is_dead(d),tag(d))
r2 = (value(d), !p || is_dead(d),tag(d))
Merge(d1,d2) = r
r = if is_dead(d1) then d2 else d1
Enter(d, frame_name) = r
value(r) = value(d)
is_dead(r) = is_dead(d)
tag(r) = tag(d)/frame_name/0
Exit(d) = r
value(r) = value(d)
is_dead(r) = is_dead(d)
tag(r) = tag1 where tag(d)=tag1/frame_name/n
NextIteration(d) = d1
value(d1) = value(d)
is_dead(d1) = is_dead(d)
tag(d1) = tag1/frame_name/(n+1) where tag(d) = tag1/frame_name/n
Op(d1,...,dm) = (r1,...,rn)
value(ri) = Op.Compute(value(d1),...,value(dm)) if !is_dead(ri)
is_dead(ri) = any(is_dead(d1),...,is_dead(dm)), for all i
tag(ri) = tag(d1), for all i
最后一个规则适用于所有的非控制流节点。注意只有当所有的输入都有效时,计算才会执行。如果有一个dead输入,我们将会跳过计算,而将dead信号传递下去。对于dead信号的传递将有助于支持控制流的分布式执行。
分布式条件表达式
对于分布式执行来说,一个条件表达式可能被分配到了不同的设备上,如下图所示:
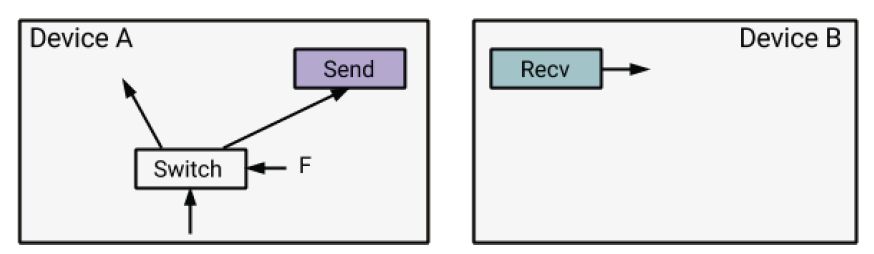
由于每一个recv节点都是source节点,并且随时可能会开始执行,在设备B上的recv节点甚至在出于未选择的条件分支上时也会执行。为了让出于未选择的分支上的recv节点的执行合理化,我们将is_dead标签通过send节点跨设备传输到recv节点。这种信息会一直跨越设备传输下去。这种简单的传输机制使得在分布式环境下的条件判断更加自然,也有助于分布式环境下的while循环。
分布式的while循环
在分布式环境下,一个while循环(特别是循环体),可能被分割到不同的设备上。如果我们简单的应用分割逻辑,然后在跨设备的节点之间插入send/recv,那么设备上的局部执行器将缺少准确执行while循环的信息。
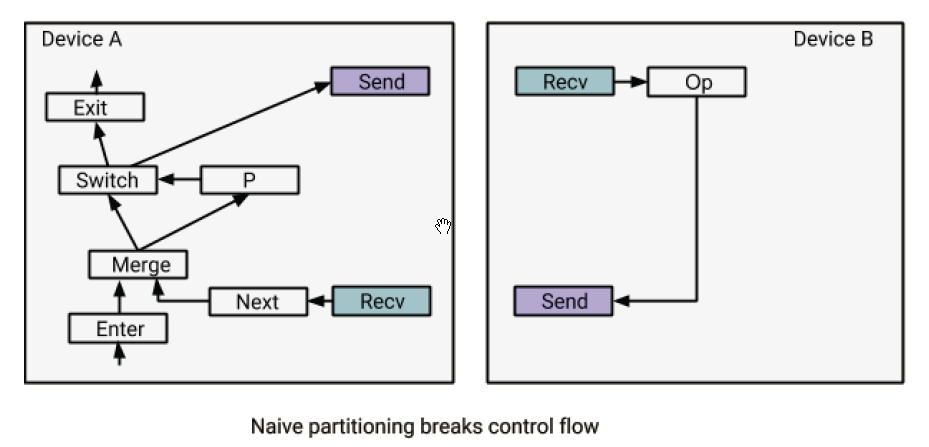
让我们通过一个例子来认识这个问题。在上述例子中,Op在循环体中,并且被分配给了设备B。一个简单的分割可能会在Switch和Op之间插入一对send/recv节点来执行跨设备的数据传输。然而,这样是无法工作的,因为设备B并不知道recv和Op操作是处在一个循环当中的,在执行完Op一次之后,设备B上的执行器就会认为,它的工作已经完成了(从设备B的角度看,它只需要从recv获取数据,执行Op,然后将结果通过send发送出去,执行就结束了)。解决方案是,重写数据流图,在while循环体分配到的每个设备上,添加一个控制循环状态机(如下图中所示)。标量0被用来作为Enter节点的输入。
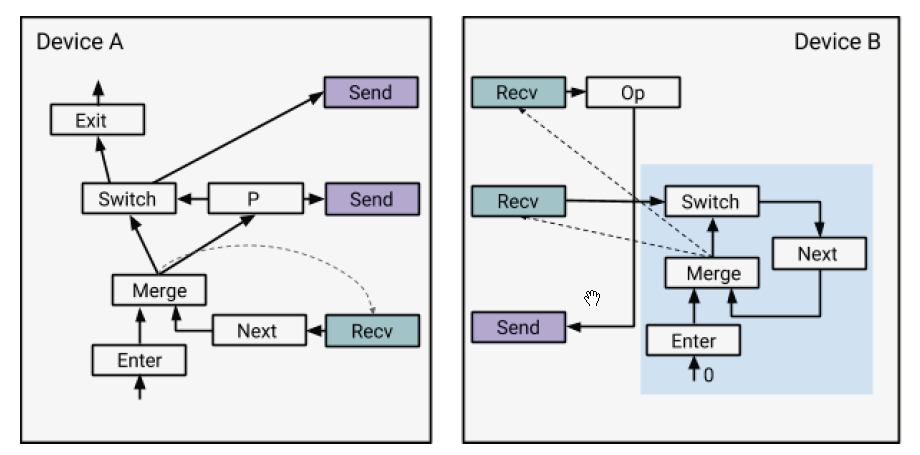
这些控制循环为设备上的执行器提供了足够的信息,使得它们可以像以前一样独立的执行,同时通过send/recv与其它设备通信。注意到图中的虚线代表了控制输入。
(具体执行过程分为0次执行,和大于等于1次执行两种情况讨论,这里就不写了,大家可以自行分析)
注意到执行中有非常多的并行执行。例如,在接收到P之后,设备B可以开始下一轮迭代,或者停止执行。一个设备可能同时存在并行的多个执行轮次,并且两个不同的设备还可以同时处在同一个循环的不同迭代轮次上。
这种while循环的分布式执行方式带来的开销是,任何一个参与的设备都必须在每一个迭代轮次里,接收来自产生P的设备传递过来的布尔张量。由于执行过程是高度并行的,这种开销可以忽略不计了。
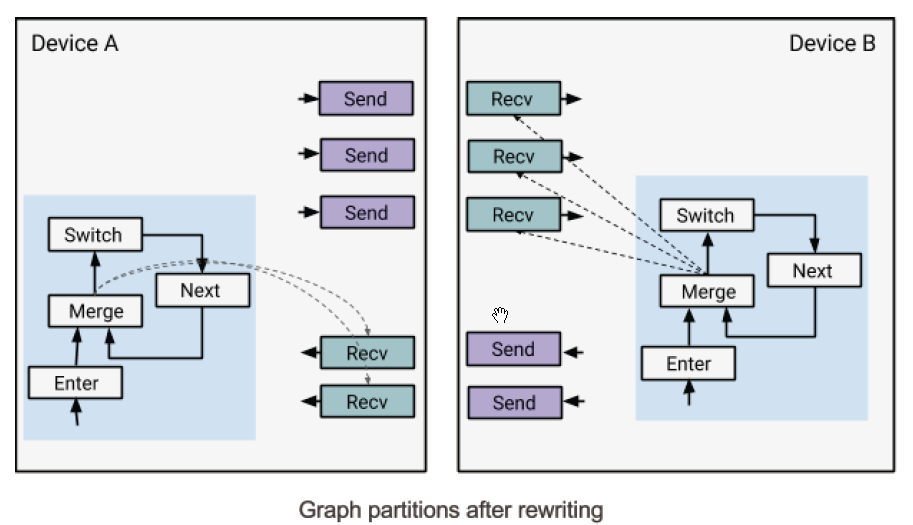
下图展示了当一个while循环被分割到不同的设备上时是什么样子。每个分割的部分都被添加了一个控制循环结构,用来控制while循环内部的recv操作。重写之后的新图与原图是语义等价的。
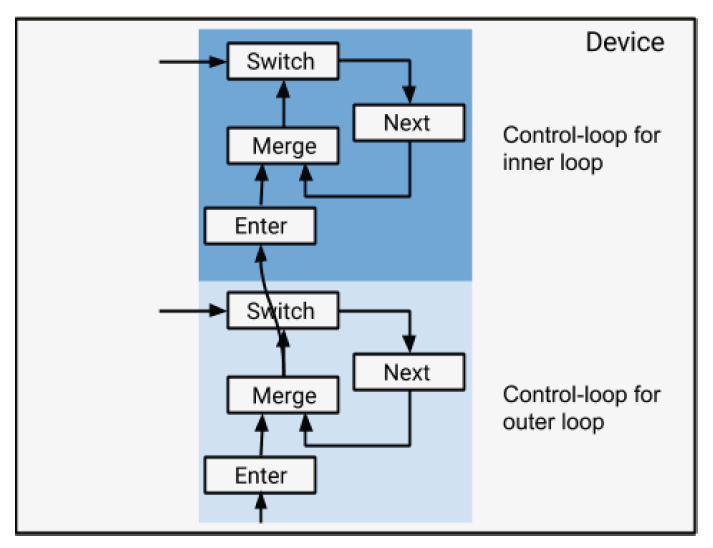
对于嵌套的while循环,我们按照下图所示的方式将控制循环堆叠起来。注意如果一台设备仅包含了外层循环的节点,我们不会在它上面添加与内层循环有关的控制循环结构。
自动微分
待补充。
Control Flow in Tensorflow TF中的控制流解析的更多相关文章
- [翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow" 目录 [翻译] TensorFlow ...
- CSAPP Chapter 8:Exception Control Flow
prcesssor在运行时,假设program counter的值为a0, a1, ... , an-1,每个ak表示相对应的instruction的地址.从ak到ak+1的变化被称为control ...
- SSIS的 Data Flow 和 Control Flow
Control Flow 和 Data Flow,是SSIS Design中主要用到的两个Tab,理解这两个Tab的作用,对设计更高效的package十分重要. 一,Control Flow 在Con ...
- Control Flow 如何处理 Error
在Package的执行过程中,如果在Data Flow中出现Error,那么Data Flow component能够将错误行输出,只需要在组件的ErrorOutput中进行简单地配置,参考<D ...
- Core Java Volume I — 3.8. Control Flow
3.8. Control FlowJava, like any programming language, supports both conditional statements and loops ...
- A swift Tour(2) Control Flow
Control Flow 用 if 和 switch 来做条件语句,并且用for-in,for,while,和do-while做循环,条件和循环的括号是可以不写的,但是body外面的括号是必须写的 l ...
- [译]Stairway to Integration Services Level 9 - Control Flow Task Errors
介绍 在本文中,我们会实验 MaximumErrorCount和ForceExecutioResult 故障容差属性,并且还要学习Control Flow task errors, event han ...
- Chapter 8: Exceptional Control Flow
概述: 我们可以用一种“流”的概念来理解处理器的工作流程,PC(Program Counter)依次为a0,a1,a2,...,an-1,这个序列可以称作control flow.当然我们并不总是按顺 ...
- TensorFlow tf.app&tf.app.flags用法介绍
TensorFlow tf.app&tf.app.flags用法介绍 TensorFlow tf.app argparse tf.app.flags 下面介绍 tf.app.flags.FL ...
随机推荐
- Solution -「Gym 102798I」Sean the Cuber
\(\mathcal{Description}\) Link. 给定两个可还原的二阶魔方,求从其中一个状态拧到另一个状态的最小步数. 数据组数 \(T\le2.5\times10^5\). ...
- Centos 7.6 使用 kubekey 部署 kubesphere v3.1.0
文章目录 主要功能 硬件要求 Kubernetes版本要求 配置主机之间的免密 安装所需依赖 下载KubeKey 创建Kubernetes集群以及KubeSphere kk命令使用方式 修改配置文件 ...
- 麦克风阵列波束形成之DSB原理与实现
语音识别有近场和远场之分,且很多场景下都会用到麦克风阵列(micphone array).所谓麦克风阵列是一组位于空间不同位置的麦克风按一定的形状规则布置形成的阵列,是对空间传播声音信号进行空间采样的 ...
- python数据结构:链表
链表与列表.数组这线性结构不同之处在于其在首末两端增删的话比较方便 单链表: 但是链表查找和删除的话都是需要从第一个开始从头查找 因此查找和删除的复杂度都为O(n) 双链表: 相比单链表来说,每个节点 ...
- Nacos2.X源码阅读总结
前言 Nacos是一个Alibaba出品的高性能微服务时代产出的组件,集注册和配置中心为一体.那么Nacos为什么这么高性能呢?总结以下几点: 1:基于阿里自研的distro协议进行Nacos把不同节 ...
- 推荐一款好用的国产web报表软件,轻松搞定复杂报表
随着经济全球化程度的逐步加深以及全球市场的加速整合以便最大程度地对企业资源进行整合,从而达到降低成本和提高效率的目的.Web报表由于借助于web平台,即运用了B/S模式,即"浏览器/服务器& ...
- 案例一:shell脚本指定日期减去一天
如果只减去一天的话,直接写就可以了. #date -d"yesterday 20150401" +%Y%m%d 如果要减去几天,还可以这样写,如果用负数是往前数, #date -d ...
- EasyUI Datagrid 数据网格 点击选中行 再次单击取消选中行
适用于jquery-easyui-1.9.15版本: 在项目中全局搜索: opts.singleSelect==true 或者在jquery.easyui.min.js中搜索: opts.single ...
- .NET 5+ 中已过时的功能
从 .NET 5 开始,一些新标记为已过时的 API 使用 ObsoleteAttribute 上的两个新属性. ObsoleteAttribute.DiagnosticId 属性指示编译器使用自定义 ...
- 不知道这10个术语,你还敢说会JavaScript?
每个行业,都有业内"行话",不了解这些行话的人,很难融入到行业中,也永远装不了逼. 从Curry到Closes,有很多JavaScript行话(该领域中使用的特殊词汇)知道这些行话 ...