【react】什么是fiber?fiber解决了什么问题?从源码角度深入了解fiber运行机制与diff执行

壹 ❀ 引
我在[react] 什么是虚拟dom?虚拟dom比操作原生dom要快吗?虚拟dom是如何转变成真实dom并渲染到页面的?一文中,介绍了虚拟dom的概念,以及react中虚拟dom的使用场景。那么按照之前的约定,本文来聊聊react中另一个非常重要的概念,也就是fiber。那么通过阅读本文,你将了解到如下几个知识点:
react在使用fiber之前为什么会出现丢帧(卡顿)?- 如何理解浏览器中的帧?
- 什么是
fiber?它解决了什么问题? fiber有哪些优势?- 了解
requestIdleCallback react中的fiber是如何运转的(fiber的两个阶段)diff源码分析(基于react 17.0.2)
同样,若文中涉及到的源码部分,我依然会使用17.0.2的版本,保证文章的结论不会过于老旧;其次,fiber的概念理解起来其实比较枯燥,但我会尽量描述的通俗易懂一点,那么本文开始。
贰 ❀ 在fiber之前
我们学习任何东西,一定会经历两个阶段,一是这个东西是什么?二是这个东西有什么用(解决了什么问题)?所以在介绍fiber之前,我们还是先说说在fiber之前react遇到了什么问题,而这个问题,我们可以通过自己手写一个简单的render来模拟react 15之前的渲染过程。
通过虚拟dom一文,我们已经知道所谓虚拟dom其实就是一个包含了dom节点类型type,以及dom属性props的对象,我们假定有如下一段dom信息,现在需要通过自定义方法render将其渲染到页面:
const vDom = {
type: "div",
props: {
id: "0",
children: [
{
type: "span",
children: 111,
},
],
},
};
其实一共就三步,创建dom,加工属性,以及递归处理子元素,直接上代码:
const render = (element, container) => {
// 创建dom节点
let dom = document.createElement(element.type);
// 添加属性
const props = Object.keys(element.props);
props.forEach((e) => {
if (e !== "children") {
dom[e] = element.props[e];
}
});
// 处理子元素
if (Array.isArray(element.props.children)) {
// 是数组,那就继续递归
element.props.children.forEach((c) => render(c, dom));
} else {
// 是文本节点就设置文本
dom.innerHTML = element.props.children;
}
// 将当前加工好的dom节点添加到父容器节点中
container.appendChild(dom);
};
render(vDom, document.getElementById("root"));
通过这段代码,你应该想到了一个问题,假设我们的dom结果非常复杂,react在递归进行渲染时一定会非常耗时;而这段代码又是同步执行,递归一旦开始就不能停止。
大家都知道浏览器是单线程,JS线程与UI线程互斥,假设这段代码运行的时间足够久,那么浏览器就必须一直等待,严重情况下浏览器还可能失去响应。
当然,react团队大佬云集,不至于说react会在渲染上严重卡顿,但在极端情况下,react在渲染大量dom节点时还是会出现丢帧问题,这个现象大家可以对比react 15(栈实现)与react引入fiber之后的渲染差异Fiber vs Stack Demo:


很显然,在引入fiber概念以及Reconcilation(diff相关)重构后,react在渲染上可以说跟德芙一样纵享丝滑了。
即便现在我们还未了解fiber,但通过了解传统的递归渲染,我们知道了同步渲染会占用线层,既然fiber能解决这个问题,我们可以猜测到fiber一定会有类似线程控制的操作,不过在介绍fiber之前,我们还是得介绍浏览器帧的概念,以及为啥react 15会有掉帧的情况,这对于后续理解fiber也会有一定的帮助,我们接着聊。
叁 ❀ 帧的概念
如何理解帧?很直观的解释可以借用动画制作工艺,传统的动画制作其实都是逐帧拍摄,动画作者需要将一个连贯的画面一张一张的画出来,然后再结合画面的高速切换以达到动画的效果,我相信不少人在读书时代应该也做过在课本每一页画画然后玩翻页动画的事情。

所以如果一个连贯动作我们用100个画面去呈现,那么你会发现这个画面看起来非常流畅,但如果我们抽帧到只有10帧,人物的动作就会显得不连贯且卡顿,这时候大家就说开启眨眼补帧模式。不过在视频混剪上,也有人还会故意用抽帧来达到王家卫电影的拖影效果,但这都是艺术表现层面的话术了。
所以回到浏览器渲染,我们其实也可以将浏览器的动画理解成一张张的图,而主流的显示器刷新率其实都是60帧/S,也就是一秒画面会高速的刷新60次,按照计算机1S等于1000ms的设定,那么一帧的预算时间其实是1000ms/60帧也就是16.66ms。
在实现动画效果时,我们有时候会使用到window.requestAnimationFrame方法,关于其解释可见requestAnimationFrame MDN:
window.requestAnimationFrame()告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。该方法需要传入一个回调函数作为参数,该回调函数会在浏览器下一次重绘之前执行。
而16.66ms也不是我们随口一说,我们可以通过一个简单的例子来验证这个结论:
<div id="some-element-you-want-to-animate"></div>
const element = document.getElementById('some-element-you-want-to-animate');
let start;
// callback接受一个由浏览器提供的,当函数开始执行的时间timestamp
function step(timestamp) {
if (start === undefined) {
start = timestamp;
}
// 计算每一帧刷新时的类增时间
const elapsed = timestamp - start;
console.log(elapsed);
//这里使用`Math.min()`确保元素刚好停在 200px 的位置。
element.style.transform = 'translateX(' + Math.min(0.1 * elapsed, 200) + 'px)';
if (elapsed < 2000) { // 在两秒后停止动画
window.requestAnimationFrame(step);
}
}
window.requestAnimationFrame(step);

大家有兴趣可以在本地运行下这个例子,可以看到当每一帧中执行step方法时,所接受的开始时间的时间差都是16.66ms。如果你的时间差要低于16.66ms,那说明你使用的电脑显示器刷新率要高于60帧/S。
我们人眼在舒适放松时可视帧数是24帧/S,也就是说1S起码得得有24帧我们才会觉得画面流程,但前文也说了,react 15之前的版本实现,渲染任务只要过长就会一直占用线程导致浏览器渲染任务推迟,如果这个渲染之间夹杂了多次推迟,浏览器1S都不够渲染60帧甚至更低,那浏览器渲染的整体帧率自然就会下降,我们在视觉上的直观感受就是掉帧了。
那么到这里,我们解释了react 15掉帧的根本原因,传统的递归调用栈的实现,在长任务面前会造成线程占用的情况,严重的话就会掉帧,react急需另一种策略来解决这个问题,接下来我们就来好好聊聊fiber。
肆 ❀ fiber是什么?
那么如何理解react中的fiber呢,两个层面来解释:
- 从运行机制上来解释,
fiber是一种流程让出机制,它能让react中的同步渲染进行中断,并将渲染的控制权让回浏览器,从而达到不阻塞浏览器渲染的目的。 - 从数据角度来解释,
fiber能细化成一种数据结构,或者一个执行单元。
我们可以结合这两点来理解,react会在跑完一个执行单元后检测自己还剩多少时间(这个所剩时间下文会解释),如果还有时间就继续运行,反之就终止任务并记录任务,同时将控制权还给浏览器,直到下次浏览器自身工作做完,又有了空闲时间,便再将控制权交给react,以此反复。
传统递归,一条路走到黑

react fiber,灵活让出控制权保证渲染与浏览器响应
而关于fiber数据结构,我在虚拟dom一文其实也简单提到过,每一个被创建的真实dom都会被包装成一个fiber节点,它具备如下结构:
const fiber = {
stateNode,// dom节点实例
child,// 当前节点所关联的子节点
sibling,// 当前节点所关联的兄弟节点
return// 当前节点所关联的父节点
}
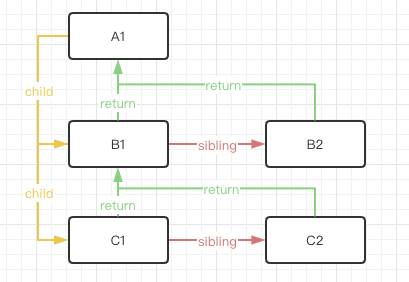
这样设计的好处就是在数据层已经在不同节点的关系给描述了出来,即便某一次任务被终止,当下次恢复任务时,这种结构也利于react恢复任务现场,知道自己接下来应该处理哪些节点。
当然,上面也抽象只是解释fiber是个什么东西,结合react的角度,综合来讲react中的fiber其实具备如下几点核心特点:
- 支持增量渲染,
fiber将react中的渲染任务拆分到每一帧。(不是一口气全部渲染完,走走停停,有时间就继续渲染,没时间就先暂停) - 支持暂停,终止以及恢复之前的渲染任务。(没渲染时间了就将控制权让回浏览器)
- 通过
fiber赋予了不同任务的优先级。(让优先级高的运行,比如事件交互响应,页面渲染等,像网络请求之类的往后排) - 支持并发处理(结合第3点理解,面对可变的一堆任务,
react始终处理最高优先级,灵活调整处理顺序,保证重要的任务都会在允许的最快时间内响应,而不是死脑筋按顺序来)
到这里,我相信大家脑中应该有了一个模糊的理解了,可能有同学就好奇了,那这个fiber是怎么做到让出控制权的呢?react又是怎么知道接下来自己可以执行的呢?那接下里,我们就不得不介绍另一个API requestIdleCallback。
伍 ❀ 关于requestIdleCallback
关于requestIdleCallback详情大家可以查看requestIdleCallback mdn介绍,这里普及下概念:
window.requestIdleCallback()方法插入一个函数,这个函数将在浏览器空闲时期被调用。这使开发者能够在主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,如动画和输入响应。
与requestAnimationFrame类似,requestIdleCallback也能接受一个callback,而这个callback又能接收一个由浏览器告知你执行剩余时间的参数IdleDeadline,我们来看个简单的例子:
const process = (deadline) => {
// 通过deadline.timeRemaining可获取剩余时间
console.log('deadline', deadline.timeRemaining());
}
window.requestIdleCallback(process);

简单点来说,这个方法其实是浏览器在有空闲时间时会自动调用,而且浏览器会告诉你剩余时间还剩多少。
因此,我们可以将一些不太重要的,或者优先级较低的事情丢在requestIdleCallback里面,然后判断有没有剩余时间,再决定要不要做。当有时间时我们可以去做需要做的事情,而我们决定不做时,控制权也会自然回到浏览器手里,毕竟浏览器也不会因为JS没事干而自己闲着。那么这个剩余时间是怎么算的呢?
通过上文我们知道,所谓掉帧就是,正常来说浏览器1S本来是可以渲染60帧,但由于线程一直被JS占着,导致浏览器响应时的时间已经不够渲染这么多次了,所以整体上1S能渲染的帧数比较低,这就是我们所谓的掉帧。而一般情况下,1帧的时间是16.66ms,那是不是表示剩余时间 = 16.66ms - (浏览器处理完自己的事情的时间) 呢?
确实是这样,但需要注意的是,在一些极端情况下,浏览器会最多给出50ms的空闲时间给我们处理想做的事情,比如我们一些任务非常耗时,浏览器知道我们会耗时,但为了让页面呈现尽可能不要太卡顿,同时又要照顾JS线程,所以它会主动将一帧的用时从16.66ms提升到50ms,也就是说此时1S浏览器至多能渲染20帧。
我们可以通过如下代码来故意造成耗时的场景,然后再来查看剩余时间:
// 用于造成耗时情况的函数
const delay = (time) => {
let now = Date.now();
// 这段逻辑会占用time时长,所以执行完它需要time时间
while (time + now > Date.now()) {};
}
// 待办事项
let work = [
() => {
console.log('任务1')
// 故意占用1S时间
delay(1000);
},
() => {
console.log('任务2')
delay(1000);
},
() => {
console.log('任务3')
},
() => {
console.log('任务4')
},
];
const process = (deadline) => {
// 通过deadline.timeRemaining可获取剩余时间
console.log('deadline', deadline.timeRemaining());
// 还有剩余时间吗?还有剩余工作吗?如果都满足,那就再做一个任务吧
if (deadline.timeRemaining() > 0 && work.length > 0) {
work.shift()();
}
// 如果还有任务,继续调用requestIdleCallback
if (work.length) {
window.requestIdleCallback(process);
}
}
window.requestIdleCallback(process);
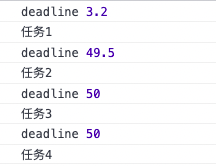
可以看到,第一个输出的剩余时间还是很少的,但第一个任务结尾处有一个耗时的逻辑,所以浏览器直接将1帧的剩余时间提到了50ms,而为什么偏偏是50ms呢,其实还是跟性能相关,如下:
| 延迟时间 | 用户感知 |
|---|---|
| 0-16ms | 非常流畅 |
| 0-100ms | 基本流畅 |
| 100-1000ms | 能感觉到有一些延迟 |
| 1000ms或更多 | 失去耐心 |
| 10000ms以上 | 拜拜,再也不来了 |
在没有办法的情况下,又要保持浏览器响应,又要尽量保证刷新看起来流程,50ms也算浏览器的一种折中方案了。
那么在了解了requestIdleCallback之后,我们知道了fiber是如何实现控制权让出的,这很重要。
但需要注意的是,react在最终实现上并未直接采用requestIdleCallback,一方面是requestIdleCallback目前还是实验中的api,兼容性不是非常好,其次考虑到剩余时间提升到50ms也就20帧左右,体验依旧不是很好。于是react通过MessageChannel + requestAnimationFrame 自己模拟实现了requestIdleCallback。
上文我们已经介绍了requestAnimationFrame会在每一帧绘制前被浏览器调用,所以react将想要做的事放在requestAnimationFrame的callback中,而callback能接受到浏览器传递过来的帧的起始时间timestamp,所以react自己动手计算帧与帧的时间差,以此判断是否超出预期时间。这部分知识我个人感觉有些超纲,大家如果自己感兴趣,可以直接搜下react 中 requestIdleCallback 的实现原理这个关键词,这里就不模拟这个实现过程了。
陆 ❀ react中的fiber是如何运转的?
fiber在渲染中每次都会经历协调Reconciliation与提交Commit两个阶段。
协调阶段:这个阶段做的事情很多,比如fiber的创建diff对比等等都在这个阶段。在对比完成之后即等待下次提交,需要注意的是这个阶段可以被暂停。
提交阶段:将协调阶段计算出来的变更一次性提交,此阶段同步进行且不可中断(优先保证渲染)。
那么接下来我将从源码角度,给大家展示下react是如何创建fiber节点,Reconciliation(diff)是如何对比,以及前文提到的剩余时间是如何运转的。
为了更好理解下面的源码,我以下面这个组件为模板:
const P = () => {
const [state, setState] = useState({ a: 1, b: 2 });
const handleState = useCallback(() => {
setState({ a: 2, b: 3 });
}, []);
return (
<div>
<span id="span1">{state.a}</span>
<span id="span2">{state.b}</span>
<button onClick={handleState}>点我</button>
</div>
);
};
陆 ❀ 壹 fiber的创建与节点关系的建立
react会在准备好虚拟dom之后再基于虚拟dom创建fiber节点,那么这里我们就来阐述fiber是如何创建,以及如何建立兄弟父级关系的。
需要注意的是,这次的源码分析我不会再从render方法开始,上面的组件P中的div有三个子元素,因为是个数组,这里我们直接关注到reconcileChildrenArray方法,如果大家也想跟这个过程,可以在本地项目启动后,然后在react-dom.development文件搜索此方法再断点,如果只是想看源码,可以直接跳转github地址,具体代码如下:
function reconcileChildrenArray(returnFiber, currentFirstChild, newChildren, lanes) {
// 删除部分逻辑
// ...
if (oldFiber === null) {
// 这里的newChildren其实就是虚拟dom节点的数据,遍历依次根据虚拟dom创建fiber阶段
for (; newIdx < newChildren.length; newIdx++) {
var _newFiber = createChild(returnFiber, newChildren[newIdx], lanes);
if (_newFiber === null) {
continue;
}
lastPlacedIndex = placeChild(_newFiber, lastPlacedIndex, newIdx);
if (previousNewFiber === null) {
resultingFirstChild = _newFiber;
} else {
// 在这里,我们建立了同层级fiber节点兄弟关系
previousNewFiber.sibling = _newFiber;
}
previousNewFiber = _newFiber;
}
// 遍历生成结束后,返回第一个child,这样父节点就知道自己的第一个孩子是谁了
return resultingFirstChild;
} // Add all children to a key map for quick lookups.
}

根据上图其实可以发现,这里的newChildren其实就是遍历到某一层级时的所有子元素的集合,然后遍历子元素依次调用createChild方法从而得到fiber节点,在下层通过previousNewFiber.sibling = _newFiber让子元素建立兄弟关系。
在方法结尾可以看到返回了resultingFirstChild(第一个子元素),目的是让父节点知道自己的第一个孩子是谁从而建立父子关系。所以到这我们就知道了兄弟关系,以及父节点的第一个子节点的关系是如何建立的。
那么如何创建的fiber呢?我们继续跟踪createChild方法:
function createChild(returnFiber, newChild, lanes) {
if (typeof newChild === 'object' && newChild !== null) {
switch (newChild.$$typeof) {
case REACT_ELEMENT_TYPE:
{
// 关注点,这里又调用了createFiberFromElement方法
var _created = createFiberFromElement(newChild, returnFiber.mode, lanes);
_created.ref = coerceRef(returnFiber, null, newChild);
// 在这里为创建出来的fiber节点绑定父节点,也就是前文说的return
_created.return = returnFiber;
return _created;
}
// 删除部分多余逻辑
}
}
在createChild中核心就两点,调用createFiberFromElement方法,顾名思义,根据element节点(虚拟element节点)来创建fiber节点。其次,在生成fiber后为通过return为其设置父节点。
我们在上个方法提到了fiber是如何建立兄弟节点(sibling字段),以及如何为父节点绑定第一个孩子(child字段)。说通俗点,站在父节点角度,我的child只用来绑定第一个子节点,而子节点自己呢都会通过return来建立与父节点的关系,所以到这里,child、sibling、return三个字段我们都解释清楚了,我们接着跟调用过程:
function createFiberFromElement(element, mode, lanes) {
var owner = null;
{
owner = element._owner;
}
// 获取虚拟dom的类型,key,props等相关信息
var type = element.type;
var key = element.key;
var pendingProps = element.props;
// 关注点在这里
var fiber = createFiberFromTypeAndProps(type, key, pendingProps, owner, mode, lanes);
{
fiber._debugSource = element._source;
fiber._debugOwner = element._owner;
}
return fiber;
}
这个方法其实也没做什么具体的事情,只是从虚拟dom上提取了元素类型,元素props相关属性,然后调用了createFiberFromTypeAndProps方法(根据type与props创建fiber):
function createFiberFromTypeAndProps(type, key, pendingProps, owner, mode, lanes) {
var fiberTag = IndeterminateComponent;
var resolvedType = type;
// 删除部分特殊预处理逻辑
// ....
// 关注点
var fiber = createFiber(fiberTag, pendingProps, key, mode);
fiber.elementType = type;
fiber.type = resolvedType;
fiber.lanes = lanes;
{
fiber._debugOwner = owner;
}
return fiber;
}
此处会根据type类型(比如是函数或者类型)做部分预处理,这里我们的虚拟dom已经能具体到div或者span,所以默认走string类型的处理,所以关注点又到了createFiber方法:
var createFiber = function (tag, pendingProps, key, mode) {
return new FiberNode(tag, pendingProps, key, mode);
};
function FiberNode(tag, pendingProps, key, mode) {
// Instance
this.tag = tag;
this.key = key;
this.elementType = null;
this.type = null;
this.stateNode = null; // Fiber
// 节点关系网初始化,兄弟节点,子节点,父节点等等。
this.return = null;
this.child = null;
this.sibling = null;
this.index = 0;
this.ref = null;
this.pendingProps = pendingProps;
this.memoizedProps = null;
this.updateQueue = null;
this.memoizedState = null;
this.dependencies = null;
this.mode = mode; // Effects
this.flags = NoFlags;
this.nextEffect = null;
this.firstEffect = null;
this.lastEffect = null;
this.lanes = NoLanes;
this.childLanes = NoLanes;
this.alternate = null;
// 时间相关初始化,用于后续剩余时间计算
{
this.actualDuration = Number.NaN;
this.actualStartTime = Number.NaN;
this.selfBaseDuration = Number.NaN;
this.treeBaseDuration = Number.NaN;
this.actualDuration = 0;
this.actualStartTime = -1;// 真正的开始时间
this.selfBaseDuration = 0;
this.treeBaseDuration = 0;
}
if (!hasBadMapPolyfill && typeof Object.preventExtensions === 'function') {
// 让fiber节点变的不可扩展,也就是永远不能再添加新的属性。
Object.preventExtensions(this);
}
}
可以看到最终来到了FiberNode构造函数,通过new调用我们得到了一个fiber实例。那么到这里,我们清晰的了解了fiber节点的创建过程,以及fiber节点的关系网是如何建立的。
事实上,react使用fiber节点的另一个原因就是为了通过这种关系网(链表),来模拟传统的js调用栈。为啥这样说呢?前文也说了传统的调用栈一旦开始就不能停止,而链表好的好处是,我即便暂停了,也能通过next提前设置好下次要恢复的节点单元,一旦浏览器有了空闲时间,我们还是能快速恢复之前的工作,而fiber与fiber之间又存在了父子兄弟的关系,上下文能很自然的再度形成,可想而知fiber节点对于恢复先前的工作具有极大的意义。
陆 ❀ 贰 diff阶段的对比过程
之前一直想将fiber和diff做两篇文章写,结果在阅读源码后发现,diff本身就是fiber协调阶段的一部分,当组件更新时在会根据现有的fiber节点与新的虚拟dom进行对比,若有不同则更新fiber节点,所以这里我就站在源码角度,来看看diff是如何进行的。
为了方便理解如下过程,这里我提前将fiber结构列出来,它其实是这样的。
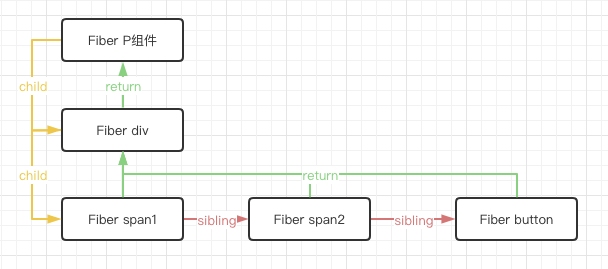
所以一开始更新的起点,其实是一个代表了组件P的fiber节点,它的child指向了我们组件内部的div。而对比过程其实也是在通过链表进行递归,递归的过程依赖了如下两个方法:
function workLoopSync() {
// Already timed out, so perform work without checking if we need to yield.
// 只要还有节点单元,一直进行对比
while (workInProgress !== null) {
performUnitOfWork(workInProgress);
}
}
function performUnitOfWork(unitOfWork) {
// 获取当前fiber节点
var current = unitOfWork.alternate;
setCurrentFiber(unitOfWork);
// 创建next节点,等会会设置next为下一个要对比的fiber节点
var next;
if ( (unitOfWork.mode & ProfileMode) !== NoMode) {
// 设置fiber节点的开始时间
startProfilerTimer(unitOfWork);
// 获取当前fiber节点的child,将其设置为next
next = beginWork$1(current, unitOfWork, subtreeRenderLanes);
stopProfilerTimerIfRunningAndRecordDelta(unitOfWork, true);
} else {
next = beginWork$1(current, unitOfWork, subtreeRenderLanes);
}
resetCurrentFiber();
unitOfWork.memoizedProps = unitOfWork.pendingProps;
if (next === null) {
// If this doesn't spawn new work, complete the current work.
completeUnitOfWork(unitOfWork);
} else {
// 将next赋予给workInProgress,于是while循环会持续进行
workInProgress = next;
}
}
在workLoopSync方法中可以看到while (workInProgress !== null)的判断,只要fiber节点不为空,就一直递归调用performUnitOfWork方法。
而在performUnitOfWork中可以看到前文我们说的链表的概念,react通过next = 当前节点child的操作,只要子节点仍存在,就不断更新next并赋予给workInProgress,所以也验证了前文所说,即便任务被暂停,react也能通过next继续先前的工作。
现在我们点击的P组件的更新按钮按钮修改状态,react会以当前组件为根节点依次向下进行重新渲染,所以此时的起点,就是上图的fiber P,我们跳过多余的递归部分,最终会来到beginWork方法的return updateFunctionComponent这一句,这里就是P组件真正开始更新的起点。
接下来,因为要重新渲染P组件,所以又会通过调用P组件得到其child,也就是虚拟dom节点信息:
var children = Component(props, secondArg);
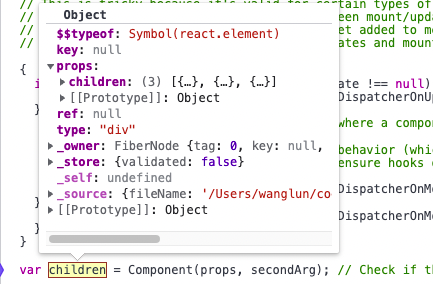
拿到了虚拟dom就可以准备开始diff对比了,这里展示下updateFunctionComponent需要关注的代码:
function updateFunctionComponent(current, workInProgress, Component, nextProps, renderLanes) {
// 删除多余的代码
var nextChildren;
{
// 获取函数组件P的子节点,也就是上面的Component(props, secondArg)
nextChildren = renderWithHooks(current, workInProgress, Component, nextProps, context, renderLanes);
if ( workInProgress.mode & StrictMode) {
try {
nextChildren = renderWithHooks(current, workInProgress, Component, nextProps, context, renderLanes);
} finally {
reenableLogs();
}
}
}
workInProgress.flags |= PerformedWork;
// 根据新的虚拟dom节点,更新旧有的fiber节点
reconcileChildren(current, workInProgress, nextChildren, renderLanes);
// 更新完当前节点后,继续递归更新child节点
return workInProgress.child;
}
紧接着我们来到reconcileChildren方法(fiber的第一个阶段,Reconciliation协调阶段):
// current -- 旧有的fiber节点信息
// workInProgress -- 也是旧有的fiber节点信息,结构与current有少许不同
// nextChildren -- 之前调用Component(props, secondArg)得到的虚拟dom子节点
function reconcileChildren(current, workInProgress, nextChildren, renderLanes) {
// 通过current我们能知道此时是初次渲染,还是更新
if (current === null) {
// 挂载fiber节点
workInProgress.child = mountChildFibers(workInProgress, null, nextChildren, renderLanes);
} else {
// diff fiber节点
workInProgress.child = reconcileChildFibers(workInProgress, current.child, nextChildren, renderLanes);
}
}
reconcileChildren做的事情很简单,就是看current(旧fiber节点)存不存在,初次渲染肯定不存在,所以会走挂载路线mountChildFibers,我们前面分析fiber的创建过程其实就是走的mountChildFibers。
由于此时我们是更新state,所以current肯定是存在的,紧接着我们将旧节点以及新的虚拟dom节点传递下去,可以看到此时的nextChildren中props已经是更新后的了:
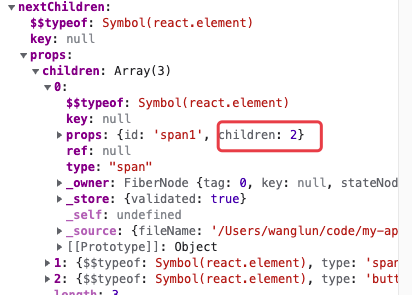
那么接下来我想大家也猜得到,肯定得根据新的虚拟dom来更新fiber节点了,我们将关注点放在reconcileChildFibers上:
// returnFiber -- 当前fiber节点的父节点,此时就是P组件
// currentFirstChild -- returnFiber节点的子节点,也就是旧的div fiber节点
// newChild -- 新的div 虚拟dom节点
function reconcileChildFibers(returnFiber, currentFirstChild, newChild, lanes) {
// 判断传递的新虚拟dom是不是对象
var isObject = typeof newChild === 'object' && newChild !== null;
if (isObject) {
switch (newChild.$$typeof) {
case REACT_ELEMENT_TYPE:
// 是对象,且是虚拟dom类型,继续调用
return placeSingleChild(reconcileSingleElement(returnFiber, currentFirstChild, newChild, lanes));
}
}
// 删除部分无用代码
if (isArray$1(newChild)) {
return reconcileChildrenArray(returnFiber, currentFirstChild, newChild, lanes);
}
}
(注意参数注解,便于你理解当前在干啥)
reconcileChildFibers方法会判断新的节点是什么类型,比如当前我们传递的是虚拟dom div,它是个对象,所以会继续调用placeSingleChild方法,根据递归的特性,等会还会对比div的props,也就是包含了2个span一个button的数组,因此下一轮会调用reconcileChildrenArray方法,这里提前打声招呼,那我们先看placeSingleChild方法:
// 参数与上个方法的参数注解相同,按值传递
function reconcileSingleElement(returnFiber, currentFirstChild, element, lanes) {
// 获取新虚拟dom的key
var key = element.key;
// 旧有的div fiber节点
var child = currentFirstChild;
// 判断旧有fiber存不存在,一定是存在才能diff,否则就是走fiber创建初始化了
while (child !== null) {
// TODO: If key === null and child.key === null, then this only applies to
// the first item in the list.
if (child.key === key) {
switch (child.tag) {
// 删除部分无用逻辑
default:
{
if (child.elementType === element.type || (
isCompatibleFamilyForHotReloading(child, element) )) {
deleteRemainingChildren(returnFiber, child.sibling);
// 根据新的虚拟dom的props来更新旧有div fiber节点
var _existing3 = useFiber(child, element.props);
// 更新完成后重新设置ref以及父节点
_existing3.ref = coerceRef(returnFiber, child, element);
_existing3.return = returnFiber;
return _existing3;
}
break;
}
}
deleteRemainingChildren(returnFiber, child);
break;
} else {
// 如果key不相等,直接在父节点上把自己整个都删掉
deleteChild(returnFiber, child);
}
child = child.sibling;
}
// 如果不存在旧的fiber节点,那说明是挂载,因此否则走fiber的初始化
// 这里的初始化我删掉了
}
placeSingleChild其实就是diff了,大家可以看看我添加的注释,这里我简单描述这个过程:
- 判断是否存在旧有的
fiber节点,如果不存在说明没必要diff,直接走fiber新建挂载逻辑。 - 有
child说明有旧有fiber,那就对比key,如果不相等,直接运行deleteChild(returnFiber, child),也就是从div节点的旧有父节点上,将整个div都删除掉,div的子节点都不需要比了,这也验证了react的逐级比较,父不同,子一律都不比较视为不同。 - 若
key相同,那就比较新旧fiber的type(标签类型),如果type不相同,跟key不相同一样,调用了deleteRemainingChildren(returnFiber, child)方法,直接从div的旧有父节点上将自己整个删除。 - 若
key type都相同,那只能说明是props变了,因此调用var _existing3 = useFiber(child, element.props)方法,根据新的props来更新旧有的div fiber节点。
我们将关注点放到useFiber上,代码如下:
function useFiber(fiber, pendingProps) {
// 使用旧有的fiber节点以及新的props来创建一个新的clone fiber
var clone = createWorkInProgress(fiber, pendingProps);
clone.index = 0;
clone.sibling = null;
return clone;
}
做的事情很清晰,使用旧有的fiber div节点以及新的虚拟dom div的props创建了一个全新的div fiber,创建过程的代码跟前面fiber一样,这里就不展示了。
创建完成之后返回,然后为新的fiber设置ref,父节点等相关信息,那么到这里div这个fiber就更新完成了。代码会一层层返回,直到updateFunctionComponent的return workInProgress.child这一句,一直返回到next的赋值。啥意思呢?
前面的对比,其实是站在fiber P的角度把fiber div更新完了,而fiber div还有自己的孩子呢,所以接下来又以div为父节点依次更新它的三个子节点,还记得前文我们提前打的招呼吗?接下来它就会执行下面这段:
// 可在本文搜索代码,回顾上文剧情
if (isArray$1(newChild)) {
return reconcileChildrenArray(returnFiber, currentFirstChild, newChild, lanes);
}
reconcileChildrenArray方法在fiber创建阶段已经给大家分析了部分源码,当时执行的逻辑是if (oldFiber === null),因为不存在旧有fiber,所以直接重新创建,而此时因为咱们有,所以就不是重新创建,而是执行下面这段代码:
function reconcileChildrenArray(returnFiber, currentFirstChild, newChildren, lanes) {
// for循环,依次更新两个span以及button
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
if (oldFiber.index > newIdx) {
nextOldFiber = oldFiber;
oldFiber = null;
} else {
// 建立兄弟关系
nextOldFiber = oldFiber.sibling;
}
// 调用updateSlot,使用新的props来更新旧有fiber节点
var newFiber = updateSlot(returnFiber, oldFiber, newChildren[newIdx], lanes);
// 删除多余代码....
}
而updateSlot又是一次diff,源码如下:
// returnFiber -- 当前节点的父级,此时是div
// oldFiber -- 旧span1节点
// newChild -- 新的span1的虚拟dom
function updateSlot(returnFiber, oldFiber, newChild, lanes) {
// 获取旧有fiber的key
var key = oldFiber !== null ? oldFiber.key : null;
if (typeof newChild === 'object' && newChild !== null) {
switch (newChild.$$typeof) {
// 是react node类型吗?
case REACT_ELEMENT_TYPE:
{
// 判断旧fiber与信虚拟dom的key
if (newChild.key === key) {
// 判断是不是fragment节点
if (newChild.type === REACT_FRAGMENT_TYPE) {
return updateFragment(returnFiber, oldFiber, newChild.props.children, lanes, key);
}
// 利用新的虚拟dom来更新旧fiber span
return updateElement(returnFiber, oldFiber, newChild, lanes);
} else {
return null;
}
}
// 删除部分无用代码
}
}
return null;
}
这一段逻辑与之前div的对比大同小异,同样是对比type与key,因为都相等,所以我们来到了updateElement方法,顾名思义,根据新虚拟dom的属性来更新旧fiber节点:
function updateElement(returnFiber, current, element, lanes) {
// 有旧fiber就单纯的更新
if (current !== null) {
if (current.elementType === element.type || ( // Keep this check inline so it only runs on the false path:
isCompatibleFamilyForHotReloading(current, element) )) {
// 与前面更新div的逻辑一模一样
var existing = useFiber(current, element.props);
existing.ref = coerceRef(returnFiber, current, element);
existing.return = returnFiber;
{
existing._debugSource = element._source;
existing._debugOwner = element._owner;
}
return existing;
}
}
// 没有就重新创建
var created = createFiberFromElement(element, returnFiber.mode, lanes);
created.ref = coerceRef(returnFiber, current, element);
created.return = returnFiber;
return created;
}
updateElement做的事情很简单,判断存不存在旧fiber节点,存在就同样调用useFiber,以旧fiber clone一个新fiber出来,没有就重新创建。
不知道大家发现没,react虽然明确做了很多的条件判断,即便如此,依旧会在某个地方底层内部再做一次兜底的处理,所以代码看着挺多,其实大部分是为了逻辑的健壮性。
之后做的事情相比大家也清晰了,更新span2以及button,以及考虑span1 span2 button有没有child,很明显他们都没有,于是代码最终又来到了workLoopSync,可见此时已经没有可执行的任务单元了,于是协调阶段完整结束。

由于协调阶段结束,紧接着来到commit阶段,我们直接关注到performSyncWorkOnRoot方法:
function performSyncWorkOnRoot(root){
// 删除意义不大的代码
var finishedWork = root.current.alternate;
root.finishedWork = finishedWork;
root.finishedLanes = lanes;
// 提交root节点
commitRoot(root); // Before exiting, make sure there's a callback scheduled for the next
// pending level.
ensureRootIsScheduled(root, now());
return null;
}
我们再关注到commitRoot方法,这里会对当前任务进行优先级判断,再决定后续处理:
function commitRoot(root) {
// 断点发现这里的优先级是99,最高优先级
var renderPriorityLevel = getCurrentPriorityLevel();
runWithPriority$1(ImmediatePriority$1, commitRootImpl.bind(null, root, renderPriorityLevel));
return null;
}
由于是优先级最高的render,因此后续react会在浏览器允许的情况下将最终创建的真实dom重新更新到页面,这里我就不再展示代码过程了。
柒 ❀ 总结
那么到这里,我们阐述了react 15以及之前的大量dom渲染时卡顿的原因,从而介绍了帧的概念。
紧接着我们引出了fiber,那么什么是fiber呢?往小了说它就是一种数据结构,包含了任务开始时间,节点关系信息(return,child这些),我们把视角往上抬一点,我们也可以说fiber是一种模拟调用栈的特殊链表,目的是为了解决传统调用栈无法暂停的问题。
而站在宏观角度fiber又是一种调度让出机制,它让react达到了增量渲染的目的,在保证帧数流畅的同时,fiber总是在浏览器有剩余时间的情况下去完成目前目前最高优先级的任务。
所以如果让我来提炼fiber的关键词,我大概给出如下几点:
fiber是一种数据结构。fiber使用父子关系以及next的妙用,以链表形式模拟了传统调用栈。fiber是一种调度让出机制,只在有剩余时间的情况下运行。fiber实现了增量渲染,在浏览器允许的情况下一点点拼凑出最终渲染效果。fiber实现了并发,为任务赋予不同优先级,保证了一有时间总是做最高优先级的事,而不是先来先占位死板的去执行。fiber有协调与提交两个阶段,协调包含了fiber创建与diff更新,此过程可暂停。而提交必须同步执行,保证渲染不卡顿。
而通过fiber的协调阶段,我们了解了diff的对比过程,如果将fiber的结构理解成一棵树,那么这个过程本质上还是深度遍历,其顺序为父---父的第一个孩子---孩子的每一个兄弟。
通过源码,我们了解到react的diff是同层比较,最先比较key,如果key不相同,那么不用比较剩余节点直接删除,这也强调了key的重要性,其次会比较元素的type以及props。而且这个比较过程其实是拿旧的fiber与新的虚拟dom在比,而不是fiber与fiber或者虚拟dom与虚拟dom比较,其实也不难理解,如果key与type都相同,那说明这个fiber只用做简单的替换,而不是完整重新创建,站在性能角度这确实更有优势。
最后,附上fiber更新调度的执行过程:
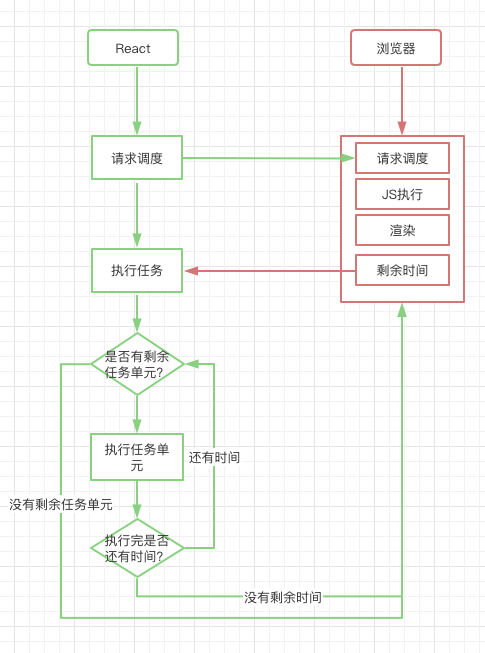
那么到这里,本文结束。
捌 ❀ 参考
这可能是最通俗的 React Fiber(时间分片) 打开方式
【react】什么是fiber?fiber解决了什么问题?从源码角度深入了解fiber运行机制与diff执行的更多相关文章
- 解决eclipse为什么不能查看源码
Java eclipse中查看源代码ctrl+左键单击 一.你是第一次使用该功能,没有导入项目源码,故无法查看源码 解决方法: 1.点 “window“-> “Preferences”-> ...
- MyEclipse中android 项目如何解决第三方jar无法关联源码的问题( The JAR of this class file belongs to container 'Android Private Libraries' which does not allow modifications to source attachments on its entries.)
若我们要为第三方jar(android-support-v4.jar)关联源码通常的做法是 右键项目 单击菜单Properties 单击菜单 Java Build Path 单击 Libraries ...
- android翻译应用、地图轨迹、视频广告、React Native知乎日报、网络请求框架等源码
Android精选源码 android实现高德地图轨迹效果源码 使用React Native(Android和iOS)实现的 知乎日报效果源码 一款整合百度翻译api跟有道翻译api的翻译君 RxEa ...
- 建议收藏!利用Spring解决循环依赖,深入源码给你讲明白!
前置知识 只有单例模式下的bean会通过三级缓存提前暴露来解决循环依赖的问题.而非单例的bean每次获取都会重新创建,并不会放入三级缓存,所以多实例的bean循环依赖问题不能解决. 首先需要明白处于各 ...
- 〖Windows〗Linux的Qt程序源码转换至Windows平台运行,编码的解决
在中国大陆,Windows默认的编码是gb2312,而Linux是UTF8: 多数情况下,把Linux上的程序转换至Windows上运行需要进行编码转换才能正常显示: 而其实大可以不必的,同样,文件使 ...
- 解决 Ubuntu16.04 + opencv4.1 源码编译错误 Makefile:160: recipe for target 'all' failed
最近源码编译 opencv,出现下面的错误 [ %] Built target opencv_dnn Makefile:: recipe for target 'all' failed google ...
- 从源码角度解析Netty的React模式是如何工作的
Netty 支持多种实现方式,比如nio,epoll 等,本文以nio的实现方式进行讲解. 1.EventLoop : 事件循环看,简单来说就是一个死循环监听事件,如果事件来了,处理掉.通常做法就是开 ...
- React key究竟有什么作用?深入源码不背概念,五个问题刷新你对于key的认知
壹 ❀ 引 我在[react]什么是fiber?fiber解决了什么问题?从源码角度深入了解fiber运行机制与diff执行一文中介绍了react对于fiber处理的协调与提交两个阶段,而在介绍协调时 ...
- React Fiber源码分析 (介绍)
写了分析源码的文章后, 总觉得缺少了什么, 在这里补一个整体的总结,输出个人的理解~ 文章的系列标题为Fiber源码分析, 那么什么是Fiber,官方给出的解释是: React Fiber是对核心算法 ...
随机推荐
- XCTF练习题---MISC---Janos-the-Ripper
XCTF练习题---MISC---János-the-Ripper flag:flag{ev3n::y0u::bru7us?!} 解题步骤: 1.观察题目,下载附件 2.发现是压缩包,进行解压,是一个 ...
- 前后端分离,简单JWT登录详解
前后端分离,简单JWT登录详解 目录 前后端分离,简单JWT登录详解 JWT登录流程 1. 用户认证处理 2. 前端登录 3. 前端请求处理 4. 后端请求处理 5. 前端页面跳转处理 6. 退出登录 ...
- 完全卸载nginx的详细步骤
一个执着于技术的公众号 前言 在开局配置Nginx时有可能会配置错误,报各种错误代码.看不懂或者懒得去看这个报错时,其实最简单的方式是卸载并重装咯.今天就带大家一起学习下,如何彻底卸载nginx程序. ...
- 记将一个大型客户端应用项目迁移到 dotnet 6 的经验和决策
在经过了两年的准备,以及迁移了几个应用项目积累了让我有信心的经验之后,我最近在开始将团队里面最大的一个项目,从 .NET Framework 4.5 迁移到 .NET 6 上.这是一个从 2016 时 ...
- 如何彻底禁止 macOS Monterey 自动更新,去除更新标记和通知
请访问原文链接:如何彻底禁止 macOS Monterey 自动更新,去除更新标记和通知,查看最新版.原创作品,转载请保留出处. 作者主页:www.sysin.org 随着 macOS Montere ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- 【mq】从零开始实现 mq-09-消费者拉取消息 pull message
前景回顾 [mq]从零开始实现 mq-01-生产者.消费者启动 [mq]从零开始实现 mq-02-如何实现生产者调用消费者? [mq]从零开始实现 mq-03-引入 broker 中间人 [mq]从零 ...
- ReentrantLock可重入、可打断、Condition原理剖析
本文紧接上文的AQS源码,如果对于ReentrantLock没有基础可以先阅读我的上一篇文章学习ReentrantLock的源码 ReentrantLock锁重入原理 重入加锁其实就是将AQS的sta ...
- FinClip 前端之 VUE 核心原理总结
小程序框架有很多,都是支持前端JavaScript语言的,也是支持 vue.js 框架的.FinClip 小程序是兼容各家平台的.所以在学习了框架使用之后的进阶就要熟悉框架的底层原理. 1.数据响应式 ...
- arts-week13
Algorithm 992. Sort Array By Parity II - LeetCode Review https://tls.ulfheim.net/ HTTP协议图解 Tip linux ...