单链表上的一系列操作(基于c语言)
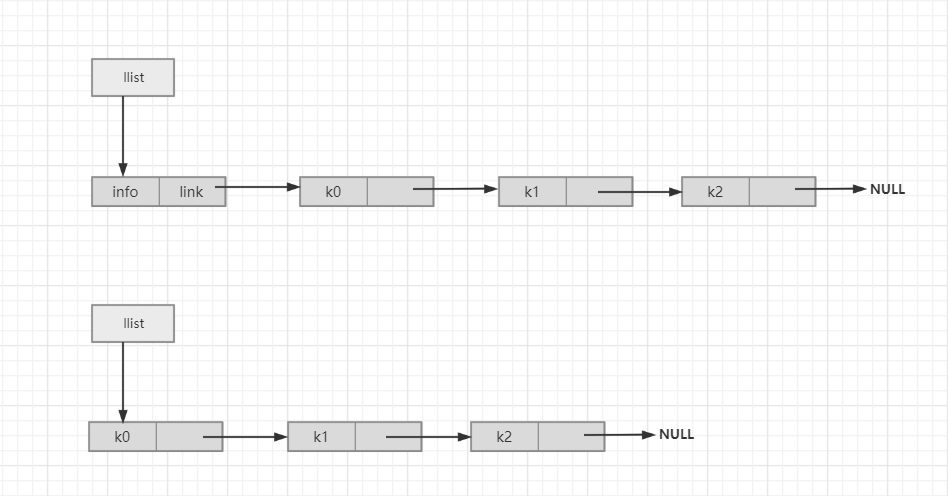
单链表的实现分为两种单链表(其实差别并不是很大):带头结点和不带头结点,分别对应下面图中的上下两种。
链表的每一个结点是由两个域组成:数据域和指针域,分别存放所含数据和下一个结点的地址(这都是很明白的东西)
图中的东西可以分为三种:头指针llist;头节点info;正常的节点ki
下面定义结点的类型和单链表的类型:
struct Node;
typedef struct Node * PNode;
struct Node{
DataType info;
PNode link;
};
typedef struct Node * LinkList;
//很明显我们定义的结点指针类型和单链表的类型实际上是一样的东西
//后续的代码暂时与书上的内容保持一致,均使用有头结点的链表
//总结过后再将不带头结点的单链表实现补上
创建一个空链表:
LinkList creatNullList_link(void){
LinkList llist = (LinkList)malloc(sizeof(struct Node)); //创建一个指向Node类型的指针llist
if(llist != NULL) llist->link = NULL; //将其指向为空,也就是链表末尾
else printf("OUTOFSPACE!");
return llist; //看上面的代码后可知,llist可能为空,所以后面其他的函数经常会先判断了llist的情况
}
是否是空链表:
int isNullList_link(LinkList llist){
return (llist->link == NULL);
}
//判断链表是否为空的代码比较简单
在链表中求第一个值为x的结点的存储位置:
PNode locate_link(LinkList llist,DataType x){
PNode p;
if (llist == NULL) return NULL;
p = llist->link;
while(p != NULL && p->info != x) p = p->link;
return p;
}
//为什么要判断llist是否为空而不是判断llist->link是否为空?
//如果llist为空,那使用llist->link不就是对一个空指针操作了吗,记得学指针的时候书上的一句话嘛,千万不要用没有初始化的指针,这里如果其指向为空,那llist->link也就不知道指向哪里
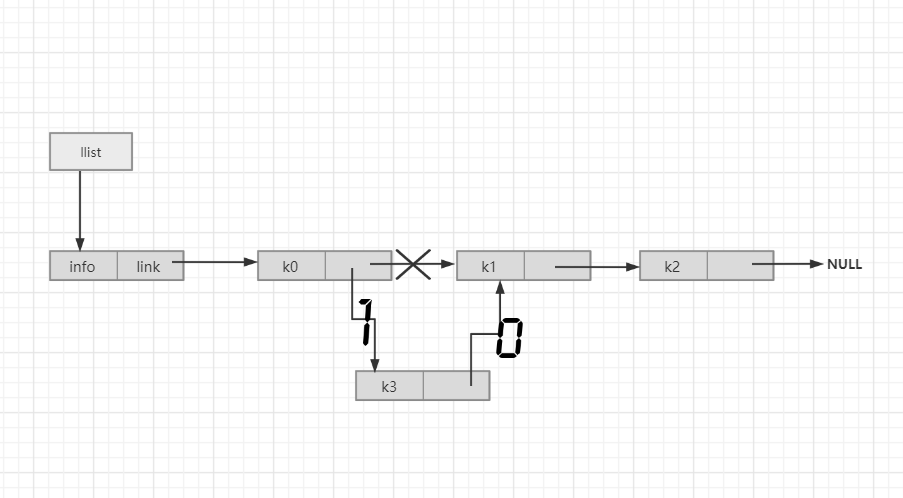
在p结点的后面插入一个值为x的新结点,返回是否插入成功的标志:
int insertPost_link(LinkList llist,PNode p,DataType x){
PNode q = (PNode)malloc(sizeof(struct Node));
if (q == NULL){
printf("OUTOFSPACE");
return 0;
}
q->info = x;
q->link = p->link;
p->link = q;
return 1;
}//下图为操作顺序,操作顺序不能反
//这一个方法是不需要用到llist
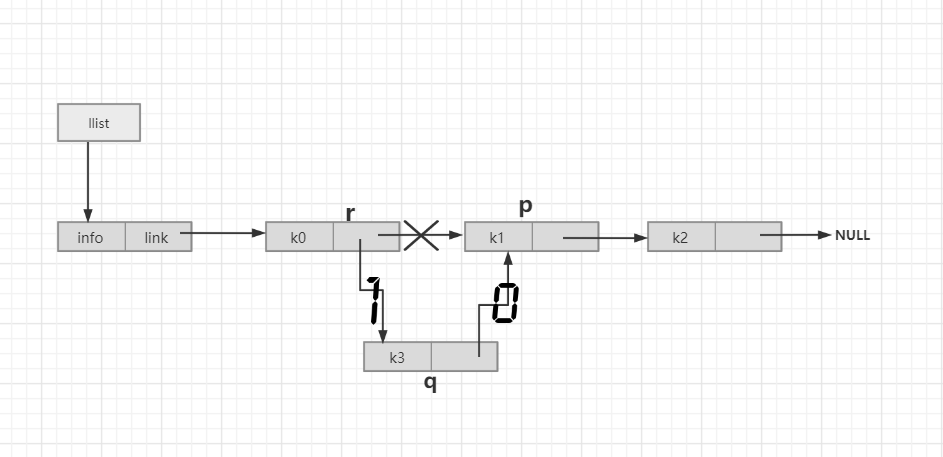
在p结点的前面插入值为x的新结点,返回插入成功与否的标志:
int insertPre_link(LinkList llist,PNode p,DataType x){
PNode r;
PNode q = (PNode)malloc(sizeof(struct Node));
if(q == NUll){
printf("OUTOFSPACE");
return 0;
}
r = locatePre_link(llist,p);
q->info = x;
q->link = r->link;
r->link = q;
reutrn 1;
}
//找p结点的前驱结点
PNode locatePre_link(LinkList llist,PNode p){
PNode p1;
if (llist == NULL) return NULL;
p1 = llist;
while(p1->link!=NULL && p1->link==p){
p1 = p1->link;
}
reutn p1;
}
//感觉这个难一点的就是前驱结点的查找,p1->link!=NULL && p1->link == p是这个找前驱结点的灵魂
删除第一个元素内容为x的结点,返回删除成功与否的标志:
int deleteV_link(LinkList llist,DataType x){
//不展示的方法:前面有一个定位方法,找到元素x的结点p,然后前面还有一个找前驱结点的方法,然后就可以执行删除操作了
//下面是书上的方法
PNode q,p;
p = llist;
if (p == NULL) return 0;
while(p->link!=NULL && p->link->info==x) p = p->link;
//p是要删除结点的前驱结点
if (p->link == NULL){
printf("NOT EXIST!");
return 0;
}
else{
q = p->link;
p->link = q->link;
//也可以是p->link = p->link->link
free(q);
return 1;
}
}
目前这基本上是书本上的代码示例了,后续会补充未给出的思考题,并且给出没有头结点时上述函数方法。
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
- 添加到短语集
- 没有此单词集:中文(简体) -> 英语...
- 创建新的单词集...
- 没有此单词集:中文(简体) -> 英语...
- 拷贝
单链表上的一系列操作(基于c语言)的更多相关文章
- C++学习---单链表的构建及操作
#include <iostream> using namespace std; typedef struct LinkNode { int elem;//节点中的数据 struct Li ...
- C++单链表的创建与操作
链表是一种动态数据结构,他的特点是用一组任意的存储单元(可以是连续的,也可以是不连续的)存放数据元素.链表中每一个元素成为“结点”,每一个结点都是由数据域和指针域组成的,每个结点中的指针域指向下一个结 ...
- 单链表的插入删除操作(c++实现)
下列代码实现的是单链表的按序插入.链表元素的删除.链表的输出 // mylink.h 代码 #ifndef MYLINK_H #define MYLINK_H #include<iostream ...
- 循环单链表定义初始化及创建(C语言)
#include <stdio.h> #include <stdlib.h> /** * 含头节点循环单链表定义,初始化 及创建 */ #define OK 1; #defin ...
- c++学习之单链表以及常用的操作
新学数据结构,上我写的代码. #include <iostream> #include <cstdlib> using namespace std; typedef int E ...
- 单链表无head各种操作及操作实验
#encoding=utf-8 class ListNode: def __init__(self,x): self.val=x; self.next=None; #链表逆序 def revers ...
- C++ 单链表操作总结
第一.单链表的定义和操作 #include <iostream> using namespace std; template <typename T> struct Node ...
- 数据结构(一) 单链表的实现-JAVA
数据结构还是很重要的,就算不是那种很牛逼的,但起码得知道基础的东西,这一系列就算是复习一下以前学过的数据结构和填补自己在这一块的知识的空缺.加油.珍惜校园中自由学习的时光.按照链表.栈.队列.排序.数 ...
- C++ "链链"不忘@必有回响之单链表
1. 前言 数组和链表是数据结构的基石,是逻辑上可描述.物理结构真实存在的具体数据结构.其它的数据结构往往在此基础上赋予不同的数据操作语义,如栈先进后出,队列先进先出-- 数组中的所有数据存储在一片连 ...
随机推荐
- numpy 知识汇总
1.增加维度 高纬度打印出来很不好观察,所以打印出来shape更加容易理解维度的增加, 此外一维向量a=np.array([1,2,3]), a[:,None],相当于变为二维并转置了shape=(3 ...
- 关于 BSGS 以及 ExBSGS 算法的理解
BSGS 引入 求解关于\(X\)的方程, \[A^X\equiv B \pmod P \] 其中\(Gcd(A,P)=1\) 求解 我们令\(X=i*\sqrt{P}-j\),其中\(0<=i ...
- 分享刚出炉的基于Blazor技术的Web应用开发框架
这是最近刚刚重构完成的项目,有点迫不及待的分享给大家,为了跟上技术升级把原来基于MVC Razor Page开源项目 RazorPageCleanArchitecture 进行重构, 前端用Blazo ...
- 3.k8s核心概念
k8s的核心概念 一. Pod pod,中文翻译过来叫豆荚,如下图.我们都知道豆荚,一个豆荚里面有很多豆子.豆荚就可以理解为pod,一个个的豆子就可以理解为容器.pod和容器的关系是一个pod里面可以 ...
- Solution -「POI 2014」「洛谷 P5904」HOT-Hotels 加强版
\(\mathcal{Description}\) Link. 给定一棵 \(n\) 个点的树,求无序三元组 \((u,v,w)\) 的个数,满足其中任意两点树上距离相等. \(n\le1 ...
- [LeetCode]3.无重复字符的最长子串(Java)
原题地址: longest-substring-without-repeating-characters/submissions 题目描述: 示例 1: 输入: s = "pwwkew&qu ...
- 暑假撸系统6- Thymeleaf ajax交互!
本来用Thymeleaf也没想着深度使用ajax,就是用也是非常传统的ajax方式提交然后js控制修改下变量.闲来无事的时候看Thymeleaf的教程发现一哥们的实现方式,以及实现思路,堪称惊奇,先说 ...
- Aluminum: An Asynchronous, GPU-Aware Communication Library Optimized for Large-Scale Training of Deep Neural Networks on HPC Systems
本文发表在MLHPC 2018上,主要介绍了一个名为Aluminum通信库,这个库针对Allreduce做了一些关于计算通信重叠以及针对延迟的优化,以加速分布式深度学习训练过程. 分布式训练的通信需求 ...
- 实际项目中使用CompletionService提升系统性能的一次实践
随着互联网应用的深入,很多传统行业也都需要接入到互联网.我们公司也是这样,保险核心需要和很多保险中介对接,比如阿里.京东等等.这些公司对于接口服务的性能有些比较高的要求,传统的核心无法满足要求,所以信 ...
- 使用IDEA新建一个Spring Boot项目
本文使用Spring Initializer来创建 开发环境 操作系统:Windows 10 IDEA:2020.3.2 JDK:1.8 1. 启动IDEA,选择New Project(新建工程): ...