学习HashMap源码
HashMap简介
HashMap是一种存储K-V类型的容器,HashMap底层数据结构为数组+链表+红黑树(jdk 1.8新增),它根据键的HashCode值存储数据,获取元素的时间复杂度为O(1)。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致,在多线程环境下请使用ConcurrentHashMap。
成员变量
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
// 默认初始化容量大小为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的负载因子为0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当链表长度达到8时转换成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 链表长度变为6时红黑树转为链表
static final int UNTREEIFY_THRESHOLD = 6;
// Node类型的table数组
transient Node<K,V>[] table;
// 红黑树时数组最小长度为64
static final int MIN_TREEIFY_CAPACITY = 64;
// 负载因子
final float loadFactor;
}
Get方法
- 计算 key 的 hash 值,根据 hash 值找到对应数组下标: hash & (length-1)
- 判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步
- 判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步
- 遍历链表,直到找到相等(==或equals)的 key
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods.
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 如果数组不为null
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 与数组第一个元素进行比较,相等则直接返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
// 判断是否为红黑树
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 遍历链表
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
Put方法
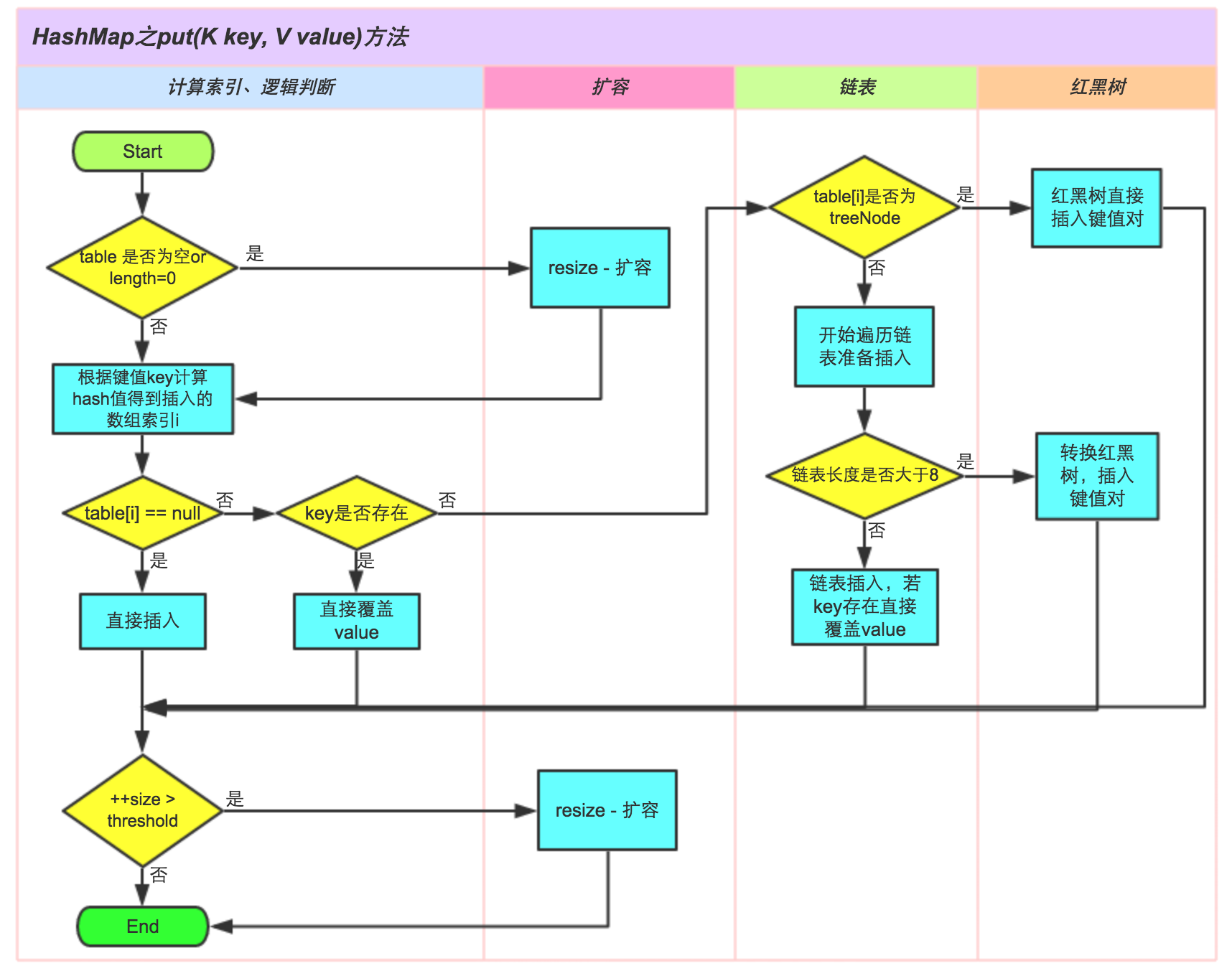
图片来源:https://tech.meituan.com/2016/06/24/java-hashmap.html
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 判断数组是否为空
if ((tab = table) == null || (n = tab.length) == 0)
// 进行扩容操作
n = (tab = resize()).length;
// 找到数组下标,如果该位置没有值,则初始化一个Node节点并把插入的键值放置在该位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 数组中该位置有数据
else {
Node<K,V> e; K k;
// 判断该位置的第一个数据和我们要插入的数据,key 是不是相等,如果是,取出这个节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果该位置的节点是红黑树
else if (p instanceof TreeNode)
// 调用红黑树的插入方法
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
// 插入到链表的最后面
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 插入元素后链表长度达到转化成红黑树的阈值
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 链表转化成红黑树
treeifyBin(tab, hash);
break;
}
// 在链表中找到了相等的key
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// e为链表中与插入值key相等的节点
break;
p = e;
}
}
// e!=null 说明存在旧值的key与要插入的key相等
if (e != null) { // existing mapping for key
// 覆盖原来的值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
++modCount;
// 如果 HashMap 由于新插入这个值导致 size 已经超过了阈值,需要进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
扩容
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 总是两倍扩容
newThr = oldThr << 1; // double threshold
}
// 已经设置了容量
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// 否则设置为默认容量
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 用新的数组大小初始化新的数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 开始遍历数组,进行数据迁移
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 该位置只有一个元素
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果是红黑树的情况
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 需要将此链表拆成两个链表,放到新的数组中,并且保留原来的先后顺序
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 第一条链表
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 第二条链表的新的位置是 j + oldCap
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
学习HashMap源码的更多相关文章
- hashMap源码学习记录
hashMap作为java开发面试最常考的一个题目之一,有必要花时间去阅读源码,了解底层实现原理. 首先,让我们看看hashMap这个类有哪些属性 // hashMap初始数组容量 static fi ...
- 基于jdk1.8的HashMap源码学习笔记
作为一种最为常用的容器,同时也是效率比较高的容器,HashMap当之无愧.所以自己这次jdk源码学习,就从HashMap开始吧,当然水平有限,有不正确的地方,欢迎指正,促进共同学习进步,就是喜欢程序员 ...
- HashMap源码分析
最近一直特别忙,好不容易闲下来了.准备把HashMap的知识总结一下,很久以前看过HashMap源码.一直想把集合类的知识都总结一下,加深自己的基础.我觉的java的集合类特别重要,能够深刻理解和应用 ...
- JAVA源码分析-HashMap源码分析(一)
一直以来,HashMap就是Java面试过程中的常客,不管是刚毕业的,还是工作了好多年的同学,在Java面试过程中,经常会被问到HashMap相关的一些问题,而且每次面试都被问到一些自己平时没有注意的 ...
- Java集合---HashMap源码剖析
一.HashMap概述二.HashMap的数据结构三.HashMap源码分析 1.关键属性 2.构造方法 3.存储数据 4.调整大小 5.数据读取 ...
- HashMap源码解读(转)
http://www.360doc.com/content/10/1214/22/573136_78188909.shtml 最近朋友推荐的一个很好的工作,又是面了2轮没通过,已经是好几次朋友内推没过 ...
- HashMap源码剖析
HashMap源码剖析 无论是在平时的练习还是项目当中,HashMap用的是非常的广,真可谓无处不在.平时用的时候只知道HashMap是用来存储键值对的,却不知道它的底层是如何实现的. 一.HashM ...
- [转载] Java集合---HashMap源码剖析
转载自http://www.cnblogs.com/ITtangtang/p/3948406.html 一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射 ...
- 基于JDK1.8版本的hashmap源码笔记(二)
这一篇是接着上一篇写的, 上一篇的地址是:基于JDK1.8版本的hashmap源码分析(一) /** * 返回boolean类型的值,当集合中包含key的键值,就返回true,否则就返 ...
随机推荐
- HDU3315 费用流
为了不让颓影响到学习= = (主要是颓得不想敲代码) 所以,决定在OJ上随便挑一题,能搞便搞,不会就找题解,扒过来,认真研究......(比如这题 原帖:http://m.blog.csdn.net/ ...
- ◆JAVA加密解密-3DES
从数据安全谈起 当你使用网银时,是否担心你的银行卡会被盗用? 当你和朋友用QQ进行聊天时,是否担心你的隐私会被泄露? 作为开发者,编写安全的代码比编写优雅的代码更重要,因为 ...
- Docker的资源控制管理
Docker的资源控制管理 1.CPU控制 2.对内存使用进行限制 3.对磁盘I/O配额控制的限制 1.CPU控制: cgroups,是一个非常强大的linux内核工具,他不仅可以限制被namespa ...
- LeetCode随缘刷题之Java经典面试题将一个字符串数组进行分组输出,每组中的字符串都由相同的字符组成
今天给大家分享一个Java经典的面试题,题目是这样的: 本题是LeetCode题库中的49题. 将一个字符串数组进行分组输出,每组中的字符串都由相同的字符组成 举个例子:输入["eat&qu ...
- maven下使用jstl标签(1.2)版本
使用的是1.2版本的,只需要一个jstl-1.2.jar jsp中头部加入<%@ taglib prefix="c" uri="http://java.sun ...
- 基于反熔丝FPGA、QSPI FLASH的高可靠程序存储、启动控制系统
1 涉及术语解释 1.1 三模冗余 三模冗余系统简称TMR(Triple Modular Redundancy),是最常用的一种容错设计技术.三个模块同时执行相同的操作,以多数相同的 ...
- 突然发现,npm里request依赖包已经弃用,怎么办?
摘要:在npm官网查看了request依赖包的当前状态,果然在2020年就被弃用了. 本文分享自华为云社区<npm里request依赖包已经弃用?致敬并调研替代方案!>,作者: gentl ...
- IDEA中使用Docker
开发环境 IDEA:2020.3.2 Docker:20.10.12 注意,如果没有开启Docker远程连接,请先开启Docker远程连接. 1. 打开或新建一个Web项目 可参考使用IDEA新建一个 ...
- 攻防世界之Web_php_rce
题目: ========================================================================== 解题思路: 1.这题主要考查ThinkPH ...
- c++动态内存管理与智能指针
目录 一.介绍 二.shared_ptr类 make_shared函数 shared_ptr的拷贝和引用 shared_ptr自动销毁所管理的对象- -shared_ptr还会自动释放相关联对象的内存 ...