数据库-mysql索引篇
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人。
文章不定期同步公众号,还有各种一线大厂面试原题、我的学习系列笔记。
mysql的索引类型?
mysql中有5种索引:普通索引、唯一索引、主键索引、组合索引、全文索引
- 普通索引index:最基本的索引,仅加速查询,是我们大多数情况下使用到的索引。
//为book表的bookname字段创建了名为index_bookBookname的索引
create index index_bookBookname on book(bookname)
- 唯一索引unique index:与普通索引区别是,加速查询 + 列值唯一(可以有null)
create unique index index_bookBookname on book(bookname)
- 主键索引:一个表的主键也是索引(primary key),叫主键索引,该类型的不能为null,一般在建表的时候建立
- 组合索引:在表的多个字段上创建一个组合索引,为book表的bookname和authors字段建索引
create index index_bookBooknameAndAuthors on book(bookname,authors)
或者
create table book(
id int(20),
bookname VARCHAR(32) ,
authors VARCHAR(32) ,
content text,
INDEX index_book (bookname,authors)
) ;
mysql创建索引时如果是blob 和 text 类型,索引里面必须指定length,如:
create index index_book on book(content(25)) ;
组合索引必遵循最左前缀原则
利用索引中最左边的列集来匹配行,比如新建索引 (bookname,authors,info) 最左边为bookname字段,查询的字段若为(bookname)、(bookname,authors)、(bookname,authors,info)则会启用索引,若为(authors)、(authors,info)则不会启用索引,(bookname,info)只会用到bookname列
- 全文索引:即FULLTEXT索引,它在很多文字中,通过关键字匹配就能够找到该记录。全文搜索的限制比较多,只有mysql的MyISAM存储引擎支持全文索引(mysql有InnoDB和MyISAM引擎);并且只能为CHAR、VARCHAR和TEXT列建索引;搜索的关键字默认至少要4个字符(关键字太短就会被忽略掉);
//使用全文搜索时,必须借助MATCH函数创建:
create fulltext index index_bookBookname on book(bookname)
create fulltext index index_bookBookname on book(bookname,authors)
select * from book where match(bookname) against('万历十五年');
select * from book where match(bookname,authors) against('万历十五年',"鲁迅");
主键索引又可以分为聚簇索引、非聚簇索引,它们的区别是什么?
- 相同点:聚簇索引和非聚簇索引都使用b+树实现
- 不同点:使用聚簇索引的表,它的表数据物理顺序和索引顺序保持一致,b+树中叶子节点=表数据节点=整行的表数据,它的查询比较快,修改表数据后因为要对数据进行重排序所以速度慢,mysql的Innodb引擎的主键索引就是聚簇索引(若没有主键则Innodb会选择一个唯一非空的索引列做聚簇索引,如果也没有唯一非空的索引列,则Innodb隐式生成一个主键来做聚簇索引);而非聚合索引的表则相反:它的表数据物理顺序和索引顺序不一致,b+树中叶子节点不等于表数据节点(叶子节点存的是索引字段的值、该索引字段值的表数据节点指针,故由非聚簇索引找到索引字段的值后,还要回表查询该字段值对应的行数据),修改表数据不需要对数据重排序所以速度快
谈谈sql的优化策略
- 避免全表扫描:避免使用select ,select count(),union all(求并集,包含重复值,union all比IN和union都强),select语句务必指明字段名称
- 慎用in 和 not in (in不会导致索引失效;not in会导致索引失效;当in的范围是确定的且范围比较小可以用in,不管怎样,多用between/exists 代替 in)
- 多表查询时,量小的表放在from的右边;
- where条件的and由后往前执行,故把能筛掉大量数据的and条件放在右边;where查询比having快;
- 尽量在join的on中写条件,而非on之后的where;尽量小表驱动大表,然后大表的条件列加索
- 利用索引:
- 什么时候加索引:where/on/orderby/groupby/distinct by后面的字段使用索引;对较小的列加索引,这样索引占的空间就会小
- 什么时候不要加索引:重复数据比较多的列,如0/1;text、image、bit类型的列;insert/deltete/update操作比select操作多的列(因为索引只对select语句有效)
- 使用索引的注意事项->索引有效:要符合最左前缀匹配原则;like匹配只有右模糊匹配才走索引(like xxx%);若是组合索引,则where条件的字段在组合索引中位于order by字段之前;使用explain分析sql执行计划,查看索引、使用了那些表,再进行优化;
- 使用索引的注意事项->索引失效:以下会导致索引失效,进而导致全表扫描=在where中对字段进行 null 值判断(放弃索引);在where中对字段进行表达式操作/函数操作(放弃索引);where 子句中使用!=或<>操作符(两个都是不等于的意思);where 子句中使用 or 来连接条件导致放弃索引(除非每个or条件字段都建了索引);like使用双%%、有前缀%(放弃索引)
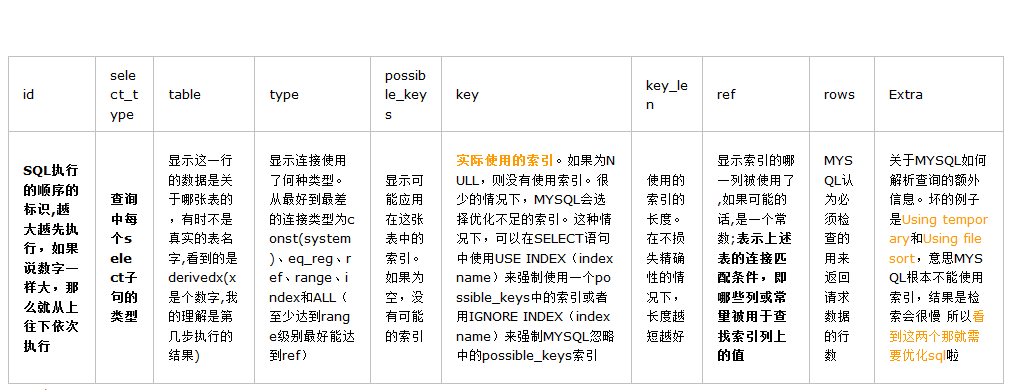
mysql的explain分析sql执行情况
- 特点:explain分析只是估算值并非准确值;explain只对select语句有效;
- 字段:
- id:SQL执行的顺序标识,越大越先执行,如果说数字一样大,那么就从上往下依次执行
- select_type:表示每个select子句的类型,如SIMPLE,PRIMARY,UNION,DERIVED;SIMPLE,简单的SELECT,表示不用UNION或子查询的select;
- PRIMARY,需要union操作或者含有子查询的select;
- table:数据表的名字。他们按被读取的先后顺序排列,这里因为只查询一张表,所以只显示book
- type:指定本数据表和其他数据表之间的关联关系,type最好能达到ref级别
- possible_keys:MySQL在搜索数据记录时可以选用的各个索引,查询涉及到的字段上若存在索引,则该索引将会被列出,但不一定被当前查询实际使用。
- key:实际选用的索引,若为null,则没有使用到索引
- key_len:计算使用了的索引长度,以字节为单位,字段类型 int为4个,date为3,datetime为4,char(n)为3n,varchar(n)为3n+2个
- ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
- extra:提供了与关联操作有关的信息,如Using filtersort文件排序(没有索引),Using index使用了索引;extra最好不要出现【using temporary=使用临时表】、【using filesort=使用文件排序=需要回表查询导致更多地io操作+需要更多的额外空间】
- rows :查询返回的行数
mysql索引为什么使用B+树而不是B-树(也称B树)?
- 由数据结构可知,B-树每个节点关键字个数为【[m/2]-1 ~ m-1】个,而B+树每个节点的关键字个数为【[m/2] ~ m】个,即B+树比B-树节点能存储更多的数据,所以同样的数据量在B+树的高度会比B-树低=访问B+树进行的I/O操作比B-树少=查询B+树所需的时间更少
- B-树每个节点都存有关键字,而B+树的所有关键字都存于叶子节点,所以B+树的查找速度更稳定
OK,如果文章哪里有错误或不足,欢迎各位留言。
创作不易,各位的「三连」是二少创作的最大动力!我们下期见!
数据库-mysql索引篇的更多相关文章
- mysql 索引篇
一.索引优化 索引优化主要还是依赖explain命令,关于explain命令相信大家并不陌生,具体用法和字段含义可以参考官网explain-output,这里需要强调rows是核心指标,绝大部分r ...
- MySQL索引篇之索引存储模型
本文重点介绍下索引的存储模型 二分查找 给定一个1~100的自然数,给你5次机会,你能猜中这个数字吗? 你会从多少开始猜? 为什么一定是50呢?这个就是二分查找的一种思想,也叫折半查找,每 ...
- 数据库-mysql索引
MySQL 索引 MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度. 打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索 ...
- 数据库——MySQL——索引
索引的功能就是加速查找,MySQL中的primary key,unique,联合唯一也都是索引,只是这些索引除了加速查找以外,还有约束功能. 一般的应用系统,读写比例在10:1左右,而且插入操作和一般 ...
- 数据库——MySQL——索引——索引原理及B+树
索引原理 我们使用索引,就是为了提高查询的效率,如同查书一样,先找到章,再找到章中对于的小节,再找到具体的页码,再到我们需要的内容. 事实上索引的本质就是不断缩小获取数据的筛选范围,找出我们想要的结果 ...
- MySQL索引篇
innodb索引概念 总结记录下innodb的索引概念,以备查看 innodb索引分类: 聚簇索引(clustered index) 1) 有主键时,根据主键创建聚簇索引 2 ...
- 为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生【宇哥带你玩转MySQL 索引篇(二)】
为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生 在上一节,我们聊到数据库为了让我们的查询加速,通过索引方式对数据进行冗余并排序,这样我们在使用时就可以在排好序的数据里进行快速的二分查找,使得查 ...
- MySQL如何创建一个好索引?创建索引的5条建议【宇哥带你玩转MySQL 索引篇(三)】
MySQL如何创建一个好索引?创建索引的5条建议 过滤效率高的放前面 对于一个多列索引,它的存储顺序是先按第一列进行比较,然后是第二列,第三列...这样.查询时,如果第一列能够排除的越多,那么后面列需 ...
- 数据库——MySQL——>Java篇
MySQL MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是 ...
随机推荐
- Github使用指南(学习中随时更新)
注册好一个账号后先创建一个仓库 点击"Create repository"创建一个版本库 填好带*号的必填项,选择是要公开仓库还是私人使用,勾选自动添加README选项 READM ...
- pg数据库排序和limit同时使用遇到的奇怪问题
这两天由于一位实习生同事回学校答辩,因此我来跟进他之前开发的功能进行测试,测试反馈上来这么一个问题: 也就是说下面这两条sql查询出来的数据前10条的数据不一样. select * from tabl ...
- MyISAM Static 和 MyISAM Dynamic 有什么区别?
在 MyISAM Static 上的所有字段有固定宽度.动态 MyISAM 表将具有像 TEXT, BLOB 等字段,以适应不同长度的数据类型. MyISAM Static 在受损情况下更容易恢复.
- String 和 StringBuilder、StringBuffer 的区别?
Java 平台提供了两种类型的字符串:String 和 StringBuffer/StringBuilder,它 们可以储存和操作字符串.其中 String 是只读字符串,也就意味着 String 引 ...
- 什么是redis的缓存雪崩与缓存穿透?如何解决?
一.缓存雪崩 1.1 什么是缓存雪崩? 首先我们先来回答一下我们为什么要用缓存(Redis): 1.提高性能能:缓存查询是纯内存访问,而硬盘是磁盘访问,因此缓存查询速度比数据库查询速度快 2.提高并发 ...
- mysql问题排查与性能优化
MySQL 问题排查都有哪些手段? 使用 show processlist 命令查看当前所有连接信息. 使用 explain 命令查询 SQL 语句执行计划. 开启慢查询日志,查看慢查询的 SQL. ...
- CI_CD 简单了解
- MariaDB数据库设置用户密码
SET PASSWORD [FOR user] = { PASSWORD('some password') | OLD_PASSWORD('some password') | 'encrypted p ...
- 学习openldap03
ldap统一认证架构 一.ldap目录服务介绍什么是目录服务? 目录是一类为了浏览和搜索数据而设计的特殊的数据库.例如,为人所熟知的微软公司的活动目录(active directory)就是目录数据 ...
- 2_稳定性分析_极点_Stability
在复平面内 控制理论就是设计控制器D使输入输出之间的传递函数的极点落在复平面的左侧,在现代控制理论中研究状态矩阵的特征值判断稳定性