AQS:Java 中悲观锁的底层实现机制
介绍 AQS
AQS(AbstractQueuedSynchronizer)是 Java 并发包中,实现各种同步组件的基础。比如
- 各种锁:ReentrantLock、ReadWriteLock、StampedLock
- 各种线程同步工具类:CountDownLatch、CyclicBarrier、Semaphore
- 线程池中的 Worker
Lock 接口的实现基本都是通过聚合了一个 AQS 的子类来完成线程访问控制的。
Doug Lea 曾经介绍过 AQS 的设计初衷。从原理上,一种同步组件往往是可以利用其他的组件实现的,例如可以使用 Semaphore 实现互斥锁。但是,对某种同步组件的倾向,会导致复杂、晦涩的实现逻辑,所以,他选择了将基础的同步相关操作抽象在 AbstractQueuedSynchronizer 中,利用 AQS 为我们构建同步组件提供了范本。
如何使用 AQS
利用 AQS 实现一个同步组件,我们至少要实现两类基本的方法,分别是:
- 获取资源,需要实现 tryAcquire(int arg) 方法
- 释放资源,需要实现 tryRelease(int arg) 方法
如果需要共享式获取 / 释放资源,需要实现对应的 tryAcquireShared(int arg)、tryReleaseShared(int arg)
AQS 使用的是模板方法设计模式。AQS 方法的修饰符很有规律,其中,使用 protected 修饰的方法为抽象方法,通常需要子类去实现,从而实现不同的同步组件;使用 public 修饰的方法基本可以认为是模板方法,不建议子类直接覆盖。
通过调用 AQS 的 acquire(int arg) 方法可以获取资源,该方法会调用 protected 修饰的 tryAcquire(int arg) 方法,因此我们需要在 AQS 的子类中实现 tryAcquire(int arg),tryAcquire(int arg) 方法的作用是:获取资源。
当前线程获取资源并执行了相应逻辑之后,就需要释放资源,使得后续节点能够继续获取资源。通过调用 AQS 的 release(int arg) 方法可以释放资源,该方法会调用 protected 修饰的 tryRelease(int arg) 方法,因此我们需要在 AQS 的子类中实现 tryRelease(int arg),tryRelease(int arg) 方法的作用是:释放资源。
AQS 的实现原理
从实现角度分析 AQS 是如何完成线程访问控制。
AQS 的实现原理可以从 同步阻塞队列、获取资源时的执行流程、释放资源时的执行流程 这 3 个方面介绍。
同步阻塞队列
AQS 依赖内部的同步阻塞队列(一个 FIFO 双向队列)来完成资源的管理。
同步阻塞队列的工作机制:
- 节点:同步阻塞队列中的节点(Node)用来保存获取资源失败的线程引用、等待状态以及前驱和后继节点,没有成功获取资源的线程将会成为节点加入同步阻塞队列的尾部,同时会阻塞当前线程(Java 线程处于 WAITING 状态,释放 CPU 的使用权)。
- 首节点:同步阻塞队列遵循 FIFO(先进先出),首节点是获取资源成功的节点,首节点的线程在释放资源时,将会唤醒后继节点,使其再次尝试获取资源,而后继节点将会在获取资源成功时将自己设置为首节点。
static final class Node {/*** Marker to indicate a node is waiting in shared mode*/static final AbstractQueuedSynchronizer.Node SHARED = new AbstractQueuedSynchronizer.Node();/*** Marker to indicate a node is waiting in exclusive mode*/static final AbstractQueuedSynchronizer.Node EXCLUSIVE = null;/*** waitStatus value to indicate thread has cancelled*/static final int CANCELLED = 1;/*** waitStatus value to indicate successor's thread needs unparking*/static final int SIGNAL = -1;/*** waitStatus value to indicate thread is waiting on condition*/static final int CONDITION = -2;/*** waitStatus value to indicate the next acquireShared should* unconditionally propagate*/static final int PROPAGATE = -3;// 等待状态volatile int waitStatus;// 前驱节点volatile AbstractQueuedSynchronizer.Node prev;// 后继节点volatile AbstractQueuedSynchronizer.Node next;/*** The thread that enqueued this node. Initialized on* construction and nulled out after use.*/volatile Thread thread;// 条件等待队列的后继节点AbstractQueuedSynchronizer.Node nextWaiter;/*** Returns true if node is waiting in shared mode.*/final boolean isShared() {return nextWaiter == SHARED;}/*** Returns previous node, or throws NullPointerException if null.* Use when predecessor cannot be null. The null check could* be elided, but is present to help the VM.** @return the predecessor of this node*/final AbstractQueuedSynchronizer.Node predecessor() throws NullPointerException {AbstractQueuedSynchronizer.Node p = prev;if (p == null) throw new NullPointerException();else return p;}Node() { // Used to establish initial head or SHARED marker}Node(Thread thread, AbstractQueuedSynchronizer.Node mode) { // Used by addWaiterthis.nextWaiter = mode;this.thread = thread;}Node(Thread thread, int waitStatus) { // Used by Conditionthis.waitStatus = waitStatus;this.thread = thread;}}
等待状态
在节点中用 volatile int waitStatus 属性表示节点的等待状态。
节点有如下几种等待状态:
- CANCELLED,值为 1,由于在同步阻塞队列中等待的线程等待超时或者被中断,需要从同步阻塞队列中取消等待,节点进人该状态将不会变化
- SIGNAL,值为 -1,后继节点的线程处于等待状态,而当前节点的线程如果释放了同步状态或者被取消,将会通知后继节点,使后继节点的线程得以运行
- CONDITION,值为 -2,节点在条件等待队列中,节点线程等待在 Condition 上,当其他线程对Condition 调用了 signal() 方法后,该节点将会从条件等待队列转移到同步阻塞队列中,加入到对同步状态的获取中
- PROPAGATE,值为 -3,表示下一次共享式同步状态获取将会无条件地被传播下去
- INITIAL,值为 0,初始状态
获取资源、释放资源的执行流程,结论先行:
- 在获取资源时,获取资源失败的线程都会被加入到同步阻塞队列中,并在队列中进行自旋;移出队列(或停止自旋)的条件是前驱节点为头节点且成功获取了资源。
- 在释放资源时,AQS 调用 tryRelease(int arg) 方法释放资源,然后唤醒头节点的后继节点。
获取资源
下面来介绍获取资源时的执行流程。
调用 AQS 的 acquire(int arg) 方法可以获取资源。
acquire(int arg) 方法是独占式获取资源,它调用流程如下图所示。
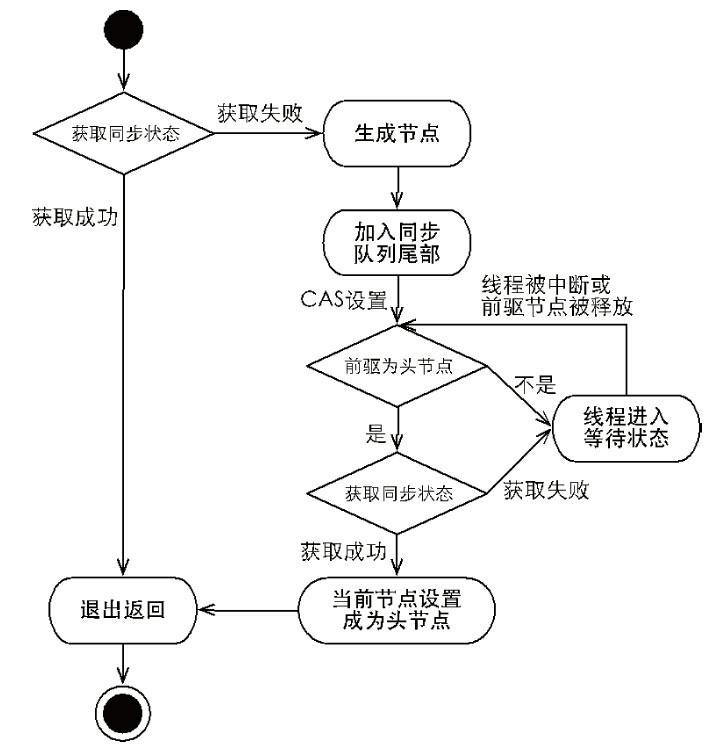
用文字描述 acquire(int arg) 方法的调用流程:首先调用自定义 AQS 实现的 tryAcquire(int arg) 方法,该方法的作用是尝试获取资源:
如果获取资源成功,则直接从 acquire(int arg) 方法返回
如果获取资源失败,则构造节点,并将该节点加入到同步阻塞队列的尾部,最后调用 acquireQueued(Node node,int arg) 方法,使得该节点以“死循环”的方式尝试获取资源。只有当前节点的前驱节点是头节点,才能尝试获取资源。
- 如果当前节点的前驱节点是头节点,并且获取资源成功,则设置当前节点为头节点,并从 acquireQueued(Node node,int arg) 方法返回
- 如果当前节点的前驱节点不是头节点 或者 获取资源失败,则阻塞当前线程,线程被唤醒后继续执行该循环操作
acquireQueued(Node node,int arg) 方法的调用过程也被称为“自旋过程”。
自旋是什么意思是呢?我的理解就是:自旋就是一个死循环,循环执行某个操作序列,直到满足某个条件才退出循环。
/*** Acquires in exclusive mode, ignoring interrupts. Implemented* by invoking at least once {@link #tryAcquire},* returning on success. Otherwise the thread is queued, possibly* repeatedly blocking and unblocking, invoking {@link* #tryAcquire} until success. This method can be used* to implement method {@link Lock#lock}.** @param arg the acquire argument. This value is conveyed to* {@link #tryAcquire} but is otherwise uninterpreted and* can represent anything you like.*/public final void acquire(int arg) {if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}
acquire(int arg) 的主要逻辑是:
首先调用自定义 AQS 实现的 tryAcquire(int arg) 方法,该方法保证线程安全的获取资源:
- 如果获取资源成功,则直接从 acquire(int arg) 方法返回
- 如果获取资源失败,则构造同步节点(独占式 Node.EXCLUSIVE,同一时刻只能有一个线程成功获取资源)并通过 addWaiter(Node node) 方法将该节点加入到同步阻塞队列的尾部,最后调用 acquireQueued(Node node,int arg) 方法,使得该节点以“死循环”的方式获取资源。如果获取不到则阻塞节点中的线程,而被阻塞线程的唤醒主要依靠 前驱节点的出队 或 阻塞线程被中断 来实现。
/*** Acquires in exclusive uninterruptible mode for thread already in* queue. Used by condition wait methods as well as acquire.** @param node the node* @param arg the acquire argument* @return {@code true} if interrupted while waiting*/final boolean acquireQueued(final Node node, int arg) {boolean failed = true;try {boolean interrupted = false;for (;;) {final Node p = node.predecessor();if (p == head && tryAcquire(arg)) {setHead(node);p.next = null; // help GCfailed = false;return interrupted;}if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);}}
在 acquireQueued(final Node node,int arg) 方法中,当前线程在“死循环”中尝试获取资源,而只有前驱节点是头节点才能够尝试获取资源,这是为什么?原因有两个,如下。
- 第一,头节点是成功获取到资源的节点,而头节点的线程释放了资源之后,将会唤醒其后继节点,后继节点的线程被唤醒后需要检查自己的前驱节点是否是头节点。
- 第二,维护同步阻塞队列的 FIFO 原则。
释放资源
当前线程获取资源并执行了相应逻辑之后,就需要释放资源,使得后续节点能够继续获取资源。
下面来介绍释放资源时的执行流程。
通过调用 AQS 的 release(int arg) 方法可以释放资源,该方法在释放资源之后,会唤醒头节点的后继节点,进而使后继节点重新尝试获取资源。
/*** Releases in exclusive mode. Implemented by unblocking one or* more threads if {@link #tryRelease} returns true.* This method can be used to implement method {@link Lock#unlock}.** @param arg the release argument. This value is conveyed to* {@link #tryRelease} but is otherwise uninterpreted and* can represent anything you like.* @return the value returned from {@link #tryRelease}*/public final boolean release(int arg) {if (tryRelease(arg)) {Node h = head;if (h != null && h.waitStatus != 0)unparkSuccessor(h);return true;}return false;}
release(int arg) 方法执行时,会唤醒头节点的后继节点线程, unparkSuccessor(Node node) 方法使用 LockSupport#unpark() 方法来唤醒处于等待状态的线程。
共享式 获取 & 释放 资源
上面讲的是独占式获取 / 释放 资源。
共享式获取与独占式获取最主要的区别在于:同一时刻能否有多个线程同时获取到资源。以文件的读写为例,如果一个程序在对文件进行读操作,那么这一时刻对于该文件的写操作均被阻塞,而读操作能够同时进行。写操作要求对资源的独占式访问,而读操作可以是共享式访问。
- 共享式访问资源时,其他共享式的访问均被允许,独占式访问被阻塞
- 独占式访问资源时,同一时刻其他访问均被阻塞
共享式获取资源
调用 AQS 的 acquireShared(int arg) 方法可以共享式地获取资源。
在 acquireShared(int arg) 方法中,AQS 调用 tryAcquireShared(int arg) 方法尝试获取资源, tryAcquireShared(int arg) 方法返回值为 int 类型,当返回值 >= 0 时,表示能够获取到资源。
可以看到,在 doAcquireShared(int arg) 方法的自旋过程中,如果当前节点的前驱为头节点时,才能尝试获取资源,如果获取资源成功(返回值 >= 0),则设置当前节点为头节点,并从自旋过程中退出。
public final void acquireShared(int arg) {if (tryAcquireShared(arg) < 0)doAcquireShared(arg);}private void doAcquireShared(int arg) {final Node node = addWaiter(Node.SHARED);boolean failed = true;try {boolean interrupted = false;for (;;) {final Node p = node.predecessor();if (p == head) {int r = tryAcquireShared(arg);if (r >= 0) {setHeadAndPropagate(node, r);p.next = null; // help GCif (interrupted)selfInterrupt();failed = false;return;}}if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);}}
共享式释放资源
调用 releaseShared(int arg) 方法可以释放资源。该方法在释放资源之后,会唤醒头节点的后继节点,进而使后继节点重新尝试获取资源。
对于能够支持多个线程同时访问的并发组件(比如 Semaphore),它和独占式主要区别在于 tryReleaseShared(int arg) 方法必须确保资源安全释放,因为释放资源的操作会同时来自多个线程。 确保资源安全释放一般是通过循环和 CAS 来保证的。
public final boolean releaseShared(int arg) {if (tryReleaseShared(arg)) {doReleaseShared();return true;}return false;}
独占式超时获取资源
调用 AQS 的 doAcquireNanos(int arg,long nanosTimeout) 方法可以超时获取资源,即在指定的时间段内获取资源,如果获取资源成功则返回 true,否则返回 false。
该方法提供了传统 Java 同步操作(比如 synchronized 关键字)所不具备的特性。
在分析该方法的实现前,先介绍一下响应中断的获取资源过程。
- 在 Java 5 之前,当一个线程获取不到锁而被阻塞在 synchronized 之外时,对该线程进行中断操作,此时该线程的中断标志位会被修改,但线程依旧会阻塞在 synchronized 上,等待着获取锁。
- 在 Java 5 中,AQS 提供了 acquireInterruptibly(int arg) 方法,这个方法在等待获取资源时,如果当前线程被中断,会立刻返回,并抛出 InterruptedException。
acquire(int arg) 方法对中断不敏感,也就是由于线程获取资源失败后进入同步阻塞队列中,后续对线程进行中断操作时,线程不会从同步阻塞队列中移出。
超时获取资源过程可以被视作响应中断获取资源过程的“增强版”,doAcquireNanos(int arg,long nanosTimeout) 方法在支持响应中断的基础上,增加了超时获取的特性。
针对超时获取,主要需要计算出需要睡眠的时间间隔 nanosTimeout,为了防止过早通知, nanosTimeout 计算公式为:nanosTimeout -= now - lastTime,其中 now 为当前唤醒时间, lastTime 为上次唤醒时间,如果 nanosTimeout 大于 0 则表示超时时间未到,需要继续睡眠 nanosTimeout 纳秒,反之,表示已经超时。
public final boolean tryAcquireNanos(int arg, long nanosTimeout)throws InterruptedException {if (Thread.interrupted())throw new InterruptedException();return tryAcquire(arg) ||doAcquireNanos(arg, nanosTimeout);}/*** Acquires in exclusive timed mode.** @param arg the acquire argument* @param nanosTimeout max wait time* @return {@code true} if acquired*/private boolean doAcquireNanos(int arg, long nanosTimeout) throws InterruptedException {if (nanosTimeout <= 0L)return false;final long deadline = System.nanoTime() + nanosTimeout;final Node node = addWaiter(Node.EXCLUSIVE);boolean failed = true;try {for (;;) {final Node p = node.predecessor();if (p == head && tryAcquire(arg)) {setHead(node);p.next = null; // help GCfailed = false;return true;}nanosTimeout = deadline - System.nanoTime();if (nanosTimeout <= 0L)return false;if (shouldParkAfterFailedAcquire(p, node) &&nanosTimeout > spinForTimeoutThreshold)LockSupport.parkNanos(this, nanosTimeout);if (Thread.interrupted())throw new InterruptedException();}} finally {if (failed)cancelAcquire(node);}}
该方法在自旋过程中,当节点的前驱节点为头节点时尝试获取资源,如果成功获取资源则从该方法返回,这个过程和独占式同步获取的过程类似,但是在获取资源失败的处理上有所不同。
如果当前线程获取资源失败,则判断是否超时(nanosTimeout 小于等于 0 表示已经超时),如果没有超时,则重新计算超时间隔 nanosTimeout,然后使当前线程等待 nanosTimeout 纳秒(当已到设置的超时时间,该线程会从 LockSupport.parkNanos(Object blocker,long nanos)方法返回)。
如果 nanosTimeout 小于等于 spinForTimeoutThreshold(1000 纳秒)时,将不会使该线程进行超时等待,而是进入快速的自旋过程。原因在于,非常短的超时等待无法做到十分精确,如果这时再进行超时等待,相反会让 nanosTimeout 的超时从整体上表现得反而不精确。因此,在超时非常短的场景下,AQS 会进入无条件的快速自旋。
独占式超时获取资源的流程如下所示。
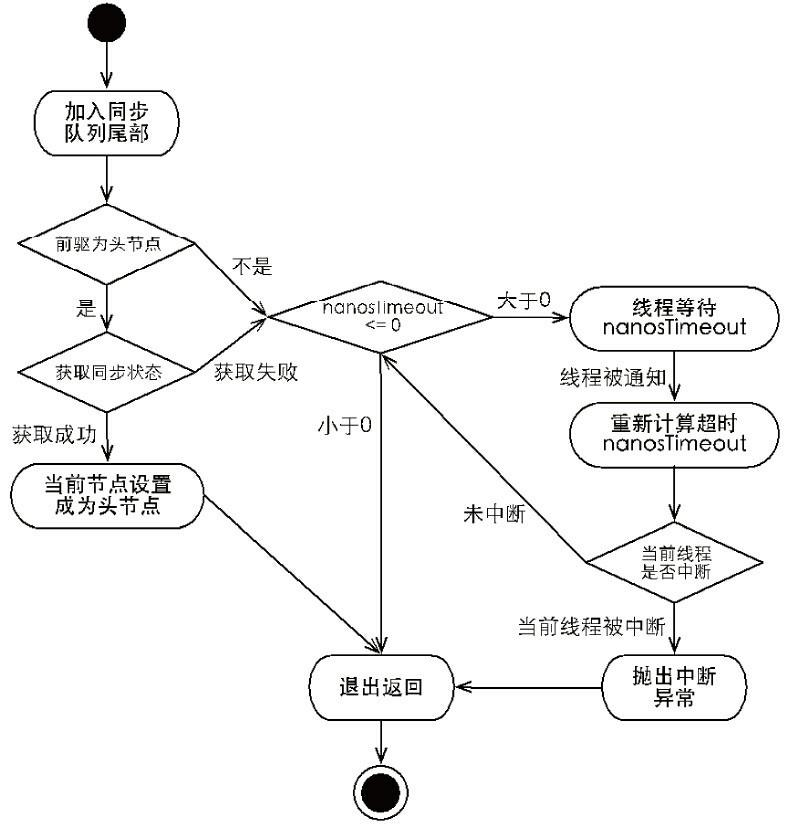
从图中可以看出,独占式超时获取资源 doAcquireNanos(int arg,long nanosTimeout) 和独占式获取资源 acquire(int args)在流程上非常相似,其主要区别在于:未获取到资源时的处理逻辑。
acquire(int args) 在未获取到资源时,将会使当前线程一直处于等待状态,而 doAcquireNanos(int arg,long nanosTimeout) 会使当前线程等待 nanosTimeout 纳秒,如果当前线程在 nanosTimeout 纳秒内没有获取到资源,将会从等待逻辑中自动返回。
Condition 的实现原理
技术是为了解决问题而生的,通过 Condition 我们可以实现等待 / 通知功能。
ConditionObject 是 AQS 的内部类。每个 Condition 对象都包含着一个条件等待队列,这个条件等待队列是 Condition 对象实现等待 / 通知功能的关键。
下面我们分析 Condition 的实现原理,主要包括:条件等待队列、等待 和 通知。
下面提到的 Condition 如果不加说明均指的是 ConditionObject。
条件等待队列
Condition 依赖内部的条件等待队列(一个 FIFO 双向队列)来实现等待 / 通知功能。
条件等待队列的工作机制:
- 节点:条件等待队列中的每个节点(Node)都包含一个线程引用,该线程就是在 Condition 对象上等待的线程,如果一个线程调用了 Condition.await()方法,那么该线程将会释放资源、构造成为节点加入条件等待队列的尾部,同时线程状态变为等待状态。
事实上,条件等待队列中的节点定义复用了 AQS 节点的定义,也就是说,同步阻塞队列和条件等待队列中节点类型都是 AQS 的静态内部类 AbstractQueuedSynchronizer.Node。
在 Object 的监视器模型上,一个对象拥有一个同步阻塞队列和一个条件等待队列,而并发包中的 Lock(更确切地说是 AQS)拥有一个同步阻塞队列和多个条件等待队列。
等待
下面来介绍让线程等待的执行流程。
调用 Condition 的 await() 方法(或者以 await 开头的方法),将会使当前线程释放资源、构造成为节点加入条件等待队列的尾部,同时线程状态变为等待状态。
如果从队列(同步阻塞队列和条件等待队列)的角度看 await()方法,当调用 await() 方法时,相当于同步阻塞队列的首节点(获取到锁的节点)移动到 Condition 的条件等待队列中。并且同步阻塞队列的首节点并不会直接加入条件等待队列,而是通过 addConditionWaiter() 方法把当前线程构造成一个新的节点,将其加入条件等待队列中。
/*** Implements interruptible condition wait.* <ol>* <li> If current thread is interrupted, throw InterruptedException.* <li> Save lock state returned by {@link #getState}.* <li> Invoke {@link #release} with saved state as argument,* throwing IllegalMonitorStateException if it fails.* <li> Block until signalled or interrupted.* <li> Reacquire by invoking specialized version of* {@link #acquire} with saved state as argument.* <li> If interrupted while blocked in step 4, throw InterruptedException.* </ol>*/public final void await() throws InterruptedException {if (Thread.interrupted())throw new InterruptedException();Node node = addConditionWaiter();int savedState = fullyRelease(node);int interruptMode = 0;while (!isOnSyncQueue(node)) {LockSupport.park(this);if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)break;}if (acquireQueued(node, savedState) && interruptMode != THROW_IE)interruptMode = REINTERRUPT;if (node.nextWaiter != null) // clean up if cancelledunlinkCancelledWaiters();if (interruptMode != 0)reportInterruptAfterWait(interruptMode);}
通知
下面来介绍唤醒等待线程的执行流程。
调用 Condition 的 signal() 方法,将会唤醒在条件等待队列中等待时间最长的节点(首节点),在唤醒节点之前,会将当前节点从条件等待队列移动到同步阻塞队列中。
条件等待队列中的节点被唤醒后,被唤醒的线程以“死循环”的方式尝试获取资源。成功获取资源之后,被唤醒的线程将从先前调用的 await() 方法返回。
如果被唤醒的线程不是通过其他线程调用 Condition.signal() 方法唤醒,而是对等待线程进行中断,则会抛出InterruptedException。
被唤醒的线程,将从 await() 方法中的 while 循环中退出(isOnSyncQueue(Node node) 方法返回 true,节点已经在同步阻塞队列中),进而调用 AQS 的 acquireQueued() 方法以“死循环”的方式尝试获取资源。成功获取资源之后,被唤醒的线程将从先前调用的 await() 方法返回。
Condition 的 signalAll() 方法,相当于对条件等待队列中的每个节点均执行一次 signal() 方法,效果就是将条件等待队列中所有节点全部移动到同步阻塞队列中,并唤醒每个节点的线程。
虽然是把每个节点的线程都唤醒了,这些线程需要尝试获取资源, 但是只有一个线程能够成功获取资源,然后从 await() 方法返回;其他获取资源失败的线程又都会被加入到同步阻塞队列中,并在队列中进行自旋;移出队列(或停止自旋)的条件是前驱节点为头节点且成功获取了资源。
/*** Moves the longest-waiting thread, if one exists, from the* wait queue for this condition to the wait queue for the* owning lock.** @throws IllegalMonitorStateException if {@link #isHeldExclusively}* returns {@code false}*/public final void signal() {if (!isHeldExclusively())throw new IllegalMonitorStateException();Node first = firstWaiter;if (first != null)doSignal(first);}/*** Removes and transfers nodes until hit non-cancelled one or* null. Split out from signal in part to encourage compilers* to inline the case of no waiters.* @param first (non-null) the first node on condition queue*/private void doSignal(Node first) {do {if ( (firstWaiter = first.nextWaiter) == null)lastWaiter = null;first.nextWaiter = null;} while (!transferForSignal(first) &&(first = firstWaiter) != null);}
参考资料
《Java并发编程艺术》第5章:Java 中的锁
AQS:Java 中悲观锁的底层实现机制的更多相关文章
- Java并发编程:Java中的锁和线程同步机制
锁的基础知识 锁的类型 锁从宏观上分类,只分为两种:悲观锁与乐观锁. 乐观锁 乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新 ...
- 深入介绍Java中的锁[原理、锁优化、CAS、AQS]
1.为什么要用锁? 锁-是为了解决并发操作引起的脏读.数据不一致的问题. 2.锁实现的基本原理 2.1.volatile Java编程语言允许线程访问共享变量, 为了确保共享变量能被准确和一致地更新, ...
- Java中的锁[原理、锁优化、CAS、AQS]
1.为什么要用锁? 锁-是为了解决并发操作引起的脏读.数据不一致的问题. 2.锁实现的基本原理 2.1.volatile Java编程语言允许线程访问共享变量, 为了确保共享变量能被准确和一致地更新, ...
- Java中的锁原理、锁优化、CAS、AQS详解!
阅读本文大概需要 2.8 分钟. 来源:jianshu.com/p/e674ee68fd3f 一.为什么要用锁? 锁-是为了解决并发操作引起的脏读.数据不一致的问题. 二.锁实现的基本原理 2.1.v ...
- Java 中的锁原理、锁优化、CAS、AQS 详解!(转)
1.为什么要用锁? 锁-是为了解决并发操作引起的脏读.数据不一致的问题. 2.锁实现的基本原理 2.1.volatile Java编程语言允许线程访问共享变量, 为了确保共享变量能被准确和一致地更新, ...
- 一篇blog带你了解java中的锁
前言 最近在复习锁这一块,对java中的锁进行整理,本文介绍各种锁,希望给大家带来帮助. Java的锁 乐观锁 乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人 ...
- 【多线程】不懂什么是 Java 中的锁?看看这篇你就明白了!
本文来源:Java建设者 原文地址:https://mp.weixin.qq.com/s/GU42BjM5jY2CEMVD_PAZBQ Java 锁分类 Java 中的锁有很多,可以按照不同的功能.种 ...
- java 中的锁 -- 偏向锁、轻量级锁、自旋锁、重量级锁(转载)
之前做过一个测试,详情见这篇文章<多线程 +1操作的几种实现方式,及效率对比>,当时对这个测试结果很疑惑,反复执行过多次,发现结果是一样的: 1. 单线程下synchronized效率最高 ...
- Java 中的锁
Java中的锁分类 在读很多并发文章中,会提及各种各样锁如公平锁,乐观锁等等,这篇文章介绍各种锁的分类.介绍的内容如下: 公平锁/非公平锁 可重入锁 独享锁/共享锁 互斥锁/读写锁 乐观锁/悲观锁 分 ...
随机推荐
- centos系统管理高级篇
1 enable virtual box 控制 - 关机 可以通过虚拟机的关机按钮执行关机,而不是登陆centos再执行init 0 首先,安装acpid包 如果你的centos已经安装这个包,就省略 ...
- Oracle数据库常用查询语句
1.[oracle@dbserver ~]$ sqlplus / as sysdbaSQL*Plus: Release 11.2.0.4.0 Production on Tue Mar 15 15:1 ...
- PTA(BasicLevel)-1094 谷歌的招聘
一.问题定义 2004 年 7 月,谷歌在硅谷的 101 号公路边竖立了一块巨大的广告牌(如下图)用于招聘.内容超级简单,就是一个以 .com 结尾的网址, 而前面的网址是一个 10 位素数,这个素数 ...
- 扩展-PageHelper分页插件
1.PageHelper 分页插件简介 1) PageHelper是MyBatis中非常方便的第三方分页插件 2) 官方文档: https://github.com/pagehelper/Mybati ...
- vue封装原生的可预览裁剪上传图片插件H5,PC端都可以使用
思路:1.先做出一个上传的图片的上传区 <!-- 上传区 --> <label for="fileUp"> <div class="upBo ...
- war包解压与压缩
解压:jar -xvf ROOT.war 压缩:jar -cvfM0 ROOT.war ./
- 适用于MES、WMS、ERP等管理系统的实体下拉框设计
场景 该设计多适用于MES,ERP,WMS 等管理类型的项目. 在做管理类型项目的时候,前端经常会使用到下拉框,比如:设备,工厂等等.下拉组件中一般只需要他们的ID,Name属性,而这些数据都创建于其 ...
- 聊聊 C++ 中的几种智能指针 (上)
一:背景 我们知道 C++ 是手工管理内存的分配和释放,对应的操作符就是 new/delete 和 new[] / delete[], 这给了程序员极大的自由度也给了我们极高的门槛,弄不好就得内存泄露 ...
- .Net 之时间轮算法(终极版)
关于时间轮算法的起始 我也认真的看了时间轮算法相关,大致都是如下的一个图 个人认为的问题 大部分文章在解释这个为何用时间轮的时候都再说 假设我们现在有一个很大的数组,专门用于存放延时任务.它的精度达到 ...
- 字节输出流的续写和换行和字节输入流InputStream类&FileInputStream类介绍
数据追加续写 每次程序运行,创建输出流对象,都会清空目标文件中的数据.如何保目标文件中的数据,还能继续添加新数据呢? public FileOutputStream(File file,boolean ...