使用Logstash把MySQL数据导入到Elasticsearch中
总结:这种适合把已有的MySQL数据导入到Elasticsearch中
有一个csv文件,把里面的数据通过Navicat Premium 软件导入到数据表中,共有998条数据
文件下载地址:https://files.cnblogs.com/files/sanduzxcvbnm/SalesJan2009.zip
csv文件格式如下:
Logstash 配置
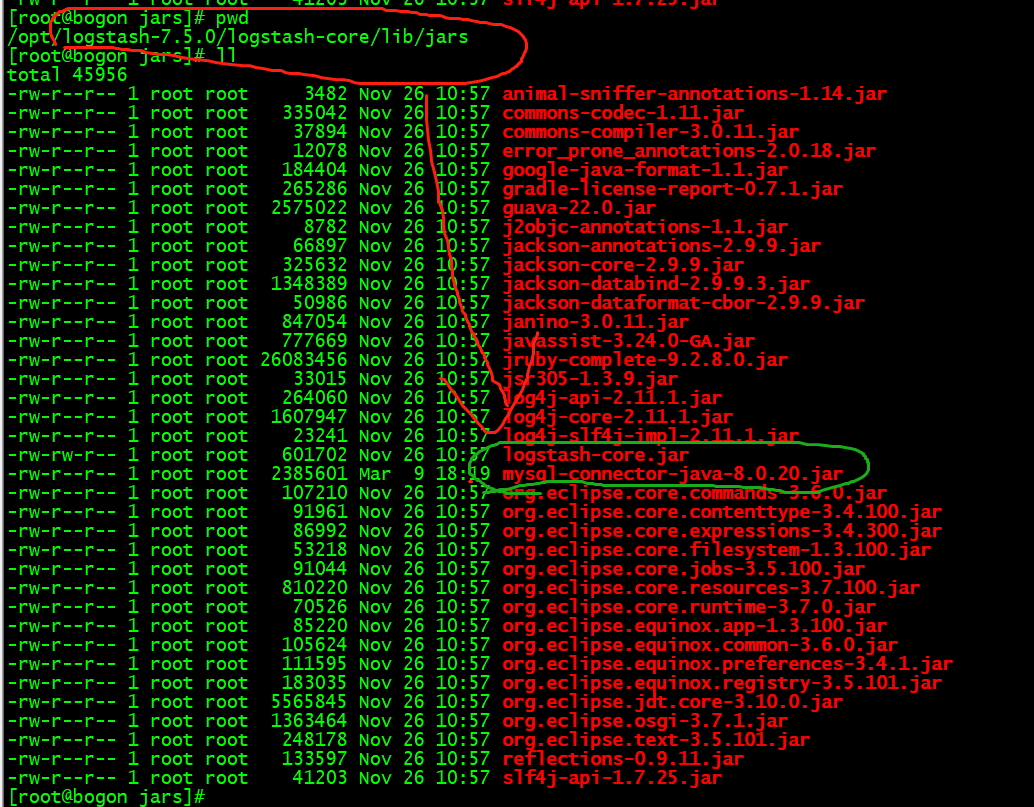
1.下载连接mysql的驱动包,放到指定目录下
在地址https://dev.mysql.com/downloads/connector/j/下载最新的Connector。下载完这个Connector后,把这个connector存入到Logstash安装目录下的如下子目录中:
logstash-core/lib/jars/
conf文件内容如下:
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.0.145:3306/db_example?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC"
jdbc_user => "root"
jdbc_password => "root"
jdbc_validate_connection => true
jdbc_driver_library => ""
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
parameters => { "Product_id" => "Product1" }
statement => "SELECT * FROM salesjan2009 WHERE Product = :Product_id"
}
}
filter {
mutate {
rename => {
"longitude" => "[location][lon]"
"latitude" => "[location][lat]"
}
}
}
output {
stdout {
}
elasticsearch {
hosts => ["192.168.75.21:9200"]
index => "sales" # 指定索引名
document_type => "_doc"
user => "elastic"
password => "GmSjOkL8Pz8IwKJfWgLT"
}
}
说明:
1.jdbc_connection_string => "jdbc:mysql://192.168.0.145:3306/db_example?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC"
连接的数据库地址,端口号,数据库名,字符编码,时区等,db_example为数据库名
2.
jdbc_user => "root"
jdbc_password => "root"
连接数据库使用的用户名和密码,根据自己的实际情况而定
3.jdbc_driver_library
驱动包路径,若是在logstash指定目录下则留空,若不是则需要指定绝对路径
4.jdbc_driver_class
最新使用的驱动包类
5.parameters
设置一个参数Product_id,其值是Product1
6.statement
sql语句,结合上面的理解,是查询salesjan2009数据表中条件Product的值是Product_id也即是Product1的数据
7.filter mutate
新增一个字段,重构经纬度参数值结构
运行Logstash来加载我们的MySQL里的数据到Elasticsearch中:
./bin/logstash --debug -f ./config/conf.d/sales.conf
可以在Kibana中查看到最新的导入到Elasticsearch中的数据:
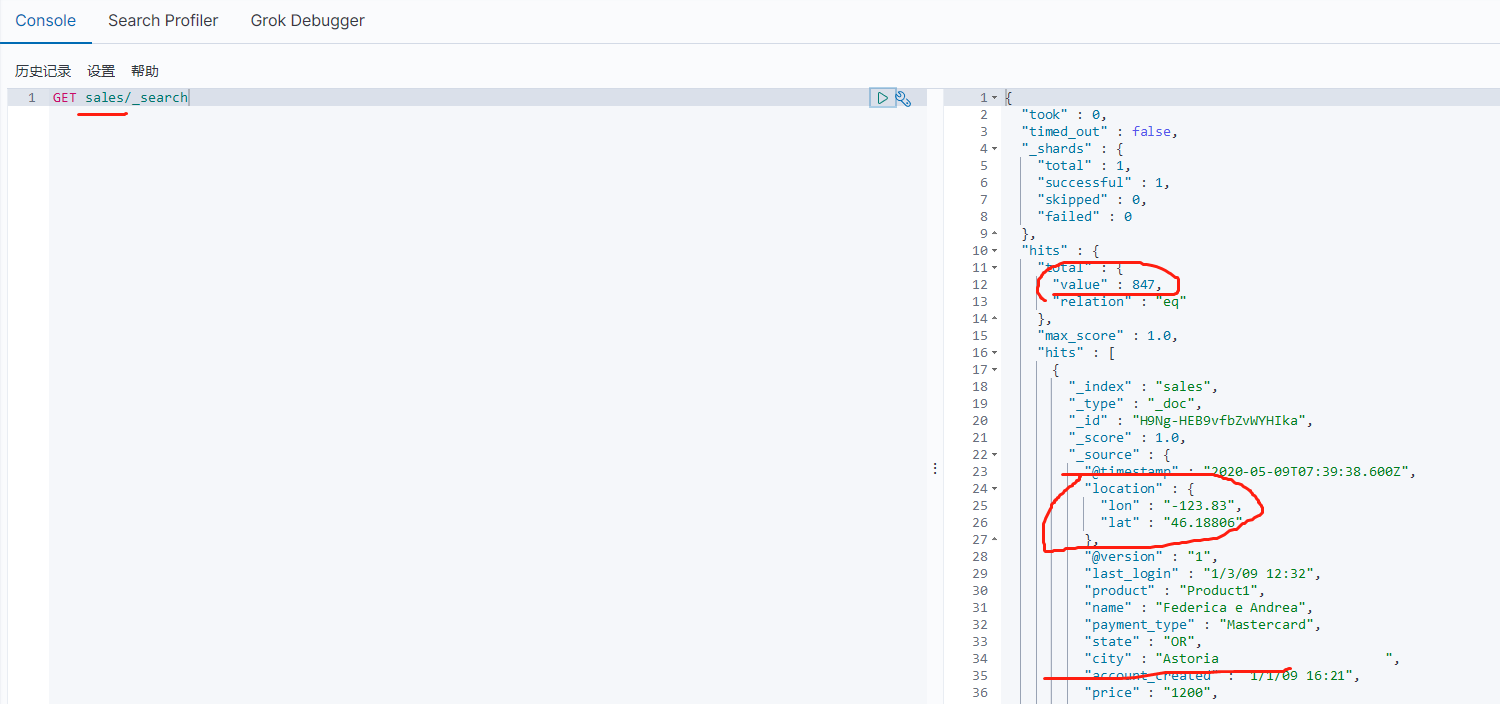
注意数据总数,并不是数据表中的全部数据,而是根据查询条件获得的部分数据。
使用Logstash把MySQL数据导入到Elasticsearch中的更多相关文章
- Logstash:把MySQL数据导入到Elasticsearch中
Logstash:把MySQL数据导入到Elasticsearch中 前提条件 需要安装好Elasticsearch及Kibana. MySQL安装 根据不同的操作系统我们分别对MySQL进行安装.我 ...
- Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一.使用Logstash将mysql数据导入elasticsearch 1.在mysql中准备数据: mysql> show tables; +----------------+ | Table ...
- Sqoop1.99.7将MySQL数据导入到HDFS中
准备 本示例将实现从MySQL数据库中将数据导入到HDFS中 参考文档: http://sqoop.apache.org/docs/1.99.7/user/Sqoop5MinutesDemo.html ...
- 使用sqoop将mysql数据导入到hive中
首先准备工具环境:hadoop2.7+mysql5.7+sqoop1.4+hive3.1 准备一张数据库表: 接下来就可以操作了... 一.将MySQL数据导入到hdfs 首先我测试将zhaopin表 ...
- Kafka Connect使用入门-Mysql数据导入到ElasticSearch
1.Kafka Connect Connect是Kafka的一部分,它为在Kafka和外部存储系统之间移动数据提供了一种可靠且伸缩的方式,它为连接器插件提供了一组API和一个运行时-Connect负责 ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- 使用logstash同步mysql数据库信息到ElasticSearch
本文介绍如何使用logstash同步mysql数据库信息到ElasticSearch. 1.准备工作 1.1 安装JDK 网上文章比较多,可以参考:https://www.dalaoyang.cn/a ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第三篇:logstash_output_kafka:Mysql同步Kafka深入详解
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484411&idx=1&sn=1f5a371 ...
随机推荐
- 研发效能|Kubernetes核心技术剖析和DevOps落地经验
本文主要介绍Kubernetes 的核心组件.架构.服务编排,以及在集群规模.网络&隔离.SideCar.高可用上的一些使用建议,尤其是在CICD中落地,什么是 GitOps. 通过此文可彻底 ...
- NAT模式 LVS负载均衡群集部署
NAT模式 LVS负载均衡群集部署的操作步骤 实验环境准备: 负载调度器:内网关 ens33:172.16.10.1,外网关 ens37:12.0.0.1 Web节点服务器1:172.16.10.10 ...
- SpringMVC底层——请求参数处理流程描述
在DispatcherServlet.java的doDispatch方法中,springmvc通过handlermapping里面找哪个handler能处理请求,handler封装了目标方法的信息, ...
- CF1593D2 Half of Same
题目大意: 给定一个包含 \(n\)(\(n\) 是偶数)个整数的数列 \(a_1,a_2,\ldots,a_n\). 考虑一个可能的正整数 \(k\),在每次操作中,你可以选定一个 \(i\),并将 ...
- display: table-cell里面文字打点的方法
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Java开发学习(十八)----AOP通知获取数据(参数、返回值、异常)
前面的博客我们写AOP仅仅是在原始方法前后追加一些操作,接下来我们要说说AOP中数据相关的内容,我们将从获取参数.获取返回值和获取异常三个方面来研究切入点的相关信息. 前面我们介绍通知类型的时候总共讲 ...
- python 参数类型理解
简介 大家都知道,在java中,函数或者方法的参数在调用时必须对其进行传参操作,也就是所谓的必选参数,也可以称为位置参数,除此之外,python还拥有其他语言不具有的一些参数类型,以下将进行一一介绍. ...
- Javascript 函数声明、调用、闭包
1 # Javascript 函数声明.调用.闭包 2 # 一.函数声明 3 # 1.直接声明.浏览器在执行前,会先将变量和函数声明进行提升. 4 fn(); 5 function fn () { 6 ...
- NRooks采样类定义和测试
类声明: #pragma once #ifndef __NROOKS_HEADER__ #define __NROOKS_HEADER__ #include "sampler.h" ...
- Linux 10 安装JDK
参考源 https://www.bilibili.com/video/BV187411y7hF?spm_id_from=333.999.0.0 版本 本文章基于 CentOS 7.6 这里使用 rpm ...