干货来袭!3天0基础Python实战项目快速学会人工智能必学数学基础全套(含源码)(第3天)概率分析篇:条件概率、全概率与贝叶斯公式
第3天:概率分析篇:条件概率与全概率、贝叶斯公式、实战项目
前言
非常抱歉,至上次博主更新人工智能关于《高等数学》相关应用及知识点,已经停更了差不多一年了,主要是博主工作上遇到公司组织架构调整,之后又是各种新项目,一直拖更到现在。不过这些都不是理由,更多得是懒了。任何时候行动起来,都不算晚,所以选择今天8月8日这个好日子,赶紧给大家更新一版。
同时为了回报粉丝们的持续关注,这段时间开始,博主不仅会把人工智能必学数学基础最后一篇概率分析篇更新完,还会陆陆续续更新一些关于博主以前做过的一些人工智能实战项目,欢迎大家继续关注。
接下来进入正题,对于人工智能概率分析这块来说,其实说起来不复杂,运用到的数学知识或数学公式可能就那么几个,但是由于现实中很多问题都可以用概率来解释分析,它的运用会具有一定复杂性,甚至有时我们无法理解其中的原因。
这里面究其根本,我觉得就是现实中各种事情的发生概率,其实并不是单一事件引起的,更多是比较复杂的多因素决定的,而且很有可能随着时间发展,其决定因素又会发生变化,所以大家到最后可能就会更加晕圈。
不过我觉得大家也不要太纠结,因为只要我们掌握了其中基本原理,再经过几次实战,你就会对概率的认识越来越清晰了,而且研究深入到最后,你就可以到达目前人工智能关于强化学习的领域,说不定哪天你就能开发出一个类似阿法尔狗的牛逼程序。
老样子,既然是分享数学知识,还是得继续拿出严谨的思维和态度来。我又翻出10多年前我的概率论课本、笔记,教材是我们学校出版的,我们主要学习的是前面6章,从随机概率、条件概率、随机变量、随机向量、随机变量的数字特征到大数定律等。
看起来我们大学时候要学习的概率相关知识还是有点多,但对于人工智能入门来说,其实最重要的就只有最前面的第一章和第二章,也就是随机概率和条件概率。


这次小伙伴们看到我这门课成绩,可以不用激动了,成绩没上90分,主要那时候,我刚好读大二,玩网易刚出来的游戏《梦幻西游》上瘾了,学习兴趣和热情远没有像大一那样高了。不知道有没有小伙伴们像我一样在读大学的时候控制不住我自己。
还好现在我已经控制住我自己了,把玩游戏的时间拿出来,今年目标学习12本技术相关书籍(目前已经学习了6本了)和听50本樊登读书,已经努力实现了不少了,有望年底全部实现。也希望小伙伴们也能活到老,学到老!大家共勉,加油!
接下来跟着我继续三天掌握人工智能必学数学基础最后一天的学习吧!
一、概率与机器学习
1.1 概率
有些小伙伴玩过下面这种俄罗斯大转盘的游戏,我们就从这个概率的简单应用场景来说。

俄罗斯大转盘总共有0-36,共37个数字。其中有18个红色数字、18个黑色数字以及1个绿色数字。大家可以思考这么一个问题:如果每次下注黑色区域1元,正确返还2元,重复3700次,预期收益多少?(当然警察叔叔经常教育我们十赌九输,这里仅供演示,用数学告诉大家真相,大家千万别禁不住诱惑,赌博害人)
18/37*1 + (18+1)/37 *(-1) = -1/37
3700 X (-1/37) = -100
从上面计算可以看出,最终结果我们是会输掉100元,玩得越多,输的越多。赌博就是让你大概率输,所以千万别迷上赌博,不然迟早一天倾家荡产。
那概率到底是什么呢?我们从百度百科找下答案:
概率,亦称“或然率”,它是反映随机事件出现的可能性大小。随机事件是指在相同条件下,可能出现也可能不出现的事件。例如,从一批有正品和次品的商品中,随意抽取一件,“抽得的是正品”就是一个随机事件。设对某一随机现象进行了n次试验与观察,其中A事件出现了m次,即其出现的频率为m/n。经过大量反复试验,常有m/n越来越接近于某个确定的常数(此论断证明详见伯努利大数定律)。该常数即为事件A出现的概率,常用P(A)表示。
举例来说,我们抛1元硬币,出现一面为国徽,一面为1元的概率就分别为1/2。
1.2 机器学习中的概率
我们关联起来的机器学习中的概率应用一般就是在分类情况下,机器学习模型直接预测的结果就是某种情况对应的概率。比如说人脸识别中,我们从所有图片中进行预测,去预测出图片是人脸的概率有多大,我们可以设定一个95%的阈值,概率超过95%以上是人脸,我们就认为是人脸,否则就不是。
其实现实生活中有很多东西都和概率有关,人工智能也有很大一部分是利用历史的数据,来预测未来发生某种事件的概率。细心的小伙伴们,如果擅于利用好概率,说不定哪天你就可以成为一个厉害的预言家了。
二、条件概率与全概率
2.1 条件概率
我们举个纸牌游戏的例子来说明条件概率吧。
有两张黑牌、两张红牌,从中抽取一张,如果为红牌,退还下注并奖励1.1倍,玩家是否应该下注?如果抽取的第一张为红牌,游戏继续,玩家是否应该下注?
我们分析一下第一种情况,分别从两张黑牌、两张红牌抽到该牌的概率都是1/2,假设每次下注为1,那么抽到黑牌,我们就损失1,抽到红牌我们就奖励1.1,那第一种情况我们的收益就应该计算如下:
1/21.1 + 1/2(-1) = 0.05 > 0 建议下注
第二种情况,在我们已经抽了一张红牌的情况下,就只剩3张牌了,那么抽到黑牌的概率就变为2/3,抽到红牌的概率就变为1/3,那收益计算就应该变为:
1/31.1 + 2/3(-1) = -0.3 < 0 不建议下注
这里就可以看出,在某些事件发生的情况下,我们的选择就可能会发生变化,也可以延伸出我们条件概率的定义。百度百科定义如下:
条件概率是指事件A在事件B发生的条件下发生的概率。条件概率表示为:P(A|B),读作“A在B发生的条件下发生的概率”。若只有两个事件A,B,那么
\]
P(AB)就是A与B同时发生的概率。拿上面的例子来计算:第一张抽到红牌和第二张抽到红牌的概率就为(1/21/3)/(1/2) = 1/3。第一张抽到红牌和第二张抽到黑牌的概率就为(1/22/3)/(1/2) = 2/3。
假设小明最近暗恋上了同一栋楼的一个女神,为了追求女神,他观察了女神和自己的出门时间。下表列出了小明的出门时间分布(8-9点)和女神的出门时间分布(8-8:30),如果小明今天计划8:15-8:30出门,遇到女神的概率是多少?(假设同一时间段即会相遇)
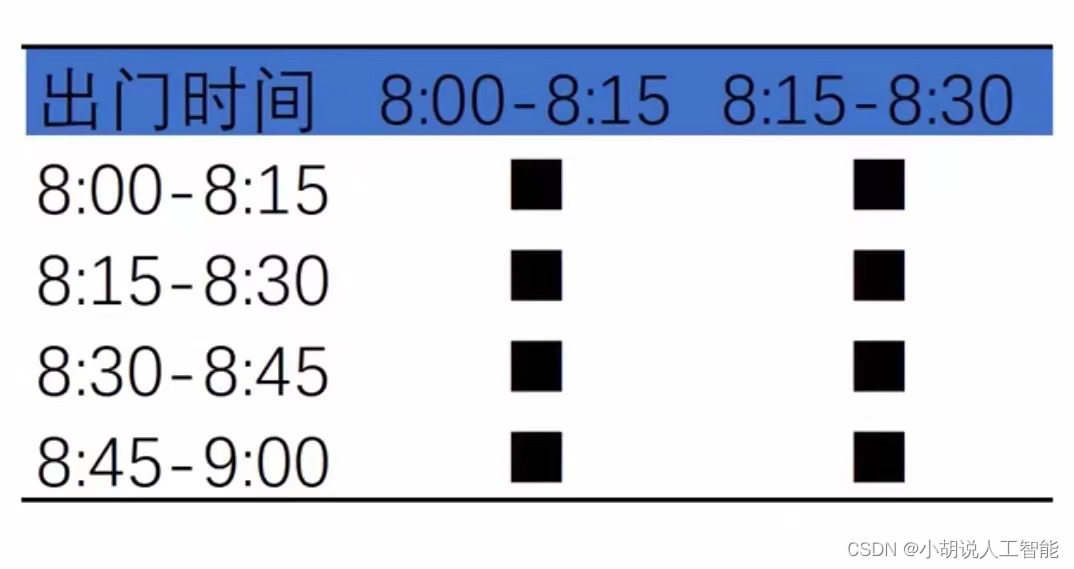 我们用条件概率的定义公式,就可以很简单计算如下:
我们用条件概率的定义公式,就可以很简单计算如下:
1)小明出门时间可以选择4个时间段,选择8:15-8:30的概率为1/4,记为P(B);
2)女神出门时间可以选择2个时间段,选择8:15-8:30的概率为1/2,记为P(A);
3)小明在8:15-8:30出门的情况下,女神同时出门的概率为1/4*1/2 = 1/8,记为P(AB);
4)那小明计划8:15-8:30出门,遇到女神的概率我们就可以记为P(A|B),那运用公式可以计算为:P(A|B)= P(AB)/P(B) = (1/8)/(1/4) = 1/2
2.2 全概率
全概率公式为概率论中的重要公式,它将对一复杂事件A的概率求解问题转化为了在不同情况下发生的简单事件的概率的求和问题。百度百科对全概率的定义如下:
若事件A1,A2,…构成一个完备事件组且都有正概率,则对任意一个事件B,有如下公式成立:
P(B)=P(BA1)+P(BA2)+...+P(BAn)=P(B|A1)P(A1) + P(B|A2)P(A2) + ... + P(B|An)P(An).
我们举个例子来说明,如下图所示:
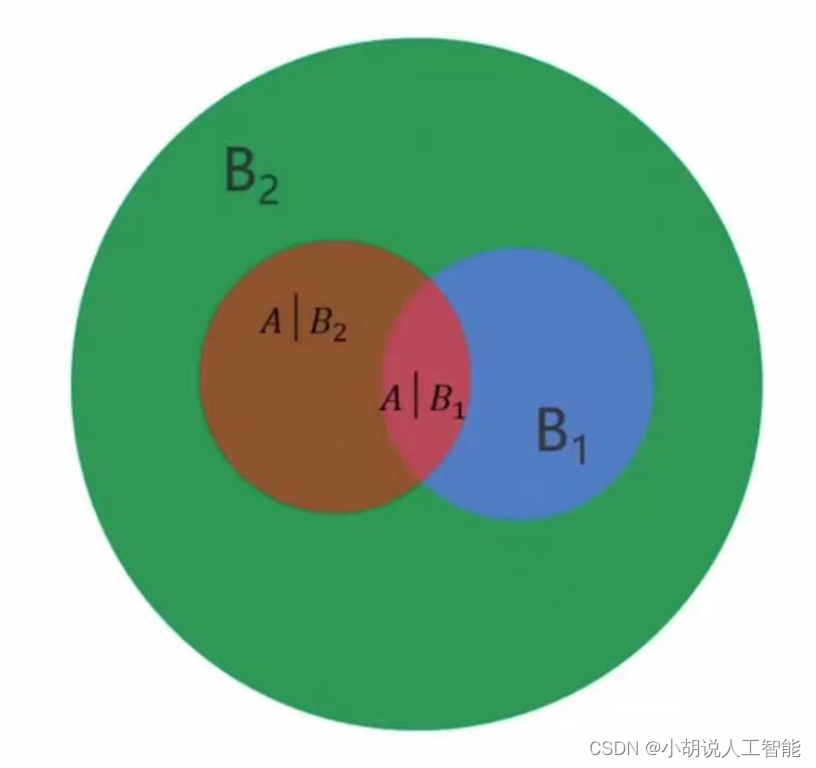 1)B1发生的情况下A发生的概率为1/4,可以记为P(A|B1)
1)B1发生的情况下A发生的概率为1/4,可以记为P(A|B1)
2)B2发生的情况下A发生的概率为1/5,可以记为P(A|B2)
3)B1发生的概率为1/3,可以记为P(B1)
4)B2发生的概率为2/3,可以记为P(B2)
那我们可以按照公司计算A发生的概率:
P(A) &=P\left(B_{1}\right) \cdot P\left(A \mid \ B_{1} \right)+P\left(B_{2}\right) \cdot P\left(A \mid \ B_{2} \right) \\
&=\frac{1}{4} \times \frac{1}{3}+\frac{1}{5} \times \frac{2}{3} \\
&=\frac{13}{60}
\end{aligned}
\]
总的来说,概率是反映随机事件出现的可能性大小的量度,而条件概率则是给定某事件A的条件下,另一事件B发生的概率。全概率公式则是利用条件概率,将复杂事件A分割为若干简单事件概率的求和问题。
三、贝叶斯公式与朴素贝叶斯
3.1. 贝叶斯公式
遇到问题找百度,我们继续通过百度百科来了解下贝叶斯公式:
贝叶斯定理由英国数学家贝叶斯 ( Thomas Bayes 1702-1761 ) 发展,用来描述两个条件概率之间的关系,比如 P(A|B) 和 P(B|A)。
按照乘法法则,可以立刻导出:P(A∩B) =P(A)P(B|A)=P(B)P(A|B)。如上公式也可变形为:P(A|B)=P(B|A)*P(A)/P(B)。
贝叶斯公式也称为贝叶斯法则, 尽管它是一个数学公式,但其原理毋需数字也可明了。如果你看到一个人总是做一些好事,则那个人多半会是一个好人。这就是说,当你不能准确知悉一个事物的本质时,你可以依靠与事物特定本质相关的事件出现的多少去判断其本质属性的概率。 用数学语言表达就是:支持某项属性的事件发生得愈多,则该属性成立的可能性就愈大。
简单来说,就是在已知一些条件下(部分事件发生的概率),实现对目标事件发生概率更准确的预测,我们接着用个例子来应用贝叶斯公式:
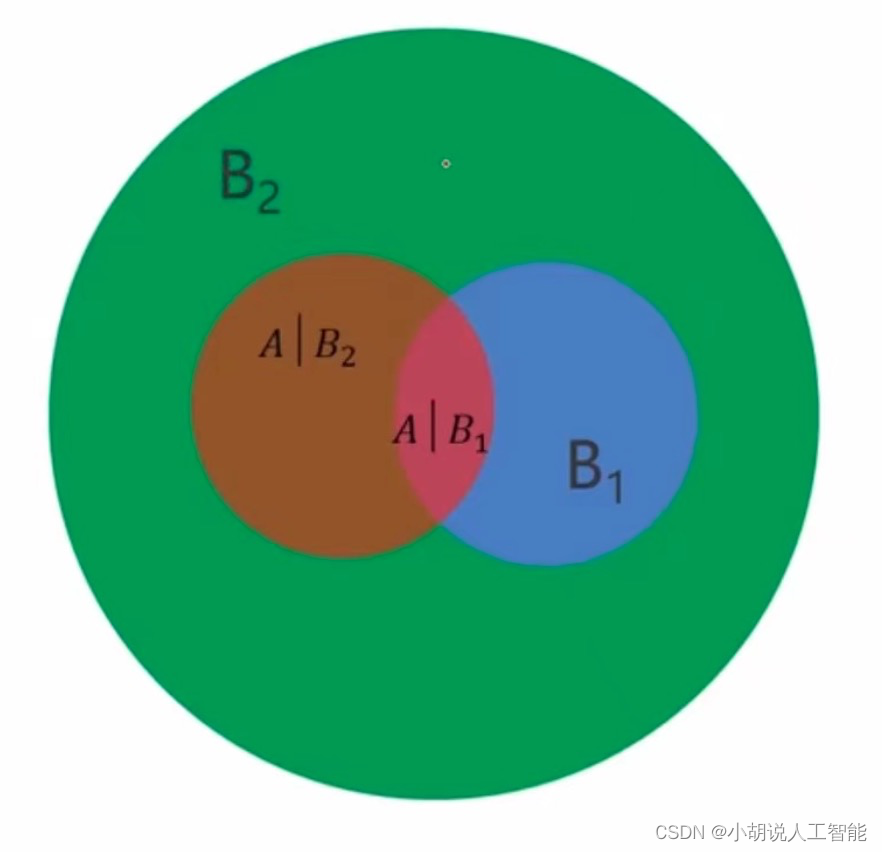 1)A发生的概率为13/60
1)A发生的概率为13/60
2)B1发生的概率为1/3
3)B1发生的情况下A发生的概率为1/4
计算A发生的情况下B1发生的概率:
P\left(B_{1} \mid A\right) &=P\left(B_{1}\right) \times \frac{P\left(A \mid B_{1}\right)}{P(A)} \\
&=\frac{1}{3} \times \frac{\frac{1}{4}}{\frac{13}{60}} \\
&=\frac{5}{13}
\end{aligned}
\]
贝叶斯公式还可以利用全概率公式延伸如下:
\]
其核心就是:基于样本信息(X)与结果分布(y)统计条件概率,再计算新样本对应的事件概率。举个例来说明:
已知:女神喜欢一个人的概率是0.1,她对喜欢的人笑的概率是0.5,她平时笑的概率是0.2,那女神对你笑,喜欢你的概率是多少?遇到问题,我们先不用慌,先定义下各个事件,然后应用公式计算
1)女神笑的概率,记为P(A);
2)女神喜欢一个人的概率,记为P(B);
3)女神对你笑的情况下,喜欢你的概率,记为P(B|A);
4)女神喜欢你的情况下,对你笑的概率,记为P(A|B);
那运用贝叶斯公式可以计算为:P(B|A)= P(B) * P(A|B) / P(A) = 0.1*0.5/0.2 = 0.25
3.2 朴素贝叶斯
定义:以贝叶斯定理为基础,假设特征之间相互独立,先通过训练数据集,学习从输入到输出的概率分布,再基于学习到的模型及输入,求出使得后验概率最大的输出实现分类。
\]
特征之间相互独立
P\left(X \mid Y=y_{i}\right)=\prod_{j=1}^{m} P\left(x_{j} \mid Y=y_{i}\right) \\
P\left(y_{i} \mid x_{1}, x_{2} \ldots, x_{m}\right)=\frac{P\left(y_{i}\right) \prod_{j=1}^{m} P\left(x_{j} \mid y_{i}\right)}{P\left(x_{1}, x_{2} \ldots, x_{m}\right)}=\frac{P\left(y_{i}\right) \prod_{j=1}^{m} P\left(x_{j} \mid y_{i}\right)}{\prod_{j=1}^{m} P\left(x_{j}\right)}
\end{gathered}
\]
这样直接看公式,大家可能看不懂,那我们用个案例来说明:
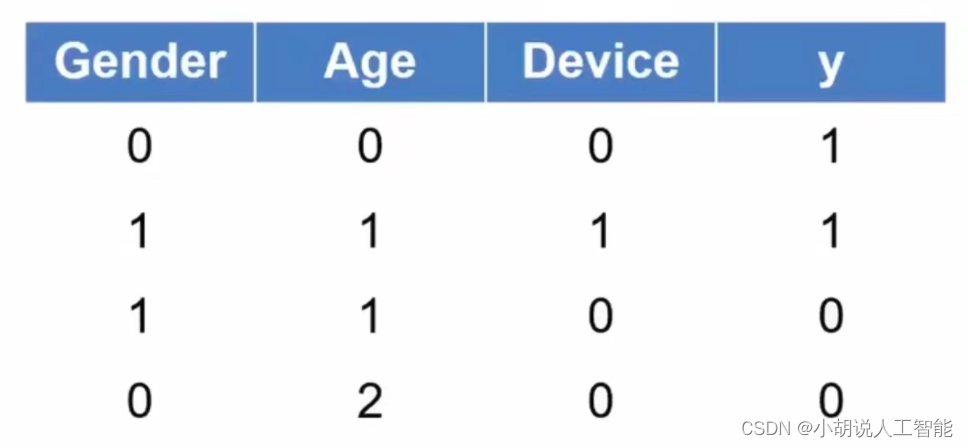
1)我们有4个样本,每个样本有Gender性别、Age年龄、Device使用设备 3个X特征;
2)每个样本有y这个label,用来表示是否会购买某个产品,会购买我们记为1,不会则记为0;
3)计算第一个样本下,y=1的概率
首先用数学的方式表述下这个问题:
1)定义 Gender为X1
2)定义Age 为X2
3)定义Device为X3
4)求解概率P(y=1|X1=0,X2=0,X3=0)
接下来就可以使用朴素贝叶斯公式来计算,具体如下:
&P(y=1)=\frac{2}{4}=\frac{1}{2} \\
&P\left(x_{1}=0 \mid y=1\right)=\frac{1}{2} \quad P\left(x_{2}=0 \mid y=1\right)=\frac{1}{2} \quad P\left(x_{3}=0 \mid y=1\right)=\frac{1}{2} \\
&P\left(x_{1}=0\right)=\frac{2}{4} \quad P\left(x_{2}=0\right)=\frac{1}{4} \quad P\left(x_{3}=0\right)=\frac{3}{4} \\
&P\left(y=1 \mid x_{1}=0, x_{2}=0, x_{3}=0\right)=\frac{P(y=1) \times\left(P\left(x_{1}=0 \mid y=1\right) \cdot P\left(x_{2}=0 \mid y=1\right) \cdot P\left(x_{3}=0 \mid y=1\right)\right)}{P\left(x_{1}=0\right) \cdot P\left(x_{2}=0\right) \cdot P\left(x_{3}=0\right)} \\
&=\frac{\frac{1}{2} \times\left(\frac{1}{2} \times \frac{1}{2} \times \frac{1}{2}\right)}{\frac{2}{4} \times \frac{1}{4} \times \frac{3}{4}}=\frac{2}{3}
\end{aligned}
\]
四、实战:Python实现朴素贝叶斯
4.1 安装python库Scikit-learn库
百度百科查询可知:Scikit-learn是GitHub上最受欢迎的机器学习库之一。Scikit-learn(以前称为scikits.learn,也称为sklearn)是针对Python 编程语言的免费软件机器学习库。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学库NumPy和SciPy联合使用。而我们也可以使用该库中的朴素贝叶斯模块CategoricalNB模块来实现朴素贝叶斯。
首先我们先来安装Scikit-learn库吧。
4.1.1 安装numpy+mkl和scipy
安装sklearn之前,需要安装两个库,即numpy+mkl和scipy。但是不要使用pip3直接在终端安装,因为pip3默安装的是numpy,而不是numpy+mkl。
下面是numpy+mkl和scipy的第三方库下载地址(里面内容较多,但是是按照首字母排序的,可以直接搜索numpy+mkl、scipy,寻找到合适的版本下载)
分别下载下载numpy+mkl和scipy的.whl文件到本地后,安装轮子工具
pip install wheel
在安装之前,首先要在终端中定位到之前下载Numpy+mkl的地址中,然后再进行安装,比如:
pip install numpy-1.22.2+mkl-cp310-cp310-win_amd64.whl
在安装之前,首先要在终端中定位到之前下载SciPy的地址中,然后再进行安装,比如:
pip install scipy-1.8.0-cp310-cp310-win_amd64.whl
4.1.2 安装Sklearn
安装完上面的numpy+mkl和scipy后,安装Sklearn比较简单,使用pip install就可以直接安装了
pip install -U scikit-learn
4.2 代码详解
我们通过下面这个用户基本信息数据集进行训练,来预测器购买商品的概率。
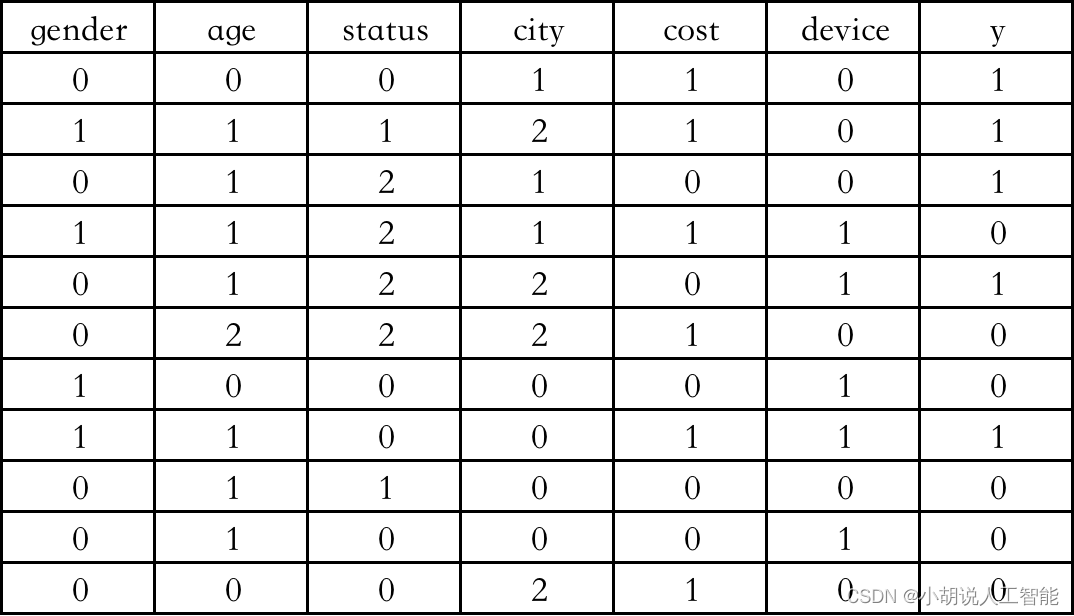 计算以下用户购买商品的概率,预测其是否会购买,具体测试样本如下:
计算以下用户购买商品的概率,预测其是否会购买,具体测试样本如下:
 这里我们可以使用scikit-learn建立一个朴素贝叶斯机器学习模型,然后使用其进行训练及预测。
这里我们可以使用scikit-learn建立一个朴素贝叶斯机器学习模型,然后使用其进行训练及预测。
使用Jupyter Notebook演示如下:
全部代码如下:
#引入关键包/模块
import pandas as pd
import numpy as np
from sklearn.naive_bayes import CategoricalNB
from sklearn.metrics import accuracy_score
#数据加载
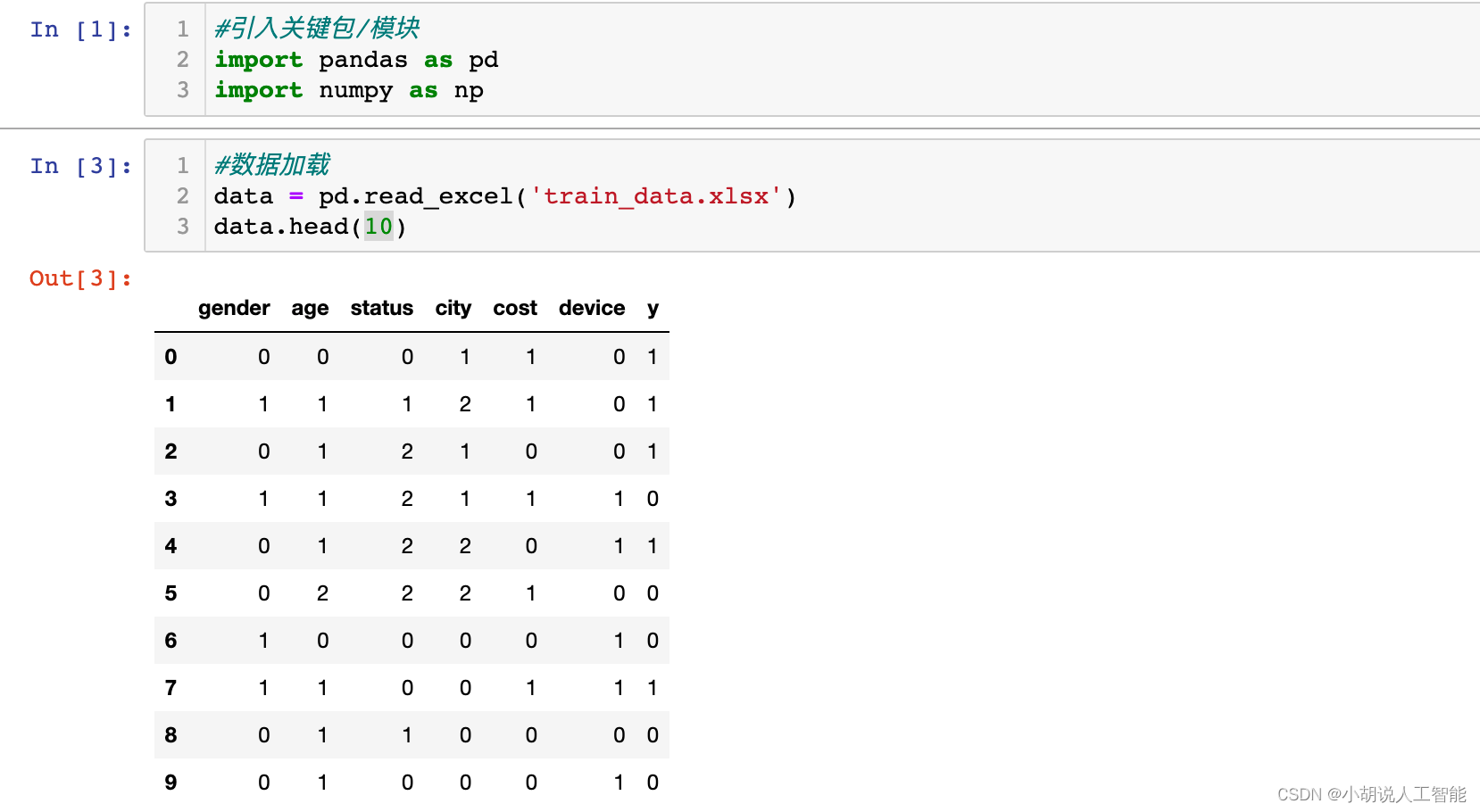
data = pd.read_excel('train_data.xlsx')
data.head(10)
# X赋值
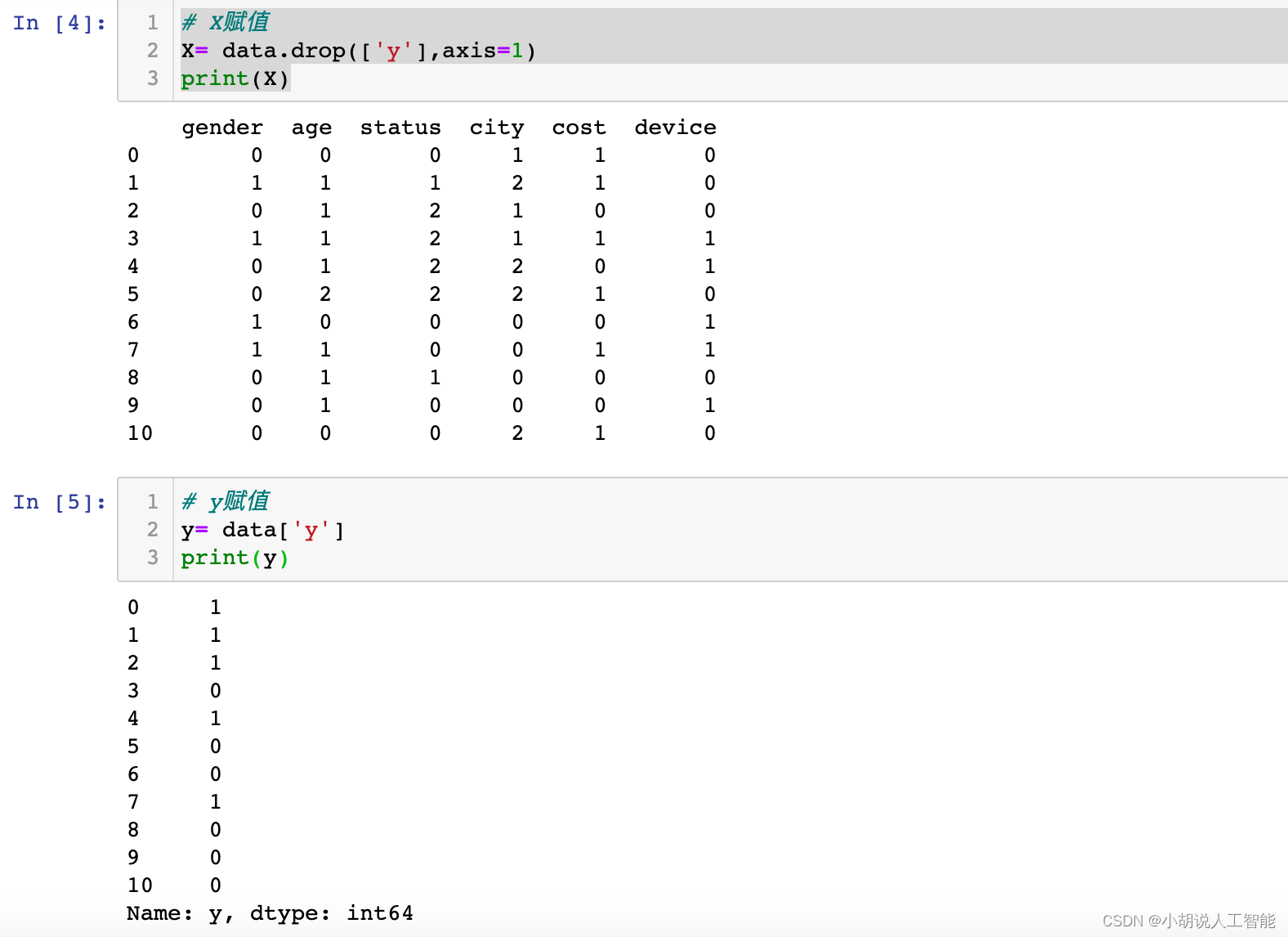
X= data.drop(['y'],axis=1)
print(X)
# y赋值
y= data['y']
print(y)
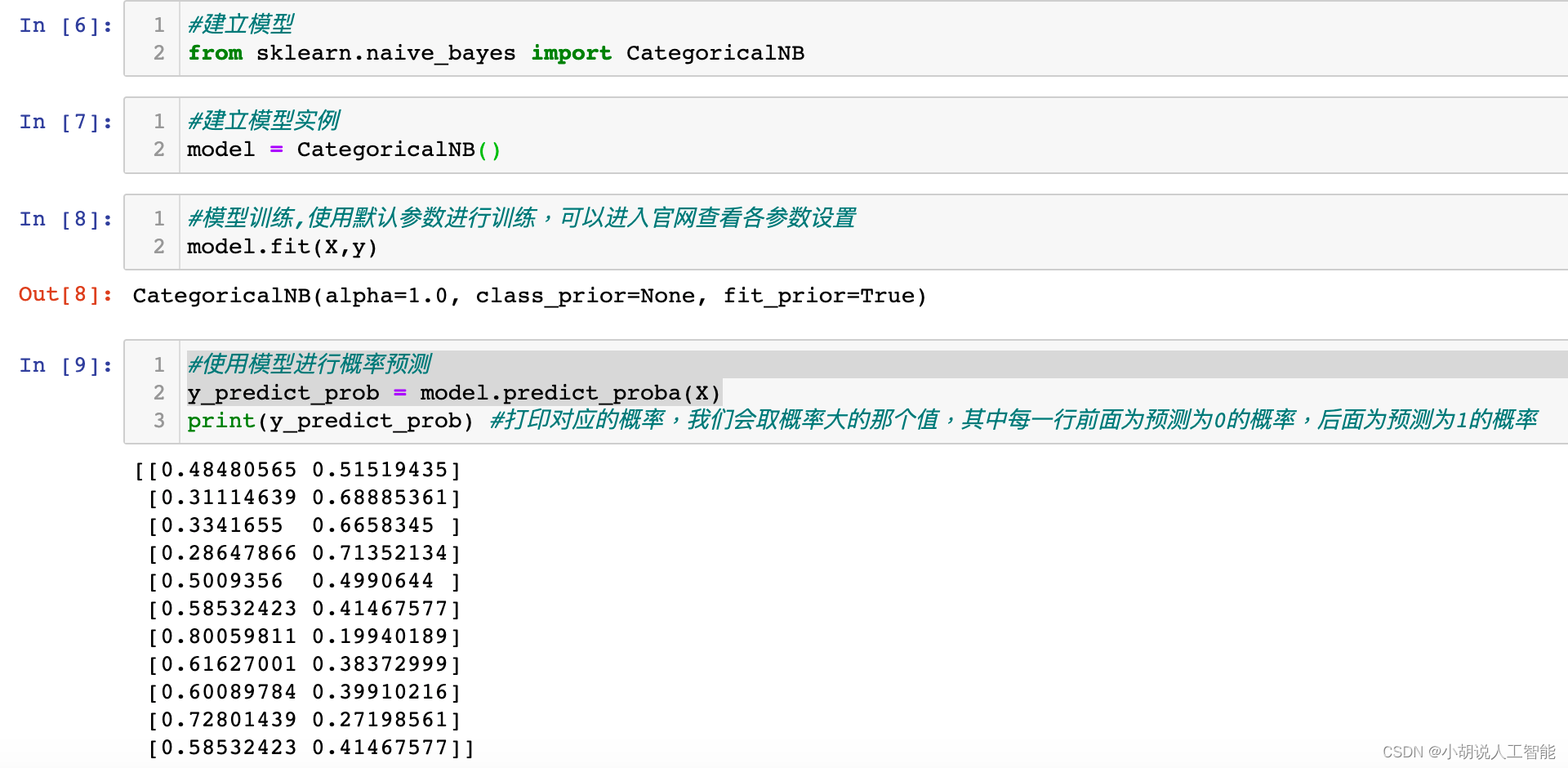
#建立模型
#建立模型实例
model = CategoricalNB()
#模型训练,使用默认参数进行训练,可以进入官网查看各参数设置
model.fit(X,y)
#使用模型进行概率预测
y_predict_prob = model.predict_proba(X)
print(y_predict_prob) #打印对应的概率,我们会取概率大的那个值,其中每一行前面为预测为0的概率,后面为预测为1的概率
#使用模型进行值预测
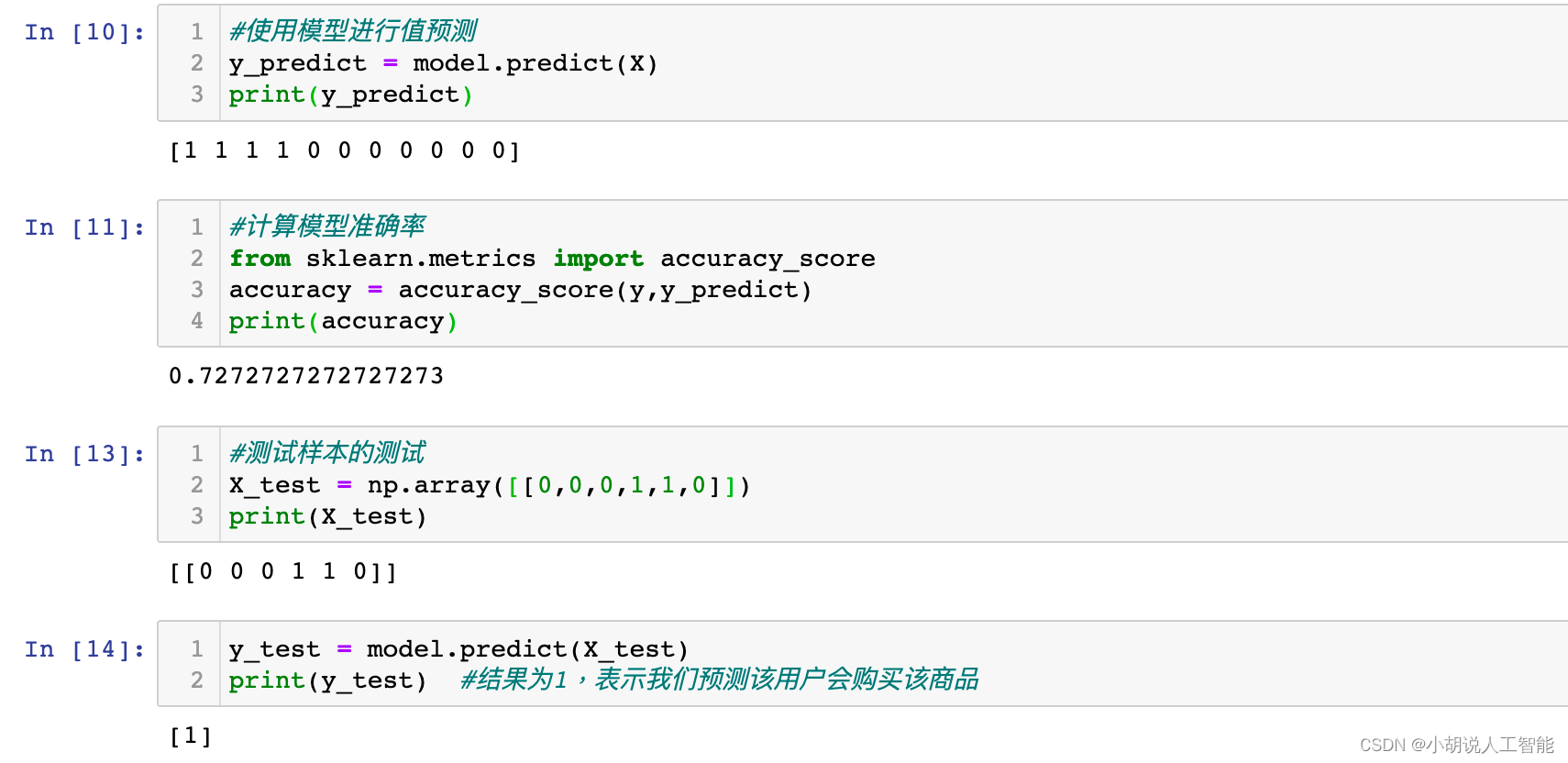
y_predict = model.predict(X)
print(y_predict)
#计算模型准确率
accuracy = accuracy_score(y,y_predict)
print(accuracy)
#测试样本的测试
X_test = np.array([[0,0,0,1,1,0]])
print(X_test)
y_test = model.predict(X_test)
print(y_test) #结果为1,表示我们预测该用户会购买该商品
总结
好啦,到这里我们就全部结束了人工智能必学数学基础三天学习了,相信从头学到尾的小伙伴们应该不会再觉得数学知识很难了吧,应该也对继续入门学习人工智能充满信心了吧。
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
欢迎大家继续支持我 关注、收藏,点赞,一键三连。如果有任何问题,也可以随时评论区留言或者私信我。
本文只供大家学习相关知识使用,不以任何商业盈利为目的,转载或分享请注明相关来源。如涉及到相关侵权,请联系我删除。
欢迎志同道合者互相交流学习,可以加我微信号:Zhihua_Steven,或者扫以下二维码关注我的微信公众号。

干货来袭!3天0基础Python实战项目快速学会人工智能必学数学基础全套(含源码)(第3天)概率分析篇:条件概率、全概率与贝叶斯公式的更多相关文章
- 再一波Python实战项目列表
前言: 近几年Python可谓是大热啊,很多人都纷纷投入Python的学习中,以前我们实验楼总结过多篇Python实战项目列表,不但有用还有趣,最主要的是咱们实验楼不但有详细的开发教程,更有在线开发环 ...
- 微信公众平台开发-OAuth2.0网页授权(含源码)
微信公众平台开发-OAuth2.0网页授权接口.网页授权接口详解(含源码)作者: 孟祥磊-<微信公众平台开发实例教程> 在微信开发的高级应用中,几乎都会使用到该接口,因为通过该接口,可以获 ...
- 原创:用python把链接指向的网页直接生成图片的http服务及网站(含源码及思想)
原创:用python把链接指向的网页直接生成图片的http服务及网站(含源码及思想) 总体思想: 希望让调用方通过 http调用传入一个需要生成图片的网页链接生成一个网页的图片并返回图片链接 ...
- Python 基于python实现的http接口自动化测试框架(含源码)
基于python实现的http+json协议接口自动化测试框架(含源码) by:授客 QQ:1033553122 欢迎加入软件性能测试交流 QQ群:7156436 由于篇幅问题,采用百度网 ...
- [干货来袭]C#6.0新特性
微软昨天发布了新的VS 2015 ..随之而来的还有很多很多东西... .NET新版本 ASP.NET新版本...等等..太多..实在没消化.. 分享一下也是昨天发布的新的C#6.0的部分新特性吧.. ...
- Python实战项目网络爬虫 之 爬取小说吧小说正文
本次实战项目适合,有一定Python语法知识的小白学员.本人也是根据一些网上的资料,自己摸索编写的内容.有不明白的童鞋,欢迎提问. 目的:爬取百度小说吧中的原创小说<猎奇师>部分小说内容 ...
- Scala实战高手****第8课:零基础实战Scala最常用数据结构Map和Tuple及Spark源码鉴赏
本课内容1.Map和Tuple在Spark源码中的鉴赏2.Map和Tuple代码操作实战 ------------------------------------------------------- ...
- python实战项目 — selenium登陆豆瓣
利用selenium 模仿浏览器,登陆豆瓣 重点: 1. 要设置好 chromedriver配置与使用, chromedriver.exe 和 Chrome的浏览器版本要对应, http://chro ...
- Spring实战(中文4,5版) PDF含源码
Spring实战 读者评价 看了一半后在做评论,物流速度挺快,正版行货,只是运输过程有点印记,但是想必大家和你关注内容,spring 4必之3更加关注的是使用注解做开发,对于初学者还是很有用,但是不排 ...
- Python之Flask项目开发【入门必学】
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:藤藤菜丶 Flask 安装Flask模块 创建一个Flask项目 运行 ...
随机推荐
- 【2020NIO.AC省选模拟#10】C. 寄蒜几盒
题目链接 原题解: 可以发现,假设我们把凸多边形看做障碍,一个点没有被染色当且仅当在它的位置上能看到凸多边形任意两条相对的边中的一条(也就是能看到至少$\dfrac{n}{2}$条边). 对于每个询问 ...
- 目前为止最完善专业的微信小程序商城
购买商业版(368元): http://market.zhenzikj.com/detail/82.html帮助文档:https://www.kancloud.cn/crmeb/crmeb/66242 ...
- 前端面试问题整理(html和css部分)
html5新增属性有哪些? 如何理解语义化标签? 你如何看待前端模块化的? 如何看待前后端分离? 浏览器兼容性问题? 你知道的行内元素.块级元素有哪些? css部分: 1.为什么要初始化css样式? ...
- Oracle添加约束
约束 -contraint Oracle中约束类型:主键约束,唯一约束,非空约束,外键约束,check约束,下述主要是alter的方法去添加约束,也可以在建表时直接添加约束 主键约束 alter ta ...
- APP性能测试——安装耗时测试
安装耗时: 这里我们用pm命令安装app,来截取安装时间(不要使用adb install安装,因为那样多一个push app的耗时). 示例代码: import os,time,datetime de ...
- std::unique_ptr release的使用
在c++中,动态内存管理是通过new/delete 运算符来进行的.由于确保在正确的时间释放内存是很困难的,为了避免内存泄漏,更加容易,安全地使用动态内存,C++11标准库提供了两种智能指针类型来管理 ...
- 【Appium_python】多进程启动时,没有设置间隔导致连接关闭,以及等待时间,导致用例未执行完成,服务提早关闭。
多进程启动多设备时,没有设置间隔时间,appium服务器以为受到远程攻击,就自动关闭连接,导致服务启动失败, 解决方法:用time.sleep设置时间间隔 也需要增加等待时间,等待其他设备用例都执行完 ...
- ArrayList 的toArray的转换数组方法的注意事项
ArrayList 的toArray的转换数组方法的注意事项 toArray()一共有两个方法 toArray(T[] a) 和toArray() 源码是 进行使用toArray()方法时候,使用 ( ...
- Java开发的事务
代码来自https://blog.csdn.net/weixin_42950079/article/details/99674292 可以看出jdbc的一个事务有这么几个步骤:1.关闭sql自动提交: ...
- 软件工程作业:个人项目—wc项目
软件工程作业:个人项目-WC项目 项目相关要求 wc.exe 是一个常见的工具,它能统计文本文件的字符数.单词数和行数.这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程 ...