测开-面试题-Java基础
1 垃圾回收机制?
答:
一、手动垃圾回收机制(C/C++)
手动:使用过的对象必须要程序员自己来回收
缺点:
1、若程序员忘记及时回收——对象会一直在内存中,若程序运行时间很长,内存中存在大量垃圾,空间越来越满,之后创建的对象没有内存可用——>导致内存泄漏、降低系统性能
2、程序员自己回收可能存在误收操作——导致系统崩溃
二、自动垃圾回收机制(Java)
1、垃圾回收机制(GC):通过自动垃圾回收算法对堆内存中 new出的且不再被引用的对象 进行回收
2、垃圾回收机制如何判断对象是否还有用?
检查堆内存中空间是否充裕:
足够,则不回收
不足,通过算法检查是否有 已创建 且长时间未被引用的对象——>若长时间未被引用 且急需创建新的对象,垃圾回收机制就会将这些对象定为垃圾,会优先将这部分空间进行回收
3、垃圾回收机制在回收任何对象之前,总会先自动调用 finalize()方法(自动调用,不由程序员调用),调用该方法可以在垃圾回收同时打印日志等操作
注:finalize可以用来清理不是new出的对象所占用的内存,可以用来清理本地对象
本地对象:指的是在Java中调用非Java代码(C/C++)时创建的对象
下面是我在一次面试中面试官问到我的问题,大家也可以看下~
final、finally、finalize的区别
final:修饰符,被final修饰的变量不能被修改,被final修饰的方法不能被重写,被final修饰的类不能被继承
finally:在异常处理时,用于最终进行收尾工作的代码块
finalize:Object中提供的方法,用于垃圾回收之前自动被垃圾回收器调用的方法
对象在内存中的状态转换【具体内容我们在下期分享】
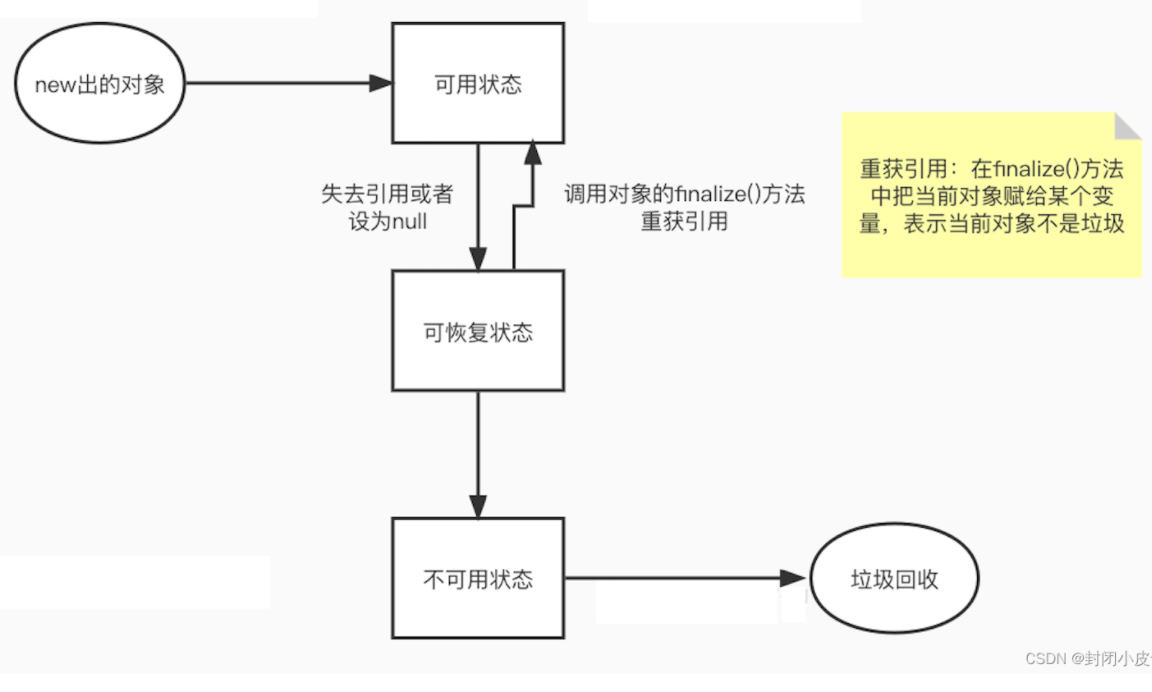
4、触发垃圾回收的条件
当没有线程在运行时,垃圾回收会被调用。因为垃圾回收在优先级最低的线程中进行,当应用忙时,垃圾回收不被调用(不是由程序员自己调用的),但除第二点
堆内存不足时会触发垃圾回收机制。
自动回收机制——>程序员无法精确控制垃圾回收的执行,可以通过System.gc() 或 Runtime.getRuntime().gc() 来通知JVM进行垃圾回收,但系统是否进行垃圾回收依旧不确定
5、Java中释放资源与垃圾回收机制的区别
垃圾回收只能释放内存中的资源,不能释放与内存无关的资源
垃圾回收具有不确定性,程序员无法精确控制垃圾回收的执行,没有确定的回收时间
IO流资源不能被GC直接释放(IO流使用了虚拟机之外的资源,所以虚拟机无法通过垃圾回收释放资源),但可以通过finalize方法释放。该方法防止程序员忘记需要手动释放资源——依旧需要手动调用close方法释放资源。
上述说到finalize方法执行在垃圾回收机制之前,但垃圾回收机制具有不确定性,不确定什么时候进行垃圾回收。所以finalize方法无法保证对 手动需要释放的资源 进行及时回收。
6、减少GC垃圾回收开销
尽量不要显式调用System.gc()
会增加GC的频率,但不能保证清除所有垃圾。GC也是一个线程,会消耗资源,可能会造成间歇性停顿次数(运行时是间歇进行的)。
7、GC的一个安全点:用户执行比较长的一段时间,让它到达一个安全点来进行gc。
安全点是在固定时间让用户停顿嘛?
答:
分为两种:抢占式、响应式;
2 SpringBoot的好处?
答:
一、独立运行:Spring Boot内嵌了各种servlet容器,Tomcat、Jetty等,现在不再需要打成war包部署到容器中,Spring Boot只要打成一个可执行的jar包就能独立运行,所有的依赖包都在一个jar包内。
二、简化配置:spring-boot-starter-web启动器自动依赖其他组件,简少了maven的配置。
三、自动配置:Spring Boot能根据当前类路径下的类、jar包来自动配置bean,如添加一个spring-boot-starter-web启动器就能拥有web的功能,无需其他配置。
四、无代码生成和XML配置:Spring Boot配置过程中无代码生成,也无需XML配置文件就能完成所有配置工作,这一切都是借助于条件注解完成的,这也是Spring4.x的核心功能之一。
3 Java中的map有没有了解?
答:
【1】Map使用场景(动态查找时)
Map是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。对于静态类型的查找来说,一般直接遍历或者用二分查找【不会对区间进行插入和删除操作】
而在现实生活中的查找比如:
1.根据姓名查询考试成绩
2.通讯录,即根据姓名查询联系方式
3.不重复集合,即需要先搜索关键字是否已经在集合中
以上等可能在查找时进行一些插入和删除的操作,即动态查找,就需要用Map进行一系列操作。
注:Map最重要的特性就是去重!
【2】概念
Map是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复。
<K,V>使用的是 key-value模型:
key-value 模型中 key 和 value 是一个整体。key-value模型就是类似于这样的一组组合。【key 和 value 互相修饰】
Map使用时一些注意点:
Map是一个接口,不能直接实例化对象,如果要实例化只能实例化其实现类TreeMap或者HashMap。
Map 中存放键值对的 Key 是唯一的, value 是可以重复的
Map 中的 Key 可以全部分离出来,存储到 Set 中 来进行访问 ( 因为 Key 不能重复 ) 。
Map 中的 value 可以全部分离出来,存储在 Collection 的任何一个子集合中 (value 可能有重复 ) 。
Map 中键值对的 Key 不能直接修改, value 可以修改,如果要修改 key ,只能先将该 key 删除掉,然后再来进行重新插入。
【3】Map 的常用方法
V get(Object key) 返回 key 对应的 value
V getOrDefault(Object key, V defaultValue) 返回 key 对应的 value,key 不存在,返回默认值
V put(K key, V value) 设置 key 对应的 value
V remove(Object key) 删除 key 对应的映射关系
Set<K> keySet() 返回所有 key 的不重复集合
Collection<V> values() 返回所有 value 的可重复集合
Set<Map.Entry<K, V>> entrySet() 返回所有的 key-value 映射关系
boolean containsKey(Object key) 判断是否包含 key
boolean containsValue(Object value) 判断是否包含 value
4 webservice接口有用过吗?
答:
有。在学校做过一个项目——和风天气,做客户端开发的时候,使用webservice接口进行远程调用天气预报WebService服务。
WebService是一种跨编程语言和跨操作系统平台的远程调用技术。
5 String、StringBuffer、StringBuilder?
答:
同-
平台提供两种类型的字符串:string和StringBuffer/StringBuilder,都可以存储和操作字符串。
异-
string 只读字符串,其字符串内容不能被改变。
StringBuffer/StringBuilder 是字符串对象,可直接进行修改;底层原理 底层是数组,当数组存储满时,会开辟一个新的更长的数组,将原先的数据转存至新数组后继续追加。
StringBuffer 1.0出现 效率低线程安全
StringBuilder 1.5出现 效率高线程不安全
5.1 String类的底层实现?
5.2 String类为什么设置成不可变?
5.3 String底层的char数组怎么做到数组中的值不可变的?
6 如何判断bug是前端还是后端?
7 面向对象特征?
答:
封装-复用性
继承-复用性
多态-可移植性,健壮性
8 ArrayList、LinkList?
答:
arraylist-数组存储,访问数据方便
linklist-链存储,指针指向下一个数据,更新数据快
优化链表查询复杂度:
9 JDK1.8 新特性?
答:
(1)接口的默认方法:Java 8允许我们给接口添加一个非抽象的方法实现,只需要使用default关键字即可,这个特征又叫做扩展方法。
(2)Lambda表达式
(3)函数式接口
(4)方法与构造函数引用:Java 8允许你使用:关键字来传递方法或者构造函数引用,上面的代码展示了如何引用一个静态方法,我们也可以引用一个对象的方法。
(5)Lambda作用域:在lambda表达式中访问外层作用域和老版本的匿名对象中的方式很相似。你可以直接访问标记了final的外层局部变量,或者实例的字段以及静态变量。
(6)访问局部变量:我们可以直接在lambda表达式中访问外层的局部变量。
(7)访问对象字段与静态变量:和本地变量不同的是,lambda内部对于实例的字段以及静态变量是即可读又可写。该行为和匿名对象是一致的。
(8)访问接口的默认方法
(9)支持多重注解
10 抽象类、接口区别?
答:
抽象类-可以定义
构造器
抽象方法和具体方法
类中成员全是public
成员变量
可包含静态方法
只能继承一个抽象类
有抽象方法的类必须被声明为抽象类,而有抽象类不一定有抽象方法
接口-
不能定义构造器
只能有抽象方法
类中成员可以是private 默认 public protected
接口中定义的成员变量就是常量
不能有静态方法
可实现多个接口
语义区别:
抽象类是我们可以得出具体概念的,比如猫狗类
接口描述某一类事务的特征,如会飞会跑(Java 接口是一系列方法的声明,是一些方法特征的集合,一个接口只有方法的特征没有方法的实现,因此这些方法可以在不同的地方被不同的类实现,而这些实现可以具有不同的行为(功能)。)
11 hashcode、equals如何使用?
答:
hashcode-求哈希值
equals-进行比较
本题底层原理-问hashmap:
hashmap是按照键值一一对应存储的,先根据key用hashcode方法计算出hashcode值,再根据hashcode值得出该数据在底层数组中存储位置;
当冲突时(也就是两个数据hashcode值相等时),二者使用equals方法进行比较,相等就不存入,若不相等就链接在后面(前七后八)。
hashmap线程安全嘛??
答:
不是线程安全的。
解析:
hashtable是线程安全带,为什么后面又造了个concurrentHashMap??
答:
因为hashtable加锁很粗暴,加的这个锁粒度很大,所以就出了concurrentHashMap,concurrentHashMap在1.7、1.8的时候依旧是在做锁粒度的细化。
12 Java代理(Spring AOP)?
答:
静态代理-弱,代理方法、类
动态代理
-proxy代理(JDK内置动态代理),借助反射实现。通过接口,接口里的方法不能用final修饰。
-cglib动态代理,借助asm实现。通过子类代理,子类也无法重写final修饰的方法。
13 “==”、“equals”区别?
答:
==-基本数据类型、对象的地址
equals-字符串、对象
14 异常处理机制?
答:
异常抛出-throw(方法内部用)
异常捕获-try,catch,finally(无论是否异常都执行)
声明异常-throws(方法声明处用)
. 重写、重载区别?
答:
重载-
overload,
同一个类中,
方法名同,形参列表方法体不同。
重写-
override,
子类对父类继承,进而重写父类中的方法,
方法名形参同,方法体不同,
子类抛出异常≤父类,
父类权限修饰符<子类,
父类返回值类型>子类。
16 如何声明一个类不被继承?声明场景下使用?
答:
被final修饰的类不能有子类,
若一个类中的方法没有被重写的必要就可用,如Math类(因math构造方法由private修饰,所以math不能被new(创建具体对象),其中的方法用static修饰,所以可直接用 类名.方法名/属性名 进行调用)
Java中的String、Integer都会用final修饰,原因??
答:
17 自定义异常在生产中如何使用?
答:-系统中某些错误符合JAVA语法,但不符合业务逻辑
-在分层软件结构中,在表现层统一对系统其他层的异常进行捕获处理
18 Https的加密算法?
答:
对称加密,双方用同一把秘钥加密:DES,AES算法。
非对称加密:公钥加密,私钥解密,公钥公开,私钥私藏。A拿着B的公钥加密给B,B用私钥解密。
19 什么是类加载?
答:
java虚拟机将编译后的class文件加载到内存中,进行校验、转换、解析和初始化,每一个类都会在方法区保存一份它的元数据,在堆中创建一个与之对应的Class对象。到最终的使用。这就是java类加载机制。
19.1 类加载过程?
答:
JAVA类的加载过程:
在Run的时候,先将.java文件编译成.class文件。然后,在通过类加载器,将class文件加载到JVM中,然后在运行。输出结果。
类加载的生命周期包括:
加载Loading,验证Verification, 准备Preparation,解析Resolution, 初始化Initialization,使用Using和卸载Unloading.
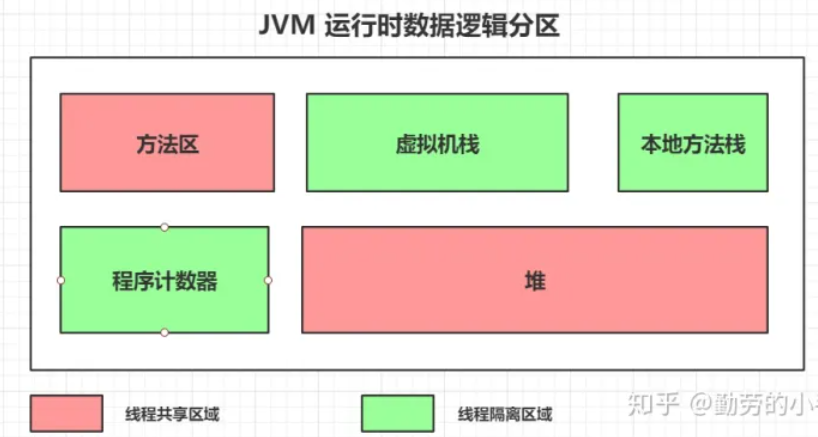
19.2 JVM内存结构划分?
答:
JVM的内存结构大致分为五个部分,分别是程序计数器、虚拟机栈、本地方法栈、堆和方法区。除此之外,还有由堆中引用的JVM外的直接内存。
19.3 jvm内存区域?
答:
根据各种数据的特性JVM从逻辑上把内存划分成了几个区域;分别为方法区、虚拟机栈、本地方法栈、程序计数器、堆 5个区域。
20 Java ee/se/me区别?
答:

Java 技术 = Java 语言 + Java 平台
Java 平台 = JVM + JDK
Java SE = JDK 根基
Java EE,JavaSE,JavaFX 是 Java SE 的扩展
简单点说
Java SE 是做电脑上运行的软件。
Java EE 是用来做网站的-(我们常见的JSP技术)
Java ME 是做手机软件的。
Java SE 全称(Java Platform,Standard Edition)以前称为 J2SE。它允许开发和部署在桌面、服务器、嵌入式环境和实时环境中使用的 Java 应用程序,包含了支持 Java Web 服务开发的类,为(Java EE)提供基础。
Java EE 全称(Java Platform,Enterprise Edition)这个版本以前称为 J2EE。企业版帮助开发和部署可移植、健壮、可伸缩且安全的服务器端 Java 应用程序。Java EE 是在 Java SE 的基础上构建的,它提供 Web 服务、组件模型、管理和通信 API,可以用来实现企业级的面向服务体系结构(service-oriented architecture,SOA)和 Web 2.0 应用程序。
Java ME 全称(Java Platform,Micro Edition)这个版本以前称为 J2ME。为在移动设备和嵌入式设备(比如手机、PDA、电视机顶盒和打印机)上运行的应用程序提供一个健壮且灵活的环境。包括灵活的用户界面、健壮的安全模型、许多内置的网络协议以及对可以动态下载的连网和离线应用程序的丰富支持。基于 Java ME 规范的应用程序只需编写一次,就可以用于许多设备,而且可以利用每个设备的本机功能。
20 jdk jre区别?
答:
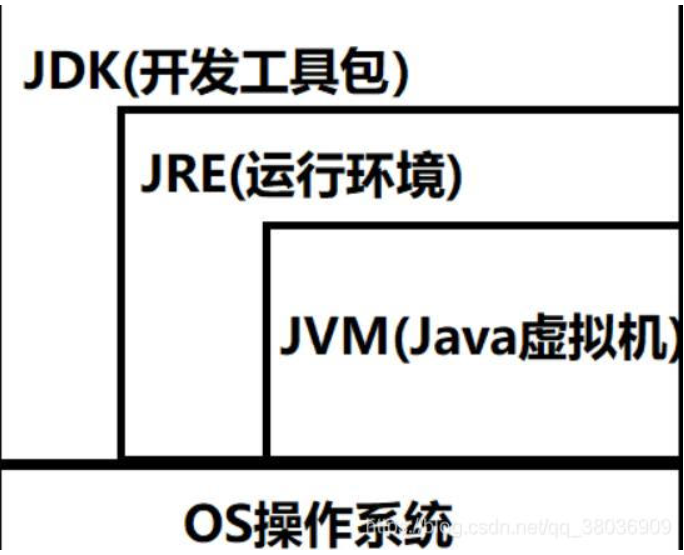
(1)JDK
JDK:Java Development Kit 是Java的标准开发工具包(普通用户只需要安装 JRE来运行 Java 程序。而程序开发者必须安装JDK来编译、调试程序)。它提供了编译、运行Java程序所需的各种工具和资源,包括Java编译器、Java运行环境JRE,以及常用的Java基础类库等,是整个JAVA的核心。
JDK一般有三种版本:
SE(J2SE),standard edition,标准版,是我们通常用的一个版本 EE(J2EE),enterpsise edtion,企业版,使用这种JDK开发J2EE应用程序, ME(J2ME),micro edtion,主要用于移动设备、嵌入式设备上的java应用程序 (相对来说现在使用的很少了)
(2)JRE
JRE:Java runtime environment 是运行基于Java语言编写的程序所不可缺少的运行环境,用于解释执行Java的字节码文件。
也是通过它,Java的开发者才得以将自己开发的程序发布到用户手中,让用户使用。JRE中包含了Java virtual machine(JVM),runtime class libraries和Java application launcher,这些是运行Java程序的必要组件。与大家熟知的JDK不同,JRE是Java运行环境,并不是一个开发环境,所以没有包含任何开发工具(如编译器和调试器),只是针对于使用Java程序的用户。
(3)JVM
JVM:Java Virtual Machine 是Java的虚拟机,是JRE的一部分。它是整个java实现跨平台的最核心的部分,负责解释执行字节码文件,是可运行java字节码文件的虚拟计算机。
所有平台的上的JVM向编译器提供相同的接口,而编译器只需要面向虚拟机,生成虚拟机能识别的代码,然后由虚拟机来解释执行。
21 Java常用命令?
答 :
appletviewer:
这个命令是的作用就是帮助我们查看applet小程序。
javac:
这个命令我们初学的时候很经常用,但是我们只是用到了很基础的部分,有些额外的选项还是值得我们去利用的。
java:
java是用来执行class文件的,若你的类中没有可以执行的main方法,就不能执行了。
jar:
jar命令主要是用于打jar包,很多人很说用c或者c++可以生成exe文件,双击就运行,用这个命令生成jar后,也可以双击运行,只不过前提是你必须配置了java的运行环境。
javadoc:
javadoc命令主要是生成帮助文档。
javah:
这个命令主要是用于生成头文件,可以用于jni,即是在java中调用c或者c++的代码。
javap:
这个命令是反编译器,显示编译类中可以访问的方法和数据。
22 java的数据类型以及应用场景?
答:
基本数据类型分成四个大类
1、整型:byte 、short 、int 、long
由上可以看出 byte、short 的取值范围比较小,而long的取值范围最大的,所以占用的空间也是最多的。int 取值范围基本上可以满足我们的日常计算需求了。
2、浮点型:float 、 double
double 类型比float 类型存储范围更大,精度更高。一般用于金融行业或者和钱有关的业务。
3、字符型:char
4、布尔型:boolean
boolean 型只有两个取值 true 和 false;它的默认值是 false。
类型名称 字节空间 使用场景
byte 1字节(8位) 储存字节数据
short 2字节(16位) 兼容性考虑
int 4字节(32位) 储存普通整数
long 8字节(64位) 储存长整数
float 4字节(64位) 存储浮点数
double 8字节(64位) 存储双精度浮点数
char 2字节(16位) 存储一个字符
boolean 1字节(8位) 存储逻辑变量(true,false)
23 java的语法?
答:
关键字不能用作变量名,方法名,类名,包名和参数。
保留字定义:现在java尚未使用,但以后版本可能会作为关键字使用。自己使用时应避免使用。
标识符:
凡是可以自己命名的地方都叫标识符。例如:包名,类名,方法等。
定义合法标识符规则
1.有26个英文字母大小写,0-9,_或$组成。
2.不能以数字开头。
3.不可以使用关键字和保留字,但能包含关键字和保留字。
4.严格区分大小写。
5.标识符不能包含空格。
java中的名称命名规范
1.包名:多单词组成时所有字母都小写:xxxyyyzzz
2.类名、接口名:多单词组成时,所有单词的首字母大写:XxxYyyZzz
3.变量名、方法名:多单词组成时,第一个单词首字母小写,第二个单词开始每个单词首字母大写:xxxYyyZzz
4.常量名:所有字母都大写。多单词时每个单词用下划线连接:XXX_YYY_ZZZ
运算符优先级
程序流程控制
特殊关键字continue、break ......
24 java泛型?
答:
1. 什么是泛型
泛型:是一种把明确类型的工作推迟到创建对象或者调用方法的时候才去明确的特殊的类型。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,而这种参数类型可以用在类、方法和接口中,分别被称为泛型类、泛型方法、泛型接口。
注意:一般在创建对象时,将未知的类型确定具体的类型。当没有指定泛型时,默认类型为Object类型。
2.为什么使用泛型
泛型的第一作用:起到约束和规范的作用,约束类型属于某一个,规范使用只能用某一种类型。可以让我们业务变得更加清晰和明了并得到了编译时期的语法检查。
泛型的第二作用:使用泛型的类型或者返回值的方法,自动进行数据类型转换。
3. 使用泛型的好处
避免了类型强转的麻烦。
它提供了编译期的类型安全,确保在泛型类型(通常为泛型集合)上只能使用正确类型的对象,避免了在运行时出现ClassCastException。
4. 泛型的使用
泛型虽然通常会被大量的使用在集合当中,但是我们也可以完整的学习泛型只是。泛型有三种使用方式,分别为:泛型类、泛型方法、泛型接口。将数据类型作为参数进行传递。
4.1 泛型类
泛型类型用于类的定义中,被称为泛型类。通过泛型可以完成对一组类的操作对外开放相同的接口。最典型的就是各种集合框架容器类,如:List、Set、Map。
泛型类的定义格式:
修饰符 class 类名<代表泛型的变量> { }
......
25 说一下stream?
答:
Stream是Java 8 API添加的一个新的抽象,称为流Stream,以一种声明性方式处理数据集合(侧重对于源数据计算能力的封装,并且支持序列与并行两种操作方式)
Stream流是从支持数据处理操作的源生成的元素序列,源可以是数组、文件、集合、函数。流不是集合元素,它不是数据结构并不保存数据,它的主要目的在于计算
Stream流是对集合(Collection)对象功能的增强,与Lambda表达式结合,可以提高编程效率、间接性和程序可读性。
特点
1、代码简洁:函数式编程写出的代码简洁且意图明确,使用stream接口让你从此告别for循环
2、多核友好:Java函数式编程使得编写并行程序如此简单,就是调用一下方法
流程
1、将集合转换为Stream流(或者创建流)
2、操作Stream流(中间操作,终端操作)
stream流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果
26 Maven?
答:
1、什么是Maven
Maven是项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的项目管理工具软件
Maven除了以程序构建能力为特色之外,还提供高级项目管理工具。由于Maven的缺省构建规则有较高的可重用性,所以常常用两三行Maven构建脚本就可以构建简单的项目。
Maven是项目进行模型抽象,充分利用的面向对象的思想,maven可以通过一小段描述信息来管理项目的构建,报告和文档的软件项目管理工具。Maven除了以程序构建能力为特色之外,还提供高级项目管理工具。由于maven的缺省规则有较高的可重用性,所以常常用两三行maven构建脚本就可以构建简单的项目
2、maven的作用
maven对项目的第三方构建(jar包)进行统一管理。向工程中加入jar包不要手工从其他地方拷贝,通过maven定义jar包的坐标,自动从maven仓库中下载到工程中
maven提供一套对项目生命周期管理的标准,开发人员和测试人员统一使用maven进行项目构建。项目生命周期管理:编译、测试、打包、部署、运行
maven对工程分模块构建,提高开发效率
26.1 maven常用命令?
答:
compile是maven工程的编译命令,作用是将src/main/java下的文件编译为class文件输出到target目录下。
test是maven工程的测试命令 mvn test,会执行src/test/java下的单元测试类。
clean是maven工程的清理命令,执行 clean会删除target目录及内容。
package是maven工程的打包命令,对于java工程执行package打成jar包,对于web工程打成war包。
install是maven工程的安装命令,执行install将maven打成jar包或war包发布到本地仓库。
26.2 maven怎么解决版本冲突?
答:
1、第一声明优先原则
在pom.xml配置文件中,如果有两个名称相同版本不同的依赖声明,那么先写的会生效。
所以,先声明自己要用的版本的jar包即可。
所以,添加新依赖时要放在最后边,以防止新依赖替换原有依赖造成版本冲突。
2、路径近者优先
直接依赖优先于传递依赖,如果传递依赖的jar包版本冲突了,那么可以自己声明一个指定版本的依赖jar,即可解决冲突。
3、排出原则
传递依赖冲突时,可以在不需要的jar的传递依赖中声明排除,从而解决冲突。
4、版本所定原则(最常用)
在配置文件pom.xml中先声明要使用哪个版本的相应jar包,声明后其他版本的jar包一律不依赖。解决了依赖冲突。
5、查看jar包的间接依赖
如果发现某个jar包,自己的pom中并没有定义,想看一下是被哪个jar包间接引用的,执行以下命令,直接输出到当前项目下,然后在idea中打开,搜索要找的jar包名字即可。这里的 “±” 和"-"并没有什么意义,只是为了让分级看起来更直观。
6、排包
26.2 maven怎么统一管理版本号?
答:
方案一:mvn -Denv.project.version=1.0-env
方案二 maven的profile+自定参数变量
方案三(推荐) mvn versions:set -DnewVersion=1.0-dev
27 git常用命令?
答:
7.常用git 命令
git init // 初始化 在工作路径上创建主分支
git clone 地址 // 克隆远程仓库
git clone -b 分支名 地址 // 克隆分支的代码到本地
git status // 查看状态
git add 文件名 // 将某个文件存入暂存区
git checkout -- file // 撤销工作区的修改 例如git checkout -- readMe.txt 将本次readMe.txt在工作区的修改撤销掉
git add b c //把b和c存入暂存区
git add . // 将所有文件提交到暂存区
git add -p 文件名 // 一个文件分多次提交
git stash -u -k // 提交部分文件内容 到仓库 例如本地有3个文件 a b c 只想提交a b到远程仓库 git add a b 然后 git stash -u -k 再然后git commit -m "备注信息" 然后再push push之后 git stash pop 把之前放入堆栈的c拿出来 继续下一波操作
git commit -m "提交的备注信息" // 提交到仓库
28 mybatis plus的使用以及优点?
答:
MybatisPlus:
1.Mapper层和service层继承并且封装了大部分简单的CRUD操作,通过少量的配置就可以直接实现CRUD操作
2.提供了简单的CRUD操作,不需要程序员手动的去编写sql语句
3.自动解析实体关系映射转换为MyBatis内部对象注入容器
4.支持Lambda语句的使用
5.MybatisPlus通过的条件构造器可以实现复杂的业务需求
MyabtisPlus的优点:
1.简单的单表查询的CRUD操作不需要手动去编写sql语句,可直接通过少量配置来调用方法实现
2.内置分页插件:基于 Mybatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通List查询。
3.支持代码的生成,可通过代码来自动快速生成 Mapper 、 Model 、 Service 、 Controller 层代码
4.仅仅依赖 Mybatis 以及 Mybatis-Spring
缺点:
1.如果要实现多表联查的业务需求,会比mybatis更加的复杂
2.项目引入第三方插件包,未来升级有一定的兼容性问题。
29 spring和springboot的区别?
答:
二者主要区别是:
1、Spring Boot提供极其快速和简化的操作,让 Spring 开发者快速上手。
2、Spring Boot提供了 Spring 运行的默认配置。
3、Spring Boot为通用 Spring项目提供了很多非功能性特性。例如:嵌入式 Serve、Security、统计、健康检查、外部配置等等。
(1)Spring:
框架为开发Java应用程序提供了全面的基础架构支持。它包含一些很好的功能,如依赖注入和开箱即用的模块,如:Spring JDBC 、Spring MVC 、Spring Security、 Spring AOP 、Spring ORM 、Spring Test,这些模块缩短应用程序的开发时间,提高了应用开发的效率。例如,在Java Web开发的早期阶段,我们需要编写大量的代码来将记录插入到数据源中。但是通过使用Spring JDBC模块的JDBCTemplate,我们可以将这操作简化为只需配置几行代码。
(2)springboot:
SpringBoot是Spring框架的扩展,是一个在spring基础上进行简化配置和开发流程的web整合的轻量级框架,可以更快更高效地开发生态系统,使开发,测试和部署更加方便。S
SpringBoot的优势在于以下两个特点:
① 约定大于配置
SpringBoot定义了项目的基本骨架,例如各个环境的配置文件统一放到resource中,使用active来启用其中一个。配置文件默认为application.properties,或者yaml、yml都可以。
② 自动装配
以前在Spring使用到某个组件的时候,需要在xml中对配置好各个属性,之后被Spring扫描后注入进容器。
而有了SpringBoot后,我们仅仅需要引入一个starter,就可以直接使用该组件,如此方便、快捷,得益于自动装配机制。
30 springboot怎么做到的自动装配?
答:
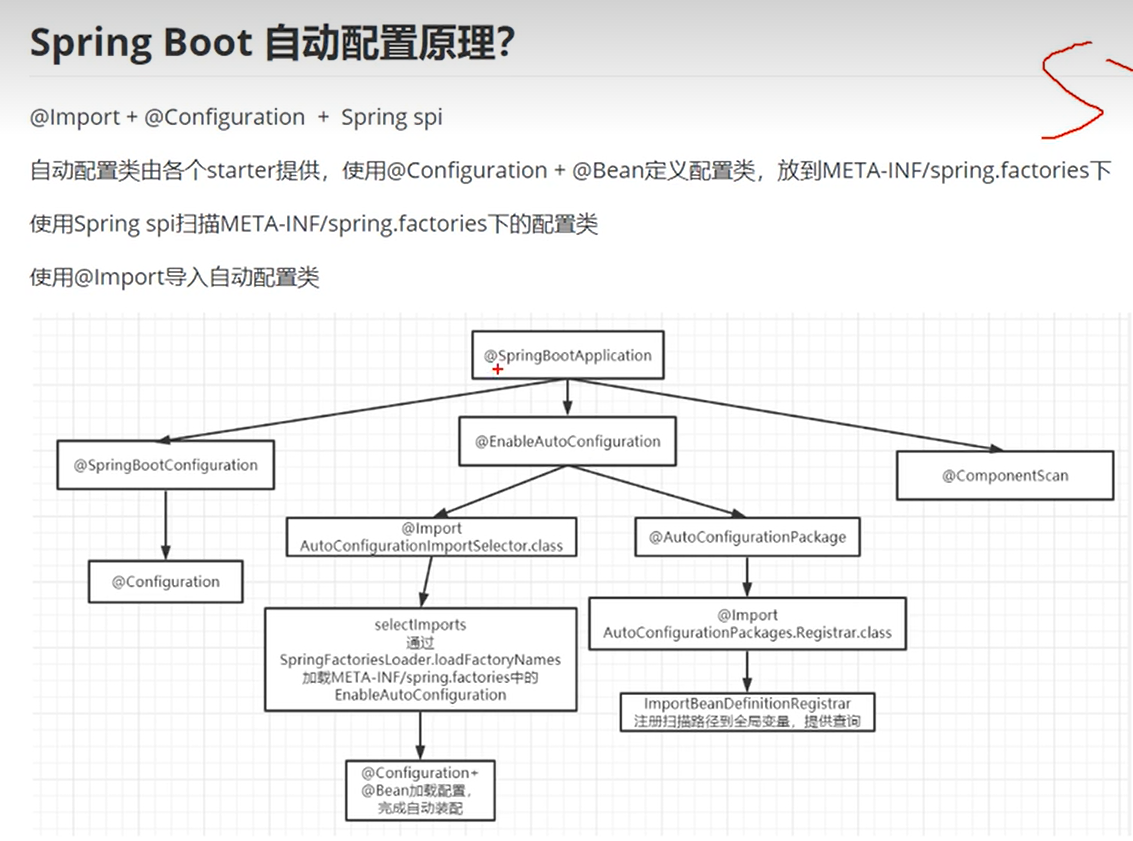
31 spring和springboot项目部署有什么不同?
答:
32 如何部署一个java项目上线?
答:
1.购买云服务器
我是在阿里云试用中心免费试用的一个月,对于小型web项目来说选哪种服务器都行,服务器在购买时最好选择centOS。
2.配置云服务器
这里主要是配置一下服务器的密码,和安全组里需要放行一些端口比如数据库的3306,宝塔的8888,tomcat的8080等等。
3.远程连接云服务器
这里我的mac用的是iTerm2
4.安装宝塔到云服务器上
去宝塔官网复制安装命令到终端里。待安装完成后会给你URL和账号密码,你就可以用来访问宝塔的dashboard了。
5.服务器所需环境配置
在宝塔的软件商店可以直接下你所需要的服务器上的环境,比如说JAVA,Tomcat,MySQL等等,这里要根据实际情况来选择和调试
6.配置服务器数据库
点到宝塔数据库界面,可以将本地项目的数据库.sql文件导入到服务器数据库上。然后更改本地项目中database.properties的url,将localhost改为自己的云服务器地址,以及root账号密码,看项目是否能够跑通。
7.项目打包
有多种打包方式,我自己使用的是在pom.xml里加上<packaging>war</packaging>,然后用右侧maven的clean和package,就会在target文件中得到一个.war文件。
8.将war包传到服务器上的tomcat内
我这里尝试了两种办法,一种是使用ip:8080/manager/html界面下的deplpy来导包到webapps下,或者直接在宝塔里的文件找到tomcat下的root文件下,将其他内容删除,并上传刚才的war包。注意解压后要将文件内的内容复制到上一级目录,也就是root下。
9.访问项目
这时候如果没有错误,访问ip:8080就是你自己的项目,也就是整个部署过程完成了。
33 为什么会有Integer这种包装类?与int的区别在哪儿?
答:
(2)在 Java 中每个基本数据类型都对应了一个包装类,而 int 对应的包装类就是 Integer,包装类的存在解决了基本数据类型无法做到的事情泛型类型参数、序列化、类型转换、高频区间数据缓存等问题。
(2)区别:
数据类型不同:int 是基础数据类型,而 Integer 是包装数据类型;
默认值不同:int 的默认值是 0,而 Integer 的默认值是 null;
内存中存储的方式不同:int 在内存中直接存储的是数据值,而 Integer 实际存储的是对象引用,当 new 一个 Integer时实际上是生成一个指针指向此对象;
实例化方式不同:Integer 必须实例化才可以使用,而 int 不需要;
变量的比较方式不同:int 可以使用 == 来对比两个变量是否相等,而 Integer 一定要使用 equals 来比较两个变量是否相等。
34 讲一下hashmap,为什么用链表不直接用红黑树?红黑树?
答:
(1)
1.8以前用数组+链表的方式,1.8开始当数组大于64 链表大于8时,链表转化成红黑树。
JDK 8 HashMap为啥要引入红黑树?
当HashMap 的 key 冲突过多时,比如我们使用了不好的 hash 算法,导致 key冲突率极高,我们都知道链表的查找性能很差,所以引入红黑树是为了优化查询性能。
JDK 8 HashMap为啥不直接用红黑树?
因为树节点所占用的空间是普通节点的两倍,所以只有当节点足够多的时候,才会使用树节点。也就是说,最开始使用链表的时候,链表是比较短的,空间占用也是比较少的,查询性能都差不多,但是当链表越来越长,链表查询越来越慢,为了保证查询效率,这时候才会舍弃链表而使用红黑树,以空间换时间。
所以没有必要一开始就用红黑树,另外,链表较长的情况非常少见,一开始就使用红黑树反而会导致所有的情况都会占用比链表大2倍的空间,适得其反,这也是一种平衡的策略。
(2)红黑树
红黑树的概念:
红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色,可以是Red或Black。 通过任何一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有一条路径会比其他路径长出俩倍,因而是接近平衡的。
红黑树的性质:
每个结点不是红色就是黑色
根节点是黑色的
如果一个节点是红色的,则它的两个孩子结点是黑色的
对于每个结点,从该结点到其所有后代叶结点的简单路径上,均包含相同数目的黑色结点
每个叶子结点都是黑色的(此处的叶子结点指的是空结点)
35 讲讲java的引用?
答:
一、java中引用
Java不像C语言那样有着明确的指针的概念,下面的程序:
Object obj = new Object();
这段代码中在new Object()的时候在堆中创建了一个Object类型的对象,并且把这个对象的相关信息给了obj引用。
我们没办法直接去修改堆内存中的对象,我们可以通过引用找到堆内存进而进行修改。
二、引用类型
1.强引用
强引用是引用关系中最常见的一种,例如上边的例子就是一种强引用。垃圾回收器不会回收还存在强引用关系的对象。代码示例如下:
Object object = new Object();
System.out.println(object);//java.lang.Object@1b6d3586
System.gc();
System.out.println(object);//java.lang.Object@1b6d3586
//删除对象的话,只需讲引用置为null,之后垃圾回收器认为该对象是不可达对象就会自动回收
object = null;
System.out.println(object);
由于强引用关系在,对象不会回收,强引用也是造成Java内存泄露的主要原因之一。
2.软引用
软引用是SoftReference 类实现的。对于内存足够的时候,软引用连接的对象是不会被删除的,但是当内存不够的时候,软引用连接的对象就会被垃圾收集器回收。代码如下
//前提 设置-Xms10M -Xmx10M
SoftReference<byte[]> softReference = new SoftReference<>(new byte[1024 * 1024 * 4]);
System.out.println(softReference.get()); //[B@1b6d3586
System.gc();
System.out.println(softReference.get()); //[B@1b6d3586
byte[] bytes = new byte[1024 * 1024 * 4];
System.out.println(softReference.get()); //null
上述代码中我们先打印了下引用[B@1b6d3586,当我们手动进行了gc后,引用打印出来还是[B@1b6d3586。当我们在创建一个4M数据大小的数组后,我们打印出来就变成null。
(笔者使用的java8默认的垃圾回收器)我们设置堆内存10M,新生代内存大约3.3M,老年代大约6.6M。我们手动gc时内存充足,因此软引用的对象没有回收。当我们创建一个强引用bytes的数组对象时,内存分配不下,因此jvm进行了一次gc,认为内存不够,就把软引用的对象给回收了
3、弱引用
弱引用是WeakReference类实现的。是一种比软引用还弱的引用,当我们下一次gc的时候,对象内存就会被回收,不管内存够不够。代码示例如下
WeakReference<byte[]> weakReference = new WeakReference<>(new byte[1024 * 1024 * 1]);
System.out.println(weakReference .get()); //[B@1b6d3586
System.gc();
System.out.println(weakReference .get()); //null
我们的堆内存还有剩余,但是gc的时候还是把对象内存回收了。
4、虚引用
虚引用是PhantomReference类实现的。虚引用好比没有引用一样,在gc中会被回收,与弱引用不同的是,弱引用在被回收前可以拿到实例化的相关数据,而虚引用是无法通过引用找到实例的。因此又被成为幽灵引用。
C++的指针指向地址,java的引用相对来说会更安全。
C++的野指针:在循环迭代的时候会有一些操作导致逻辑上的指向内存的地址,可能你已经无法识别它指的是一个什么东西,它本来指向的是一个确定的地址,但得到的确是一个不确定的地址。
用判空、安全性的检查去解决野指针。
C++相比java更面向基础的工作,比如说算法的开发等。
java更便捷成熟,有更丰富的框架。
36 HashMap中的put操作?
答:
我们在使用put方法的时候会传进key和value参数
在我们将这两个参数传入后,
第一步,我们的put方法会去判断这个hashmap是否为null 或者长度是否为0,如果是则对hashmap数组进行resize()扩容,
第二步,put方法会根据这个key计算hash码来得到数组的位置,(这里需要解释一下,我们的hashmap默认是由一个数组加链表组成的)
得到位置后当然是继续判断这个数组下标的值是否为null,为null 自然是直接插入我们的value值,如果不为空的话进行第三步
第三步,判断key是否为null,当key!=null我们就可以覆盖value值,key==null继续第四步
第四步,如果key值也为空,则判断结点类型是链表还是红黑树
第五步,如果节点类型为红黑树,则执行红黑树插入操作
如果节点类型为链表,那么put方法就会遍历这个链表,for循环遍历链表直至链表尾部,然后进行尾插,当链表长度>=8时,会进入链表转红黑树的方法,treeifyBin方法中还会判断数组长度,数组长度>=64,链表长度>=8同时满足,才会将链表转为红黑树;在for循环遍历过程中,如果key相同,则直接插入元素
第五步,记录操作次数变量modCount+1,最后再判断当前map中有多少元素,和阈值做对比,如果超过阈值则进行扩容当数组容量超过最大容量时就会扩容一倍(即二进制的进位),没有则返回null。
put方法是由返回值的,在插入完成后,如果插入之前已经存在这个key,则返回的是插入之前已存在元素的value。
37 Java集合中的 Set、List、Map?
答:
1.集合概念
集合是java中提供的一种容器,可以用来存储多个数据。
2.集合与数组的区别(集合和数组都是容器)
数组的长度是固定的。集合的长度是可变的
数组中存储的是同一类型的元素,可以存储基本数据类型值。集合存储的都是对象。而且对象的类型可以不一致。在开发中一般当对象多的时候,使用集合进行存储。
3.集合框架
集合按照其存储结构可以分为两大类,分别是单列集合java.util.Collection和双列集合java.util.Map。
Collection:单列集合类的根接口,用于存储一系列符合某种规则的元素,它有两个重要的子接口,分别是java.util.List和java.util.Set。
其中,List的特点是元素有序、元素可重复。List接口的主要实现类有java.util.ArrayList和java.util.LinkedList.
Set的特点是元素无序,而且不可重复。Set接口的主要实现类有java.util.HashSet和java.util.TreeSet。
集合本身是一个工具,它存放在java.util包中。在Collection接口定义着单列集合框架中最最共性的内容。
4.List接口介绍
ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
Vector
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低
LinkedList
优点: 底层数据结构是链表(双向链表),查询慢,增删快。
缺点: 线程不安全,效率高
5.Set接口介绍
HashSet(底层实现是HashMap)
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals()
LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
TreeSet
底层数据结构是红黑树。(唯一,有序)
1.如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
6 Map接口介绍
答:
【1】Map使用场景(动态查找时)
Map是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。对于静态类型的查找来说,一般直接遍历或者用二分查找【不会对区间进行插入和删除操作】
而在现实生活中的查找比如:
1.根据姓名查询考试成绩
2.通讯录,即根据姓名查询联系方式
3.不重复集合,即需要先搜索关键字是否已经在集合中
以上等可能在查找时进行一些插入和删除的操作,即动态查找,就需要用Map进行一系列操作。
注:Map最重要的特性就是去重!
【2】概念
Map是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复。
<K,V>使用的是 key-value模型:
key-value 模型中 key 和 value 是一个整体。key-value模型就是类似于这样的一组组合。【key 和 value 互相修饰】
Map使用时一些注意点:
Map是一个接口,不能直接实例化对象,如果要实例化只能实例化其实现类TreeMap或者HashMap。
Map 中存放键值对的 Key 是唯一的, value 是可以重复的
Map 中的 Key 可以全部分离出来,存储到 Set 中 来进行访问 ( 因为 Key 不能重复 ) 。
Map 中的 value 可以全部分离出来,存储在 Collection 的任何一个子集合中 (value 可能有重复 ) 。
Map 中键值对的 Key 不能直接修改, value 可以修改,如果要修改 key ,只能先将该 key 删除掉,然后再来进行重新插入。
38 链表?
答:
链表是一种 物理存储结构上非连续 、非顺序的存储结构,数据元素的 逻辑顺序 是通过链表中的 指针链 接 次序实现的 。
相较于查询更便于插入、删除操作。实现主要是单双链表。
可结合数组回答,引导linklist→arraylist→list、set、map集合
39 maven git 用来干嘛? git的原理?
答:
Maven是一个优秀的Java项目管理工具。在用Java做项目时,项目的创建、编译、测试、打包和安装部署都需要敲入不少的命令,而且在编译和运行Java程序时,必须能从CLASSPATH中找到该项目依赖的jar包,否则编译无法顺利进行,更不可能成功运行。为解决这些问题,Maven应运而生。
Git用于源代码的版本控制和多人协作。
git基本底层原理
Git的核心是它的对象数据库,其中保存着git的对象,其中最重要的是blob、tree和commit对象,blob对象实现了对文件内容的记录,tree对象实现了对文件名、文件目录结构的记录,commit对象实现了对版本提交时间、版本作者、版本序列、版本说明等附加信息的记录。这三类对象,完美实现了git的基础功能:对版本状态的记录。
blob数据对象记录内容,tree对象记录文件名和文件目录结构,commit对象记录版本的信息
git提交流程原理
git add 添加文件到暂存区,并且创建数据对象添加到tree对象中且记录到git数据库 (作用)
Git根据某一时刻暂存区所表示的状态创建并记录一个对应的树对象(一个暂存区对应一个tree对象)
git commit (作用)
然后把以上的tree对象添加到commit 对象中记录到git 数据库中。
bolob(文件)>tree(目录)>commit(汇总提交和提交信息)>Git数据库
每次我们运行 git add 和 git commit 命令时, Git 所做的实质工作是将被改写的文件保存为数据对象,更新暂存区,记录树对象,最后创建一个指明了顶层树对象和父提交的提交对象。 这三种主要的 Git 对象——数据对象、树对象、提交对象——最初均以单独文件的形式保存在 .git/objects 目录下(对象数据库)。
40 自动装箱与自动拆箱?
答:
41 Java为什么默认继承Object类?
答:
一般对于这种靠虚拟机运行的语言(如Java、C#等)会有两种方法处理默认继承问题。
编译器处理
在编译源代码时,当一个类没有显式标明继承的父类时,编译器会为其指定一个默认的父类(一般为Object),而交给虚拟机处理这个类时,由于这个类已经有一个默认的父类了。
JVM处理
编译器仍然按照实际代码进行编译,并不会做额外的处理,即如果一个类没有显式地继承于其他类时,编译后的代码仍然没有父类。然后由虚拟机运行二进制代码时,当遇到没有父类的类时,就会自动将这个类看成是Object类的子类(一般这类语言的默认父类都是Object)。
JDK 6之前是编译器处理,JDK 7之后是虚拟机处理。
42 哈希表?
答:
也就是散列表。
根据关键码值(Key value)而直接进行访问的数据结构。
也就是说,它通过映射函数把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
43 同步、异步?
答:
44
测开-面试题-Java基础的更多相关文章
- 面试题-Java基础-面向对象
1.面向对象软件开发的优点有哪些? 代码开发模块化,更易维护和修改.代码复用.增强代码的可靠性和灵活性.增加代码的可理解性.面向对象编程有很多重要的特性,比如:封装,继承,多态和抽象.下面的章节我们会 ...
- 面试题-Java基础-开发环境
1.什么是Java虚拟机?为什么Java被称作是“平台无关的编程语言”? Java虚拟机是一个可以执行Java字节码的虚拟机进程.Java源文件被编译成能被Java虚拟机执行的字节码文件.Java被设 ...
- 蓝桥网试题 java 基础练习 十六进制转八进制
- -------------------------------------------------------------------------------------------------- ...
- JAVA面试题——JAVA基础篇
1.JAVA多态的实现方式:继承.重载.覆盖 2.JAVA有8种基本数据类型:byte.short.int.long.float.double.boolean.char 3.final.finally ...
- 面试题-Java基础-Applet部分
java applet是能够被包含在HTML页面中并且能被启用了java的客户端浏览器执行的程序.Applet主要用来创建动态交互的web应用程序.
- 面试题-Java基础-垃圾回收
1.Java中垃圾回收有什么目的?什么时候进行垃圾回收? 垃圾回收的目的是识别并且丢弃应用不再使用的对象来释放和重用资源. 2.System.gc()和Runtime.gc()会做什么事情? 这两个方 ...
- 面试题-Java基础-集合和数组
1.Java集合类框架的基本接口有哪些? 集合类接口指定了一组叫做元素的对象.集合类接口的每一种具体的实现类都可以选择以它自己的方式对元素进行保存和排序.有的集合类允许重复的键,有些不允许.Java集 ...
- 面试题-Java基础-线程部分
1.进程和线程的区别是什么? 进程是执行着的应用程序,而线程是进程内部的一个执行序列.一个进程可以有多个线程.线程又叫做轻量级进程. 2.创建线程有几种不同的方式?你喜欢哪一种?为什么? 有三种方式可 ...
- 面试题-Java基础-异常部分
1.Java中的两种异常类型是什么?他们有什么区别? Java中有两种异常:受检查的(checked)异常和不受检查的(unchecked)异常.不受检查的异常不需要在方法或者是构造函数上声明,就算方 ...
- 蓝桥网试题 java 基础练习 矩形面积交
------------------------------------------------------------------------------------------- 思路见锦囊2 - ...
随机推荐
- 教你用JavaScript实现计数器
案例介绍 欢迎来到我的小院,我是霍大侠,恭喜你今天又要进步一点点了!我们来用JavaScript编程实战案例,做一个计数器.点击按钮数字改变,点击重置数字归0.通过实战我们将学会forEach循环.c ...
- [论文总结] Genecology and Adaptation of Forest Trees 林木的基因生态学与适应性
文章目录 介绍 进化的力量 基因学方法 种源试验 短期基因检测实验 表型与遗传估计 差异化 基因学趋势 预测对气候变化的反应 介绍 基因生态学是研究种内遗传变异与环境条件的关系.它揭示了种群适应环境的 ...
- [Unity]Update()与FixedUpdate()
Update()介绍 首先我们从官方文档的介绍了解: MonoBehaviour.Update() Description Update is called every frame, if the M ...
- LOJ 数列分块入门 9 题解题报告
LOJ 数列分块入门 9 题解题报告 \(\text{By DaiRuiChen007}\) I. 数列分块入门 1 题目大意 \(\text{Link}\) 维护一个长度为 \(n\) 的序列,支持 ...
- angular--路由导航三种方法
- angular Ionic CLI连接数据获取数据无限滚动
- gRPC介绍(以Java为例)
1.简介 1.1 gRPC的起源 RPC是Remote Procedure Call的简称,中文叫远程过程调用.用于解决分布式系统中服务之间的调用问题.通俗地讲,就是开发者能够像调用本地方法一样调用远 ...
- 模板层语法、模板层之标签、模板的继承与导入、模型层之ORM常见关键字
模板层语法.模板层之标签.模板的继承与导入.模型层之ORM常见关键字 一.模板层语法 1.模板语法的传值 urls代码: path('modal/', views.modal) views代码: de ...
- MyBatis-Plus生成的id传给前端最后两位变为0
问题描述: 使用MybatisPlus-Plus插入一条数据,生成的id长这样 1621328019543105539 但是在前端显示的时候id却是这样 1621328019543105500 所以导 ...
- 在日报、读后感、小说、公文模版、编程等场景体验了一把chatGPT
总结/朱季谦 在日报.读后感.小说.公文模版.编程等场景体验了一把chatGPT,说下体会. 昨天经过一顿操作猛如虎的捣鼓,终于在Mac笔记本上将chatGPT的访问环境搭建了起来,忍不住立马开始玩起 ...