Webpack 常见静态资源处理 - 模块加载器(Loaders)+ExtractTextPlugin插件
Webpack 常见静态资源处理 - 模块加载器(Loaders)+ExtractTextPlugin插件
webpack系列目录
- webpack 系列 一:模块系统的演进
- webpack 系列 二:webpack 介绍&安装
- webpack 系列 三:webpack 如何集成第三方js库
- webpack 系列 四:webpack 多页面支持 & 公共组件单独打包
- webpack 系列 五:webpack Loaders 模块加载器
- webpack 系列 六:前端项目模板-webpack+gulp实现自动构建部署
基于webpack搭建纯静态页面型前端工程解决方案模板, 最终形态源码见github: https://github.com/ifengkou/webpack-template
正文
Webpack将所有静态资源都认为是模块,比如JavaScript,CSS,LESS,TypeScript,JSX,CoffeeScript,图片等等,从而可以对其进行统一管理。为此Webpack引入了加载器的概念,除了纯JavaScript之外,每一种资源都可以通过对应的加载器处理成模块。和大多数包管理器不一样的是,Webpack的加载器之间可以进行串联,一个加载器的输出可以成为另一个加载器的输入。比如LESS文件先通过less-load处理成css,然后再通过css-loader加载成css模块,最后由style-loader加载器对其做最后的处理,从而运行时可以通过style标签将其应用到最终的浏览器环境。
一 常用loader
安装css/sass/less loader加载器
cnpm install file-loader css-loader style-loader sass-loader ejs-loader html-loader jsx-loader image-webpack-loader --save-dev
webpack.config.js配置:
module: {
loaders: [
{
test: /\.((woff2?|svg)(\?v=[0-9]\.[0-9]\.[0-9]))|(woff2?|svg|jpe?g|png|gif|ico)$/,
loaders: [
// 小于10KB的图片会自动转成dataUrl
'url?limit=10240&name=img/[hash:8].[name].[ext]',
'image?{bypassOnDebug:true, progressive:true,optimizationLevel:3,pngquant:{quality:"65-80",speed:4}}'
]
},
{
test: /\.((ttf|eot)(\?v=[0-9]\.[0-9]\.[0-9]))|(ttf|eot)$/,
loader: 'url?limit=10000&name=fonts/[hash:8].[name].[ext]'
},
{test: /\.(tpl|ejs)$/, loader: 'ejs'},
{test: /\.css$/, loader: 'style-loader!css-loader'},
{ test: /\.scss$/, loader: 'style!css!sass'}
]
},
index.html 新增两个div
<div class="small-webpack"></div>
<div class="webpack"></div>
index.css 增加两个图片,同时将webpack.png(53kb) 和 small-webpack.png(9.8k)
.webpack {
background: url(../img/webpack.png) no-repeat center;
height:500px;
}
.small-webpack {
background: url(../img/small-webpack.png) no-repeat center;
height:250px;
}
index.js 引入css
require('../css/index.css');
执行webpack指令
$ webpack
查看生成的目录结构
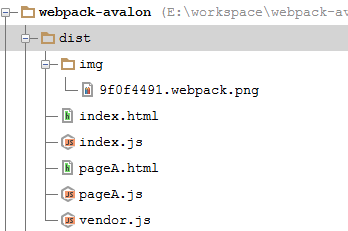
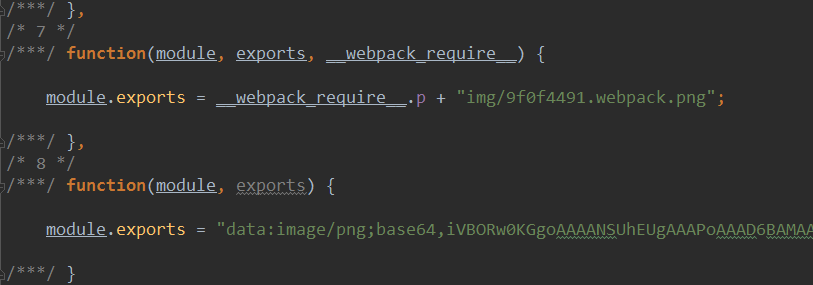
其中并没有css文件,css被写入到了index.js中,index.js 部分截图
总结:
- 图片采用了url-loader加载,如果小于10kb,图片则被转化成 base64 格式的 dataUrl
- css文件被打包进了js文件中
css被打包进了js文件,如果接受不了,可以强制把css从js文件中独立出来。官方文档是以插件形式实现:文档docs点这,插件的github点这
二:extract-text-webpack-plugin 插件介绍
Extract text from bundle into a file.从bundle中提取出特定的text到一个文件中。使用 extract-text-webpack-plugin就可以把css从js中独立抽离出来
安装
$ npm install extract-text-webpack-plugin --save-dev
使用(css为例)
var ExtractTextPlugin = require("extract-text-webpack-plugin");
module.exports = {
module: {
loaders: [
{ test: /\.css$/, loader: ExtractTextPlugin.extract("style-loader", "css-loader") }
]
},
plugins: [
new ExtractTextPlugin("styles.css")
]
}
它将从每一个用到了require("*.css")的entry chunks文件中抽离出css到单独的output文件
API
new ExtractTextPlugin([id: string], filename: string, [options])
idUnique ident for this plugin instance. (For advanded usage only, by default automatic generated)filenamethe filename of the result file. May contain [name], [id] and [contenthash].[name]the name of the chunk[id]the number of the chunk[contenthash]a hash of the content of the extracted file
optionsallChunksextract from all additional chunks too (by default it extracts only from the initial chunk(s))disabledisables the plugin
ExtractTextPlugin.extract([notExtractLoader], loader, [options])
根据已有的loader,创建一个提取器(loader的再封装)
notExtractLoader(可选)当css没有被抽离时,加载器不应该使用(例如:当allChunks:false时,在一个additional 的chunk中)loader数组,用来转换css资源的加载器soptionspublicPath重写该加载器(loader)的publicPath的设置
多入口文件的extract的使用示例:
let ExtractTextPlugin = require('extract-text-webpack-plugin');
// multiple extract instances
let extractCSS = new ExtractTextPlugin('stylesheets/[name].css');
let extractLESS = new ExtractTextPlugin('stylesheets/[name].less');
module.exports = {
...
module: {
loaders: [
{test: /\.scss$/i, loader: extractCSS.extract(['css','sass'])},
{test: /\.less$/i, loader: extractLESS.extract(['css','less'])},
...
]
},
plugins: [
extractCSS,
extractLESS
]
};
三:改造项目-抽离css
安装插件到项目
npm install extract-text-webpack-plugin --save-dev
配置webpack.config.js,加入ExtractTextPlugin和相关处理:
var webpack = require("webpack");
var path = require("path");
var srcDir = path.resolve(process.cwd(), 'src');
var nodeModPath = path.resolve(__dirname, './node_modules');
var pathMap = require('./src/pathmap.json');
var glob = require('glob')
var CommonsChunkPlugin = webpack.optimize.CommonsChunkPlugin;
var HtmlWebpackPlugin = require('html-webpack-plugin');
var ExtractTextPlugin = require('extract-text-webpack-plugin');
var entries = function () {
var jsDir = path.resolve(srcDir, 'js')
var entryFiles = glob.sync(jsDir + '/*.{js,jsx}')
var map = {};
for (var i = 0; i < entryFiles.length; i++) {
var filePath = entryFiles[i];
var filename = filePath.substring(filePath.lastIndexOf('\/') + 1, filePath.lastIndexOf('.'));
map[filename] = filePath;
}
return map;
}
var html_plugins = function () {
var entryHtml = glob.sync(srcDir + '/*.html')
var r = []
var entriesFiles = entries()
for (var i = 0; i < entryHtml.length; i++) {
var filePath = entryHtml[i];
var filename = filePath.substring(filePath.lastIndexOf('\/') + 1, filePath.lastIndexOf('.'));
var conf = {
template: 'html!' + filePath,
filename: filename + '.html'
}
//如果和入口js文件同名
if (filename in entriesFiles) {
conf.inject = 'body'
conf.chunks = ['vendor', filename]
}
//跨页面引用,如pageA,pageB 共同引用了common-a-b.js,那么可以在这单独处理
//if(pageA|pageB.test(filename)) conf.chunks.splice(1,0,'common-a-b')
r.push(new HtmlWebpackPlugin(conf))
}
return r
}
var plugins = [];
var extractCSS = new ExtractTextPlugin('css/[name].css?[contenthash]')
var cssLoader = extractCSS.extract(['css'])
var sassLoader = extractCSS.extract(['css', 'sass'])
plugins.push(extractCSS);
plugins.push(new CommonsChunkPlugin({
name: 'vendor',
minChunks: Infinity
}));
module.exports = {
entry: Object.assign(entries(), {
// 用到什么公共lib(例如jquery.js),就把它加进vendor去,目的是将公用库单独提取打包
'vendor': ['jquery', 'avalon']
}),
output: {
path: path.join(__dirname, "dist"),
filename: "[name].js",
chunkFilename: '[chunkhash:8].chunk.js',
publicPath: "/"
},
module: {
loaders: [
{
test: /\.((woff2?|svg)(\?v=[0-9]\.[0-9]\.[0-9]))|(woff2?|svg|jpe?g|png|gif|ico)$/,
loaders: [
//小于10KB的图片会自动转成dataUrl,
'url?limit=10000&name=img/[hash:8].[name].[ext]',
'image?{bypassOnDebug:true, progressive:true,optimizationLevel:3,pngquant:{quality:"65-80",speed:4}}'
]
},
{
test: /\.((ttf|eot)(\?v=[0-9]\.[0-9]\.[0-9]))|(ttf|eot)$/,
loader: 'url?limit=10000&name=fonts/[hash:8].[name].[ext]'
},
{test: /\.(tpl|ejs)$/, loader: 'ejs'},
{test: /\.css$/, loader: cssLoader},
{test: /\.scss$/, loader: sassLoader}
]
},
resolve: {
extensions: ['', '.js', '.css', '.scss', '.tpl', '.png', '.jpg'],
root: [srcDir, nodeModPath],
alias: pathMap,
publicPath: '/'
},
plugins: plugins.concat(html_plugins())
}
其中,用ExtractTextPlugin 来抽离css
var ExtractTextPlugin = require('extract-text-webpack-plugin');
var extractCSS = new ExtractTextPlugin('css/[name].css?[contenthash]')
var cssLoader = extractCSS.extract(['css'])
var sassLoader = extractCSS.extract(['css', 'sass'])
plugins.push(extractCSS);
......
//conf - module - loaders
{test: /\.css$/, loader: cssLoader},
{test: /\.scss$/, loader: sassLoader}
注意事项:
css中img的路径会出现问题,通过设置publicPath 解决,采用绝对路径
output: {
......
publicPath: "/"
},
运行:
$ webpack
期望
- css单独抽离,打包成单独的css文件
- html自动引用css文件
- 小于10k的图片,转成base64 格式的 dataUrl
- webpack.png 会被压缩,减少文件大小
运行webpack后的项目的目录结构:
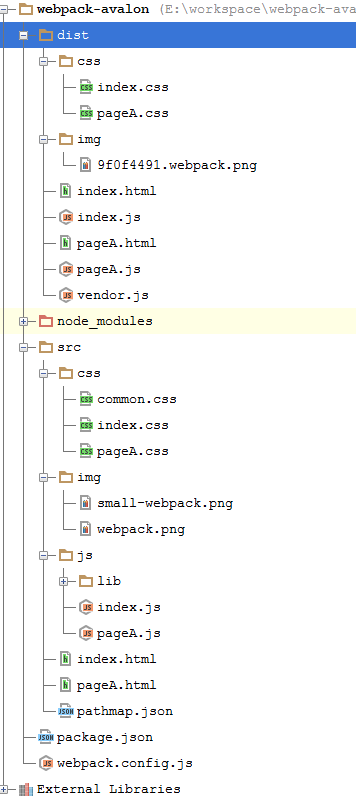
生成的 dist/index.html 自动引用了 index.css 和相关的js,由于设置了publicPath 所以相应的链接都采用了绝对路径
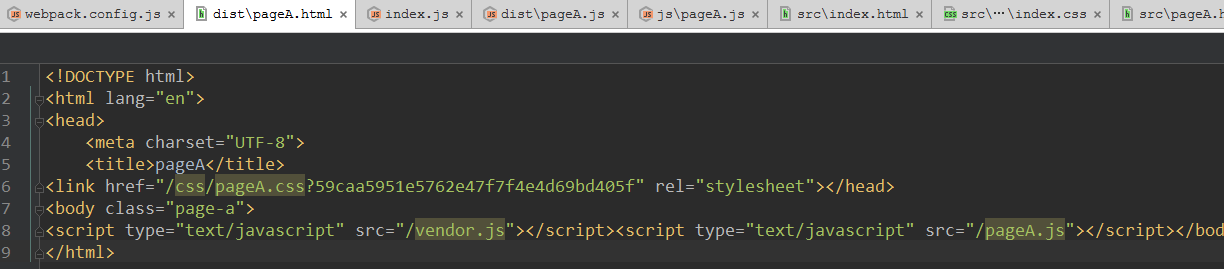
生成的 dist/index.css 小图片被转成了data:image形式:
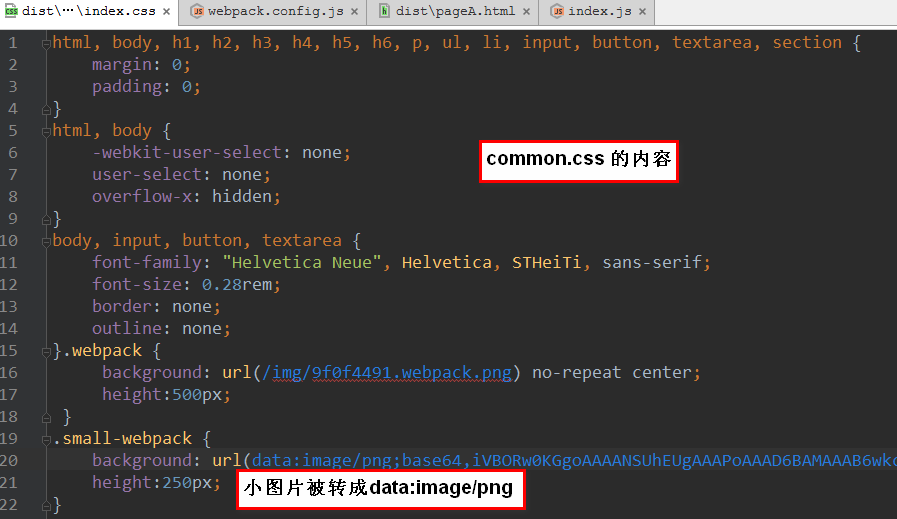
结果:
- css单独打包到css目录
- html自动注入了
link标签 - small-webpack.png 小于10k,被打包进了index.css
- webpack.png 由原来的50+k 被压缩成 10- k
最后,运行 webpack-dev-server 看一下运行结果:

总结
Webpack将所有静态资源都认为是模块,而通过loader,几乎可以处理所有的静态资源,图片、css、sass之类的。并且通过一些插件如extract-text-webpack-plugin,可以将共用的css抽离出来
下篇介绍改进webpack.config.js:
- 区分开发环境和生产环境
- 集成 gulp 实现自动构建打包部署
- github 发布 前端自动化构建的项目模板
Webpack 常见静态资源处理 - 模块加载器(Loaders)+ExtractTextPlugin插件的更多相关文章
- Webpack模块加载器
一.介绍 Webpack是德国开发者 Tobias Koppers 开发的模块加载器,它能把所有的资源文件(JS.JSX.CSS.CoffeeScript.Less.Sass.Image等)都作为模块 ...
- 实现简单的 JS 模块加载器
实现简单的 JS 模块加载器 1. 背景介绍 按需加载是前端性能优化的一个重要手段,按需加载的本质是从远程服务器加载一段JS代码(这里主要讨论JS,CSS或者其他资源大同小异),该JS代码就是一个模块 ...
- 构建服务端的AMD/CMD模块加载器
本文原文地址:http://trock.lofter.com/post/117023_1208040 . 引言: 在前端开发领域,相信大家对AMD/CMD规范一定不会陌生,尤其对requireJS. ...
- 【模块化编程】理解requireJS-实现一个简单的模块加载器
在前文中我们不止一次强调过模块化编程的重要性,以及其可以解决的问题: ① 解决单文件变量命名冲突问题 ② 解决前端多人协作问题 ③ 解决文件依赖问题 ④ 按需加载(这个说法其实很假了) ⑤ ..... ...
- JavaScript AMD 模块加载器原理与实现
关于前端模块化,玉伯在其博文 前端模块化开发的价值 中有论述,有兴趣的同学可以去阅读一下. 1. 模块加载器 模块加载器目前比较流行的有 Requirejs 和 Seajs.前者遵循 AMD规范,后者 ...
- js模块化/js模块加载器/js模块打包器
之前对这几个概念一直记得很模糊,也无法用自己的语言表达出来,今天看了大神的文章,尝试根据自己的理解总结一下,算是一篇读后感. 大神的文章:http://www.css88.com/archives/7 ...
- 实现一个类 RequireJS 的模块加载器 (二)
2017 新年好 ! 新年第一天对我来说真是悲伤 ,早上兴冲冲地爬起来背着书包跑去实验室,结果今天大家都休息 .回宿舍的时候发现书包湿了,原来盒子装的牛奶盖子松了,泼了一书包,电脑风扇口和USB口都进 ...
- 使用RequireJS并实现一个自己的模块加载器 (一)
RequireJS & SeaJS 在 模块化开发 开发以前,都是直接在页面上引入 script 标签来引用脚本的,当项目变得比较复杂,就会带来很多问题. JS项目中的依赖只有通过引入JS的顺 ...
- JS模块加载器加载原理是怎么样的?
路人一: 原理一:id即路径 原则.通常我们的入口是这样的: require( [ 'a', 'b' ], callback ) .这里的 'a'.'b' 都是 ModuleId.通过 id 和路径的 ...
随机推荐
- Spring Boot 整合Mybatis非starter时,mapper一直无法注入解决
本来呢,直接使用mybatis-spring-boot-starter还是挺好的,但是我们系统比较复杂,有多个数据源,其中一个平台自己的数据源,另外一些是动态配置出来的,两者完全没有关系.所以直接使用 ...
- protocol method: #method<channel.close>(reply-code=406, reply-text=PRECONDITION_FAILED - unknown delivery tag 2, class-id=60, method-id=80)
Caused by: com.rabbitmq.client.ShutdownSignalException: channel error; reason: {#method<channel.c ...
- vue.JS 介绍
vueJS 介绍 首先,vueJS 是我很早之前就想要接触学习的东西,但是呢,一直没时间,主要是在学校,事太多,没心思定下心来学习,我学生生涯的最后一个假期的第一天晚上,万事开头难,那就先写点儿什么东 ...
- Python爬虫(二)——豆瓣图书决策树构建
前文参考: https://www.cnblogs.com/LexMoon/p/douban1.html Matplotlib绘制决策树代码: # coding=utf-8 import matpl ...
- amqp 抓包
1. wireshark 2. tcpick -yR -r file.name
- django基础 -- 9.中间件
一.中间件的介绍 中间件顾名思义,是介于request与response处理之间的一道处理过程,相对比较轻量级, 并且在全局上改变django的输入与输出.因为改变的是全局,所以需要谨慎实用, 用不好 ...
- uniGUI试用笔记(六)
uniGUI提供了一个文件上传控件TUniFileUpload,进行数据的导入就变得比较容易.首先将TUniFileUpload控件放置在窗体上,按下导入按钮后,执行TUniFileUpload的文件 ...
- [LightOJ 1370] Bi-shoe and Phi-shoe(欧拉函数快速筛法)
题目链接: https://vjudge.net/problem/LightOJ-1370 题目描述: 给出一些数字,对于每个数字找到一个欧拉函数值大于等于这个数的数,求找到的所有数的最小和. 知识点 ...
- CommandLine exe参数
[Verb("OptionsEntity")] public class OptionsEntity { [Option('a', HelpText = "Plantfo ...
- ssh中的 Connection closed by ***
另一台电脑的 mac/windows10/win7 都可以连接,就这台电脑不可以,但是能 ping 通, ssh 时总是 Connection reset by xxx 或 Connection cl ...