075 importSTV的使用,与bulkload的使用
一:由HDFS将数据直接导入到HBase中
1.生成TSV文件
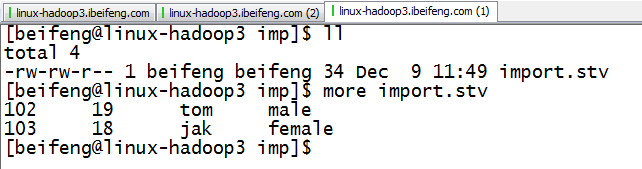
2.内容

3.上传到HDFS

4.运行
export HBASE_HOME=/etc/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase mapredcp`
export HADOOP_HOME=/etc/opt/modules/hadoop-2.5.0
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb1 /imp/import.tsv
重要的是:
)HBASE_ROW_KEY
)info:name,等都要和import.tsv相对应
)目录是HDFS的目录
)表名是将要书写进去的表名
5.结果

二:将数据转换为HFile
1.将数据转为HFile
hbase-0.98.6-hadoop2]$ $HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.bulk.output=/impout -Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb2 /imp/import.tsv
其中:nstest1:tb2的作用是按照这个表的格式进行转换HFile
/impout 是HFile的路径。

2.将HFile保存进HBase
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar completebulkload /impout nstest1:tb2
3.结果
HDFS中的HFile数据不再存在

HBase的结果

三:自定义分隔符
1.新定义文件

2.删除以前的文件,再重新上传文件
3.运行
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.separator=,
-Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb2 /imp/import.tsv
3.结果

075 importSTV的使用,与bulkload的使用的更多相关文章
- 使用bulkload向hbase中批量写入数据
1.数据样式 写入之前,需要整理以下数据的格式,之后将数据保存到hdfs中,本例使用的样式如下(用tab分开): row1 N row2 M row3 B row4 V row5 N row6 M r ...
- 【hbase】——HBase 写优化之 BulkLoad 实现数据快速入库
1.为何要 BulkLoad 导入?传统的 HTableOutputFormat 写 HBase 有什么问题? 我们先看下 HBase 的写流程: 通常 MapReduce 在写HBase时使用的是 ...
- 通过BulkLoad的方式快速导入海量数据
摘要 加载数据到HBase的方式有多种,通过HBase API导入或命令行导入或使用第三方(如sqoop)来导入或使用MR来批量导入(耗费磁盘I/O,容易在导入的过程使节点宕机),但是这些方式不是慢就 ...
- bulk-load 装载HDFS数据到HBase
bulk-load的作用是用mapreduce的方式将hdfs上的文件装载到hbase中,对于海量数据装载入hbase非常有用,参考http://hbase.apache.org/docs/r0.89 ...
- HBase BulkLoad批量写入数据实战
1.概述 在进行数据传输中,批量加载数据到HBase集群有多种方式,比如通过HBase API进行批量写入数据.使用Sqoop工具批量导数到HBase集群.使用MapReduce批量导入等.这些方式, ...
- 通过BulkLoad快速将海量数据导入到Hbase
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据.我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等. 但是这些方式不是慢就是在导入的过程的占用Region ...
- spark批量写写数据到Hbase中(bulkload方式)
1:为什么大批量数据集写入Hbase中,需要使用bulkload BulkLoad不会写WAL,也不会产生flush以及split. 如果我们大量调用PUT接口插入数据,可能会导致大量的GC操作.除了 ...
- 在Spark上通过BulkLoad快速将海量数据导入到Hbase
我们在<通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]>文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入 ...
- [How to] HBase的bulkload使用方法
1.简介 将数据插入HBase表中的方法很多,我们可以通过TableOutputFormat以Mapreduce on HBase的方式将数据插入,也可以单纯的使用客户端API将数据插入.但是以上方法 ...
随机推荐
- L1比L2更稀疏
1. 简单列子: 一个损失函数L与参数x的关系表示为: 则 加上L2正则化,新的损失函数L为:(蓝线) 最优点在黄点处,x的绝对值减少了,但依然非零. 如果加上L1正则化,新的损失函数L为:(粉线) ...
- EOF \n \0 NULL 之间的区别
\n 是换行符 \0 是字符串的结束标志 EOF是流的结束标志 FILE* 这种流 NULL 是指针为空 第一个问题是EOF 它是end of file的缩写,表示"文字流"(s ...
- keepalived高可用系列~通用基础
简介:今天咱们来聊聊keepalived一 keepalived 架构 1 标准架构: keepalived+lvs/haproxy+后端 real server(mysql从库,nginx.myc ...
- DSO windowed optimization 代码 (3)
4 Schur Complement 部分信息计算 参考<DSO windowed optimization 公式>,Schur Complement 部分指 Hsc(\(H_{X\rho ...
- Weblogic的安装与卸载
一.下载weblogic 到Oracle官网https://www.oracle.com/downloads/index.html,我在这里下载的是weblogic12C进行安装:https://ww ...
- NSIS程序安装包制作
nsis下载地址:http://www.pc6.com/softview/SoftView_14342.html nsis使用: 启动NSIS程序主界面,选择"可视化脚本编辑器(VNISEd ...
- 【PE结构】由浅入深PE基础学习-菜鸟手动查询导出表、相对虚拟地址(RVA)与文件偏移地址转换(FOA)
0 前言 此篇文章想写如何通过工具手查导出表.PE文件代码编程过程中的原理.文笔不是很好,内容也是查阅了很多的资料后整合出来的.希望借此加深对PE文件格式的理解,也希望可以对看雪论坛有所贡献.因为了解 ...
- win10-Anaconda2-Theano-cuda7.5-VS2013
两天的辗转反侧,终于灵光一现找到了错误. 首先,我在win10下配置好了gpu和cudnn版本的caffe.但是因为win平台的限制,caffe用的不够舒服.因为之前用过一阵子theano,虽然很慢, ...
- spring mvc常用配置
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.sp ...
- crontab在/var/log/目录下没有cron.log文件
1.修改rsyslog文件: /etc/rsyslog.d/50-default.conf 将 rsyslog 文件中的 #cron.* 前的 # 删掉: 2.重启rsyslog服务: s ...