(常用)re模块
#re:一些带有特殊含义的符号或者符号的组合
#为什么要用re:一堆字符串中找到你所需要的内容,过滤规则是什么样,通过re模块功能来告诉计算机你的过滤规则
#应用:在爬虫中最为常用;使用爬虫时有其他模块可以导入帮助clear数据,正则也可用于其他方面
#原理:re模块的内部实现 不是python 而是调用了c库
import re
print(re.findall('\w','ab 12\+- *&_'))
print(re.findall('\W','ab 12\+- *&_'))
print(re.findall('\s','ab \r1\n2\t\+- *&_'))
print(re.findall('\S','ab \r1\n2\t\+- *&_'))
print(re.findall('\d','ab \r1\n2\t\+- *&_'))
print(re.findall('\D','ab \r1\n2\t\+- *&_'))
print(re.findall('\w_sb','egon alex_sb123123wxx_sb,lxx_sb'))
print(re.findall('\Aalex','abcalex is salexb'))
print(re.findall('\Aalex','alex is salexb'))
print(re.findall('^alex','alex is salexb'))
print(re.findall('sb\Z','alexsb is sbalexbsb'))
print(re.findall('sb$','alexsb is sbalexbsb'))
print(re.findall('^ebn$','ebn1')) #^ebn$ 筛出的就是ebn(以ebn开头,以ebn结尾)
print(re.findall('a\nc','a\nc a\tc a1c'))
\A ^ #使用^
\Z $ #使用$
#. ? * + {m,n} .* .*? {m}
1、.:代表除了换行符外的任意一个字符
. 除了换行符之外的任意一个字符, 如果想不除换行符,后加re.DOTALL
print(re.findall('a.c','abc a1c aAc aaaaaca\nc',re.DOTALL))
?不能单独使用
print(re.findall('ab*','a ab abb abbb abbbb abbbb a1bbbbbbb'))
print(re.findall('ab+','a ab abb abbb abbbb abbbb a1bbbbbbb'))
print(re.findall('ab?','a ab abb abbb abbbb abbbb'))
print(re.findall('ab{0,1}','a ab abb abbb abbbb abbbb'))
print(re.findall('ab*','a ab abb abbb abbbb abbbb a1bbbbbbb'))
print(re.findall('ab{0,}','a ab abb abbb abbbb abbbb a1bbbbbbb'))
print(re.findall('ab+','a ab abb abbb abbbb abbbb a1bbbbbbb'))
print(re.findall('ab{1,}','a ab abb abbb abbbb abbbb a1bbbbbbb'))
print(re.findall('ab{1,3}','a ab abb abbb abbbb abbbb a1bbbbbbb'))
print(re.findall('a.*c','ac a123c aaaac a *123)()c asdfasfdsadf'))
print(re.findall('a.*?c','a123c456c'))
print(re.findall('(alex)_sb','alex_sb asdfsafdafdaalex_sb'))
print(re.findall(
'href="(.*?)"',
'<li><a id="blog_nav_sitehome" class="menu" href="http://www.cnblogs.com/">博客园</a></li>')
)
[] 内写什么就是其单独的意义, 可写0-9 a-zA-Z
print(re.findall('a[0-9][0-9]c','a1c a+c a2c a9c a11c a-c acc aAc'))
a-b有特别的意思,所以如果想让-表示它本身,要将其放在最左或最右
print(re.findall('a[-+*]c','a1c a+c a2c a9c a*c a11c a-c acc aAc'))
print(re.findall('a[a-zA-Z]c','a1c a+c a2c a9c a*c a11c a-c acc aAc'))
print(re.findall('a[^a-zA-Z]c','a c a1c a+c a2c a9c a*c a11c a-c acc aAc'))
print(re.findall('a[^0-9]c','a c a1c a+c a2c a9c a*c a11c a-c acc aAc'))
print(re.findall('([a-z]+)_sb','egon alex_sb123123wxxxxxxxxxxxxx_sb,lxx_sb'))
print(re.findall('compan(ies|y)','Too many companies have gone bankrupt, and the next one is my company'))
print(re.findall('compan(?:ies|y)','Too many companies have gone bankrupt, and the next one is my company'))
print(re.findall('alex|sb','alex sb sadfsadfasdfegon alex sb egon'))
print(re.findall('alex|sb','123123 alex sb sadfsadfasdfegon alex sb egon'))
print(re.search('alex|sb','123213 alex sb sadfsadfasdfegon alex sb egon').group())
print(re.search('^alex','123213 alex sb sadfsadfasdfegon alex sb egon'))
print(re.search('^alex','alex sb sadfsadfasdfegon alex sb egon').group())
re.search, 取第一个结果,若没有返回None;若想让结果直接显示后加group();返回None时用group()会报错
print(re.match('alex','alex sb sadfsadfasdfegon alex sb egon').group())
print(re.match('alex','123213 alex sb sadfsadfasdfegon alex sb egon'))
re.match 相当于^版本的search
info='a:b:c:d'
print(info.split(':'))
print(re.split(':',info))
print(re.split('[ :\\\/]',info))
print('egon is beutifull egon'.replace('egon','EGON',1))
print(re.sub('(.*?)(egon)(.*?)(egon)(.*?)',r'\1\2\3EGON\5','123 egon is beutifull egon 123'))
print(re.sub('([a-zA-Z]+)([^a-zA-Z]+)([a-zA-Z]+)([^a-zA-Z]+)([a-zA-Z]+)',r'\5\2\3\4\1',r'lqzzzz123+ is SB'))
pattern=re.compile('alex')
print(pattern.findall('alex is alex alex'))
print(pattern.findall('alexasdfsadfsadfasdfasdfasfd is alex alex'))
如果不用断言,以往用过的那些表达式,仅仅能获取到有规律的字符串,而不能获取无规律的字符串。
想解决以上问题,就要用到断言知识。
在讲断言之前,读者应该先了解分组,这有助于理解断言。
分组在正则中用()表示,根据小菜理解,分组的作用有两个:
n 将某些规律看成是一组,然后进行组级别的重复,可以得到意想不到的效果。
n 分组之后,可以通过后向引用简化表达式。
先来看第一个作用,对于IP地址的匹配,简单的可以写为如下形式:
\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}
但仔细观察,我们可以发现一定的规律,可以把.\d{1,3}看成一个整体,也就是把他们看成一组,再把这个组重复3次即可。表达式如下:
\d{1,3}(.\d{1,3}){3}
这样一看,就比较简洁了。
再来看第二个作用,就拿匹配<title>xxx</title>标签来说,简单的正则可以这样写:
<title>.*</title>
可以看出,上边表达式中有两个title,完全一样,其实可以通过分组简写。表达式如下:
<(title)>.*</\1>
这个例子实际上就是反向引用的实际应用。对于分组而言,整个表达式永远算作第0组,在本例中,第0组是<(title)>.*</\1>,然后从左到右,依次为分组编号,因此,(title)是第1组。
用\1这种语法,可以引用某组的文本内容,\1当然就是引用第1组的文本内容了,这样一来,就可以简化正则表达式,只写一次title,把它放在组里,然后在后边引用即可。
以此为启发,我们可不可以简化刚刚的IP地址正则表达式呢?原来的表达式为\d{1,3}(.\d{1,3}){3},里边的\d{1,3}重复了两次,如果利用后向引用简化,表达式如下:
(\d{1,3})(.\1){3}
简单的解释下,把\d{1,3}放在一组里,表示为(\d{1,3}),它是第1组,(.\1)是第2组,在第2组里通过\1语法,后向引用了第1组的文本内容。
经过实际测试,会发现这样写是错误的,为什么呢?
小菜一直在强调,后向引用,引用的仅仅是文本内容,而不是正则表达式!
也就是说,组中的内容一旦匹配成功,后向引用,引用的就是匹配成功后的内容,引用的是结果,而不是表达式。
因此,(\d{1,3})(.\1){3}这个表达式实际上匹配的是四个数都相同的IP地址,比如:123.123.123.123。
至此,读者已经掌握了传说中的后向引用,就这么简单。
接下来说说什么是断言。
所谓断言,就是指明某个字符串前边或者后边,将会出现满足某种规律的字符串。
就拿文章开篇的例子来说,我们想要的是xxx,它没有规律,但是它前边肯定会有<title>,后边肯定会有</title>,这就足够了。
想指定xxx前肯定会出现<title>,就用正后发断言,表达式:(?<=<title>).*
向指定xxx后边肯定会出现</title>,就用正先行断言,表达式:.*(?=</title>)
两个加在一起,就是(?<=<title>).*(?=</title>)
这样就能匹配到xxx。
其实掌握了规律,就很简单了,无论是先行还是后发,都是相对于xxx而言的,也就是相对于目标字符串而言。
假如目标字符串后边有条件,可以理解为目标字符串在前,就用先行断言,放在目标字符串之后。
假如目标字符串前边有条件,可以理解为目标字符串在后,就用后发断言,放在目标字符串之前。
假如指定满足某个条件,就是正。
假如指定不满足某个条件,就是负。
断言只是条件,帮你找到真正需要的字符串,本身并不会匹配!
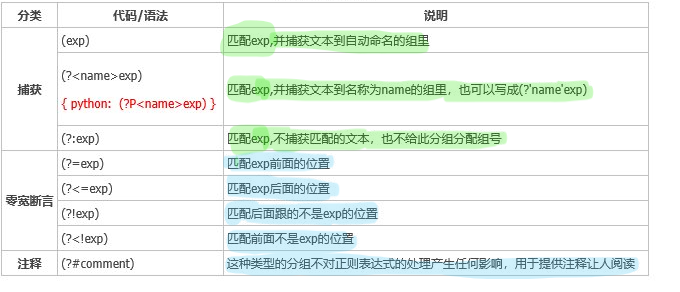
(?=X )
零宽度正先行断言。仅当子表达式 X 在 此位置的右侧匹配时才继续匹配。例如,/w+(?=/d) 与后跟数字的单词匹配,而不与该数字匹配。此构造不会回溯。
(?!X)
零宽度负先行断言。仅当子表达式 X 不在 此位置的右侧匹配时才继续匹配。例如,例如,/w+(?!/d) 与后不跟数字的单词匹配,而不与该数字匹配 。
(?<=X)
零宽度正后发断言。仅当子表达式 X 在 此位置的左侧匹配时才继续匹配。例如,(?<=19)99 与跟在 19 后面的 99 的实例匹配。此构造不会回溯。
(?<!X)
零宽度负后发断言。仅当子表达式 X 不在此位置的左侧匹配时才继续匹配。例如,(?<!19)99 与不跟在 19 后面的 99 的实例匹配
(常用)re模块的更多相关文章
- Linux驱动学习之常用的模块操作命令
1.常用的模块操作命令 (1)lsmod(list module,将模块列表显示),功能是打印出当前内核中已经安装的模块列表 (2)insmod(install module,安装模块),功能是向当前 ...
- python 常用的模块
面试的过程中经常被问到使用过那些python模块,然后我大脑就出现了一片空白各种模块一顿说,其实一点顺序也没有然后给面试官造成的印象就是自己是否真实的用到这些模块,所以总结下自己实际工作中常用的模块: ...
- Atitit 常用sdk 模块 组织架构切分 规范与范例attilax总结
Atitit 常用sdk 模块 组织架构切分 规范与范例attilax总结 常用200个模块 2017/04/12 22:01 <DIR> acc 2017/04 ...
- python中常用的模块一
一,常用的模块 模块就是我们将装有特定功能的代码进行归类,从代码编写的单位来看我们的程序,从小到大的顺序: 一条代码<语句块,<代码块(函数,类)<模块我们所写的所有py文件都是模块 ...
- Python学习手册之__main__ 模块,常用第三方模块和打包发布
在上一篇文章中,我们介绍了 Python 的 元组拆包.三元运算符和对 Python 的 else 语句进行了深入讲解,现在我们介绍 Python 的 __main__ 模块.常用第三方模块和打包发布 ...
- Nginx 常用基础模块
目录 Nginx 常用基础模块 Nginx日志管理 nginx日志切割 Nginx目录索引 Nginx状态监控 Nginx访问控制 Nginx访问限制 Nginx 请求限制配置实战 Nginx Loc ...
- python的常用内建模块与常用第三方模块
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 一.常用内置模块1.datetimePython 提供了一个 time 和 calendar 模块可 ...
- Ansible_常用文件模块使用详解
一.Ansibel常用文件模块使用详解 1.file模块 1️⃣:file模块常用的参数列表: path 被管理文件的路径 state状态常用参数: absent 删除 ...
- python 常用第三方模块
除了内建的模块外,Python还有大量的第三方模块. 基本上,所有的第三方模块都会在https://pypi.python.org/pypi上注册,只要找到对应的模块名字,即可用pip安装. 本章介绍 ...
- python中常用的模块的总结
1. 模块和包 a.定义: 模块用来从逻辑上组织python代码(变量,函数,类,逻辑:实现一个功能),本质就是.py结尾的python文件.(例如:文件名:test.py,对应的模块名:test) ...
随机推荐
- 手动实现staticmethod和classmethod装饰器
首先,staticmethod和classmethod装饰器是通过非数据描述符实现的.用法简单,这里就不细说了. 这里主要分析一下staticmethod和classmethod是如何通过描述符实现的 ...
- 「loj3058」「hnoi2019」白兔之舞
题意 有一个\((L+1)*n\) 的网格图,初始时白兔在\((0,X)\) , 每次可以向横坐标递增,纵坐标随意的位置移动,两个位置之间的路径条数只取决于纵坐标,用\(w(i,j)\) 表示,如果要 ...
- A1059. Prime Factors
Given any positive integer N, you are supposed to find all of its prime factors, and write them in t ...
- hashlib模块(二十八)
# 1.什么叫hash:hash是一种算法(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法),该算法接受传入的 ...
- 基于tcp和多线程的多人聊天室-C语言
之前在学习关于网络tcp和多线程的编程,学了知识以后不用一下总绝对心虚,于是就编写了一个基于tcp和多线程的多人聊天室. 具体的实现过程: 服务器端:绑定socket对象->设置监听数-> ...
- 第2课:什么是SQL注入
SQL注入:利用现有应用程序,将(恶意)的SQL命令注入到后台数据库引擎执行的能力,这是SQL注入的标准释义. 随着B/S模式被广泛的应用,用这种模式编写应用程序的程序员也越来越多,但由于开发人员的水 ...
- 方法重载(overroad)和方法覆盖(override)------java基础知识总结
a.什么是方法重载?(同一个类中)方法重载是指在同一个类中,出现方法名相同,参数列表不同的情况. b.什么是方法覆盖?(子父类中)方法覆盖是指在子类中,出现和父类一模一样的方法声明的时候,会运行子类的 ...
- Elasticsearch5.5 部署Head插件
Elasticsearch5.5 部署Head插件 1.git下载软件包 yum -y install git git clone git://github.com/mobz/elasticsearc ...
- Linux命令之less
less命令 用处:查看文件,功能强大,随意浏览,查看之前不会预先加载文件 用法:less + 文件名 (按q退出) 示例: 一.查看文档内容 (我这里有一个profile的文件,我想查看里面的 ...
- Ruby数组的操作
数组的创建arr = Array.new num #创建num个元素的数组,所有数组元素为nilarr = Array.new num, elem #创建num个元素的数组,所有数组元素为elemar ...