Python机器学习(1):KMeans聚类
Python进行KMeans聚类是比较简单的,首先需要import numpy,从sklearn.cluster中import KMeans模块:
import numpy as np
from sklearn.cluster import KMeans
然后读取txt文件,获取相应的数据并转换成numpy array:
X = []
f = open('rktj4.txt')
for v in f:
regex = re.compile('\s+')
X.append([float(regex.split(v)[3]), float(regex.split(v)[6])]) X = np.array(X)
设置类的数量,并聚类:
n_clusters = 5
cls = KMeans(n_clusters).fit(X)
完整代码:
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import re X = []
f = open('rktj4.txt')
for v in f:
regex = re.compile('\s+')
X.append([float(regex.split(v)[3]), float(regex.split(v)[6])]) X = np.array(X) n_clusters = 5
cls = KMeans(n_clusters).fit(X)
cls.labels_ markers = ['^','x','o','*','+']
for i in range(n_clusters):
members = cls.labels_ == i
plt.scatter(X[members, 0], X[members, 1], s=60, marker=markers[i], c='b', alpha=0.5)
print plt.title('')
plt.show()
运行结果:
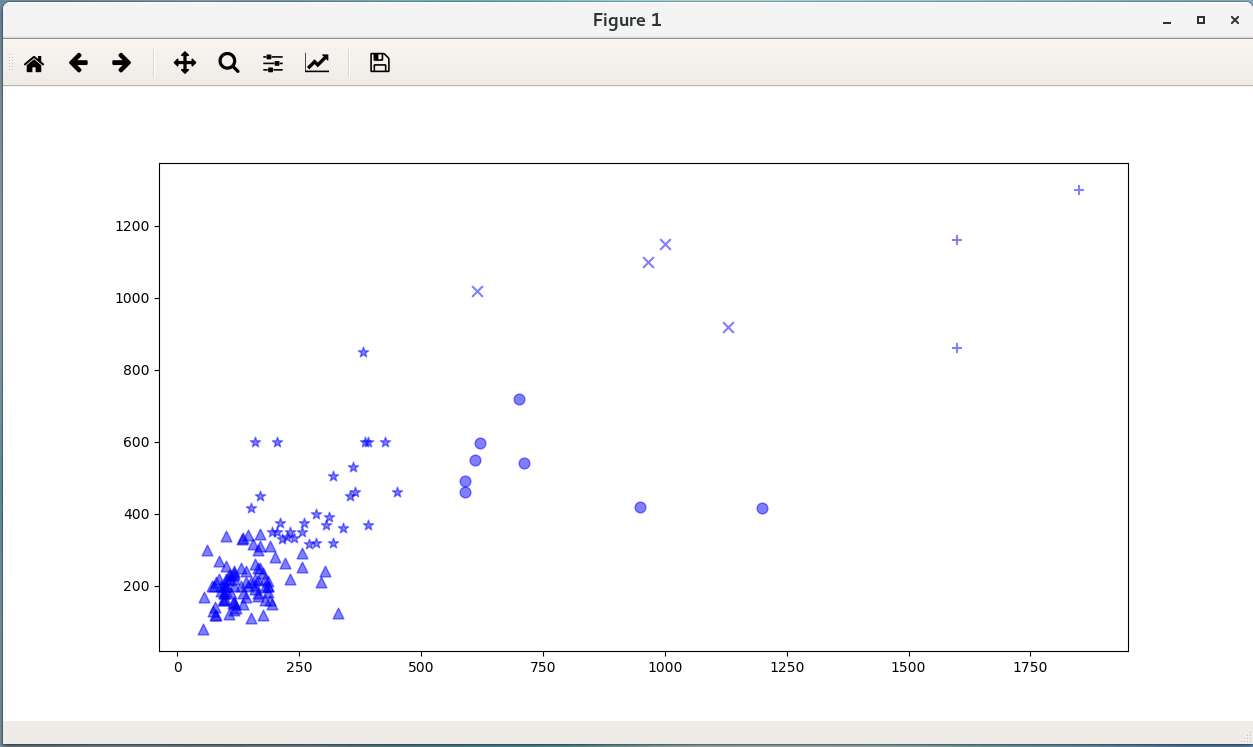
Python机器学习(1):KMeans聚类的更多相关文章
- Python机器学习算法 — K-Means聚类
K-Means简介 步,直到每个簇的中心基本不再变化: 6)将结果输出. K-Means的说明 如图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示: (a)刚开始时是原始数据,杂乱无章 ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- 【Python机器学习实战】聚类算法(1)——K-Means聚类
实战部分主要针对某一具体算法对其原理进行较为详细的介绍,然后进行简单地实现(可能对算法性能考虑欠缺),这一部分主要介绍一些常见的一些聚类算法. K-means聚类算法 0.聚类算法算法简介 聚类算法算 ...
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 菜鸟之路——机器学习之Kmeans聚类个人理解及Python实现
一些概念 相关系数:衡量两组数据相关性 决定系数:(R2值)大概意思就是这个回归方程能解释百分之多少的真实值. Kmeans聚类大致就是选择K个中心点.不断遍历更新中心点的位置.离哪个中心点近就属于哪 ...
- 机器学习算法-K-means聚类
引文: k均值算法是一种聚类算法.所谓聚类.他是一种无监督学习,将类似的对象归到同一个蔟中.蔟内的对象越类似,聚类的效果越好. 聚类和分类最大的不同在于.分类的目标事先已知.而聚类则不一样. 由于其产 ...
- 转载 | Python AI 教学│k-means聚类算法及应用
关注我们的公众号哦!获取更多精彩哦! 1.问题导入 假如有这样一种情况,在一天你想去某个城市旅游,这个城市里你想去的有70个地方,现在你只有每一个地方的地址,这个地址列表很长,有70个位置.事先肯定要 ...
- 【Python机器学习实战】聚类算法(2)——层次聚类(HAC)和DBSCAN
层次聚类和DBSCAN 前面说到K-means聚类算法,K-Means聚类是一种分散性聚类算法,本节主要是基于数据结构的聚类算法--层次聚类和基于密度的聚类算法--DBSCAN两种算法. 1.层次聚类 ...
- 机器学习: K-means 聚类
今天介绍机器学习里常见的一种无监督聚类算法,K-means.我们先来考虑在一个高维空间的一组数据集,S={x1,x2,...,xN}" role="presentation&quo ...
- 机器学习:K-Means聚类算法
本文来自同步博客. 前面几篇文章介绍了回归或分类的几个算法,它们的共同点是训练数据包含了输出结果,要求算法能够通过训练数据掌握规律,用于预测新输入数据的输出值.因此,回归算法或分类算法被称之为监督学习 ...
随机推荐
- HDU2873 Bomb Game(二维SG函数)
Bomb Game Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total ...
- 2017-2018-2 20155309南皓芯 Exp8 WEB基础实践
基础问题回答 (1)什么是表单 表单在网页中主要负责数据采集功能.一个表单有三个基本组成部分: 表单标签:这里面包含了处理表单数据所用CGI程序的URL以及数据提交到服务器的方法. 表单域:包含了文本 ...
- Kotlin 喧嚣过后,谈谈 Java 程序员未来的出路
http://blog.jobbole.com/111422 Java 生态圈 Java 的生态环境开放.自由,在Sun/Oracle.Google.Apache.Eclipse基金会等各大厂商,还有 ...
- 【BZOJ5110】[CodePlus2017]Yazid 的新生舞会
题解: 没笔的时候我想了一下 发现如果不是出现一半次数而是k次,并不太会做 然后我用前缀和写了一下发现就是维护一个不等式: 于是就可以随便维护了
- 利用python将表格中的汉字转化为拼音
缺少包时用pip install 进行安装,例如: pip install xlsxwriter 完成代码如下: #!/usr/bin/python #-*-coding:utf-8-*- #fr ...
- Python开发之pip使用详解
1 pip的优点 pip如今已经成为了Python的一大特色,可以很方便得协助Python开发者进行包管理.综合来说,匹配拥有如下优点: pip提供了丰富的功能,其竞争对手easy_install只支 ...
- 命令:hash
简介 hash命令是bash的内置命令. 我们知道在bash中执行外部命令,会根据环境变量PATH来逐一搜索命令的路径. hash就是用于记住命令的路径,并且在下次执行命令的时候直接通过hash获取而 ...
- 【java并发核心一】Semaphore 的使用思路
最近在看一本书<Java并发编程 核心方法与框架>,打算一边学习一边把学习的经验记下来,所粘贴的代码都是我运行过的,大家一起学习,欢迎吐槽. 估计也没多少人看我的博客,哈哈,那么我还是会记 ...
- xss总结--2018自我整理
0x00前言 因为ctf中xss的题目偏少(因为需要机器人在后台点选手的连接2333),所有写的比较少 这里推荐个环境http://test.xss.tv/ 0x01xss作用 常见的输出函数:pri ...
- 11.7 NOIP模拟赛
目录 2018.11.7 NOIP模拟 A 序列sequence(two pointers) B 锁lock(思路) C 正方形square(埃氏筛) 考试代码 B C 2018.11.7 NOIP模 ...