python爬虫训练——正则表达式+BeautifulSoup爬图片
这次练习爬 传送门 这贴吧里的美食图片。
如果通过img标签和class属性的话,用BeautifulSoup能很简单的解决,但是这次用一下正则表达式,我这也是参考了该博主的博文:传送门
所有图片的src地址前面都是相同的,所以根据这个就可以筛选出我们想要的图片了。也就是在匹配时不用class属性的值,而是用正则表达式去匹配src的值。
from urllib import request
from bs4 import BeautifulSoup
import re def get_page(url, tot_page):
url_list = []
for i in range(1,tot_page):
new_url = re.sub(('=(.*)'),'%s%s' %('=',i), url)
url_list.append(new_url)
return url_list if __name__ == '__main__':
url = 'http://tieba.baidu.com/p/4792769205?pn=1'
path = 'D:\python\project\爬虫结果'
count = 0
url_list = get_page(url, 4)
for url in url_list:
print(url)
page = request.urlopen(url).read().decode()
soup = BeautifulSoup(page, 'lxml')
regex = re.compile("http://imgsrc.baidu.com/forum/w%3D580/sign=.+\.jpg")
pic_list = soup.findAll('img', {'src': regex})
for pic in pic_list:
pic = pic['src']
request.urlretrieve(pic, '%s/%s.jpg' % (path, count))
count += 1
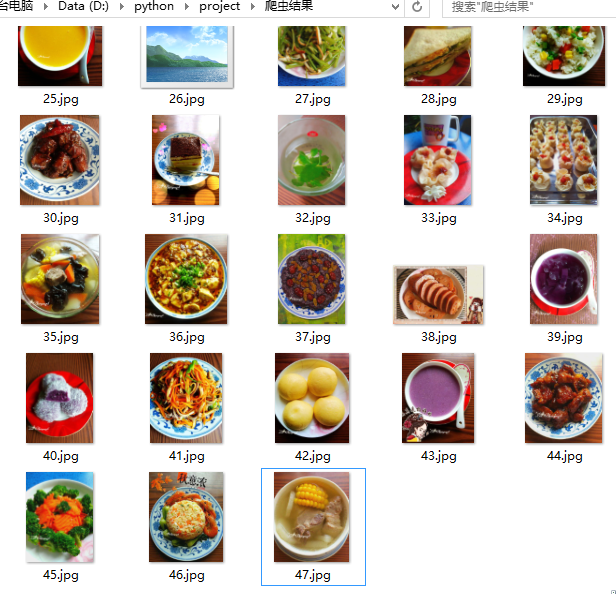
我就爬了3页的图片:
python爬虫训练——正则表达式+BeautifulSoup爬图片的更多相关文章
- 【python爬虫和正则表达式】爬取表格中的的二级链接
开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的.前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个 ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(一)——设置代理IP
自己写了一个爬虫爬取豆瓣小说,后来为了应对请求不到数据,增加了请求的头部信息headers,为了应对豆瓣服务器的反爬虫机制:防止请求频率过快而造成“403 forbidden”,乃至封禁本机ip的情况 ...
- python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1.问题描述: 爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目标网址:https://sz.lianjia.com ...
- python爬虫-80电子书,爬图片
''' 作者:Caric_lee 日期:2018 查看图片 ''' import requests from bs4 import BeautifulSoup r = requests.get(&qu ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(三)——将小说信息写入文件
#-*-coding:utf-8-*- import urllib2 from bs4 import BeautifulSoup class dbxs: def __init__(self): sel ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(二)——回车分段打印小说信息
在上一篇文章中,我主要是设置了代理IP,虽然得到了相关的信息,但是打印出来的信息量有点多,要知道每打印一页,15个小说的信息全部会显示而过,有时因为屏幕太小,无法显示全所有的小说信息,那么,在这篇文章 ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
随机推荐
- python内置函数zip
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表. 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以 ...
- mysql+servlet+jsp实现数据库的增删改查
首先,了解数据库目前我们仅仅用来存放数据,在这里我们在数据库中生成一个表,包含id,classname,teacher,location.Tomcat用来配置eclipse,只有这样我们才能使用JSP ...
- Linux基础命令---显示路由表route
route route指令用于显示或者修改IP路由表.它的主要用途是在使用ifconfig(8)程序配置接口后,通过接口设置到特定主机或网络的静态路由.当使用add或del选项时,路由将修改路由表.如 ...
- Oracle 数据库实现数据合并:merge
1.使用update进行数据更新 1)最简单的更新 update tablea a set a.price=1.00 2)带条件的数据更新 update tablea a set a.price = ...
- SpringMVC之JSON交互
#什么是json? json是一种用于储存数据格式,是js脚本语言的子集. #json的作用? 它可以传递对象.数组等数据结构.如果是单个数据,则要用数组,不用对象,因为对象都是键值对的 方式去存储, ...
- Spring/SpringMVC/MyBatis(持久层、业务层、控制层思路小结)
准备工作: ## 7 导入省市区数据到数据库中 1. 从FTP下载SQL脚本文件 2. 把脚本文件移动到易于描述绝对路径的位置 3. 进入MySQL控制台 4. 使用`xxx_xxx`数据库 5. 运 ...
- mybatis总结之一
今日内容:mybatis数据持久层的一种表现,在一定程度上,取代了jdbc. 1.建maven...... 在pom.xml中进行配置,添加mabatis包,junit测试jar包,添加连接mysql ...
- Elasticstarch 相关
索引: 在Elasticsearch中存储数据的行为就叫做索引(indexing),不过在索引之前,我们需要明确数据应该存储在哪里. 在Elasticsearch中,文档归属于一种类型(type),而 ...
- Django Form&ModelForm
ModelForm: 首先导入所需模块 from django.forms import ModelFormfrom django.forms import widgets as form_widge ...
- MD5算法详解
MD5是什么 message-digest algorithm 5(信息-摘要算法).经常说的“MD5加密”,就是它→信息-摘要算法.在下载一下东西时,经常在一些压缩包属性里,看到md5值.而且这个下 ...