【Python全栈-后端开发】数据库进阶
数据库进阶
python关于mysql的API---pymysql模块
pymsql是Python中操作MySQL的模块,其使用方法和py2的MySQLdb几乎相同。
模块安装
pip install pymysql
执行sql语句
import pymysql # 连接数据库 xiong
conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='root',db='xiong') #更改获取数据结果的数据类型,默认是元组,可以改为字典等:conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor = conn.cursor()
# cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # sql = """CREATE TABLE new_EMPLOYEE (
# FIRST_NAME CHAR(20) NOT NULL,
# LAST_NAME CHAR(20),
# AGE INT,
# SEX CHAR(1),
# INCOME FLOAT )""" # 创建表
row_affected = cursor.execute("create table t1(id INT ,name VARCHAR(20))")
# 向表t1中插入数据
row_affected=cursor.execute("INSERT INTO t1(id,name) values (1,'alvin'),(2,'xialv'),(3,'xiong')")
# 更改数据
cursor.execute("update t1 set name = 'silv2' where id=2") cursor.execute("INSERT INTO t1(id,name) values (7,'zhou'),(8,'zhang'),(9,'fan')") #查询数据
row_affected=cursor.execute("select * from t1")
print(row_affected) #3 --共有3行数据 print(cursor.fetchone()) #第一条
print(cursor.fetchone()) #第二条
print(cursor.fetchmany(3)) #第3、4、5条 #scroll 移动光标 cursor.execute("select * from t1")
print(cursor.fetchall()) #光标到最后一个位置了 # 相对绝对位置移动,移动到第2位
cursor.scroll(3 , mode='absolute') print(cursor.fetchmany(3)) print(cursor.fetchall()) # # 相对当前位置移动,负数 向上移动,正数向下移动
cursor.scroll(-1,mode='relative')
print(cursor.fetchone()) # 删除数据
cursor.execute("delete from t1 where id=2")
cursor.execute("select * from t1")
print(cursor.fetchall())
# 修改表中数据
cursor.execute("UPDATE t1 set name = 'xxx' WHERE id = 3")
cursor.execute("select * from t1")
print(cursor.fetchall()) conn.commit()
cursor.close()
conn.close()
执行顺序:
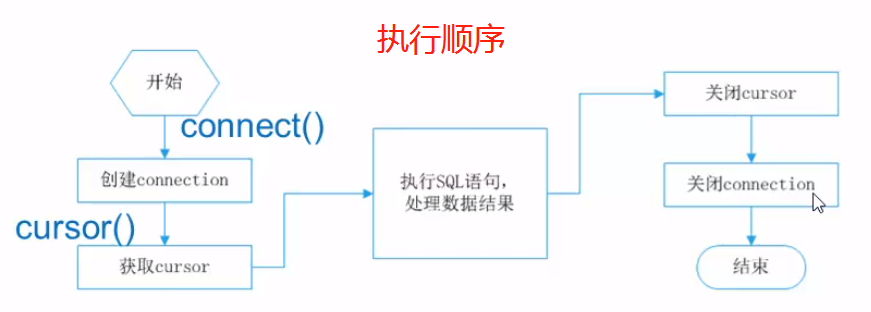


cursor 的属性和方法:

事务
事务命令
事务指逻辑上的一组操作,组成这组操作的各个单元,要不全部成功,要不全部不成功。
数据库开启事务命令
-- start transaction 开启事务
-- Rollback 回滚事务,即撤销指定的sql语句(只能回退insert delete update语句),回滚到上一次commit的位置
-- Commit 提交事务,提交未存储的事务
--
-- savepoint 保留点 ,事务处理中设置的临时占位符 你可以对它发布回退(与整个事务回退不同)
转账实例:
UPDATE account set balance=balance-5000 WHERE name=”yuan”;
UPDATE account set balance=balance+5000 WHERE name=”xialv”;
savepoint 保留点
create table test2(id int PRIMARY KEY auto_increment,name VARCHAR(20)) engine=innodb;
INSERT INTO test2(name) VALUE ("alvin"),
("yuan"),
("xialv"); start transaction;
insert into test2 (name)values('silv');
select * from test2;
commit; -- 保留点 start transaction;
insert into test2 (name)values('wu');
savepoint insert_wu;
select * from test2; delete from test2 where id=4;
savepoint delete1;
select * from test2; delete from test2 where id=1;
savepoint delete2;
select * from test2; rollback to delete1; select * from test2; savepoint
yuan先生
start transaction ;
select * from money; insert into money (name,salary) values ("wu",8000);
savepoint insert_wu;
select * from money; insert into money (name,salary) values ("chen",7000);
savepoint insert_chen;
select * from money; delete from money where name="wang";
savepoint delete_wang;
select * from money; delete from money where name="xiong";
savepoint delete_xiong;
select * from money; delete from money where id=1;
savepoint delete_id1;
select * from money; -- 返回到增加wu的时候
rollback to insert_wu;
select * from money;
-- 返回到增加chen的时候
rollback to insert_chen;
select * from money;
-- 返回到删除wang的时候
rollback to delete_wang;
select * from money;
-- 返回到删除xiong的时候
rollback to delete_xiong;
select * from money;
python中调用数据库启动事务的方式
import pymysql # 连接数据库 xiong
conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='root',db='xiong') #更改获取数据结果的数据类型,默认是元组,可以改为字典等:conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor = conn.cursor()
# cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 创建表
new_table = """create table account(
id INT primary key auto_increment,
name VARCHAR(20),
balance double)""" cursor.execute(new_table)
# 向表account中插入数据
insert_data = """INSERT INTO account(name,balance) values
('alvin',5000),
('xialv',10000),
('xiong',15000),
('wang',4000)""" cursor.execute(insert_data) cursor.execute("select * from account")
print(cursor.fetchall()) try:
insertData1 = "INSERT INTO account (name,balance) VALUES ('oldboy',4000)"
updateData2 = "update account set balance=balance-3000 where name='alvin'"
updateData3 = "update account set balance=balance+3000 where name='xiong'" cursor.execute(insertData1)
conn.commit() cursor.execute(updateData2)
raise Exception #产生一个异常
cursor.execute(updateData3)
cursor.close()
conn.commit except Exception as e:
print("撤销事务之前")
cursor.execute("select * from account")
print(cursor.fetchall())
conn.rollback()
conn.commit()
print("撤销事务之后")
cursor.execute("select * from account")
print(cursor.fetchall())
事务特性
<1> 原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
<2> 一致性(Consistency):事务前后数据的完整性必须保持一致。在事务执行之前数据库是符合数据完整性约束的,无论事务是否执行成功,事务结束后的数据库中的数据也应该是符合完整性约束的。在某一时间点,如果数据库中的所有记录都能保证满足当前数据库中的所有约束,则可以说当前的数据库是符合数据完整性约束的。
比如删部门表前应该删掉关联员工(已经建立外键),如果数据库服务器发生错误,有一个员工没删掉,那么此时员工的部门表已经删除,那么就不符合完整性约束了,所以这样的数据库也就性能太差啦!
<3>隔离性(Isolation):事务的隔离性是指多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离。
<4>持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
三、隔离性:
将数据库设计为串行化程的数据库,让一张表在同一时间内只能有一个线程来操作。如果将数据库设计为这样,那数据库的效率太低了。所以数据库的设计这没有直接将数据库设计为串行化,而是为数据库提供多个隔离级别选项,使数据库的使用者可以根据使用情况自己定义到底需要什么样的隔离级别。
不考虑隔离性可能出现的问题:
脏读
--一个事务读取到了另一个事务未提交的数据,这是特别危险的,要尽力防止。
a 1000
b 1000
a:
start transaction;
update set money=money+100 where name=b;
b:
start transaction;
select * from account where name=b;--1100
commit;
a:
rollback;
b: start transaction;
select * from account where name=b;--1000
不可重复读
--在一个事务内读取表中的某一行数据,多次读取结果不同。(一个事务读取到了另一个事务已经提交
-- 的数据--增加记录、删除记录、修改记录),在某写情况下并不是问题,在另一些情况下就是问题。 a:
start transaction;
select 活期账户 from account where name=b;--1000 活期账户:1000
select 定期账户 from account where name=b;--1000 定期账户:1000
select 固定资产 from account where name=b;--1000 固定资产:1000
------------------------------
b:
start transaction;
update set money=0 where name=b;
commit;
------------------------------
select 活期+定期+固定 from account where name=b; --2000 总资产: 2000
虚读
是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。(一个事务读取到了另一个事务已经提交的数据---增加记录、删除记录),在某写情况下并不是问题,在另一些情况下就是问题。 b 1000
c 2000
d 3000
a:
start transaction
select sum(money) from account;---3000 3000
-------------------
d:start transaction;
insert into account values(d,3000);
commit;
-------------------
select count(*)from account;---3 3
3000/3 = 1000 1000
四个隔离级别:
Serializable:可避免脏读、不可重复读、虚读情况的发生。(串行化)
Repeatable read:可避免脏读、不可重复读情况的发生。(可重复读)不可以避免虚读
Read committed:可避免脏读情况发生(读已提交)
Read uncommitted:最低级别,以上情况均无法保证。(读未提交)
安全性考虑:Serializable>Repeatable read>Read committed>Read uncommitted
数据库效率:Read uncommitted>Read committed>Repeatable read>Serializable
一般情况下,我们会使用Repeatable read、Read committed mysql数据库默认的数据库隔离级别Repeatable read
mysql中设置数据库的隔离级别语句:
set [global/session] transaction isolation level xxxx;
如果使用global则修改的是数据库的默认隔离级别,所有新开的窗口的隔离级别继承自这个默认隔离级别如果使用session修改,则修改的是当前客户端的隔离级别,和数据库默认隔离级别无关。当前的客户端是什么隔离级别,就能防止什么隔离级别问题,和其他客户端是什么隔离级别无关。
mysql中设置数据库的隔离级别语句:
select @@tx_isolation;
索引
一 索引简介
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。
索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
索引特点:创建与维护索引会消耗很多时间与磁盘空间,但查询速度大大提高!
二 索引语法
--创建表时
--语法:
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
); -------------------------------- --创建普通索引示例: CREATE TABLE emp1 (
id INT,
name VARCHAR(30) ,
resume VARCHAR(50),
INDEX index_emp_name (name)
--KEY index_dept_name (dept_name)
); --创建唯一索引示例: CREATE TABLE emp2 (
id INT,
name VARCHAR(30) ,
bank_num CHAR(18) UNIQUE ,
resume VARCHAR(50),
UNIQUE INDEX index_emp_name (name)
); --创建全文索引示例: CREATE TABLE emp3 (
id INT,
name VARCHAR(30) ,
resume VARCHAR(50),
FULLTEXT INDEX index_resume (resume)
); --创建多列索引示例: CREATE TABLE emp4 (
id INT,
name VARCHAR(30) ,
resume VARCHAR(50),
INDEX index_name_resume (name, resume)
); --------------------------------- ---添加索引 ---CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ; ---ALTER TABLE在已存在的表上创建索引 ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ; CREATE INDEX index_emp_name on emp1(name);
ALTER TABLE emp2 ADD UNIQUE INDEX index_bank_num(band_num); -- 删除索引 语法:DROP INDEX 索引名 on 表名 DROP INDEX index_emp_name on emp1;
DROP INDEX bank_num on emp2;
三、索引测试实验
--创建表
create table Indexdb.t1(id int,name varchar(20)); --存储过程 delimiter $$
create procedure autoinsert()
BEGIN
declare i int default 1;
while(i<500000)do
insert into Indexdb.t1 values(i,'yuan');
set i=i+1;
end while;
END$$ delimiter ; --调用函数
call autoinsert(); -- 花费时间比较:
-- 创建索引前
select * from Indexdb.t1 where id=300000;--0.32s
-- 添加索引
create index index_id on Indexdb.t1(id);
-- 创建索引后
select * from Indexdb.t1 where id=300000;--0.00s
【Python全栈-后端开发】数据库进阶的更多相关文章
- 【Python全栈-后端开发】嵩天老师-Django
嵩天老师-Python云端系统开发入门教程(Django) 视频地址:https://www.bilibili.com/video/av19801429 课前知识储备: 一.课程介绍: 分久必合.合久 ...
- 【Python全栈-后端开发】Django进阶2-Form表单
Django进阶2-Form表单 Django的Form主要具有一下几大功能: 生成HTML标签(可以保留上次输入内容) 验证用户数据(显示错误信息) HTML Form提交保留上次提交数据 初始化页 ...
- 【Python全栈-后端开发】Django进阶之Model操作复习
Django进阶之Model操作复习 一.字段 AutoField(Field) - int自增列,必须填入参数 primary_key=True BigAutoField(AutoField) - ...
- 【Python全栈-后端开发】Django进阶1-分页
Django[进阶篇-1 ]分页 分页 一.Django内置分页 from django.core.paginator import Paginator, EmptyPage, PageNotAnIn ...
- 【Python全栈-后端开发】MySQL数据库-练习题
MySQL数据库-练习题 一.表关系 请创建如下表,并创建相关约束 二.操作表 1.自行创建测试数据 2.查询“生物”课程比“物理”课程成绩高的所有学生的学号: 3.查询平均成绩大于60分的同学的学号 ...
- 【Python全栈-后端开发】Django入门基础
Django基础知识 一. 什么是web框架? 框架,即framework,特指为解决一个开放性问题而设计的具有一定约束性的支撑结构,使用框架可以帮你快速开发特定的系统,简单地说,就是你用别人搭建好的 ...
- 【Python全栈-后端开发】Django入门基础-2
Django入门基础知识-2 一 .模版 一.模版的组成 HTML代码+逻辑控制代码 二.逻辑控制代码的组成 1 变量(使用双大括号来引用变量) {{var_name}} 2 标签(tag)的使用 ...
- Python全栈day26-27(面向对象进阶)
参考 http://www.cnblogs.com/linhaifeng/articles/6204014.html 1,什么是反射 反射的概念是由Smith在1982年首次提出的,主要是指程序可以访 ...
- python全栈学习--day10(函数进阶)
一,引言 现在我有个问题,函数里面的变量,在函数外面能直接引用么? def func1(): m = 1 print(m) print(m) #这行报的错 报错了:NameError: name 'm ...
随机推荐
- django template if return false
如果if的参数不存在于context中就会返回false 参考:http://stackoverflow.com/questions/11107028/django-template-if-true- ...
- 红米3 MoKee 7.1.2_r36 自编译版/去魔趣中心、宙斯盾/息屏禁止刷新UI 2018年5月5日更新
一.ROM简介 MoKee是基于CM二次修改的ROM,本地化系统:农历.归属地.OMS框架.状态栏显示网速/时间显秒等等. 二.ROM自编译DIY简介 1.Lawnchair桌面. 2.Via谷歌版浏 ...
- 教你一招:win10下JDK的安装与环境变量配置
1.到官网下载最新版本的JDK http://www.oracle.com/technetwork/java/javase/downloads/index.html 2.安装JDK,同安装其他软件一样 ...
- Java知多少(21)this关键字详解
this 关键字用来表示当前对象本身,或当前类的一个实例,通过 this 可以调用本对象的所有方法和属性.例如: public class Demo{ public int x = 10; publi ...
- python中的列表、元组、数组——是不是特别容易混淆啊??
列表: 1. 即list, 是python内置的数据类型. 它的形式是: a = [1, 2, 3, 4, 5] 2. 列表内的值是可以改变的: 即可以这样子: a[0] = 100, 把列表的 ...
- net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting head
使用docker 拉镜像的时候,出现下面的错误: net/http: request canceled while waiting for connection (Client.Timeout exc ...
- 服务器最大TCP连接数及调优汇总
启动线程数: 启动线程数=[任务执行时间/(任务执行时间-IO等待时间)]*CPU内核数 最佳启动线程数和CPU内核数量成正比,和IO阻塞时间成反比.如果任务都是CPU计算型任务,那么线程数最多不超过 ...
- python通过get,post方式发送http请求和接收http响应的方法,pythonget
python通过get,post方式发送http请求和接收http响应的方法,pythonget 本文实例讲述了python通过get,post方式发送http请求和接收http响应的方法.分享给大家 ...
- MySQL 错误 1366:1366 Incorrect integer value
错误提示:General error: 1366 Incorrect integer value: '' for column 'pay_type' at row 1 (SQL: INSERT INT ...
- 用开源项目ActivityOptionsICS让ActivityOptions的动画实现兼容
我之前写过一篇文章是讲解ActivityOption的api方法的(http://www.cnblogs.com/tianzhijiexian/p/4087917.html),当时吐槽各种动画不兼容, ...