Spark MLlib 之 aggregate和treeAggregate从原理到应用
在阅读spark mllib源码的时候,发现一个出镜率很高的函数——aggregate和treeAggregate,比如matrix.columnSimilarities()中。为了好好理解这两个方法的使用,于是整理了本篇内容。
由于treeAggregate是在aggregate基础上的优化版本,因此先来看看aggregate是什么.
更多内容参考我的大数据学习之路
aggregate
先直接看一下代码例子:
import org.apache.spark.sql.SparkSession
object AggregateTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("tf-idf").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
// 创建rdd,并分成6个分区
val rdd = spark.sparkContext.parallelize(1 to 12).repartition(6)
// 输出每个分区的内容
rdd.mapPartitionsWithIndex((index:Int,it:Iterator[Int])=>{
Array((s" $index : ${it.toList.mkString(",")}")).toIterator
}).foreach(println)
// 执行agg
val res1 = rdd.aggregate(0)(seqOp, combOp)
}
// 分区内执行的方法,直接加和
def seqOp(s1:Int, s2:Int):Int = {
println("seq: "+s1+":"+s2)
s1 + s2
}
// 在driver端汇总
def combOp(c1: Int, c2: Int): Int = {
println("comb: "+c1+":"+c2)
c1 + c2
}
}
这段代码的主要目的就是为了求和。考虑到spark分区并行计算的特性,在每个分区独立加和,最后再汇总加和。
过程可以参考下面的图片:

首先看一下map阶段,即在每个分区内计算加和。初始情况如蓝色方块所示,内容为:
分区号:里面的内容
如,0分区内的数据为6和8
当执行seqop时,会说先用初始值0开始遍历累加,原理类似如下:
rdd.mapPartitions((it:Iterator)=>{
var sum = init_value // 默认为0
it.foreach(sum + _)
sum
})
因此屏幕上会出现下面的内容,由于分区之间是并行的,所以最后的结果是乱序的:
seq: 0:6
seq: 0:1
seq: 0:3
seq: 1:9
seq: 3:10
seq: 0:2
seq: 0:5
seq: 5:7
seq: 12:12
seq: 0:4
seq: 4:11
seq: 6:8
计算完成后,依次遍历每个分区结果,进行累加:
comb: 0:10
comb: 10:13
comb: 23:2
comb: 25:24
comb: 49:15
comb: 64:14
aggregate的源码也比较简单:
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U = withScope {
var jobResult = Utils.clone(zeroValue, sc.env.serializer.newInstance())
val cleanSeqOp = sc.clean(seqOp)
val cleanCombOp = sc.clean(combOp)
val aggregatePartition = (it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)
val mergeResult = (index: Int, taskResult: U) => jobResult = combOp(jobResult, taskResult)
sc.runJob(this, aggregatePartition, mergeResult)
jobResult
}
treeAggregate
treeAggregate在aggregate的基础上做了一些优化,因为aggregate是在每个分区计算完成后,把所有的数据拉倒driver端,进行统一的遍历合并,这样如果数据量很大,在driver端可能会OOM。
因此treeAggregate在中间多加了一层合并。
先来看看代码,没有任何的变化:
import org.apache.spark.sql.SparkSession
object TreeAggregateTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("tf-idf").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val rdd = spark.sparkContext.parallelize(1 to 12).repartition(6)
rdd.mapPartitionsWithIndex((index:Int,it:Iterator[Int])=>{
Array(s" $index : ${it.toList.mkString(",")}").toIterator
}).foreach(println)
val res1 = rdd.treeAggregate(0)(seqOp, combOp)
println(res1)
}
def seqOp(s1:Int, s2:Int):Int = {
println("seq: "+s1+":"+s2)
s1 + s2
}
def combOp(c1: Int, c2: Int): Int = {
println("comb: "+c1+":"+c2)
c1 + c2
}
}
输出的结果则发生了变化,首先分区内的操作不变:
3 : 3,10
2 : 2
0 : 6,8
1 : 1,9
4 : 4,11
5 : 5,7,12
seq: 0:3
seq: 0:6
seq: 3:10
seq: 6:8
seq: 0:2
seq: 0:1
seq: 1:9
seq: 0:4
seq: 4:11
seq: 0:5
seq: 5:7
seq: 12:12
...
在合并的时候发生了 变化:
comb: 10:13
comb: 23:24
comb: 14:2
comb: 16:15
comb: 47:31
配合下面的流程图,可以更好的理解:
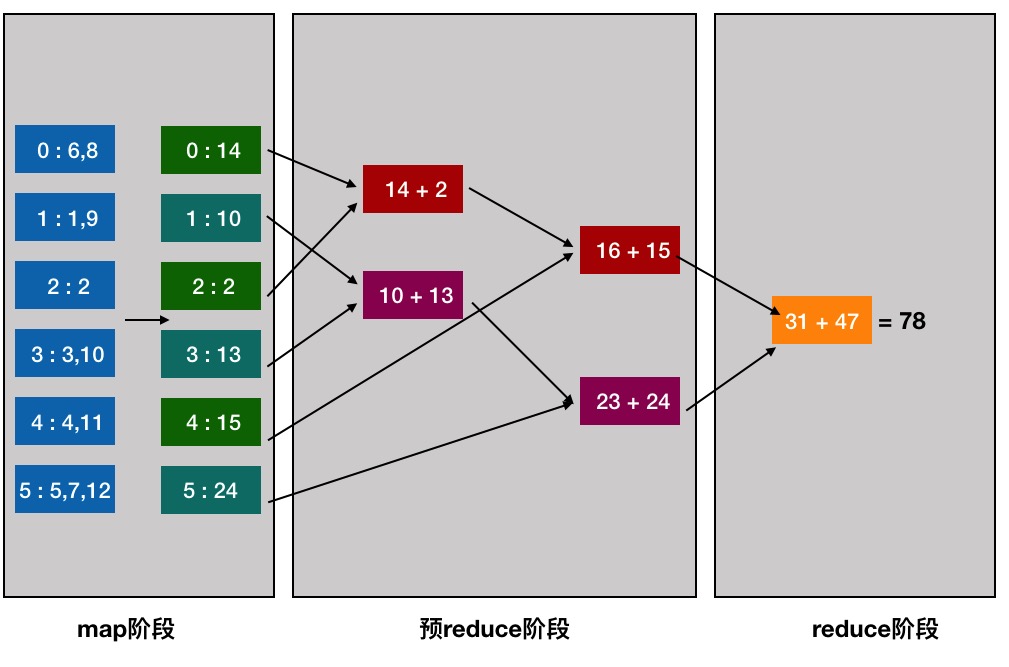
搭配treeAggregate的源码来看一下:
def treeAggregate[U: ClassTag](zeroValue: U)(
seqOp: (U, T) => U,
combOp: (U, U) => U,
depth: Int = 2): U = withScope {
require(depth >= 1, s"Depth must be greater than or equal to 1 but got $depth.")
if (partitions.length == 0) {
Utils.clone(zeroValue, context.env.closureSerializer.newInstance())
} else {
// 这里都没什么变化,在分区中遍历数据累加
val cleanSeqOp = context.clean(seqOp)
val cleanCombOp = context.clean(combOp)
val aggregatePartition =
(it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)
var partiallyAggregated = mapPartitions(it => Iterator(aggregatePartition(it)))
// 关键是这下面的内容 !!!!
// 首先获得当前的分区数
var numPartitions = partiallyAggregated.partitions.length
// 计算合适的并行度,我这里相当于6^(1/2),也就是2.4左右,ceill向上取整后变成3.
// max(3,2)得到最后的结果为3。即每个树的分枝有3个叶子节点
val scale = math.max(math.ceil(math.pow(numPartitions, 1.0 / depth)).toInt, 2)
// 遍历分区,通过对scale取模进行合并计算
// 这里判断一下,当前的分区数是否还够分。如果少于条件值 scale+(p/scale),就停止分区
while (numPartitions > scale + math.ceil(numPartitions.toDouble / scale)) {
numPartitions /= scale
val curNumPartitions = numPartitions
// 重新定义分区id,并按照分区id重新分区,执行合并计算
partiallyAggregated = partiallyAggregated.mapPartitionsWithIndex {
(i, iter) => iter.map((i % curNumPartitions, _))
}.reduceByKey(new HashPartitioner(curNumPartitions), cleanCombOp).values
}
// 最后统计结果
partiallyAggregated.reduce(cleanCombOp)
}
}
spark中的应用
// matrix求相似度
def columnSimilarities(threshold: Double): CoordinateMatrix = {
... columnSimilaritiesDIMSUM(computeColumnSummaryStatistics().normL2.toArray, gamma)
}
// 统计每一个向量的相关数据,里面包含了min max 等等很多信息
def computeColumnSummaryStatistics(): MultivariateStatisticalSummary = {
val summary = rows.treeAggregate(new MultivariateOnlineSummarizer)(
(aggregator, data) => aggregator.add(data),
(aggregator1, aggregator2) => aggregator1.merge(aggregator2))
updateNumRows(summary.count)
summary
}
了解了treeAggregate之后,后续就可以看matrix的并行求解相似度的源码了!敬请期待吧...
参考
Spark MLlib 之 aggregate和treeAggregate从原理到应用的更多相关文章
- Spark MLlib 之 大规模数据集的相似度计算原理探索
无论是ICF基于物品的协同过滤.UCF基于用户的协同过滤.基于内容的推荐,最基本的环节都是计算相似度.如果样本特征维度很高或者<user, item, score>的维度很大,都会导致无法 ...
- 梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python) http://blog.csdn.net/liulingyuan6/article/details ...
- Spark MLlib特征处理:OneHotEncoder OneHot编码 ---原理及实战
http://m.blog.csdn.net/wangpei1949/article/details/53140372 Spark MLlib特征处理:OneHotEncoder OneHot编码 - ...
- Spark MLlib LDA 基于GraphX实现原理及源代码分析
LDA背景 LDA(隐含狄利克雷分布)是一个主题聚类模型,是当前主题聚类领域最火.最有力的模型之中的一个,它能通过多轮迭代把特征向量集合按主题分类.眼下,广泛运用在文本主题聚类中. LDA的开源实现有 ...
- 《Spark MLlib机器学习实践》内容简介、目录
http://product.dangdang.com/23829918.html Spark作为新兴的.应用范围最为广泛的大数据处理开源框架引起了广泛的关注,它吸引了大量程序设计和开发人员进行相 ...
- Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就拟牛顿法L-BFGS的由来做一个简要的回顾,然后就其在spark mllib中的实现进行源码走读. 拟牛顿法 数学原理 代码实现 L-BFGS算法中使 ...
- Spark MLlib LDA 源代码解析
1.Spark MLlib LDA源代码解析 http://blog.csdn.net/sunbow0 Spark MLlib LDA 应该算是比較难理解的,当中涉及到大量的概率与统计的相关知识,并且 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
随机推荐
- python操作haproxy.cfg文件
需求 1.查 输入:www.oldboy.org 获取当前backend下的所有记录 2.新建 输入: arg = { 'bakend': 'www.oldboy.org', 'record':{ ' ...
- centos6.5下编译安装mariadb-10.0.20
源码编译安装mariadb-10.0.20.tar.gz 一.安装cmake编译工具 跨平台编译器 # yum install -y gcc* # yum install -y cmake 解决依赖关 ...
- windows下配置mysql数据库监视工具Mysqlreport
该工具除了可以监控本机Mysql数据库外,也可以监控远程服务器mysql数据库 需要的工具: 1:perl脚本解析工具安装: http://www.activestate.com/activeperl ...
- centos7 部署 docker ce
=============================================== 2019/4/9_第1次修改 ccb_warlock === ...
- vue系列之Vue-cli
Vue-cli是Vue的脚手架工具 vue-cli 地址:https://github.com/vuejs/vue-cli 安装 npm install -g vue-cli 使用 vue init ...
- C#控制台中创建数据库连接
与数据库的连接主要有以下三种类: sqlconnection:数据库连接类: sqlcommand:数据库操作: sqldatareader:数据库读取: SqlDataReader dr = cmd ...
- 【python】已安装模块提示ImportError: No module named
今天遇到了一个问题,运行代码时出现错误 Traceback (most recent call last): File , in <module> import zmq ImportErr ...
- CentOS安装redis-audit 但执行时出错未解决 记录一下安装过程
网上很多安装过程都太老了,测试很多方法终于成功了,但执行时还是出错,哪位熟悉的可以告知一下. yum install -y ruby rubygems ruby-devel git gcc gem s ...
- 交叉编译和安装ARM板(RK3288)和Linux 3.10上的RTL8188无线网卡驱动
插入无线网卡,输入ifconfig,发现没有检测到网卡. 输入lsusb,查看无线网卡型号. 我用的无线网卡是EDUP的网卡,包装盒里有一张驱动光盘,把光盘里linux下的驱动目录复制下来.如果没有驱 ...
- 【AtCoder】全国統一プログラミング王決定戦予選/NIKKEI Programming Contest 2019
感觉最近好颓,以后不能这么颓了,要省选了,争取省选之前再板刷一面ATC??? A - Subscribers 简单容斥 #include <bits/stdc++.h> #define f ...