[No0000145]深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing)理解堆与栈2/4
前言
简介
参数,大画面
- 栈会分配一块内存空间给程序执行所需要的信息(我们叫它栈结构Stack Frame)。一个栈结构包含方法调用地址(指针),它以一个GOTO指令的形式存在栈里。因此,当程序执行完方法(method)时,它会知道怎么样返回并继续执行代码。
- 方法的所有参数将被复制到栈里,这是我们将要更加详细介绍的部分。
- 控制被传递到JIT编译过的方法里,同时线程开始执行代码。此时,我们将有另一个方法呈现在栈结构的“回调栈”里。
- public int AddFive(int pValue)
- {
- int result;
- result = pValue + 5;
- return result;
- }
栈像下图所示:
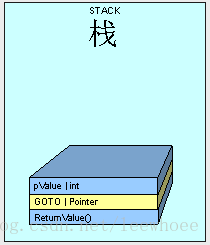
值类型传递
- class Class1
- {
- public void Go()
- {
- int x = 5;
- AddFive(x);
- Console.WriteLine(x.ToString());
- }
- public int AddFive(int pValue)
- {
- pValue += 5;
- return pValue;
- }
- }
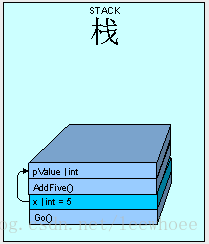
当代码执行时,栈为x分配一块内存空间并存储值5

- public struct MyStruct
- {
- long a, b, c, d, e, f, g, h, i, j, k, l, m;
- }
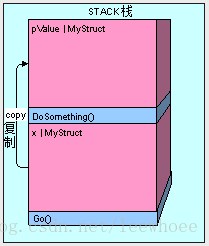
让我们看看执行下面代码Go()方法时再到DoSomething()方法会发生的情况:
- public void Go()
- {
- MyStruct x = new MyStruct();
- DoSomething(x);
- }
- public void DoSomething(MyStruct pValue)
- {
- // 省略具体实现....
- }
{
MyStruct x = new MyStruct();
DoSomething(ref x);
}
public struct MyStruct
{
long a, b, c, d, e, f, g, h, i, j, k, l, m;
}
public void DoSomething(ref MyStruct pValue)
{
// 省略实现....
}
- public void Go()
- {
- MyStruct x = new MyStruct();
- x.a = 5;
- DoSomething(ref x);
- Console.WriteLine(x.a.ToString());
- }
- public void DoSomething(ref MyStruct pValue)
- {
- pValue.a = 12345;
- }
前言
简介
引用类型传递
- public class MyInt
- {
- public int MyValue;
- }
然后调用Go()方法,MyInt会被放到堆里因为它是一个引用类型。
- public void Go()
- {
- MyInt x = new MyInt();
- }

- public void Go()
- {
- MyInt x = new MyInt();
- x.MyValue = 2;
- DoSomething(x);
- Console.WriteLine(x.MyValue.ToString());
- }
- public void DoSomething(MyInt pValue)
- {
- pValue.MyValue = 12345;
- }
会发生这种情况:
- 开始调用Go(),栈分配一块内存空间给x。
- 执行行到DoSomething(),栈分配一块内在空间给pValue。
- x的值是堆中MyInt对应在栈里的内存地址,复制x给pValue。
用引用的方式传递引用类型
- public class Thing
- {
- }
- public class Animal:Thing
- {
- public int Weight;
- }
- public class Vegetable:Thing
- {
- public int Length;
- }
执行下面的Go()方法:
- public void Go()
- {
- Thing x = new Animal();
- Switcharoo(ref x);
- Console.WriteLine(
- "x is Animal : "
- + (x is Animal).ToString());
- Console.WriteLine(
- "x is Vegetable : "
- + (x is Vegetable).ToString());
- }
- public void Switcharoo(ref Thing pValue)
- {
- pValue = new Vegetable();
- }
x最终变成Vegetable。
- x is Animal : False
- x is Vegetable : True
让我们看看堆栈里到底发生了什么情况

- 调用Go()方法,栈分配一块内存空间给x。
- 堆分配一块内存空间给Animal。
- 开始执行Switcharoo()方法,栈分配一块内存空间给pValue并指向x。
- 栈分配一块内存空间给Vegetable。
- pValue改变了x的值使其指向Vegetable的内在地址。
总结
Even though with the .NET framework we don't have to actively worry about memory management and garbage collection (GC), we still have to keep memory management and GC in mind in order to optimize the performance of our applications. Also, having a basic understanding of how memory management works will help explain the behavior of the variables we work with in every program we write. In this article I'll cover some of the behaviors we need to be aware of when passing parameters to methods.
In Part I we covered the basics of the Heap and Stack functionality and where Variable Types and Reference Types are allocated as our program executes. We also covered the basic idea of what a Pointer is.
Parameters, the Big Picture.
Here's the detailed view of what happens as our code executes. We covered the basics of what happens when we make a method call in Part I. Let's get into more detail...
When we make a method call here's what happens:
- Space is allocated for information needed for the execution of our method on the stack (called a Stack Frame). This includes the calling address (a pointer) which is basically a GOTO instruction so when the thread finishes running our method it knows where to go back to in order to continue execution.
- Our method parameters are copied over. This is what we want to look at more closely.
- Control is passed to the JIT'ted method and the thread starts executing code. Hence, we have another method represented by a stack frame on the "call stack".
The code:
public int AddFive(int pValue)
{
int result;
result = pValue + 5;
return result;
}
Will make the stack look like this:
NOTE : the method does not live on the stack, and is illustrated here just for reference as the beginnnig of the stack frame.
As discussed in Part I, Parameter placement on the stack will be handled differently depending on whether it is a value type or a reference type. A value types is copied over and the reference of a reference type is copied over.ed over.
Passing Value Types.
Here's the catch with value types...
First, when we are passing a value types, space is allocated and the value in our type is copied to the new space on the stack. Look at the following method:
class Class1
{
public void Go()
{
int x = 5;
AddFive(x);
Console.WriteLine(x.ToString());
}
public int AddFive(int pValue)
{
pValue += 5;
return pValue;
}
}
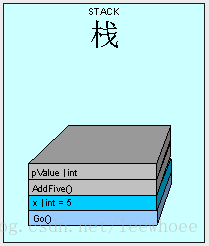
As the method executes, space for "x" is placed on the stack with a value of 5.
Next, AddFive() is placed on the stack with space for it's parameters and the value is copied, bit by bit from x.
When AddFive() has finished execution, the thread is passed back to Go() and because AddFive() has completed, pValue is essentially "removed":
So it makes sense that the output from our code is "5", right? The point is that any value type parameters passed into a method are carbon copies and we count on the original variable's value to be preserved.
One thing to keep in mind is that if we have a very large value type (such as a big struct) and pass it to the stack, it can get very expensive in terms of space and processor cycles to copy it over each time. The stack does not have infinite space and just like filling a glass of water from the tap, it can overflow. A struct is a value type that can get pretty big and we have to be aware of how we are handling it.
Here's a pretty big struct:
public struct MyStruct
{
long a, b, c, d, e, f, g, h, i, j, k, l, m;
}
Take a look at what happens when we execute Go() and get to the DoSomething() method below:
public void Go()
{
MyStruct x = new MyStruct();
DoSomething(x);
}
public void DoSomething(MyStruct pValue)
{
// DO SOMETHING HERE....
}
This can be really inefficient. Imaging if we passed the MyStruct a couple thousand times and you can understand how it could really bog things down.
So how do we get around this problem? By passing a reference to the original value type as follows:
public void Go()
{
MyStruct x = new MyStruct();
DoSomething(ref x);
}
public struct MyStruct
{
long a, b, c, d, e, f, g, h, i, j, k, l, m;
}
public void DoSomething(ref MyStruct pValue)
{
// DO SOMETHING HERE....
}
This way we end up with more memory efficient allocation of our objects in memory.
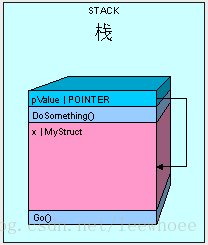
The only thing we have to watch out for when passing our value type by reference is that we have access to the value type's value. Whatever is changed in pValue is changed in x. Using the code below, our results are going to be "12345" because the pValue.a actually is looking at the memory space where our original x variable was declared.
public void Go()
{
MyStruct x = new MyStruct();
x.a = 5;
DoSomething(ref x);
Console.WriteLine(x.a.ToString());
}
public void DoSomething(ref MyStruct pValue)
{
pValue.a = 12345;
}
Passing Reference Types.
Passing parameters that are reference types is similar to passing value types by reference as in the previous example.
If we are using the value type
public class MyInt
{
public int MyValue;
}
And call the Go() method, the MyInt ends up on the heap because it is a reference type:
public void Go()
{
MyInt x = new MyInt();
}
If we execute Go() as in the following code ...
public void Go()
{
MyInt x = new MyInt();
x.MyValue = 2;
DoSomething(x);
Console.WriteLine(x.MyValue.ToString());
}
public void DoSomething(MyInt pValue)
{
pValue.MyValue = 12345;
}
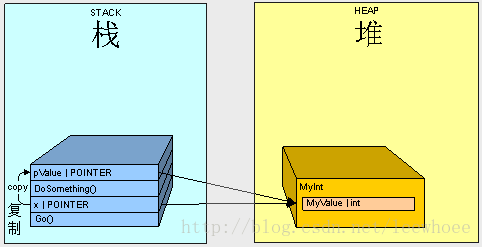
Here's what happens...
- Starting with the call to Go() the variable x goes on the stack.
- Starting with the call to DoSomething() the parameter pValue goes on the stack.
- The value of x (the address of MyInt on the stack) is copied to pValue
So it makes sense that when we change the MyValue property of the MyInt object in the heap using pValue and we later refer to the object on the heap using x, we get the value "12345".
So here's where it gets interesting. What happens when we pass a reference type by reference?
Check it out. If we have a Thing class and Animal and Vegetables are both things:
public class Thing
{
}
public class Animal:Thing
{
public int Weight;
}
public class Vegetable:Thing
{
public int Length;
}
And we execute the Go() method below:
public void Go()
{
Thing x = new Animal();
Switcharoo(ref x);
Console.WriteLine(
"x is Animal : "
+ (x is Animal).ToString());
Console.WriteLine(
"x is Vegetable : "
+ (x is Vegetable).ToString());
}
public void Switcharoo(ref Thing pValue)
{
pValue = new Vegetable();
}
Our variable x is turned into a Vegetable.
x is Animal : False
x is Vegetable : True
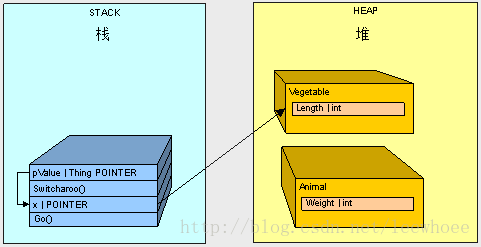
Let's take a look at what's happening:
- Starting with the Go() method call, the x pointer goes on the stack
- The Animal goes on the hea
- Starting with the call to Switcharoo() method, the pValue goes on the stack and points to x
- The Vegetable goes on the heapthe heap
- The value of x is changed through pValue to the address of the Vegetable
If we don't pass the Thing by ref, we'll keep the Animal and get the opposite results from our code.
If the above code doesn't make sense, check out my article on types of Reference variables to get a better understanding of how variables work with reference types.
In Conclusion.
We've looked at how parameter passing is handled in memory and now know what to look out for. In the next part of this series, we'll take a look at what happens to reference variables that live in the stack and how to overcome some of the issues we'll have when copying objects.
For now.
[No0000145]深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing)理解堆与栈2/4的更多相关文章
- [No0000144]深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing)理解堆与栈1/4
前言 虽然在.Net Framework 中我们不必考虑内在管理和垃圾回收(GC),但是为了优化应用程序性能我们始终需要了解内存管理和垃圾回收(GC).另外,了解内存管理可以帮助我们理解在每一个程 ...
- [No0000147]深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing)理解堆与栈4/4
前言 虽然在.Net Framework 中我们不必考虑内在管理和垃圾回收(GC),但是为了优化应用程序性能我们始终需要了解内存管理和垃圾回收(GC).另外,了解内存管理可以帮助我们理解在每一个程 ...
- [No0000146]深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing)理解堆与栈3/4
前言 虽然在.Net Framework 中我们不必考虑内在管理和垃圾回收(GC),但是为了优化应用程序性能我们始终需要了解内存管理和垃圾回收(GC).另外,了解内存管理可以帮助我们理解在每一个程 ...
- Java 堆内存与栈内存异同(Java Heap Memory vs Stack Memory Difference)
--reference Java Heap Memory vs Stack Memory Difference 在数据结构中,堆和栈可以说是两种最基础的数据结构,而Java中的栈内存空间和堆内存空间有 ...
- java - Stack栈和Heap堆的区别
首先分清楚Stack,Heap的中文翻译:Stack—栈,Heap—堆. 在中文里,Stack可以翻译为“堆栈”,所以我直接查找了计算机术语里面堆和栈开头的词语: 堆存储 ...
- 内存,堆,栈,heap,stack,data
1. 基本类型占一块内存. 引用类型占两块. 2. 类是静态概念. 函数中定义的基本类型变量和对象的引用类型变量都在函数的栈内存. 局部变量存在栈内存. new创建的对象和数组,存在堆内存. java ...
- iOS:堆(heap)和栈(stack)的理解
Objective-C的对象在内存中是以堆的方式分配空间的,并且堆内存是由你释放的,即release 栈由编译器管理自动释放的,在方法中(函数体)定义的变量通常是在栈内,因此如果你的变量要跨函数的话就 ...
- iOS中的堆(heap)和栈(stack)的理解
操作系统iOS 中应用程序使用的计算机内存不是统一分配空间,运行代码使用的空间在三个不同的内存区域,分成三个段:“text segment “,“stack segment ”,“heap segme ...
- stm32 堆和栈(stm32 Heap & Stack)【worldsing笔记】
关于堆和栈已经是程序员的一个月经话题,大部分有是基于os层来聊的. 那么,在赤裸裸的单片机下的堆和栈是什么样的分布呢?以下是网摘: 刚接手STM32时,你只编写一个 int main() ...
随机推荐
- 《STL源码剖析》学习之traits编程
侯捷老师在<STL源码剖析>中说到:了解traits编程技术,就像获得“芝麻开门”的口诀一样,从此得以一窥STL源码的奥秘.如此一说,其重要性就不言而喻了. 之前已经介绍过迭代器 ...
- Nginx 设置域名转向配置
#运行用户 #user www-data; #启动进程,通常设置成和cpu的数量相等 worker_processes 2; #全局错误日志及PID文件 error_log logs/error.lo ...
- 开源配置管理平台-Apollo
Apollo(阿波罗)是携程框架部门研发的配置管理平台,能够集中化管理应用不同环境.不同集群的配置,配置修改后能够实时推送到应用端. Apollo官网地址
- java多线程状态
造成线程进入阻塞状态的情况大致可分为: 1.调用sleep()方法 2.调用阻塞式IO方法 3. 4.等待通知 5.调用suspend(),程序挂起.
- 源码分析HotSpot GC过程(一)
«上一篇:源码分析HotSpot GC过程(一)»下一篇:源码分析HotSpot GC过程(三):TenuredGeneration的GC过程 https://blogs.msdn.microsoft ...
- python学习之struct模块
class struct.Struct(format) 返回一个struct对象(结构体,参考C). 该对象可以根据格式化字符串的格式来读写二进制数据. 第一个参数(格式化字符串)可以指定字节的顺序. ...
- 4. OpenAI GPT算法原理解析
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
- Java多线程系列——线程池简介
什么是线程池? 为了避免系统频繁地创建和销毁线程,我们可以让创建的线程进行复用.用线程时从线程池中获取,用完以后不销毁线程,而是归还给线程池. JDK 对线程池的支持 为了更好的控制多线程,JDK 提 ...
- 教你一招:修复win7 系统自带的截图工具损坏
这个问题经常见,原因是注册表没有导入. 修复很简单. 打开资源管理器,在C盘中搜索到 tpcps.dll ,在其中选一个右击,选择注册dll,然后截图工具就被修复了. 有时候便签也会出现类似问题,方法 ...
- mysql解决大量time_wait
mysql解决大量time_wait 命令查看TIME_WAIT连接数 netstat -ae|grep "TIME_WAIT" |wc -l 早上登陆服务器的时候输入ne ...