PReLU
PReLU全名Parametric Rectified Linear Unit. PReLU-nets在ImageNet 2012分类数据集top-5上取得了4.94%的错误率,首次超越了人工分类的错误率(5.1%)。PReLU增加的计算量和过拟合的风险几乎为零。考虑了非线性因素的健壮初始化方法使得该方法可以训练很深很深的修正模型(rectified model)来研究更深更大的网络结构。
ReLU和PReLU图像:

PReLU的数学表达式(i代表不同的通道,即每一个通道都有参数不相同的PReLU函数):
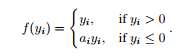
如果ai是一个很小且确定的值时,PReLU就变成了LReLU。LReLU的目的是为了避免梯度为零提出来的。实验表明,LReLU在精确度上与ReLU相差无几。然而,PReLU是通过在训练中自学习参数ai的。PReLU只引进了n(n为通道数量)个参数,这和整个模型的权重数量比起来是微不足道的。因此我们预料这不会增加过拟合的风险。作者也考虑了通道共享的参数,即所有通道的ai都相等,这样就只引进了一个参数。
PReLU可以通过反向传播算法来更新参数。ai 的梯度为:
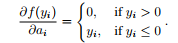
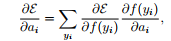
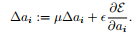
其中μ是动量,e代表学习速率,ε代表目标函数,ai初始值为0.25。值得注意的是,不使用权重衰减(L2正则化)来更新ai,因为这会使得ai趋向于0,变为ReLU。即使没有正则化,ai在实验中也没有超过1。作者没有限制ai的范围,因此激活函数可能是非单调的。
当参数为通道共享时,a 的梯度为:
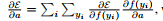 ,其中∑i 表示该层所有通道相加。
,其中∑i 表示该层所有通道相加。
参考论文:【1】Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
PReLU的更多相关文章
- PReLU与ReLU
PReLU激活函数,方法来自于何凯明paper <Delving Deep into Rectifiers:Surpassing Human-Level Performance on Image ...
- tensorflow prelu的实现细节
tensorflow prelu的实现细节 output = tf.nn.leaky_relu(input, alpha=tf_gamma_data,name=name) #tf.nn.leaky_r ...
- 激活函数ReLU、Leaky ReLU、PReLU和RReLU
“激活函数”能分成两类——“饱和激活函数”和“非饱和激活函数”. sigmoid和tanh是“饱和激活函数”,而ReLU及其变体则是“非饱和激活函数”.使用“非饱和激活函数”的优势在于两点: 1 ...
- 激活函数(relu,prelu,elu,+BN)对比on cifar10
激活函数(relu,prelu,elu,+BN)对比on cifar10 可参考上一篇: 激活函数 ReLU.LReLU.PReLU.CReLU.ELU.SELU 的定义和区别 一.理论基础 ...
- Difference between ReLU、LReLU、PReLU、CReLU、ELU、SELU
激活函数 ReLU.LReLU.PReLU.CReLU.ELU.SELU 的定义和区别 ReLU tensorflow中:tf.nn.relu(features, name=None) LReLU ...
- [转]激活函数ReLU、Leaky ReLU、PReLU和RReLU
“激活函数”能分成两类——“饱和激活函数”和“非饱和激活函数”. sigmoid和tanh是“饱和激活函数”,而ReLU及其变体则是“非饱和激活函数”.使用“非饱和激活函数”的优势在于两点: 1 ...
- PReLU——Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
1. 摘要 在 \(ReLU\) 的基础上作者提出了 \(PReLU\),在几乎没有增加额外参数的前提下既可以提升模型的拟合能力,又能减小过拟合风险. 针对 \(ReLU/PReLU\) 的矫正非线性 ...
- python实现并绘制 sigmoid函数,tanh函数,ReLU函数,PReLU函数
Python绘制正余弦函数图像 # -*- coding:utf-8 -*- from matplotlib import pyplot as plt import numpy as np impor ...
- 使用prelu
一个使用方式:http://blog.csdn.net/xg123321123/article/details/52610919 还有一种是像relu那样写,我就是采用的这种方式,直接把名字从relu ...
随机推荐
- vs编译出现 fatal error LNK1281:无法生成 SAFESEH 映像
问题: 在vs编译中我们有时候常常会见到这样的错误,无法生成 SAFESEH 映像,镜像安全问题 解决方法: 1.打开该项目的"属性页"对话框. 2.单击"链接器&quo ...
- JUnit 4 Vs TestNG比较
JUnit 4和TestNG都是Java中非常受欢迎的单元测试框架.两种框架在功能上看起来非常相似. 哪一个更好? 在Java项目中应该使用哪个单元测试框架? 下面表中概括了JUnit 4和TestN ...
- 手动添加jar包到maven仓库
引言: 虽然配置了maven以后可以通过索引的方式自动下载jar包到本地maven仓库,从而使项目中直接使用本地仓库里面的架包, 但是这一招并不是每一次都灵应,也有遇到了失败的时候,当遇到失败的时候, ...
- ORACLE SYNONYM详解
以下内容整理自Oracle 官方文档 一 概念 A synonym is an alias for any table, view,materialized view, sequence, proce ...
- mysql-5.6.41-winx64安装
安装包 链接:https://pan.baidu.com/s/11-Ts3SrfJViQEtdtI_ik9w 提取码:cxt3 1.解压 将下载好的mysql-5.6.41-winx64.zip的安装 ...
- .NET Core 管道
从用户发请求到服务器响应返回数据 请求从 Request进去 先经过 Middleware(中间件) 然后经过AuthoriationFilters授权验证(token验证和 多租户验证) 在经 ...
- Linux性能测试工具-UnixBench
■下载路径: unixbench-5.1.2.tar.gz :http://soft.vpser.net/test/unixbench/ unixbench-5.1.3.tar.gz :http:// ...
- Java代理机制之初见(理解及实现)
都知道Java中的Spring,有一重要思想:AOP,实现原理也就是Java的动态代理机制.初见代理这个名词时,觉得生活中常有代理的这一说法. 那么,在Java中,代理又是什么呢?它又是如何实现的?实 ...
- 获取解码字符串指定位置的数值 Decoded String at Index
2018-10-04 12:53:06 问题描述: 问题求解: 首先本题给出了问题的规模,从Note中我们可以看到解码后的字符串长度甚至可以达到2^63的长度,这个长度已经远远超过整型数的范围,因此如 ...
- 差异基因分析:fold change(差异倍数), P-value(差异的显著性)
在做基因表达分析时必然会要做差异分析(DE) DE的方法主要有两种: Fold change t-test fold change的意思是样本质检表达量的差异倍数,log2 fold change的意 ...