LINUX内核分析第六周学习总结——进程的描述与创建
LINUX内核分析第六周学习总结——进程的描述与创建
标签(空格分隔): 20135321余佳源
余佳源 原创作品转载请注明出处 《Linux内核分析》MOOC课程 http://mooc.study.163.com/course/USTC-1000029000
一、进程的描述
1.操作系统三大功能
进程管理
内存管理
文件系统
最核心的是进程管理
2、进程的作用
将信号、进程间通信、内存管理和文件系统联系起来
3.进程控制块PCB——task_struct
来自课件↓
为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息。
struct task_struct数据结构很庞大
Linux进程的状态与操作系统原理中的描述的进程状态似乎有所不同,比如就绪状态和运行状态都是TASK_RUNNING,为什么呢?
进程的标示pid
所有进程链表struct list_head tasks;
内核的双向循环链表的实现方法 - 一个更简略的双向循环链表
程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
进程处于内核态时使用,不同于用户态堆栈,即PCB中指定了内核栈,那为什么PCB中没有用户态堆栈?用户态堆栈是怎么设定的?
内核控制路径所用的堆栈很少,因此对栈和Thread_info来说,8KB足够了
struct thread_struct thread; //CPU-specific state of this task
文件系统和文件描述符
内存管理——进程的地址空间
分析:
pid_t pid又叫进程标识符,唯一地标识进程
list_head tasks即进程链表
——双向循环链表链接起了所有的进程,也表示了父子、兄弟等进程关系
struct mm_struct 指的是进程地址空间,涉及到内存管理(对于X86而言,一共有4G的地址空间)
thread_struct thread 与CPU相关的状态结构体
struct *file表示打开的文件链表
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
4.进程状态转换图
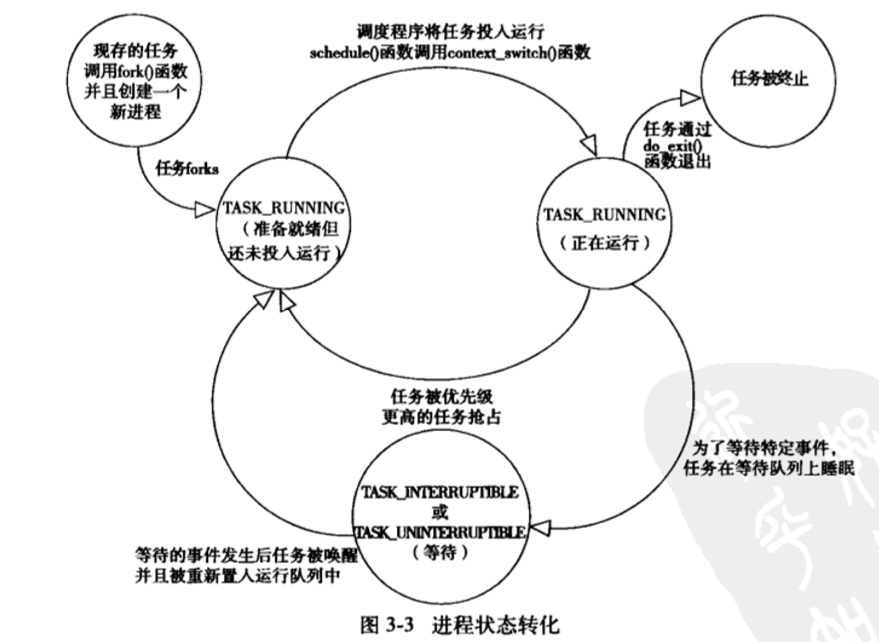
Linux进程的状态与操作系统原理中的描述的进程状态有所不同,比如就绪状态和运行状态都是TASK_RUNNING
一般操作系统原理中描述的进程状态有就绪态,运行态,阻塞态,但是在实际内核进程管理中是不一样的。
struct task_struct数据结构很庞大
struct task_struct {
volatile long state; /* 进程状态 -1 unrunnable, 0 runnable, >0 stopped */
void *stack; /* 进程的内核堆栈 */
atomic_t usage;
unsigned int flags; /* 每个进程的标识符 */
unsigned int ptrace;
/ #ifdef CONFIG_SMP // 条件编译,SMP多处理器相关
……
int on_rq // 运行队列相关,下面几行是进程队列和调度相关。
……
struct list_head tasks // 进程链表
……
next_task
prev_task // 对进程链表的管理
tty_struct // 控制台
fs_struct // 文件系统
struct files_struct *files; // 打开的文件描述符列表
file_struct // 打开的文件描述符
mm_struct // 内存管理描述
struct mm_struct *mm, *active_mm; // 地址空间,内存管理。
signal_struct // 进程间通信、信号描述
struct list_head ptraced // 调试用
utime
stime // 进程时间相关
- TASK_RUNNING具体是就绪还是执行,要看系统当前的资源分配情况;
- TASK_ZOMBIE也叫僵尸进程

二、进程的创建
1.进程的创建概览及fork一个进程的用户态代码
道生一(start_kernel....cpu_idle),一生二(kernel_init和kthreadd),二生三(即前面0、1和2三个进程),三生万物(1号进程是所有用户态进程的祖先,0号进程是所有内核线程的祖先),新内核的核心代码已经优化的相当干净,都符合中国传统文化精神了
0号进程,是代码写死的,1号进程复制0号进程PCB,再修改,再加载可执行程序。
系统调用进程创建过程:
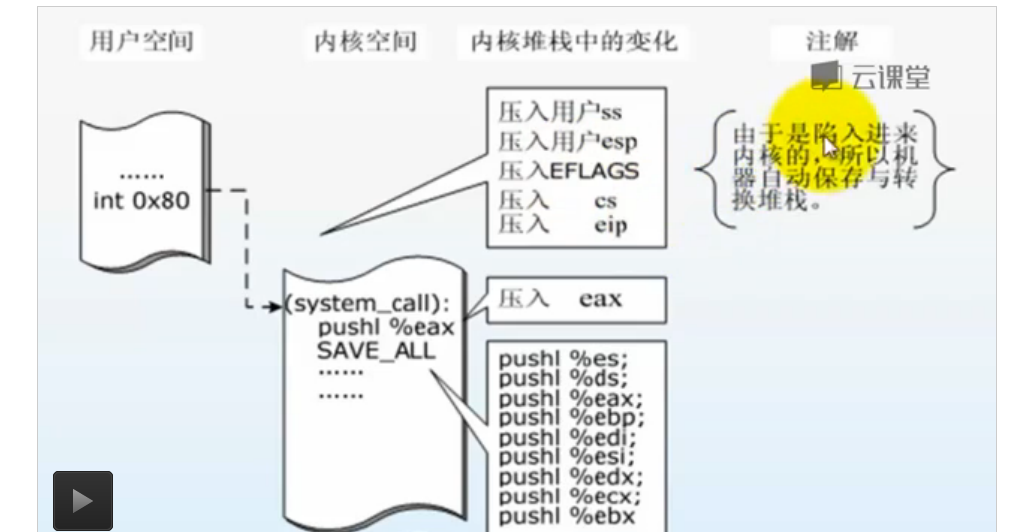
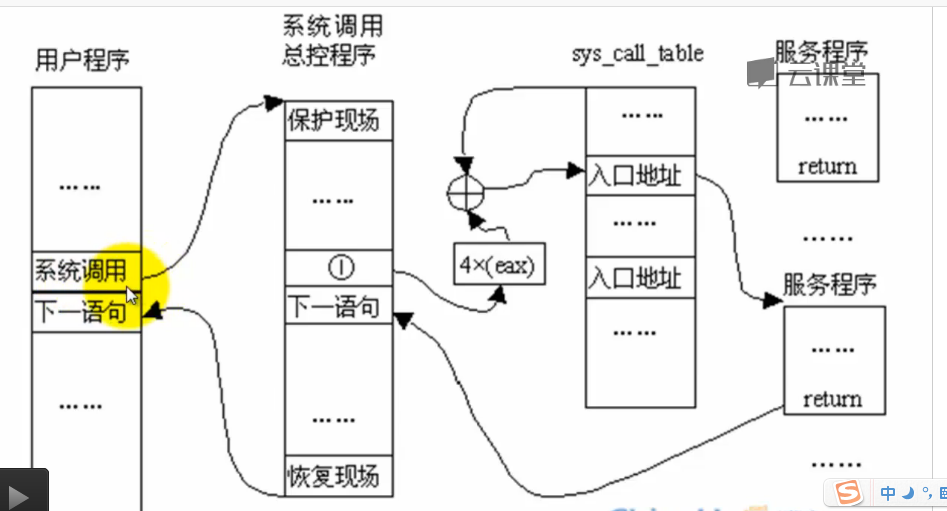
iret与int 0x80指令对应,一个是弹出寄存器值,一个是压入寄存器的值
如果将系统调用类比于fork();那么就相当于系统调用创建了一个子进程,然后子进程返回之后将在内核态运行,而返回到父进程后仍然在用户态运行。
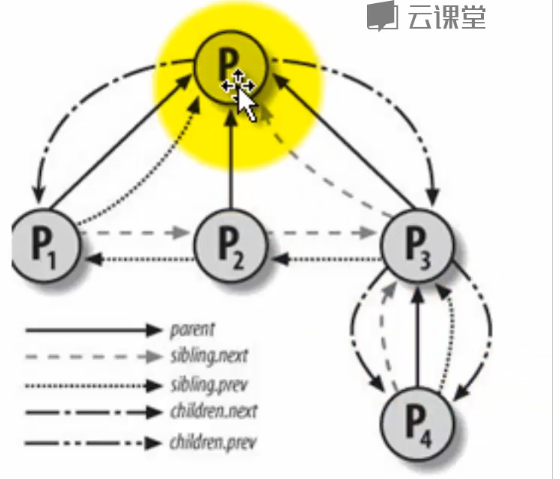
进程的父子关系直观图:
2.分析内核处理过程
do_fork
- 调用copy_process,将当前进程复制一份出来给子进程,并且为子进程设置相应地上下文信息。
- 调用wake_up_new_task,将子进程放入调度器的队列中,此时的子进程就可以被调度进程选中运行。
fork代码:fork、vfork和clone这三个函数最终都是通过do_fork函数实现的
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char * argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < 0)
{
/* error occurred */
fprintf(stderr,"Fork Failed!");
exit(-1);
}
else if (pid == 0) //pid == 0和下面的else都会被执行到(一个是在父进程中即pid ==0的情况,一个是在子进程中,即pid不等于0)
{
/* child process */pid=0时 if和else都会执行 fork系统调用在父进程和子进程各返回一次
printf("This is Child Process!\n");
}
else
{
/* parent process */
printf("This is Parent Process!\n");
/* parent will wait for the child to complete*/
wait(NULL);
printf("Child Complete!\n");
}
}
创建新进程的框架do_fork:dup_thread复制父进程的PCB
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
}
copy_process:进程创建的关键,修改复制的PCB以适应子进程的特点,也就是子进程的初始化
- 创建进程描述符以及子进程所需要的其他所有数据结构,为子进程准备运行环境
- 调用dup_task_struct复制一份task_struct结构体,作为子进程的进程描述符。
- 复制所有的进程信息
- 调用copy_thread,设置子进程的堆栈信息,为子进程分配一个pid。
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
// 分配一个新的task_struct
p = dup_task_struct(current);
// 检查该用户的进程数是否超过限制
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
// 检查该用户是否具有相关权限
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}
retval = -EAGAIN;
// 检查进程数量是否超过 max_threads
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
// 初始化自旋锁,挂起信号,定时器
retval = sched_fork(clone_flags, p);
// 初始化子进程的内核栈
retval = copy_thread(clone_flags, stack_start, stack_size, p);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
// 这里为子进程分配了新的pid号
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
if (!pid)
goto bad_fork_cleanup_io;
}
/* ok, now we should be set up.. */
// 设置子进程的pid
p->pid = pid_nr(pid);
// 如果是创建线程
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
// 线程组的leader设置为当前线程的leader
p->group_leader = current->group_leader;
// tgid是当前线程组的id,也就是main进程的pid
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
// 创建的是进程,自己是一个单独的线程组
p->group_leader = p;
// tgid和pid相同
p->tgid = p->pid;
}
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
//同一线程组内的所有线程、进程共享父进程
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
// 如果是创建进程,当前进程就是子进程的父进程
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
dup_ task_ struct
- 先调用alloc_task_struct_node分配一个task_struct结构体。
- 调用alloc_thread_info_node,分配了一个union。这里分配了一个thread_info结构体,还分配了一个stack数组。返回值为ti,实际上就是栈底。
- tsk->stack = ti将栈底的地址赋给task的stack变量。
- 最后为子进程分配了内核栈空间。
- 执行完dup_task_struct之后,子进程和父进程的task结构体,除了stack指针之外,完全相同。
copy_thread:
- 获取子进程寄存器信息的存放位置
- 对子进程的thread.sp赋值,将来子进程运行,这就是子进程的esp寄存器的值。
- 如果是创建内核线程,那么它的运行位置是ret_from_kernel_thread,将这段代码的地址赋给thread.ip,之后准备其他寄存器信息,退出
- 将父进程的寄存器信息复制给子进程。
- 将子进程的eax寄存器值设置为0,所以fork调用在子进程中的返回值为0.
- 子进程从ret_from_fork开始执行,所以它的地址赋给thread.ip,也就是将来的eip寄存器。
int copy_thread(unsigned long clone_flags, unsigned long sp,
unsigned long arg, struct task_struct *p)
{
struct pt_regs *childregs = task_pt_regs(p);
struct task_struct *tsk;
int err;
// 如果是创建的内核线程
if (unlikely(p->flags & PF_KTHREAD)) {
/* kernel thread */
memset(childregs, 0, sizeof(struct pt_regs));
// 内核线程开始执行的位置
p->thread.ip = (unsigned long) ret_from_kernel_thread;
task_user_gs(p) = __KERNEL_STACK_CANARY;
childregs->ds = __USER_DS;
childregs->es = __USER_DS;
childregs->fs = __KERNEL_PERCPU;
childregs->bx = sp; /* function */
childregs->bp = arg;
childregs->orig_ax = -1;
childregs->cs = __KERNEL_CS | get_kernel_rpl();
childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
p->thread.io_bitmap_ptr = NULL;
return 0;
}
// 复制内核堆栈,并不是全部,只是regs结构体(内核堆栈栈底的程序)
*childregs = *current_pt_regs();
childregs->ax = 0;
if (sp)
childregs->sp = sp;
// 子进程从ret_from_fork开始执行
p->thread.ip = (unsigned long) ret_from_fork;//调度到子进程时的第一条指令地址,也就是说返回的就是子进程的空间了
task_user_gs(p) = get_user_gs(current_pt_regs());
return err;
}
#ifdef CONFIG_SMP //条件编译,多处理器会用到
struct llist_node wake_entry;
int on_cpu;
struct task_struct *last_wakee;
unsigned long wakee_flips;
unsigned long wakee_flip_decay_ts;
int wake_cpu;
#endif
int on_rq;
int prio, static_prio, normal_prio;
unsigned int rt_priority; //与优先级相关
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
……
struct list_head tasks; //进程链表
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
struct rb_node pushable_dl_tasks;
#endif
3.创建一个新进程在内核中的执行过程
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建;
Linux通过复制父进程来创建一个新进程,那么这就给我们理解这一个过程提供一个想象的框架:
- 复制一个PCB——task_struct
$ err = arch_dup_task_struct(tsk, orig); //在这个函数复制父进程的数据结构 - 要给新进程分配一个新的内核堆栈
$ ti = alloc_thread_info_node(tsk, node);
- 复制一个PCB——task_struct
$ tsk->stack = ti; //复制内核堆栈
$ setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈
```
- 要修改复制过来的进程数据,比如pid、进程链表等等都要改
- 从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回。那它在系统调用处理过程中的哪里开始执行的呢?这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process
```
$ *childregs = *current_pt_regs(); //复制内核堆栈
$ childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因
$ p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
$ p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
```
三、实践部分
1.准备工作:
rm menu -rf
git clone http://github.com/mengning/menu.git # 更新Menu
cd menu
mv test_fork.c test.c # 把test.c覆盖掉
make rootfs
2.运行内核,可以看到fork命令

3.启动gdb调试,并对主要的函数设置断点
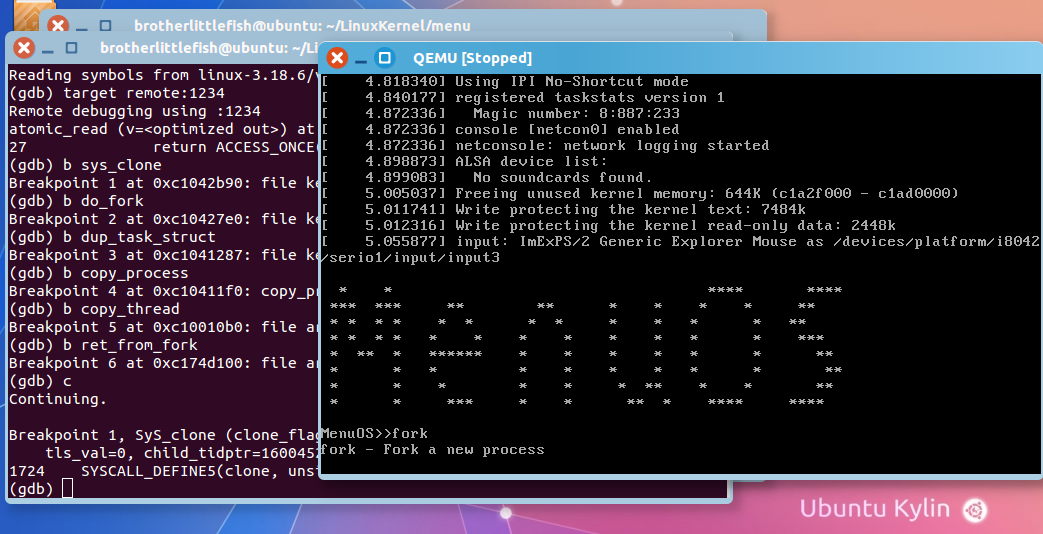
可以看到只输出了fork功能的描述,在断点处sys_clone处停止了。
继续调试,停在do_ fork 和copy_ process

程序停在dup_task_struct函数处

4.在copy_thread函数中单步执行,可看到,内核空间压栈地址被初始化

struct pt_regs *childregs =task_pt_regs(p) ——>内核空间压栈地址被初始化
5.调度到子进程时的内核栈顶

p->thread.sp=(unsigned long)childregs时调度到子进程的内核栈顶
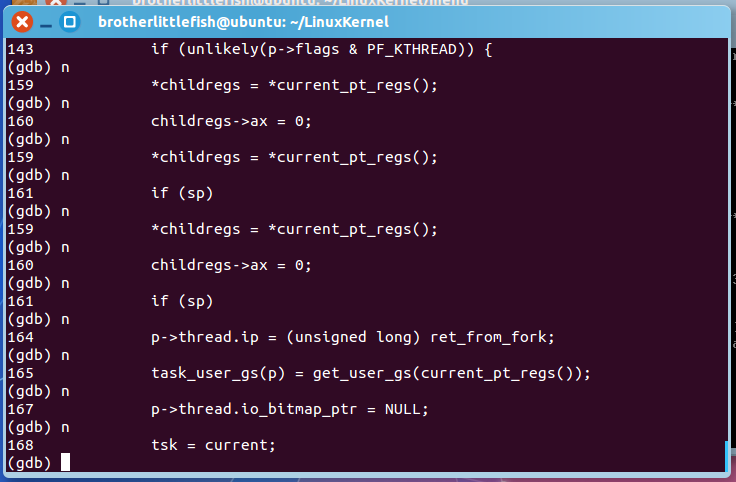
childregs=current_pt_regs()->复制内核堆栈,当前内核堆栈寄存器中的值复制到子进程中
childregs->ax=0 ->子进程fork返回0原因
p->thread.ip=(unsigned long )ret_from_fork ->设置子进程调度起点,调度到子进程时的第一条指令地址
6.打印进程信息的ret_from_fork

程序停止在了ret_ from_ fork处,当前系统执行的是汇编代码,同时打印出进程信息。
四、小结
Linux通过复制父进程来创建一个新进程,通过调用do_ fork来实现并为每个新创建的进程动态地分配一个task_ struct结构。不论是使用 fork 还是 vfork 来创建进程,最终都是通过 do_fork() 方法来实现的。PS:当子进程获得CPU控制权的时候,它的ret_ from_ fork可以把后面堆栈从iret返回到用户态,这里的用户态是子进程的用户态
fork创建的新的子进程是从ret_from_fork开始执行的,然后跳转到syscall_exit,从系统调用中返回。
Linux中的线程,又是一种特殊的进程。
为了把内核中的所有进程组织起来,Linux提供了几种组织方式,其中哈希表和双向循环链表方式是针对系统中的所有进程(包括内核线程),而运行队列和等待队列是把处于同一状态的进程组织起来
fork()函数被调用一次,但返回两次
新进程如何开始的关键:
copy_thread()中:
p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
将子进程的ip设置为ret_ form _ fork的首地址,因此子进程是从ret_ from_ fork开始执行的。
在设置子进程的ip之前:
p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
*childregs = *current_ pt_ regs();
将父进程的regs参数赋值到子进程的内核堆栈,*childregs的类型为pt_regs,其中存放了SAVE ALL中压入栈的参数。
LINUX内核分析第六周学习总结——进程的描述与创建的更多相关文章
- LINUX内核分析第六周学习总结——进程的描述和进程的创建
LINUX内核分析第六周学习总结——进程的描述和进程的创建 张忻(原创作品转载请注明出处) <Linux内核分析>MOOC课程http://mooc.study.163.com/cours ...
- linux内核分析第六周学习笔记
LINUX内核分析第六周学习总结 标签(空格分隔): 20135328陈都 陈都 原创作品转载请注明出处 <Linux内核分析>MOOC课程 http://mooc.study.163.c ...
- Linux内核分析第六周学习笔记——分析Linux内核创建一个新进程的过程
Linux内核分析第六周学习笔记--分析Linux内核创建一个新进程的过程 zl + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/U ...
- LINUX内核分析第八周学习总结——进程的切换和系统的一般执行过程
LINUX内核分析第八周学习总结——进程的切换和系统的一般执行过程 张忻(原创作品转载请注明出处) <Linux内核分析>MOOC课程http://mooc.study.163.com/c ...
- Linux内核分析第六周学习总结:进程的描述和进程的创建
韩玉琪 + 原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 一.进程的描述 ...
- Linux内核分析——第六周学习笔记20135308
第六周 进程的描述和进程的创建 一.进程描述符task_struct数据结构 1.操作系统三大功能 进程管理 内存管理 文件系统 2.进程控制块PCB——task_struct 也叫进程描述符,为了管 ...
- Linux内核分析——第六周学习笔记
进程的描述和进程的创建 前言:以下笔记除了一些讲解视频中的概念记录,图示.图示中的补充文字.总结.分析.小结部分均是个人理解.如有错误观点,请多指教! PS.实验操作会在提交到MOOC网站的博客中写.
- LINUX内核分析第七周学习总结——可执行程序的装载
LINUX内核分析第六周学习总结——进程的描述和进程的创建 张忻(原创作品转载请注明出处) <Linux内核分析>MOOC课程http://mooc.study.163.com/cours ...
- LINUX内核分析第七周学习总结:可执行程序的装载
LINUX内核分析第七周学习总结:可执行程序的装载 韩玉琪 + 原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/cours ...
随机推荐
- PHP APP端微信支付
前面已经写了手机APP支付宝支付,今天再把手机APP微信支付补上,前期的准备工作在这里就不多说了,可以参考微信支付开发文档,一定要仔细阅读开发文档,可以让你少踩点坑:准备工作完成后就是配置参数,调用统 ...
- Keil常见错误汇总及处理方式
1. warning: #767-D: conversion from pointer to smaller integer 解释:将指针转换为较小的整数 影响:可能造成的影响:容易引起数据截断,造成 ...
- oracle数据库用户基本操作
每个数据库都有一系列的用户,为了访问数据库,用户必须使用用户名等信息先连接上数据库实例,oracle数据库提供了多种方式来管理用户安全.创建用户的时候,可以通过授权等操作来限制用户能访问的资源以及一些 ...
- var a = {m:1}; var b = a; a.n = b ={n:1}; console.log(a);console.log(b);
var a = {m:1}; var b = a; a.n = b ={n:1}; console.log(a); console.log(b); 确定b为{n:1},所以a为 {m:1,n:{n:1 ...
- WEB应用打成jar包全记录
内容属原创,转载请注明出处 题外 由于项目的需求—不管是怎么产生的这个需求—总之,需要支持把一个web应用打成jar包供其他应用使用,这就有了下面的过程. 这个过程里用到了Spring和SpringM ...
- Android back键及backWebview模式跳转详解
首先,来看一下关于Android home键和back键区别 back键 Android的程序无需刻意的去退出,当你一按下手机的back键的时候,系统会默认调用程序栈中最上层Activity的Dest ...
- ERROR 1045 (28000): Access denied for user 'ODBC'@'localhost' (using password: NO) ERROR 1045 (28000): Access denied for user 'ODBC'@'localhost' (using password: YES)
windows下,以上两个错误的解决方法 工具/原料 windows 8 MySql 方法/步骤 找到配置文件my.ini ,然后将其打开,可以选择用记事本打开 打开后,搜索mysq ...
- 在H5页面内通过地址调起高德地图实现导航
项目中用到的一个功能是要通过点击地址来实现打开地图app实现地址导航. 如下图: 实现思路就是在H5页面内通过点击marker图标然后进行当前位置与页面上地址的路程规划与导航. 由于项目中用到的是高德 ...
- ECharts.js学习动态数据绑定
https://my.oschina.net/brillantzhao/blog/1541702https://www.cnblogs.com/leoxuan/p/6513591.htmlhttps: ...
- java开发过程问题及解决
1.junit做测试时候报异常: junit.framework.AssertionFailedError: No tests found in com.mq.original.OriginalMqP ...