Flask的Context(上下文)学习笔记
上下文是一种属性的有序序列,为驻留在环境内的对象定义环境。在对象的激活过程中创建上下文,对象被配置为要求某些自动服务,如同步、事务、实时激活、安全性等等。
比如在计算机中,相对于进程而言,上下文就是进程执行时的环境。具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存信息等。可以理解上下文是环境的一个快照,是一个用来保存状态的对象。在程序中我们所写的函数大都不是单独完整的,在使用一个函数完成自身功能的时候,很可能需要同其他的部分进行交互,需要其他外部环境变量的支持,上下文就是给外部环境的变量赋值,使函数能正确运行。
Flask提供了两种上下文,一种是应用上下文(Application Context),一种是请求上下文(Request Context)。
请求上下文:保存了客户端和服务器交互的数据
应用上下文:flask 应用程序运行过程中,保存的一些配置信息,比如程序名、数据库连接、应用信息等
通俗地解释一下application context与request context:
- application 指的就是当你调用app = Flask(name)创建的这个对象app;
- request 指的是每次http请求发生时,WSGI server(比如gunicorn)调Flask.call()之后,在Flask对象内部创建的Request对象;
- application 表示用于响应WSGI请求的应用本身,request 表示每次http请求;
- application的生命周期大于request,一个application存活期间,可能发生多次http请求,所以,也就会有多个request
Flask处理流程
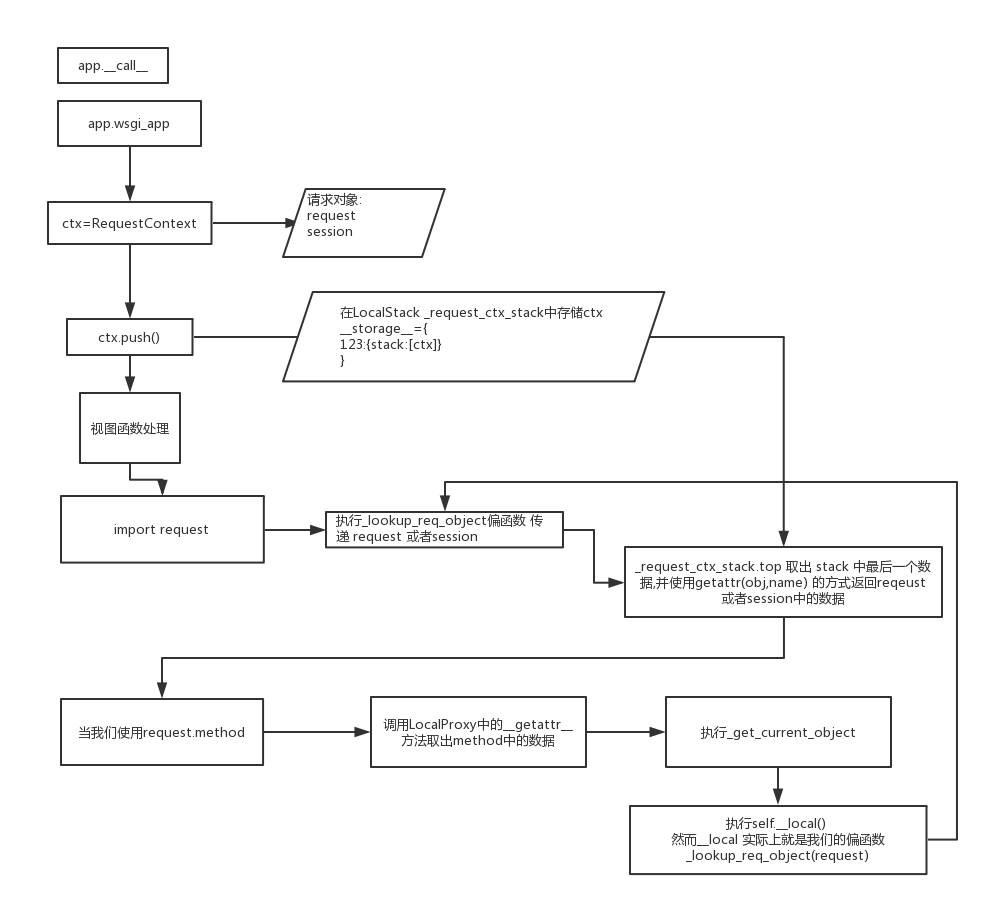
请求上下文
from flask import request
@app.route('/')
def index():
user_agent = request.headers.get('User-Agent')
return '<p>Your browser is %s</p>' % user_agent```
Flask中有四种请求hook,分别是@before_first_request @before_request @after_request @teardown_request
如同上面的代码一样,在每个请求上下文的函数中我们都可以访问request对象,然而request对象却并不是全局的,因为当我们随便声明一个函数的时候,比如:
def handle_request():
print 'handle request'
print request.url
if __name__=='__main__':
handle_request()
此时运行就会产生
RuntimeError: working outside of request context。
因此可知,Flask的request对象只有在其上下文的生命周期内才有效,离开了请求的生命周期,其上下文环境不存在了,也就无法获取request对象了。而上面所说的四种请求hook函数,会挂载在生命周期的不同阶段,因此在其内部都可以访问request对象。
可以使用Flask的内部方法request_context()来构建一个请求上下文
from werkzeug.test import EnvironBuilder
ctx = app.request_context(EnvironBuilder('/','http://localhost/').get_environ())
ctx.push()
try:
print request.url
finally:
ctx.pop()
对于Flask Web应用来说,每个请求就是一个独立的线程。请求之间的信息要完全隔离,避免冲突,这就需要使用到Thread Local。
Thread Local
对象是保存状态的地方,在Python中,一个对象的状态都被保存在对象携带的一个字典中,**Thread Local **则是一种特殊的对象,它的“状态”对线程隔离 —— 也就是说每个线程对一个 Thread Local 对象的修改都不会影响其他线程。这种对象的实现原理也非常简单,只要以线程的 ID 来保存多份状态字典即可,就像按照门牌号隔开的一格一格的信箱。
在Python中获取Thread Local最简单的方式是threading.local()
>>> import threading
>>> storage = threading.local()
>>> storage.foo = 1
>>> print(storage.foo)
1
>>> class AnotherThread(threading.Thread):
... def run(self):
... storage.foo = 2
... print(storage.foo) # 这这个线程里已经修改了
>>>
>>> another = AnotherThread()
>>> another.start()
2
>>> print(storage.foo) # 但是在主线程里并没有修改
1
因此只要有Thread Local对象,就能让同一个对象在多个线程下做到状态隔离。
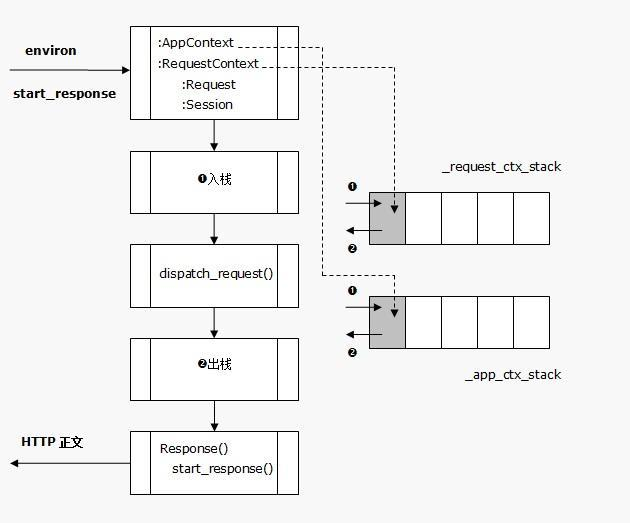
Flask是一个基于WerkZeug实现的框架,因此Flask的App Context和Request Context是基于WerkZeug的Local Stack的实现。这两种上下文对象类定义在flask.ctx中,ctx.push会将当前的上下文对象压栈压入flask._request_ctx_stack中,这个_request_ctx_stack同样也是个Thread Local对象,也就是在每个线程中都不一样,上下文压入栈后,再次请求的时候都是通过_request_ctx_stack.top在栈的顶端取,所取到的永远是属于自己线程的对象,这样不同线程之间的上下文就做到了隔离。请求结束后,线程退出,ThreadLocal本地变量也随即销毁,然后调用ctx.pop()弹出上下文对象并回收内存。
应用上下文
从一个 Flask App 读入配置并启动开始,就进入了 App Context,在其中我们可以访问配置文件、打开资源文件、通过路由规则反向构造 URL。可以看下面一段代码:
from flask import Flask, current_app
app = Flask('__name__') @app.route('/')
def index():
return 'Hello, %s!' % current_app.name
current_app是一个本地代理,它的类型是werkzeug.local. LocalProxy,它所代理的即是我们的app对象,也就是说current_app == LocalProxy(app)。使用current_app是因为它也是一个ThreadLocal变量,对它的改动不会影响到其他线程。可以通过current_app._get_current_object()方法来获取app对象。current_app只能在请求线程里存在,因此它的生命周期也是在应用上下文里,离开了应用上下文也就无法使用。
app = Flask('__name__')
print current_app.name
同样会报错:
RuntimeError: working outside of application context
和请求上下文一样,同样可以手动创建应用上下文:
with app.app_context():
print current_app.name
这里的with语句和** with open() as f一样,是Python提供的语法糖,可以为提供上下文环境省略简化一部分工作。这里就简化了其压栈和出栈操作,请求线程创建时,Flask会创建应用上下文对象,并将其压入flask._app_ctx_stack**的栈中,然后在线程退出前将其从栈里弹出。
应用上下文也提供了装饰器来修饰hook函数,@teardown_request,它会在上下文生命周期结束前,也就是_app_ctc_stack出栈前被调用,可以用下面的代码调用验证:
@app.teardown_appcontext
def teardown_db(exception):
print 'teardown application'
需要注意的陷阱
当 app = Flask(name)构造出一个 Flask App 时,App Context 并不会被自动推入 Stack 中。所以此时 Local Stack 的栈顶是空的,current_app也是 unbound 状态。
>>> from flask import Flask
>>> from flask.globals import _app_ctx_stack, _request_ctx_stack
>>>
>>> app = Flask(__name__)
>>> _app_ctx_stack.top
>>> _request_ctx_stack.top
>>> _app_ctx_stack()
<LocalProxy unbound>
>>>
>>> from flask import current_app
>>> current_app
<LocalProxy unbound>
在编写离线脚本的时候,如果直接在一个 Flask-SQLAlchemy 写成的 Model 上调用 User.query.get(user_id),就会遇到 RuntimeError。因为此时 App Context 还没被推入栈中,而 Flask-SQLAlchemy 需要数据库连接信息时就会去取 current_app.config,current_app 指向的却是 _app_ctx_stack为空的栈顶。
解决的办法是运行脚本正文之前,先将 App 的 App Context 推入栈中,栈顶不为空后 current_app这个 Local Proxy 对象就自然能将“取 config 属性” 的动作转发到当前 App 上。
>>> ctx = app.app_context()
>>> ctx.push()
>>> _app_ctx_stack.top
<flask.ctx.AppContext object at 0x102eac7d0>
>>> _app_ctx_stack.top is ctxTrue
>>> current_app<Flask '__main__'>
>>>
>>> ctx.pop()
>>> _app_ctx_stack.top
>>> current_app
<LocalProxy unbound>
那么为什么在应用运行时不需要手动 app_context().push()呢?因为 Flask App 在作为 WSGI Application 运行时,会在每个请求进入的时候将请求上下文推入 _request_ctx_stack中,而请求上下文一定是 App 上下文之中,所以推入部分的逻辑有这样一条:如果发现 _app_ctx_stack为空,则隐式地推入一个 App 上下文。
思考部分
- 既然在 Web 应用运行时里,应用上下文 和 请求上下文 都是 Thread Local 的,那么为什么还要独立二者?
- 既然在Web应用运行时中,一个线程同时只处理一个请求,那么 _req_ctx_stack和 _app_ctx_stack肯定都是只有一个栈顶元素的。那么为什么还要用“栈”这种结构?
- App和Request是怎么关联起来的?
查阅资料后发现第一个问题是因为设计初衷是为了能让两个以上的Flask应用共存在一个WSGI应用中,这样在请求中,需要通过应用上下文来获取当前请求的应用信息。
而第二个问题则是需要考虑在非Web Runtime的环境中使用的时候,在多个App的时候,无论有多少个App,只要主动去Push它的app context,context stack就会累积起来,这样,栈顶永远是当前操作的 App Context。当一个 App Context 结束的时候,相应的栈顶元素也随之出栈。如果在执行过程中抛出了异常,对应的 App Context 中注册的 teardown函数被传入带有异常信息的参数。
这么一来就解释了这两个问题,在这种单线程运行环境中,只有栈结构才能保存多个 Context 并在其中定位出哪个才是“当前”。而离线脚本只需要 App 关联的上下文,不需要构造出请求,所以 App Context 也应该和 Request Context 分离。
第三个问题
可以参考一下源码看一下Flask是怎么实现的请求上下文:
# 代码摘选自flask 0.5 中的ctx.py文件,
class _RequestContext(object):
def __init__(self, app, environ):
self.app = app
self.request = app.request_class(environ)
self.session = app.open_session(self.request)
self.g = _RequestGlobals()
Flask中的使用_RequestContext的方法如下:
class Flask(object):
def request_context(self, environ):
return _RequestContext(self, environ)
在Flask类中,每次请求都会调用这个request_context函数。这个函数则会创建一个_RequestContext对象,该对象需要接收WerkZeug中的environ对象作为参数。这个对象在创建时,会把Flask实例本身作为实参传进去,所以虽然每次http请求都创建一个_RequestContext对象,但是每次创建的时候传入的都是同一个Flask对象,因此:
由同一个Flask对象相应请求创建的_RequestContext对象的app成员变量都共享一个application
通过Flask对象中创建_RequestContext对象,并将Flask自身作为参数传入的方式实现了多个request context对应一个application context。
然后可以看self.request = app.request_class(environ)这句
由于app成员变量是app = Flask(name) 这个对象,所以app.request_class就是Flask.request_class,而在Flask类的定义中:
request_class = Request
class Request(RequestBase):
....
所以self.request = app.request_class(environ)实际上是创建了一个Request对象。由于一个http请求对应一个_RequestContext对象的创建,而每个_RequestContext对象的创建对应一个Request对象的创建,所以,每个http请求对应一个Request对象。
因此
application 就是指app = Flask(name)对象
request 就是对应每次http 请求创建的Request对象
Flask通过_RequestContext将App与Request关联起来
仅为自己学习用,汇总了查阅的资料,记录了一些笔记,转载请注明资料中原作者。
Flask的Context(上下文)学习笔记的更多相关文章
- Python 上下文(Context)学习笔记
前言 最早接触到with语句的时候,是初学python,对文件进行读写的时候,当时文件读写一般都是用open()函数来对文件进行读写,为了防止读写的过程中出现错误,也为了让代码更加的pythonic, ...
- 《Flask Web开发》学习笔记
第一部分 Flask简介 前言:想熟练掌握一门web框架,为以后即将诞生的测试工具集做准备.为什么选择flask要做熟练掌握的一门框架,而不是其他的,最主要的原因是可以随意定制. 特别提醒:这本书的代 ...
- Flask 学习笔记
Flask 是一个Web应用框架,我也就是一边看书,一边写博文做记录 这本书: 首先安装Flask ,和配置环境,参考这边博客: 然后就开始学习Flask 了. 1.Application and R ...
- [原创]java WEB学习笔记59:Struts2学习之路---OGNL,值栈,读取对象栈中的对象的属性,读取 Context Map 里的对象的属性,调用字段和方法,数组,list,map
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- Python Flask学习笔记之模板
Python Flask学习笔记之模板 Jinja2模板引擎 默认情况下,Flask在程序文件夹中的templates子文件夹中寻找模板.Flask提供的render_template函数把Jinja ...
- Python Flask学习笔记之Hello World
Python Flask学习笔记之Hello World 安装virtualenv,配置Flask开发环境 virtualenv 虚拟环境是Python解释器的一个私有副本,在这个环境中可以安装私有包 ...
- Flask 学习笔记(一)
一.Web 服务器与 Web 框架 首先明确一下,要运行一个动态网页,我们需要 一个 Web 服务器来监听并响应请求,如果请求的是静态文件它就直接将其返回,如果是动态 url 它就将请求转交给 Web ...
- 《C#并发编程经典实例》学习笔记—2.7 避免上下文延续
避免上下文延续 在默认情况下,一个 async 方法在被 await 调用后恢复运行时,会在原来的上下文中运行. 为了避免在上下文中恢复运行,可让 await 调用 ConfigureAwait 方法 ...
- SpringNet学习笔记一
---恢复内容开始--- 最近看了园子里的大神分享的springnet框架的知识,感觉挺不错的,自己闲下来也研究研究springnet.这几天看了springnet容器的基础篇IOC和AOP,也有点个 ...
随机推荐
- PHP几种加密方式
1.MD5() 2.Sha1() 3.urlencode()方法用于加密,urldecode()方法用于解密 4.base64_encode ( ) 64位加密 base64_decode ( ...
- 使用Docker搭建CentOS 7 + Apache 2.4+ PHP7
从Docker Hub上Pull最新的CentOS 7镜像并新建容器 # sudo docker pull centos docker run -p 8082:80 --name centos_c - ...
- 「NOI2018」屠龙勇士(EXCRT)
「NOI2018」屠龙勇士(EXCRT) 终于把传说中 \(NOI2018D2\) 的签到题写掉了... 开始我还没读懂题目...而且这题细节巨麻烦...(可能对我而言) 首先我们要转换一下,每次的 ...
- DBUtils的增删改查
数据准备: CREATE DATABASE mybase; USE mybase; CREATE TABLE users( uid INT PRIMARY KEY AUTO_INCREMENT, us ...
- python实现线性排序-基数排序
基数排序算法是一种是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较. 由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于 ...
- Ubuntu 16.04 python和OpenCV安装
Ubuntu 16.04 python和OpenCV安装:最进在做深度学习和计算机视觉的有关内容,因此要在python中用到opencv.我的电脑装的是Ubuntu 16.04,python 2.7和 ...
- Tools - Atom编辑器
Atom官网 Atom编辑器的常用插件 预览 document-outline:Show a heirarchical outline of a text document minimap:A pre ...
- C++primer笔记之顺序容器
最近又重新拾起C++primer,发现每一次看都会有不同的体验,但每一次看后因为不常用,忘记得很快,所以记笔记是很关键的一环,咋一看是浪费时间,实际上是节省了很多时间.下面就把这一节的内容做一个简单的 ...
- PyTorch(二)Intermediate
Convolutional Neural Network import torch import torch.nn as nn import torchvision import torchvisio ...
- apache和tomcat的区别和联系
两者既有联系又有区别,是两个软件,可独立使用,也可整合使用.Apache是web服务器(静态解析,如HTML),本身只支持html,Web服务器专门处理HTTP请求(request),可以通过插件支持 ...