Django Rest framework 之 序列化
- RESTful 规范
- django rest framework 之 认证(一)
- django rest framework 之 权限(二)
- django rest framework 之 节流(三)
- django rest framework 之 版本(四)
- django rest framework 之 解析器(五)
- django rest framework 之 序列化(六)
- django rest framework 之 分页(七)
- django rest framework 之 视图(八)
一、前言
先建立数据库,并添加相应的数据,用来后面序列化使用
1、建立数据库模型
为数据建立相应的数据库模型,并且有一对一,多对多,外键关联。
from django.db import models
class UserGroup(models.Model):
title = models.CharField(max_length=32)
class UserInfo(models.Model):
user_type_choices = (
(1,'普通用户'),
(2,'VIP'),
(3,'SVIP'),
)
user_type = models.IntegerField(choices=user_type_choices)
username = models.CharField(max_length=32,unique=True)
password = models.CharField(max_length=64)
group = models.ForeignKey("UserGroup", on_delete=models.CASCADE)
roles = models.ManyToManyField("Role")
class UserToken(models.Model):
user = models.OneToOneField(to='UserInfo', on_delete=models.CASCADE)
token = models.CharField(max_length=64)
class Role(models.Model):
title = models.CharField(max_length=32)
并执行数据库迁移操作
python manage.py makemigrations
python manage.py migrate
2、添加少量数据
当数据迁移执行之后,会在sqlite数据库中生活如下表
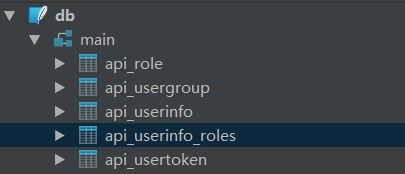
多对多关系的时候,django自动生成第三张表维系表关系,字段分别是userinfo和role的id,其中api_userinfo_roles为多对多关系生成的表。
在表中添加少量数据
<1>、UserInfo表

<2>、UserGroup表

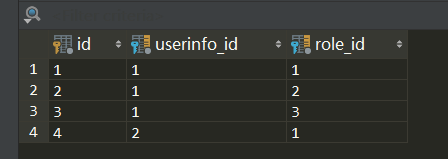
3、UserInfo_roles表
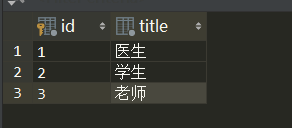
4、roles表
二、序列化的简单使用
1、不使用序列化
<1>、路由
from django.conf.urls import url
from .views import RoleView
urlpatterns = [
url(r'^role/$', RoleView.as_view()),
]
<2>、视图
from rest_framework.views import APIView
from .models import Role
import json
class RoleView(APIView):
def get(self, request, *args, **kwargs):
roles = Role.objects.all().values('id' ,'title')
print(roles, type(roles)) # roles为一个QuerySet对象
ret_roles = json.dumps(list(roles), ensure_ascii=False) # 多条数据
return HttpResponse(ret_roles)
2、简单使用Serializer
<1>、定义序列化类
from rest_framework import serializers
class RoleSerializer(serializers.Serializer):
id = serializers.IntegerField()
title = serializers.CharField()
<2>、视图
class RoleView(APIView):
def get(self, request, *args, **kwargs):
# 多条数据
# 将序列化后的数据都存到ser.data(OrderDict有序字典中)中
# roles = Role.objects.all()
# ser_roles = RoleSerializer(instance=roles, many=True)
# print(ser_roles, type(ser_roles)) # ListSerializer对象
# ret_roles = json.dumps(ser_roles.data, ensure_ascii=False) # 多条数据
# return HttpResponse(ret_roles)
# 单条数据
role = Role.objects.all().first()
ser_role = RoleSerializer(instance=role, many=False) # RoleSerializer对象
print(ser_role, type(ser_role)) # 单条数据
ret_roles = json.dumps(ser_role.data, ensure_ascii=False)
return HttpResponse(ret_roles)
总结:上面可以实现数据的简单序列化,但是无法自定义字段,也无法对数据进行处理,不方便,限制较大
三、进一步使用Serializer
1、路由
from django.conf.urls import url
from .views import UserInfo
urlpatterns = [
url(r'^userinfo/$', UserInfo.as_view()),
]
2、视图
class UserInfoView(APIView):
def get(self, request, *args, **kwargs):
users = UserInfo.objects.all()
users_ser = UserSerializer(instance=users, many=True)
users_ret = json.dumps(users_ser.data, ensure_ascii=False)
# print(users_ser.data, type(users_ser.data), type(users_ser.data[0]))
return HttpResponse(users_ret)
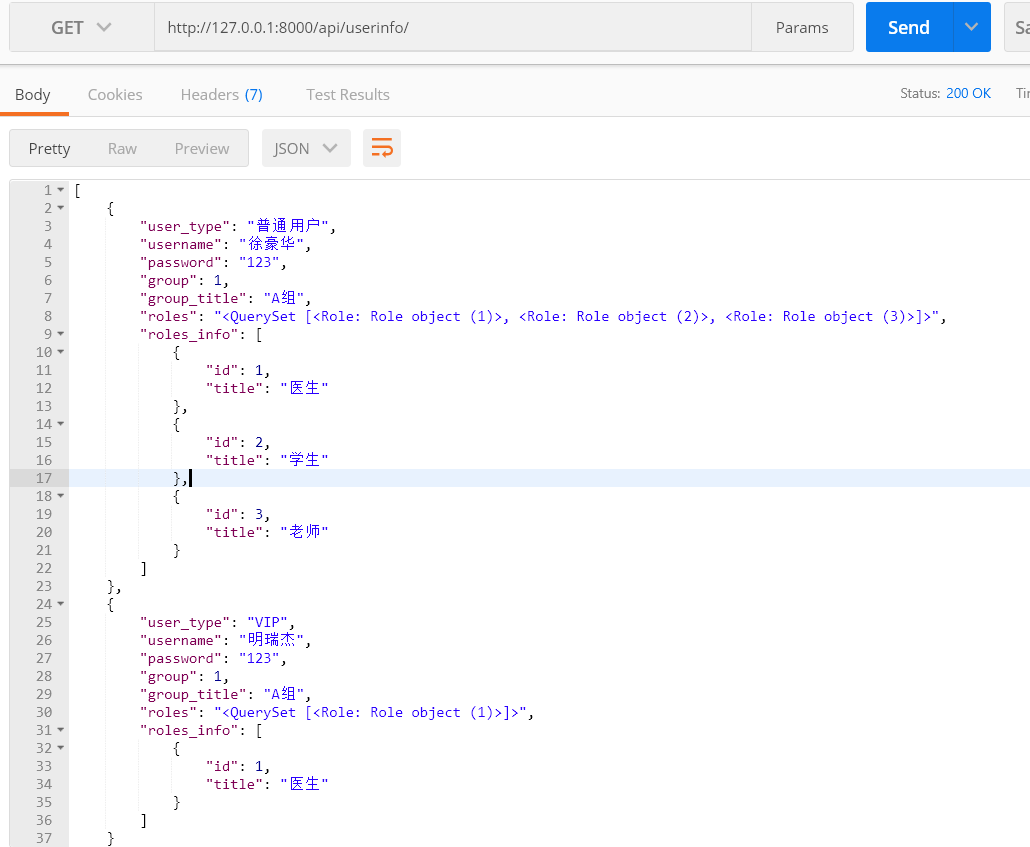
3、使用serializer
class UserSerializer(serializers.Serializer):
type = serializers.IntegerField(source='user_type')
user_type = serializers.CharField(source='get_user_type_display') # choices字段显示
username = serializers.CharField()
pwd = serializers.CharField(source='password') # 自定义serializer中的key值
group_title = serializers.CharField(source='group.title') # 关联对象属性
roles = serializers.CharField(source='roles.all') # 多对多关系
roles_info = serializers.SerializerMethodField() # 表示自定义方法,显示querytset对象详情
def get_roles_info(self, row):
roles = row.roles.all()
ret = []
for item in roles:
ret.append(
{
'id': item.id,
'title': item.title
}
)
return ret
注:
- 如果没有指定在
Filed中没有定义source参数的时候,就自动与数据库modles定义的字段进行匹配,如上面的userrname字段。在定义字段后,Serializer类中可以自定义属性如type - 当
models中是以choice定义时:需要定义source参数定义get_字段名_display才能获取数据,这与在模板语言中的用法一样,如上面的user_type - 外键关联的时候,直接 外键字段名.属性 的方式定义传参给source参数即可,如上面的
group.title - 对于roles字段,想直接获取所有的对象,但是无法做到细粒度的将对象的所有属性展示出来,只能获取到
QuerySet对象 - 自定义字段,处理数据,如
roles_info获取所有的role对象的属性,处理数据可以定义方法,方法名格式为get_属性,并return值最终返回值
执行结果:

另:自定义字段也可以采取继承的方式,如:
class UsernameField(serializers.CharField):
def to_representation(self, value):
return 'username' + value
重写to_representation方法,value为从数据库取出的值,然后对value进行处理,在返回即可
并将序列化类中的username改为
username = UsernameField()
四、使用ModelSerializer组件
1、包装Serializer
class UserSerializer(serializers.ModelSerializer):
user_type = serializers.CharField(source='get_user_type_display')
roles = serializers.CharField(source='roles.all') # 外键关联
roles_info = serializers.SerializerMethodField() # 表示自定义方法,显示外键关联详情
group_title = serializers.CharField(source='group.title')
def get_roles_info(self, row):
roles = row.roles.all()
ret = []
for item in roles:
ret.append(
{
'id': item.id,
'title': item.title
}
)
return ret
class Meta:
model = UserInfo
# fields = '__all__' # 为全部的字段做匹配
fields = ['user_type', 'username', 'password', 'group', 'group_title', 'roles', 'roles_info'] # 自定义需要展示的字段
extra_kwargs = {'group': {'source': 'group_id'}}
ModelSerializer与Serializer区别在于:ModelSerializer支持了Serializer中所有的操作,并且通过自动生成所有数据字段与序列化类的一一对应关系,而不用自己手动添加。
即Serializer是ModelSerializer的父类,所以ModelSerializer才会支持Serializer的所有操作
返回结果
2、ModelSerializer深度控制
在上面,看到在进行连表查询的时候,只能获取到外键关联对象,在当前表中存储的id,怎样拿到外键关联对象的具体信息。
class UserSerializer(serializers.ModelSerializer):
# 自动向内部进行深度查询 depth表示查询层数
class Meta:
model = UserInfo
# fields = "__all__"
fields = ['id','username','password','group','roles']
depth = 1 # 0 ~ 10 默认的depth为0
class UserInfoView(APIView):
def get(self, request, *args, **kwargs):
users = UserInfo.objects.all()
users_ser = UserSerializer(instance=users, many=True)
users_ret = json.dumps(users_ser.data, ensure_ascii=False)
# print(users_ser.data, type(users_ser.data), type(users_ser.data[0]))
return HttpResponse(users_ret)
注:这里的depth就表示深度查询的层数,默认的层数为0,层数越多查询效率越慢。
返回结果
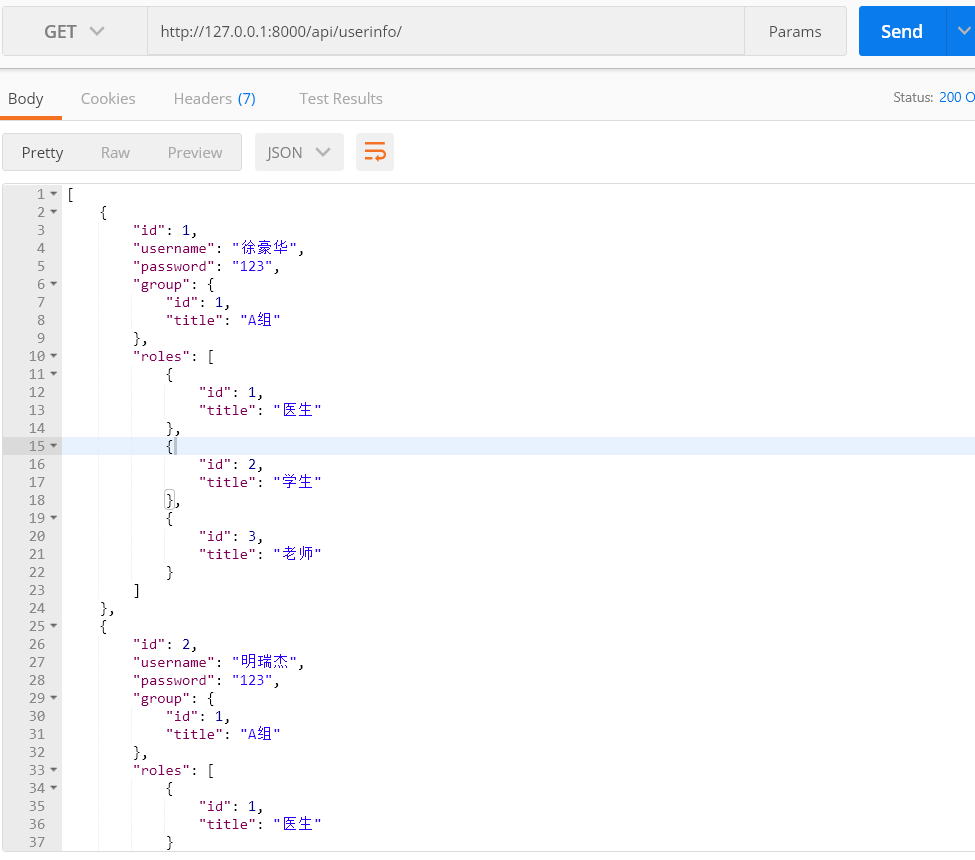
3、自动生成链接
在上面我们看到,在返回组group的时候是返回该组的id,或者用depth深度控制,返回组的详细信息。在restful规范中,规定应该给出相应的详情链接,可以通过url拼接,在django rest framework中也有相对应的实现。
首先改写一下用户信息序列化类,使之能够提供用户组详情的有关url
class UserSerializer(serializers.ModelSerializer):
group = serializers.HyperlinkedIdentityField(view_name='api:gp', lookup_field='group_id', lookup_url_kwarg='xxx')
# view_name参数 进行传参的时候是参考路由匹配中的name与namespace参数
# lookeup_field参数是根据在UserInfo表中的连表查询字段group_id
# look_url_kwarg参数在做url反向解析的时候会用到
class Meta:
model = UserInfo
fields = ['id','username','password','group','roles']
depth = 1 # 0 ~ 10
class UserInfoView(APIView):
def get(self, request, *args, **kwargs):
users = UserInfo.objects.all()
users_ser = UserSerializer(instance=users, many=True, context={'request': request}) # 在做链接的时候需要添加context参数
users_ret = json.dumps(users_ser.data, ensure_ascii=False)
# print(users_ser.data, type(users_ser.data), type(users_ser.data[0]))
return HttpResponse(users_ret)
# 添加group序列化类
class GroupSerializer(serializers.ModelSerializer):
class Meta:
model = UserGroup
fields = "__all__"
# 返回用户组的详细信息
class GroupView(APIView):
def get(self,request,*args,**kwargs):
pk = kwargs.get('xxx')
obj = UserGroup.objects.filter(pk=pk).first()
ser = GroupSerializer(instance=obj,many=False)
ret = json.dumps(ser.data,ensure_ascii=False)
return HttpResponse(ret)
返回结果

当我们点解用户组详情链接后,返回结果
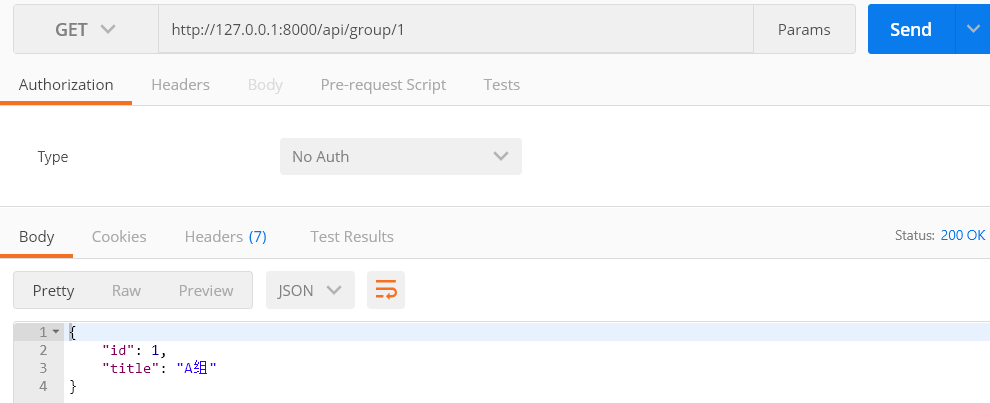
4、校验数据
序列化不仅可以做数据的返回,也可以对前端提交的数据进行校验。
<1>、类方法检验
class TitleValidator(object):
def __init__(self, base):
self.base = base
def __call__(self, value):
if not value.startswith(self.base):
message = '标题必须以 %s 为开头。' % self.base
raise serializers.ValidationError(message)
def set_context(self, serializer_field):
# 执行验证之前调用,serializer_fields是当前字段对象
pass
class UserGroupSerializer(serializers.Serializer):
title = serializers.CharField(error_messages={'required': '标题不能为空'}, validators=[TitleValidator('Django'),])
class UserGroupView(APIView):
def post(self,request,*args,**kwargs):
print(request.data)
ser = UserGroupSerializer(data=request.data)
if ser.is_valid():
print(ser.validated_data['title'])
else:
print(ser.errors)
return HttpResponse('提交数据')
上面的TitileValidator类封装了对request.data前端传来的数据的校验,title相对应的是数据中的key为title的值。TitileValidator实现了call()特殊方法,并把具体的验证逻辑封装到里边,是一个可直接调用的对象。而self.base则为具体的title对应的数据,进行处理。
<2>、钩子方法
class UserGroupSerializer(serializers.Serializer):
title = serializers.CharField()
def validate_title(self, value):
from rest_framework import exceptions
if not value:
raise exceptions.ValidationError('不可为空')
return value
class UserGroupView(APIView):
def post(self,request,*args,**kwargs):
print(request.data)
ser = UserGroupSerializer(data=request.data)
if ser.is_valid():
print(ser.validated_data['title'])
else:
print(ser.errors)
return HttpResponse('提交数据')
在定义钩子方法的时候,钩子函数是以validate_字段名的方式进行命名的。只有遵循这样的格式,在Serializer内部会对钩子函数的名字进行拆分并识别出来。在validate_title内部封装了对数据的校验操作,value则为具体的值
Django Rest framework 之 序列化的更多相关文章
- Django REST Framework的序列化器是什么?
# 转载请留言联系 用Django开发RESTful风格的API存在着很多重复的步骤.详细可见:https://www.cnblogs.com/chichung/p/9933861.html 过程往往 ...
- Django Rest Framework(2)-----序列化详解(serializers)
REST framework中的序列化类与Django的Form和ModelForm类非常相似.我们提供了一个Serializer类,它提供了一种强大的通用方法来控制响应的输出,以及一个ModelSe ...
- Django restful Framework 之序列化与反序列化
1. 首先在已建好的工程目录下新建app命名为snippets,并将snippets app以及rest_framework app加到工程目录的 INSTALLED_APPS 中去,具体如下: IN ...
- Django rest framework之序列化小结
最近在DRF的序列化上踩过了不少坑,特此结合官方文档记录下,方便日后查阅. [01]前言 serializers是什么?官网是这样的”Serializers allow complex d ...
- django rest framework serializers序列化
serializers是将复杂的数据结构变成json或者xml这个格式的 serializers有以下几个作用: - 将queryset与model实例等进行序列化,转化成json格式,返回给用户(a ...
- DRF Django REST framework 之 序列化(三)
Django 原生 serializer (序列化) 导入模块 from django.core.serializers import serialize 获取queryset 对queryset进行 ...
- django-插件django REST framework,返回序列化的数据
官网: http://www.django-rest-framework.org 1.安装 pip install djangorestframework 2.在setting.py中注册app 中添 ...
- django rest framework serializers
django rest framework serializers序列化 serializers是将复杂的数据结构变成json或者xml这个格式的 serializers有以下几个作用:- 将qu ...
- django rest framework 项目创建
Django Rest Framework 是一个强大且灵活的工具包,用以构建Web API 为什么要使用Rest Framework Django REST Framework可以在Django的基 ...
随机推荐
- Centos7部署Kubernetes集群
目录贴:Kubernetes学习系列 1.环境介绍及准备: 1.1 物理机操作系统 物理机操作系统采用Centos7.3 64位,细节如下. [root@localhost ~]# uname -a ...
- Transport Layer Protocols
1 End-to-end Protocols(端到端协议) 传输层协议往往是主机对主机(host-to-host)或者说是端到端(end-to-end).通常希望传输层协议可以提供如下service: ...
- Android框架式编程之MVP架构
MVP(Model-View-Presenter)模式.是将APP的结构分为三层:View - Presenter - Model. View 1. 提供UI交互 2. 在presenter的控制下修 ...
- [CocoaPods]故障排除
安装CocoaPods 如果您在macOS 10.9.0-10.9.2上安装,当RubyGems尝试安装jsongem 时可能会遇到问题.要解决此问题,请遵循以下说明 从macOS 10.8升级到10 ...
- java相关技术问答(二)
String为什么是final的 首先是为了安全性,final表示不可变,不可被继承,不能修改其方法保证安全 在多线程环境下,final类型的String保证线程安全 String支持字符串常量池,相 ...
- 参考信息 - Serverless
初见 Serverless的本质是什么? 看懂 Serverless,这一篇就够了 关于「Serverless」的完整指南:你知道和不知道的 了解 7个开源平台,入门无服务器计算
- 机器学习技法笔记:15 Matrix Factorization
Roadmap Linear Network Hypothesis Basic Matrix Factorization Stochastic Gradient Descent Summary of ...
- 2-1 编写HelloWorld
引用外部的vue.js文件
- 【sping揭秘】17、@Around,@Introduction
package cn.cutter.start.bean; import org.apache.commons.logging.Log; import org.apache.commons.loggi ...
- 持续集成工具-Jenkins 使用介绍
Jenkins 是一个可扩展的持续集成引擎,可以为我们提供代码自动编译.打包和发布工作,减少部署成本. 一.安装与启动 Jenkins 提供了多种便捷的安装方式,比较推荐使用执行 war 包的方式. ...