海量日志采集Flume(HA)
海量日志采集Flume(HA)
1.介绍:
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
2.日志采集
Flume—对哪个ip 哪个端口进行监控 --- 数据监控—接收数据----内存—存储本地硬盘
3.数据处理
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。 Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX tail)、Syslog(Syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
4.Flume原理:
Flume OG:
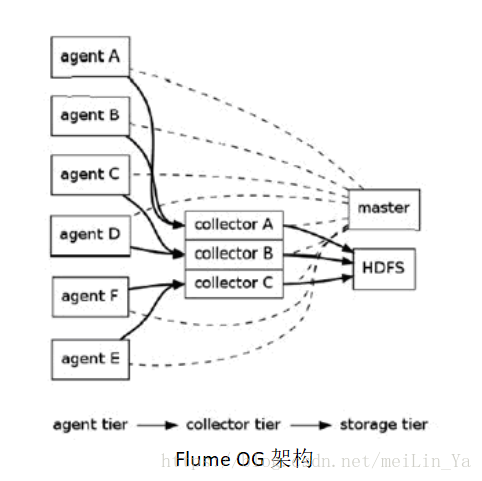
Flume逻辑上分三层架构:Agent,Collector,Storage。采用多Master,为保持数据一致项,使用zookeeper,保持数据高可用和一致性。
特点:
· 3个角色:代理节点(agent),收集节点(collector),主节点(master).
· gent 从各个数据源收集日志数据,将收集到的数据集中到 Collector,然后由收集节点汇总存入 HDFS。master 负责管理 agent,collector 的活动。
· agent、collector 由 source、sink 组成,代表在当前节点数据是从 source 传送到 sink。
Flume NG

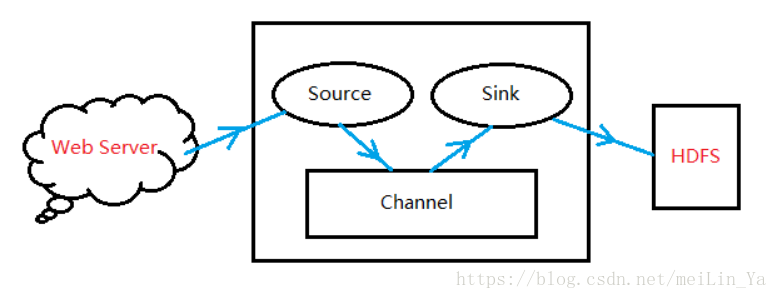
· Source:完成对日志数据的收集,分成 transtion 和 event 打入到Channel之中。
|
Source类型 |
说明 |
|
Avro Source |
支持Avro协议(实际上是Avro RPC),提供一个Avro的接口,需要往设置的地址和端口发送Avro消息,Source就能接收到,如:Log4j Appender通过Avro Source将消息发送到Agent |
|
Thrift Source |
支持Thrift协议,提供一个Thrift接口,类似Avro |
|
Exec Source |
Source启动的时候会运行一个设置的UNIX命令(比如 cat file),该命令会不断地往标准输出(stdout)输出数据,这些数据就会被打包成Event,进行处理 |
|
JMS Source |
从JMS系统(消息、主题)中读取数据,类似ActiveMQ |
|
Spooling Directory Source |
监听某个目录,该目录有新文件出现时,把文件的内容打包成Event,进行处理 |
|
Netcat Source |
监控某个端口,将流经端口的每一个文本行数据作为Event输入 |
|
Sequence Generator Source |
序列生成器数据源,生产序列数据 |
|
Syslog Sources |
读取syslog数据,产生Event,支持UDP和TCP两种协议 |
|
HTTP Source |
基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 |
|
Legacy Sources |
兼容老的Flume OG中Source(0.9.x版本) |
|
自定义Source |
使用者通过实现Flume提供的接口来定制满足需求的Source。 |
· Channel:主要提供一个队列的功能,对source提供中的数据进行简单的缓存。
|
Channel类型 |
说明 |
|
Memory Channel |
Event数据存储在内存中 |
|
JDBC Channel |
Event数据存储在持久化存储中,当前Flume Channel内置支持Derby |
|
File Channel |
Event数据存储在磁盘文件中 |
|
Spillable Memory Channel |
Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用) |
|
Pseudo Transaction Channel |
测试用途 |
|
Custom Channel |
自定义Channel实现 |
· Sink:取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
|
Sink类型 |
说明 |
|
HDFS Sink |
数据写入HDFS |
|
Logger Sink |
数据写入日志文件 |
|
Avro Sink |
数据被转换成Avro Event,然后发送到配置的RPC端口上 |
|
Thrift Sink |
数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
|
IRC Sink |
数据在IRC上进行回放 |
|
File Roll Sink |
存储数据到本地文件系统 |
|
Null Sink |
丢弃到所有数据 |
|
HBase Sink |
数据写入HBase数据库 |
|
Morphline Solr Sink |
数据发送到Solr搜索服务器(集群) |
|
ElasticSearch Sink |
数据发送到Elastic Search搜索服务器(集群) |
|
Kite Dataset Sink |
写数据到Kite Dataset,试验性质的 |
|
Custom Sink |
自定义Sink实现 |

Flume安装和使用:

安装

运行配置:

a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1运行:
在/home/bigdata/flume1.6目录下运行
flume-ng agent -n a1 -c . -f ./conf/avro.conf -Dflume.root.logger=INFO,console
当flume可以运行我们就体会下收集不同数据源(source)日志,并存放到hdfs上
source: avro
flume-ng avro-client -c /home/bigdata/flime1.6/ -H ry-hadoop1 -p4141 -F ./avro.txt 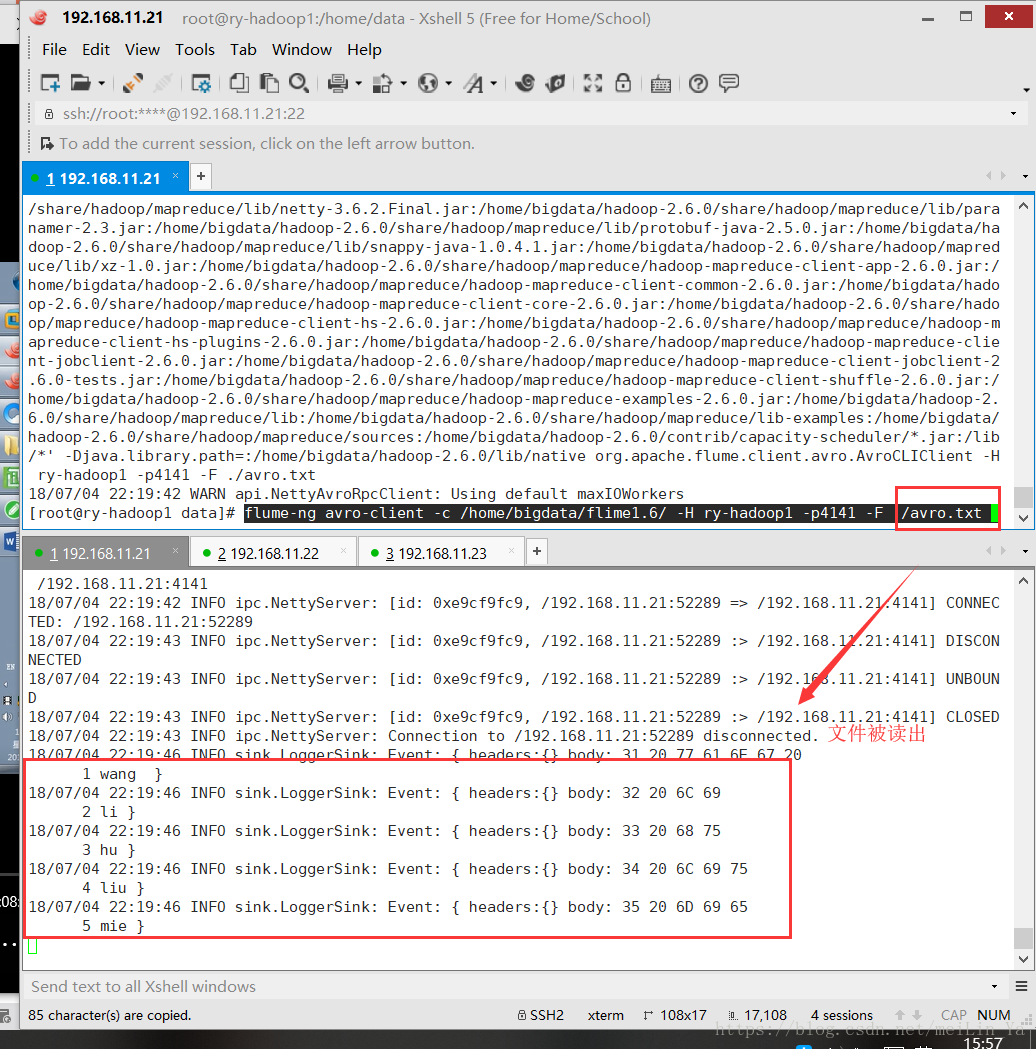
source: Exec
b1.sources=r1
b1.channels=c1
b1.sinks=k1
b1.sources.r1.type=exec
b1.sources.r1.command=tail -F /home/data/avro.txt
b1.channels.c1.type=memory
b1.channels.c1.capacity=1000
b1.channels.c1.transactionCapacity=100
b1.sinks.k1.type=logger
b1.sources.r1.channels=c1
b1.sinks.k1.channel=c1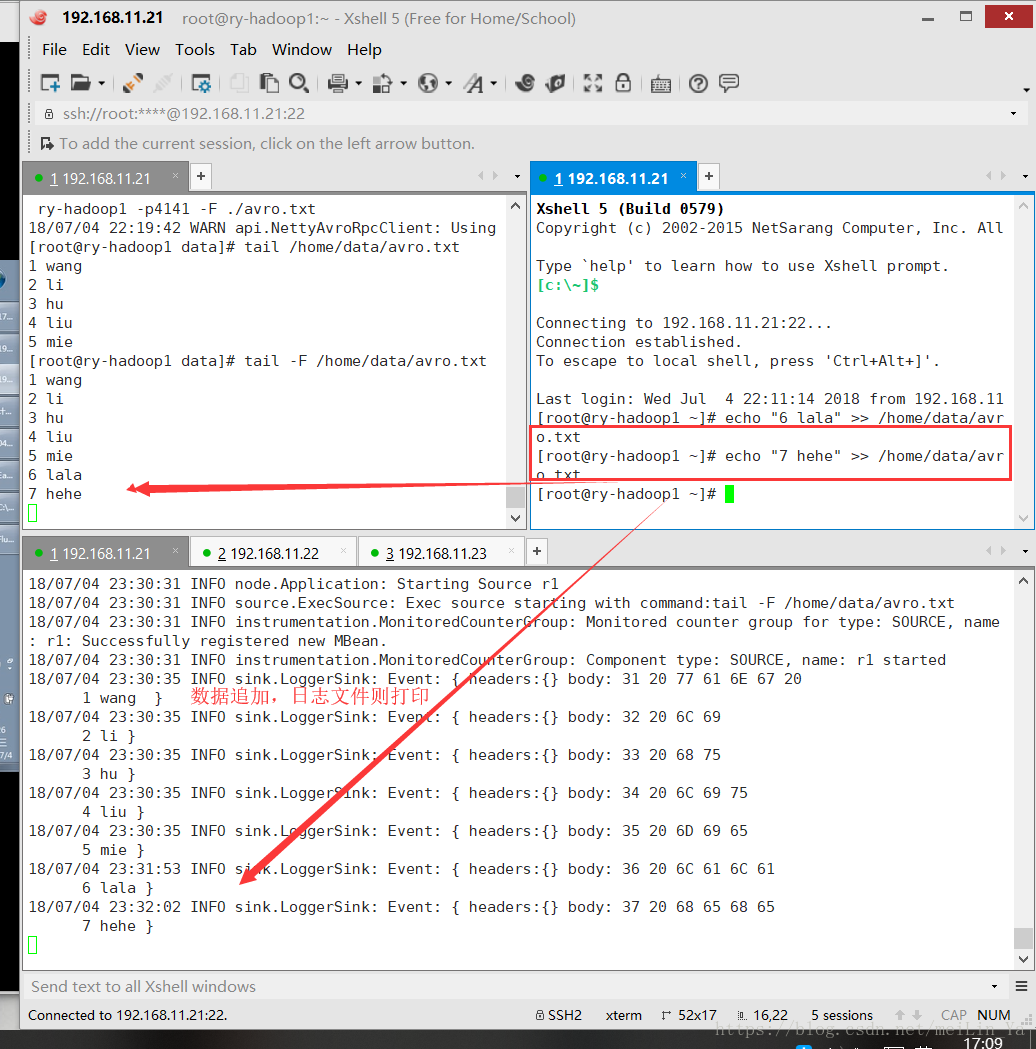
source: spooldir只能对一级目录进行收集
在数据Linux本地建一个文件夹log
agent.sources=r1
agent.channels=c1
agent.sinks=k1
agent.sources.r1.type=spooldir
agent.sources.r1.spooldir=/home/data/log
agent.sources.r1.fileHeader=true
agent.channels.c1.type=memory
agent.channels.c1.capacity=1000
agent.channels.c1.transactionCapacity=100
agent.sinks.k1.type=logger
agent.sources.r1.channels=c1
agent.sinks.k1.channel=c1启动:
flume-ng agent -n agent -c /home/bigdata/flime1.6/ -f /home/bigdata/flime1.6/conf/spoolDir.conf -Dflume.root.logger=INFO,console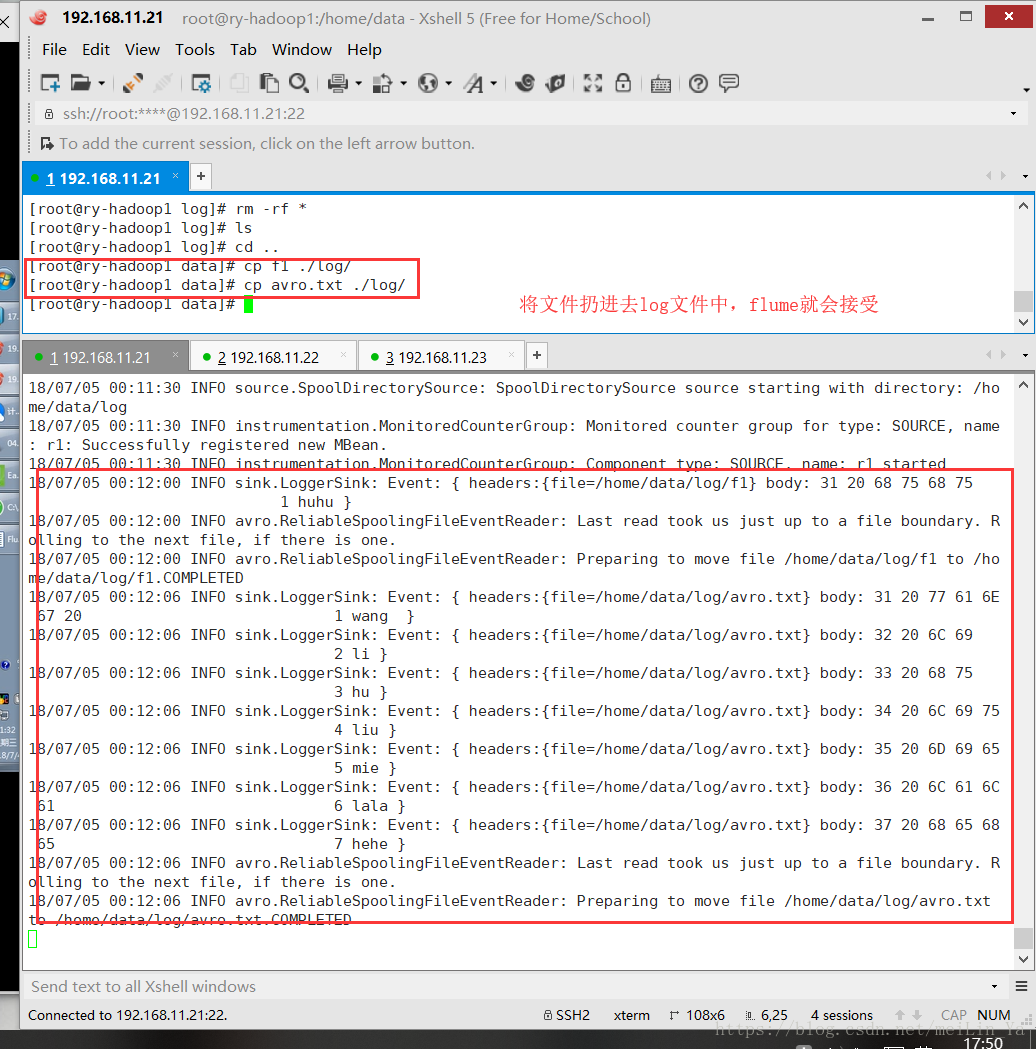
source: TCP
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = syslogtcp
a1.sources.r1.port = 5140
a1.sources.r1.host = 0.0.0.0
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1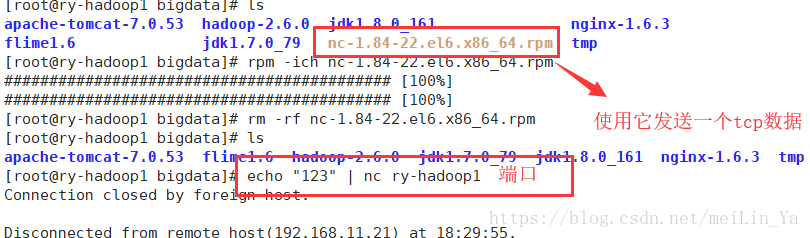
source:JSONHandler
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = org.apache.flume.source.http.HTTPSource
a1.sources.r1.port = 8888
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

source 就讲5个。
然后讲存储
hdfsSinK.conf
配置:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = syslogtcp
a1.sources.r1.port = 5140
a1.sources.r1.host = 0.0.0.0
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://ry-hadoop1:8020/flume
a1.sinks.k1.hdfs.filePrefix = Syslog
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 1
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=10240
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.idleTimeout=60
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1运行:
flume-ng agent -n a1 -c . -f ./conf/hdfsSink.conf -Dflume.root.logger=INFO,console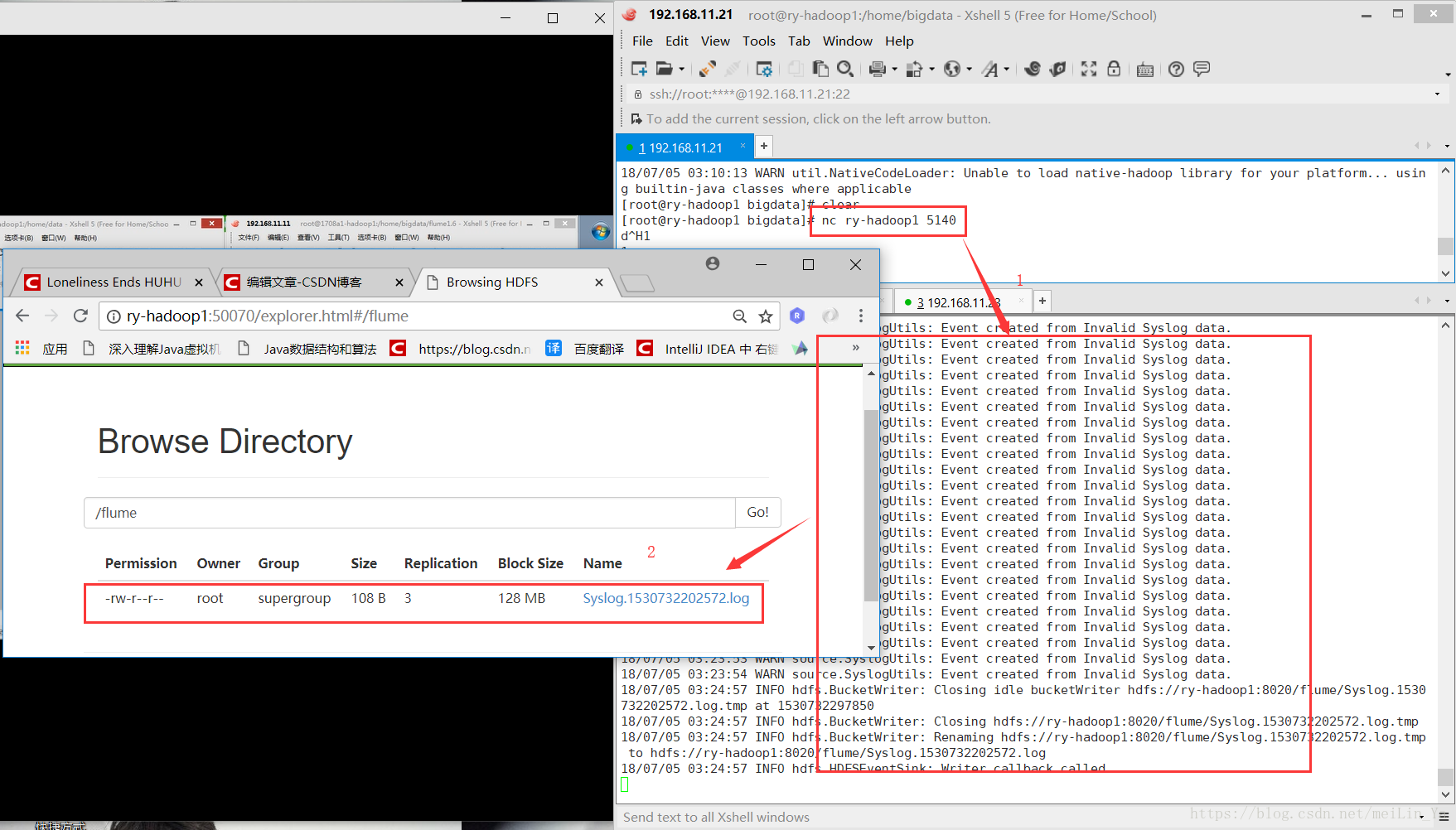
写一个shell脚本,循环输出tcp数据,然后收集在hdfs种
#!/bin/sh
int=1
while(( $int<=500000 ))
do
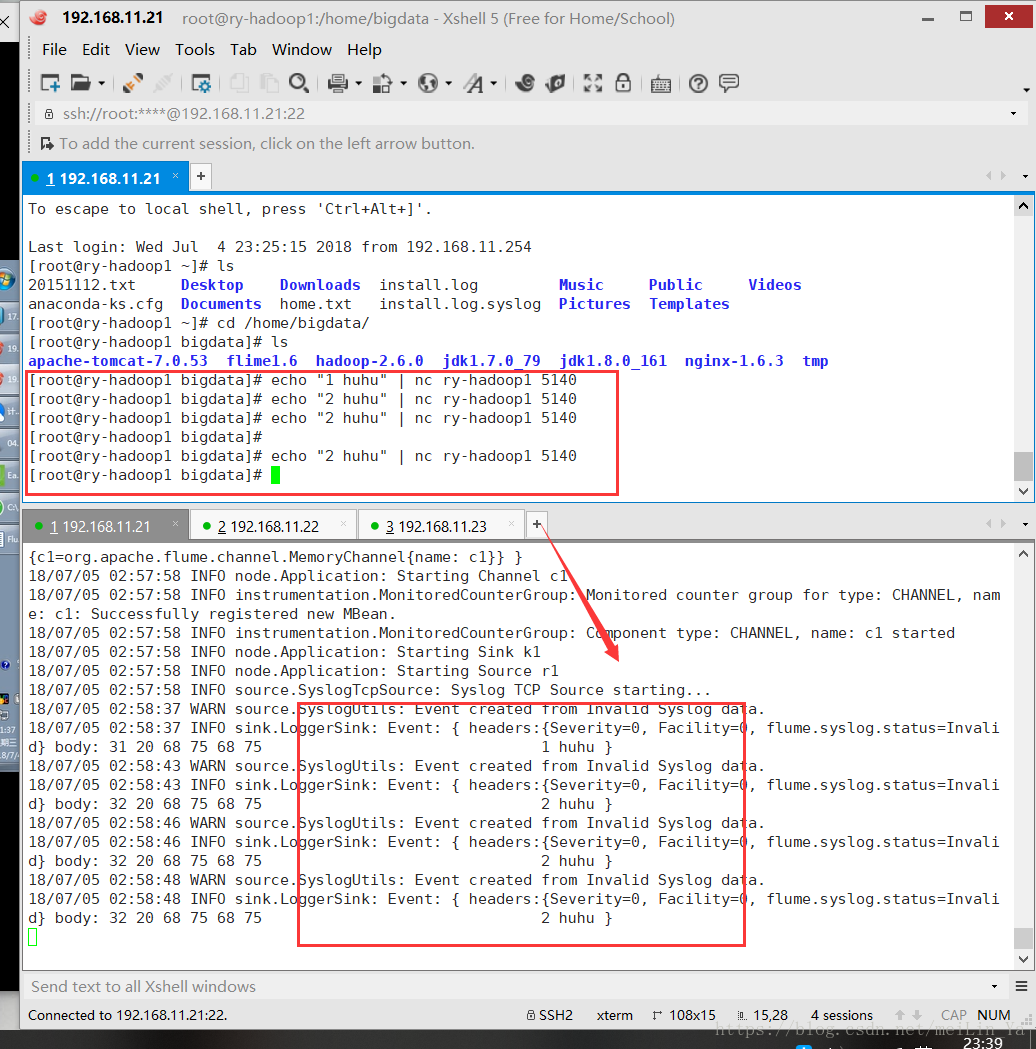
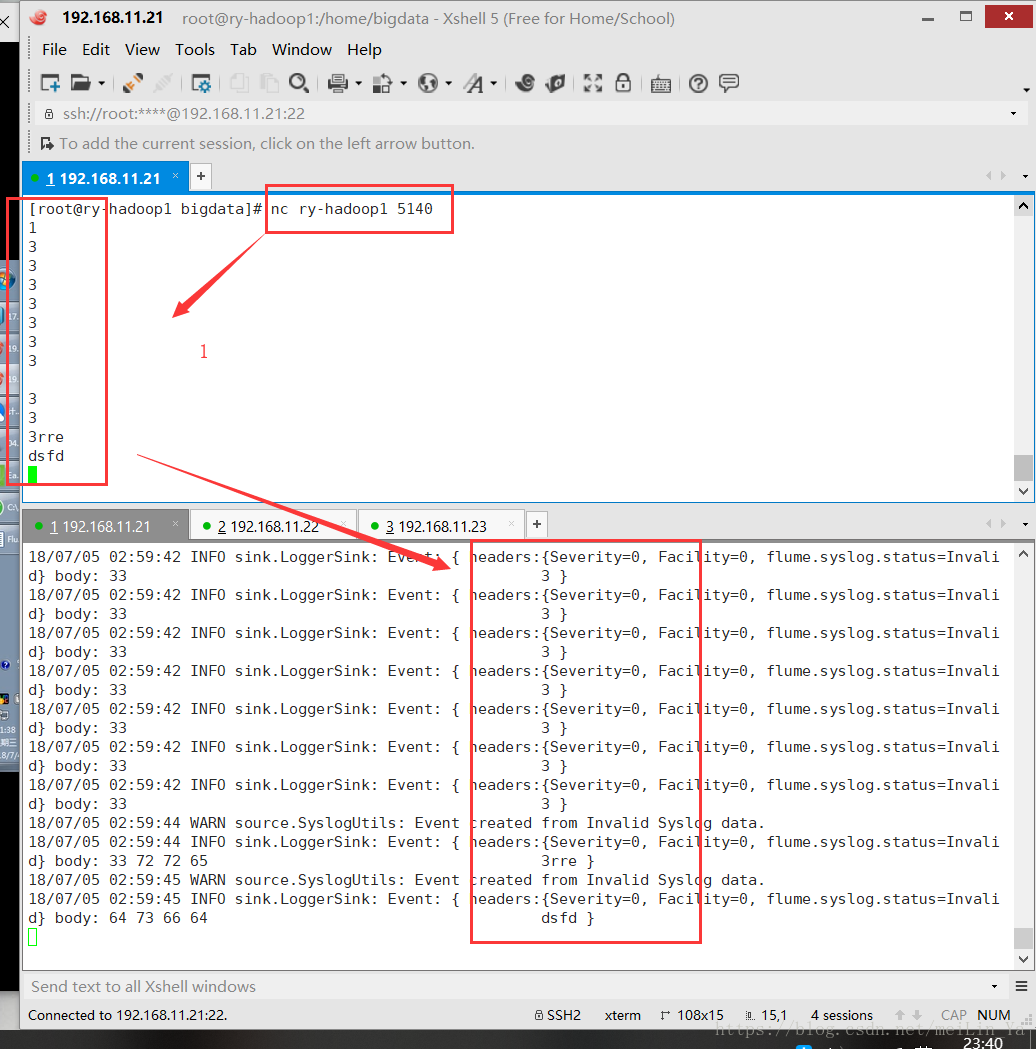
echo "this is message"$int | nc ry-hadoop1 5140
echo "this is message"$int
let "int++"
done

设定收集日志的具体时间。

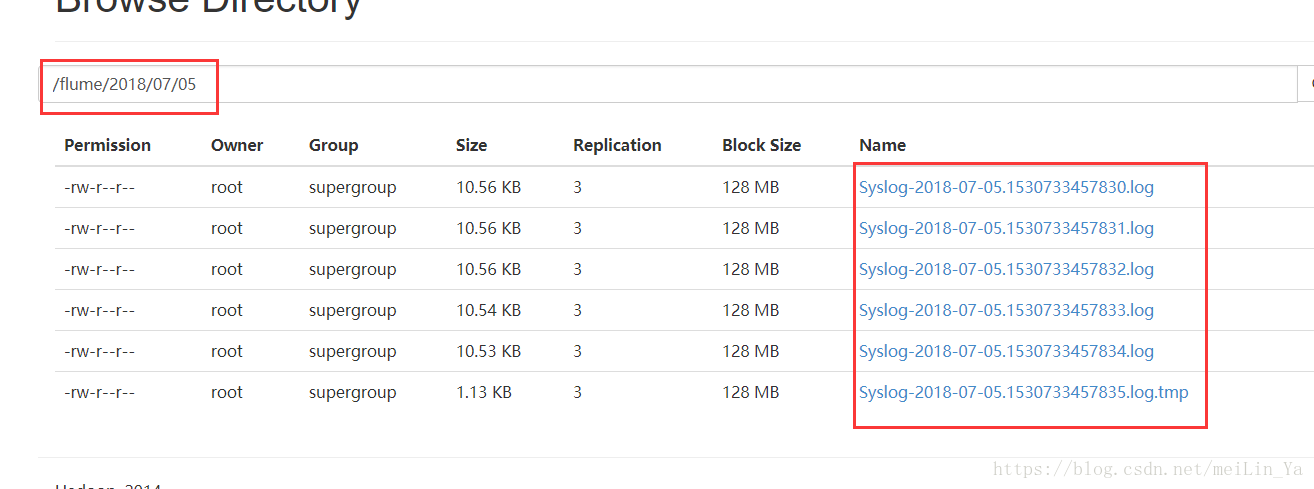
那么有个问题,当hadoop维护期间不能存储数据时,我们的日志文件存在哪里呢?
本地,那么我们看看如何存在本地
通道类型为文本形式
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = syslogtcp
a1.sources.r1.port = 5140
a1.sources.r1.host = 0.0.0.0
# Describe the sink
a1.sinks.k1.type = file_roll
a1.sinks.k1.sink.directory = /home/data/log/
a1.sinks.k1.sink.serializer=TEXT
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1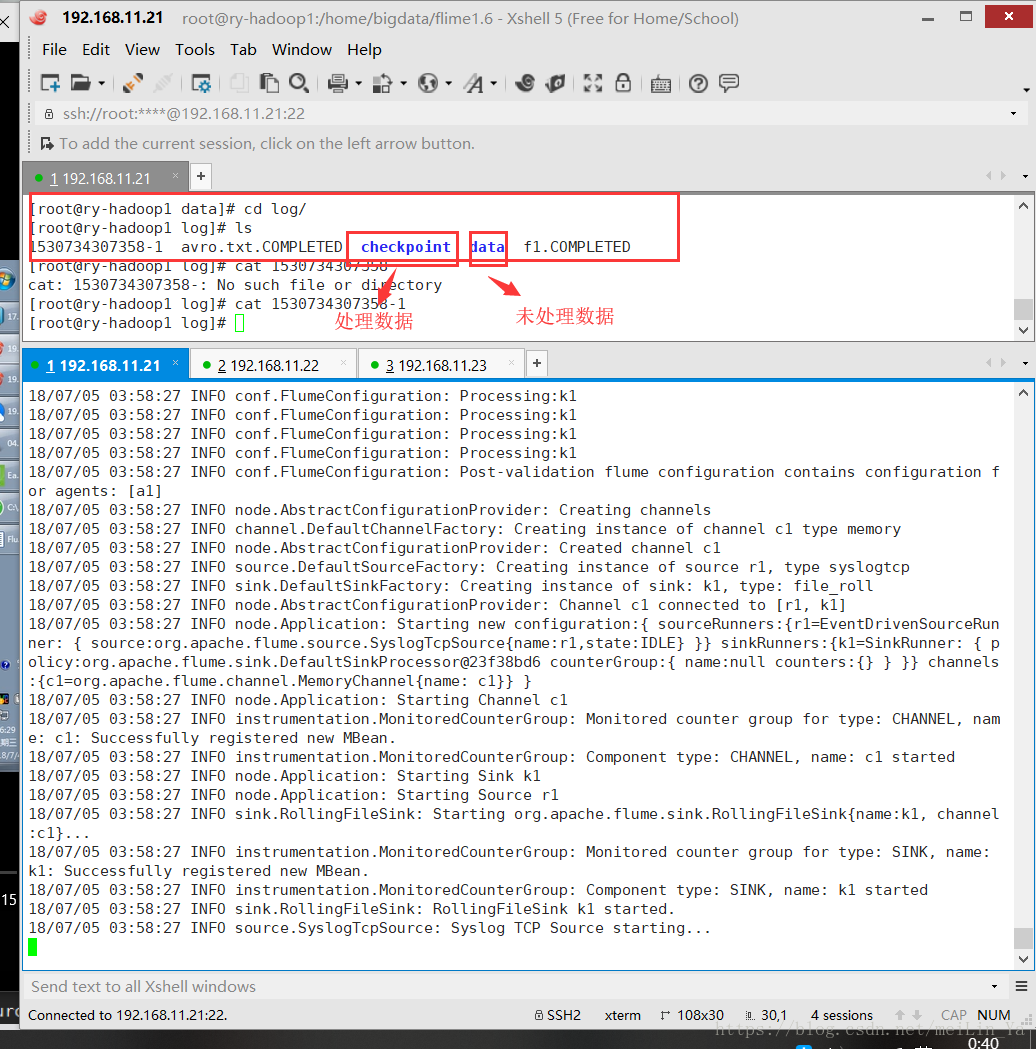
channels通道类型为文件形式
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# For each one of the sources, the type is defined
a1.sources.s1.type = syslogtcp
a1.sources.s1.host = localhost
a1.sources.s1.port = 5180
# Each sink's type must be defined
a1.sinks.k1.type = logger
# Each channel's type is defined.
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/data/log/checkpoint
a1.channels.c1.dataDir = /home/data/log/data
#Bind the source and sinks to channels
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1flume的HA:
Flume支持Fan out流从一个源到多个通道。有两种模式的Fan out,分别是复制和复用。在复制的情况下,流的事件被发送到所有的配置通道。在复用的情况下,事件被发送到可用的渠道中的一个子集。Fan out流需要指定源和Fan out通道的规则。大白话来说就是,当你采集日志的时候可以通过一个agent进行保存多份日志。启动多台集群讲多台的flume连接起来,可以同时接收到其中一台的数据进行备份,这个有点类似zookeeper。
1) Replicating Channel Selector 多个Channel
在3台机器上启动flume的avor,然后复制master连接启动source为:replicating的flume
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 5555
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1在master启动连接:
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = syslogtcp
a1.sources.r1.host = 0.0.0.0
a1.sources.r1.port = 5140
a1.sources.r1.channels = c1 c2
a1.sources.r1.selector.type = replicating
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = master
a1.sinks.k1.port = 5555
a1.sinks.k2.type = avro
a1.sinks.k2.channel = c2
a1.sinks.k2.hostname = slave1
a1.sinks.k2.port = 5555
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100当你写一条数据进入日志时,其他3台机器都会有反应
1) MulChnSel_a1.conf
输入数据映射的匹配。

a1.sources = s1
a1.channels = c1 c2
a1.sinks = k1 k2
# For each one of the sources, the type is defined
a1.sources.s1.type = org.apache.flume.source.http.HTTPSource
a1.sources.s1.port = 8887
a1.sources.s1.channels = c1 c2
a1.sources.s1.selector.type = multiplexing
a1.sources.s1.selector.header = company
a1.sources.s1.selector.mapping.ali = c1
a1.sources.s1.selector.mapping.baidu = c2
a1.sources.s1.selector.default = c2
# Each sink's type must be defined
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = master
a1.sinks.k1.port = 5555
a1.sinks.k1.channel = c1
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = slave1
a1.sinks.k2.port = 5555
a1.sinks.k2.channel = c2
# Each channel's type is defined.
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
3)Flume Sink Processors
failover的机器是一直发送给其中一个sink,当这个sink不可用的时候,自动发送到下一个sink。
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
#这个是配置failover的关键,需要有一个sink group
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
#处理的类型是failover
a1.sinkgroups.g1.processor.type = failover
#优先级,数字越大优先级越高,每个sink的优先级必须不相同
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
#设置为10秒,当然可以根据你的实际状况更改成更快或者很慢
a1.sinkgroups.g1.processor.maxpenalty = 10000
# Describe/configure the source
a1.sources.r1.type = syslogtcp
a1.sources.r1.port = 5140
a1.sources.r1.channels = c1 c2
a1.sources.r1.selector.type = replicating
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = m1
a1.sinks.k1.port = 5555
a1.sinks.k2.type = avro
a1.sinks.k2.channel = c2
a1.sinks.k2.hostname = m2
a1.sinks.k2.port = 5555
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
在hadoop1创建Flume_Sink_Processors_avro.conf配置文件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 5555
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动:
flume-ng agent -c . -f /home/bigdata/flume/conf/Flume_Sink_Processors_avro.conf -n a1 -Dflume.root.logger=INFO,console测试:
然后在hadoop1或hadoop2的任意一台机器上,测试产生log
# echo "idoall.org test1 failover" | nc localhost 51404) Load balancing Sink Processor
load balance type和failover不同的地方是,load balance有两个配置,一个是轮询,一个是随机。两种情况下如果被选择的sink不可用,就会自动尝试发送到下一个可用的sink上面。
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1
#这个是配置Load balancing的关键,需要有一个sink group
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
# Describe/configure the source
a1.sources.r1.type = syslogtcp
a1.sources.r1.port = 5140
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = m1
a1.sinks.k1.port = 5555
a1.sinks.k2.type = avro
a1.sinks.k2.channel = c1
a1.sinks.k2.hostname = m2
a1.sinks.k2.port = 5555
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100启动:
#flume-ng agent -c . -f /home/bigdata/flume/conf/Load_balancing_Sink_Processors_avro.conf -n a1 -Dflume.root.logger=INFO,console测试:
输入太快产生的日志可能会落到一台机器上
echo "idoall.org test1" | nc localhost 5140flume的海量日志离线采集于存储。不同的数据源,不同的数据存储方式(本地和hdfs),均衡负载的存储方式,存储时间,存储数据大小等等的设定。
海量日志采集Flume(HA)的更多相关文章
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- 海量日志采集系统flume架构与原理
1.Flume概念 flume是分布式日志收集系统,将各个服务器的数据收集起来并发送到指定地方. Flume是Cloudera提供的一个高可用.高可靠.分布式的海量日志采集.聚合和传输的系统.Flum ...
- flume 日志采集工具
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 日志采集框架Flume
前言 在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集.结果数据导出.任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中 ...
- 日志采集框架 Flume
日志采集框架 Flume 1 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到H ...
- 基于Flume+Kafka+ Elasticsearch+Storm的海量日志实时分析平台(转)
0背景介绍 随着机器个数的增加.各种服务.各种组件的扩容.开发人员的递增,日志的运维问题是日渐尖锐.通常,日志都是存储在服务运行的本地机器上,使用脚本来管理,一般非压缩日志保留最近三天,压缩保留最近1 ...
- Flume日志采集框架的使用
文章作者:foochane 原文链接:https://foochane.cn/article/2019062701.html Flume日志采集框架 安装和部署 Flume运行机制 采集静态文件到h ...
- 01_日志采集框架Flume简介及其运行机制
离线辅助系统概览: 1.概述: 在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集.结果数据导出. 任务调度等不可或缺的辅助系统,而这些辅助 ...
- 【Hadoop离线基础总结】日志采集框架Flume
日志采集框架Flume Flume介绍 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.它可以采集文件,socket数据包.文件.文件夹.kafka等各种形式源数据,又可 ...
随机推荐
- oracle数据库导出与导入
一.查询导出库的字符集 3个 1.查询oracle server端的字符集 SQL>select userenv('language') from dual; USERENV('LANGUAGE ...
- 用stm32f10x建立新的工程重要步骤
stm32f10x系列新建空的工程主要原理: 1.添加启动文件 不同的芯片类型的启动文件的容量是不同的,选择适合该芯片的容量作为启动文件. 注意:启动文件是汇编语言编写的,所以文件的后缀名为.s 2. ...
- day07 Python文件操作
一,文件操作基本流程 #1. 打开文件,得到文件句柄并赋值给一个变量 f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r #2. 通过句柄对文件进行操作 d ...
- Network In Network学习笔记
Network In Network学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50458190 作者:hjimce 一.相关理论 本篇 ...
- Nginx技术研究系列5-动态路由升级版
前几篇文章我们介绍了Nginx的配置.OpenResty安装配置.基于Redis的动态路由以及Nginx的监控. Nginx-OpenResty安装配置 Nginx配置详解 Nginx技术研究系列1- ...
- SpringMvc CharacterEncodingFilter 解析 encoding 参数并初始化参数
SpringMvc CharacterEncodingFilter 解析 encoding 参数并初始化参数:
- 微信小程序上传与下载文件
需要准备的工作: ①.建立微信小程序工程,编写以下代码. ②.通过IDE建立springboot+web工程,编写接收文件以及提供下载文件的方式,并将上传的文件相关信息记录在mysql数据库中.具体请 ...
- 数据库oracle 目录结构
Oracle_Home主目录位于D:\dev\oracle\product\10.2.0(oracle安装路径)下,它包含Oracle软件运行有关的子目录和网络文件以及选定的组件等:若在主机上第一次且 ...
- BIOS备忘录之IIC(touchpad)设备
简述BIOS中对IIC device的支持,以touchpad为例. 信息收集 收集平台的硬件信息: 1. IIC controller number(PCH一般包含多个controller,我们使用 ...
- LSTMs 长短期记忆网络系列
RNN的长期依赖问题 什么是长期依赖? 长期依赖是指当前系统的状态,可能受很长时间之前系统状态的影响,是RNN中无法解决的一个问题. 如果从(1) “ 这块冰糖味道真?”来预测下一个词,是很容易得出“ ...