SQL Server-执行计划教会我如何创建索引
先说点废话
以前有 DBA 在身边的时候,从来不曾考虑过数据库性能的问题,但是,当一个应用程序从头到脚都由自己完成,而且数据库面对的是接近百万的数据,看着一个页面加载速度像乌龟一样,自己心里真是有种挫败感。代码的优化问题,这是属于程序员的职责范围之内,对于我来说,这一方面比较好探查些,因为都是自己熟悉的,用 EF 或 SQL Server Profiler 跟踪一下程序代码产生的 SQL,如果有问题,直接优化程序代码就可以了,如果 SQL 没问题,那就得优化数据库了,对于我来说,这是一个无人区。
前两天,自己瞎搞了一个测试:程序员眼中的 SQL Server-非聚集索引能给我们带来什么?,因为对索引不是很熟悉,所以测试得到结果没有任何价值,甚至有些误导人,这边说声抱歉,在哪跌倒在哪爬起来。
应用场景
还是用商品表(Product)作为示例,表结构如下:
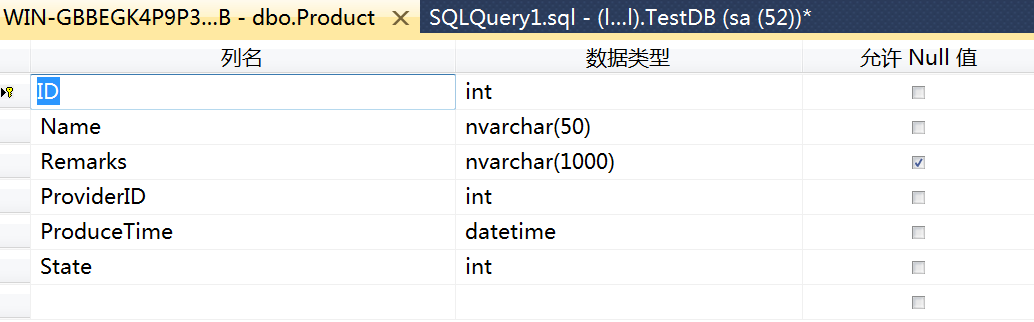
存在这样一种业务场景:获取某个供应商(ProviderID),状态为已售(State 为 1)的商品列表,排序方式为生产日期(ProduceTime)降序,有可能我们应用程序在显示数据的时候用到分页,这边我们查询前 100 行。翻译为 SQL 代码:
SELECT TOP 100
[ID],
[Name],
[Remarks],
[ProviderID],
[ProduceTime],
[State]
FROM [TestDB].[dbo].[Product]
WHERE [ProviderID]=1 AND [State]=1
ORDER BY [ProduceTime] DESC上面这个业务场景,在我们一般的应用程序中基本上都会遇到,有时候数据量不是很大的时候,我们一般不会做任何数据库优化,但是你看了下面的实践,你是否应该考虑下,为你现在的数据库加个索引呢?
SQL Server 执行计划

SQL Server 执行计划,是我们分析 SQL 执行情况的一大利器,通过它,我们也可以很方面的查看索引的执行,在实践之前,需要了解一些必备技能,以下知识点摘自-看懂 SqlServer 查询计划。
SQL Server 有二种索引:聚集索引和非聚集索引。二者的差别在于:【聚集索引】直接决定了记录的存放位置, 或者说:根据聚集索引可以直接获取到记录。【非聚集索引】保存了二个信息:1.相应索引字段的值,2.记录对应聚集索引的位置(如果表没有聚集索引则保存记录指针)。 因此,如果能通过【聚集索引】来查找记录,显然也是最快的。
SQL Server 会有以下方法来查找您需要的数据记录:
- 【Table Scan】:遍历整个表,查找所有匹配的记录行。这个操作将会一行一行的检查,当然,效率也是最差的。
- 【Index Scan】:根据索引,从表中过滤出来一部分记录,再查找所有匹配的记录行,显然比第一种方式的查找范围要小,因此比【Table Scan】要快。
- 【Index Seek】:根据索引,定位(获取)记录的存放位置,然后取得记录,因此,比起前二种方式会更快。
- 【Clustered Index Scan】:和【Table Scan】一样。注意:不要以为这里有个Index,就认为不一样了。 其实它的意思是说:按聚集索引来逐行扫描每一行记录,因为记录就是按聚集索引来顺序存放的。 而【Table Scan】只是说:要扫描的表没有聚集索引而已,因此这二个操作本质上也是一样的。
- 【Clustered Index Seek】:直接根据聚集索引获取记录,最快!
所以,当发现某个查询比较慢时,可以首先检查哪些操作的成本比较高,再看看那些操作在查找记录时, 是不是【Table Scan】或者【Clustered Index Scan】,如果确实和这二种操作类型有关,则要考虑增加索引来解决了。 不过,增加索引后,也会影响数据表的修改动作,因为修改数据表时,要更新相应字段的索引。所以索引过多,也会影响性能。 还有一种情况是不适合增加索引的:某个字段用0或1表示的状态。例如可能有绝大多数是1,那么此时加索引根本就没有意义。 这时只能考虑为0或者1这二种情况分开来保存了,分表或者分区都是不错的选择。
应用分析
我们先不建任何索引(除了主键 ID 的聚集索引),来看一下上面 SQL 代码,在 SQL Server 执行计划中的执行情况:
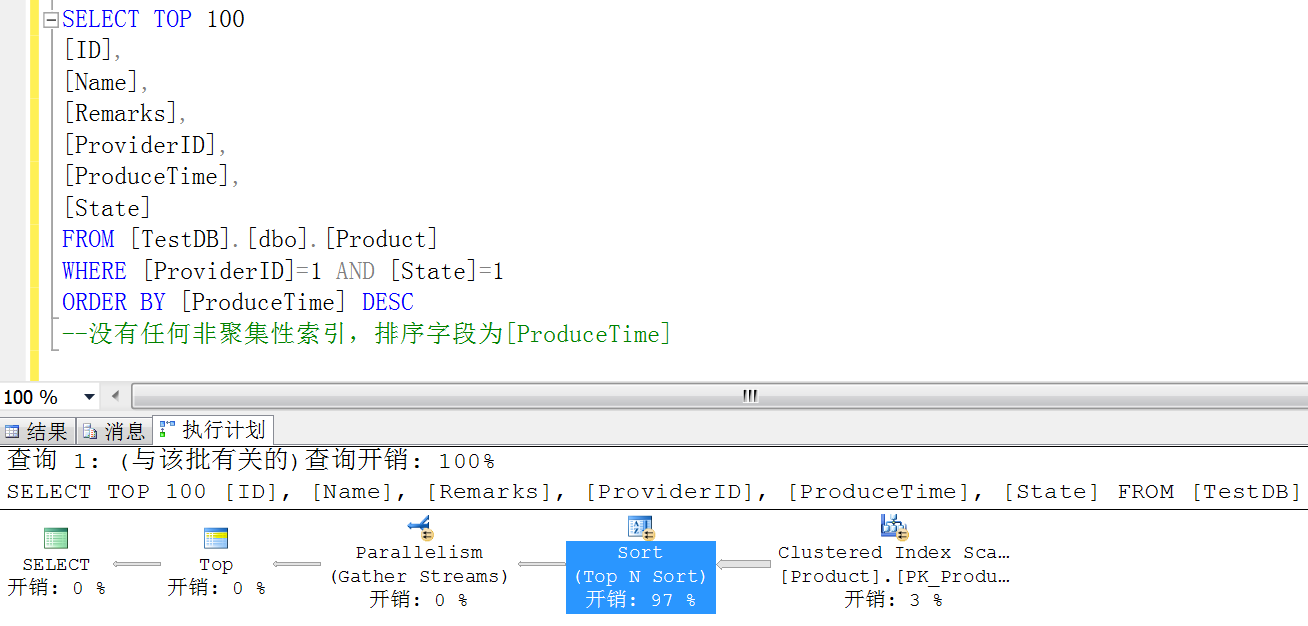
可以看到,查询开销基本上被 SORT 霸占了,看到这种情况,按照正常的思维,我们首先考虑的是为 ProduceTime 创建一个非聚集索引,然后按照 DESC 排序,但有时候我们要沉下心思考一下,是不是用 ID 排序会更好呢?因为在 Product 表中,ID 为自增字段,ProduceTime 在添加的时候获取的是当前时间,在 SQL 排序中,其实 ID 和 ProduceTime 的排序效果是一样的,但是执行性能方面确实天壤之别,我们看一下执行计划就知道了:
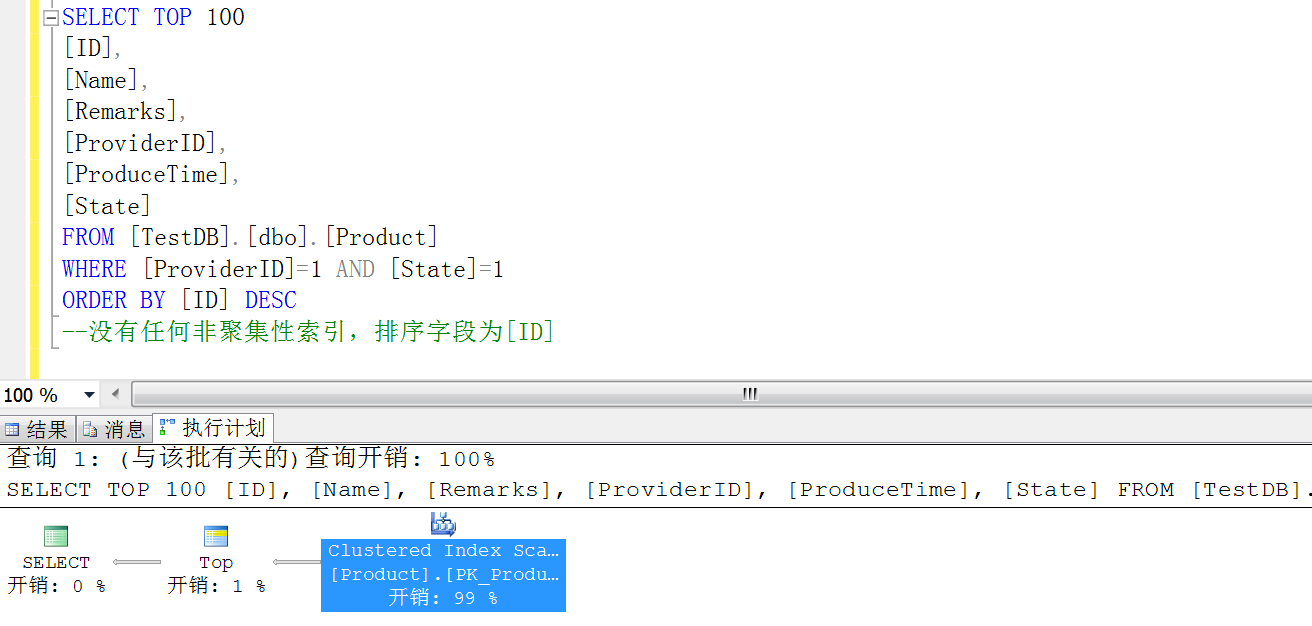
从上面的执行计划中,我们可以很直观的看出差别,所以在写 SQL 的时候,一定要慎重啊,这边为了方便展示,我们还是以 ProduceTime 字段进行排序,按照 ID 排序,虽然没有了 SORT 性能开销,但是发现查询记录为“Clustered Index Scan”,这是全表查询的意思,我们理想的应该是“Index Seek”或者“Clustered Index Seek”,因为这种是按照索引查询,速度最快。按照我们程序员的理解,应该创建一个非聚集索引,比如下面 IX_Product_Provider_State 索引:

创建好之后,我们再来执行一下 SQL 代码:
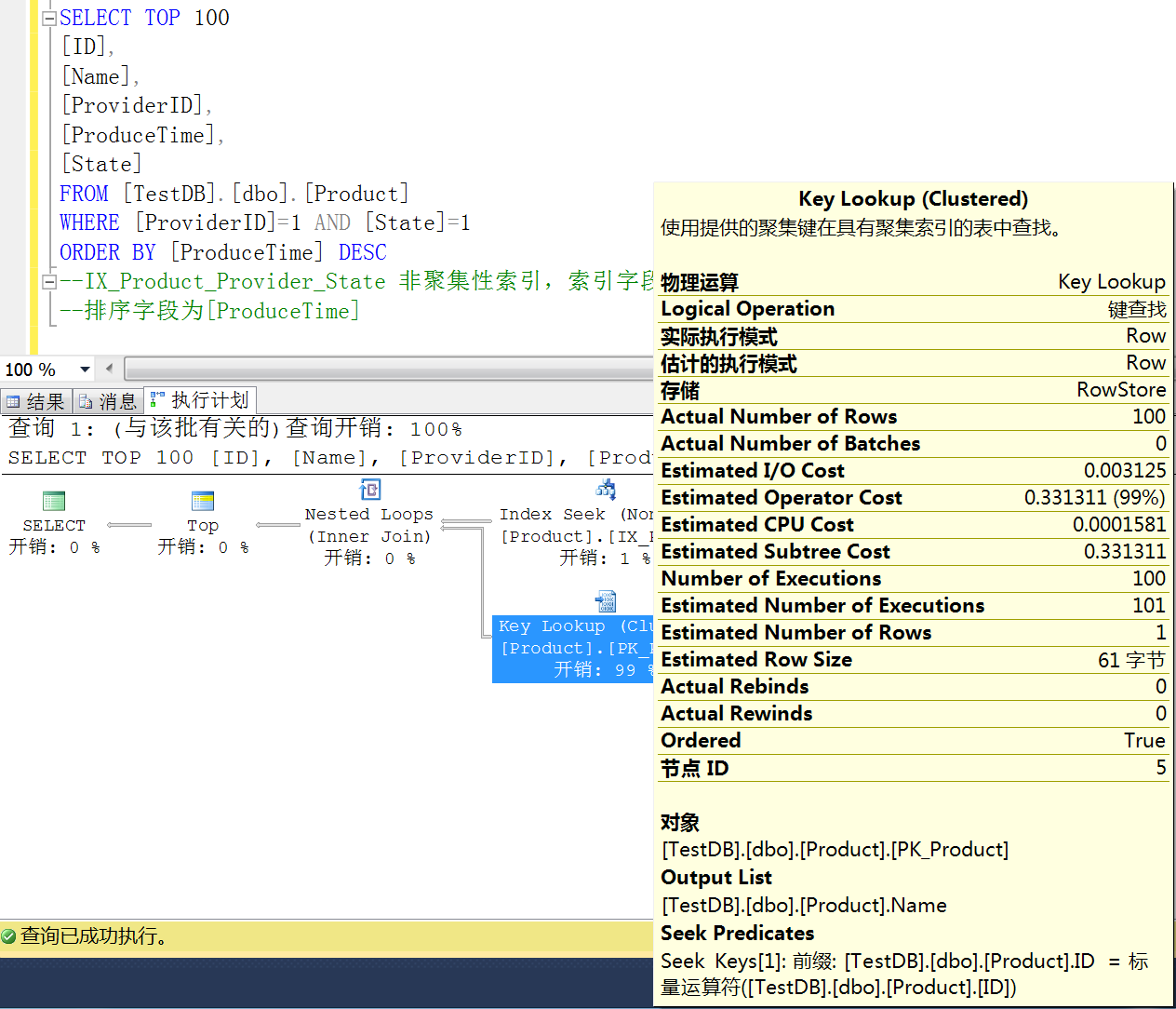
“Key Lookup(Clustered)”记录,其实还是全表进行查找,默认通过聚集索引(PK_Product),我们可能会有疑问,索引就是按照查询及排序方式创建的啊,为什么还是这种情况?这时候我们看一下 SELECT 后面的字段就知道了,我们查询显示的是 Product 表中所有字段,但是 IX_Product_Provider_State 非聚集索引,只是针对的查询条件字段,并没有吧查询显示字段包含进来,在创建索引窗口中,“索引键 列” TAB 的旁边有个“包含性 列”,我们把其他显示字段加进来,看下执行效果:
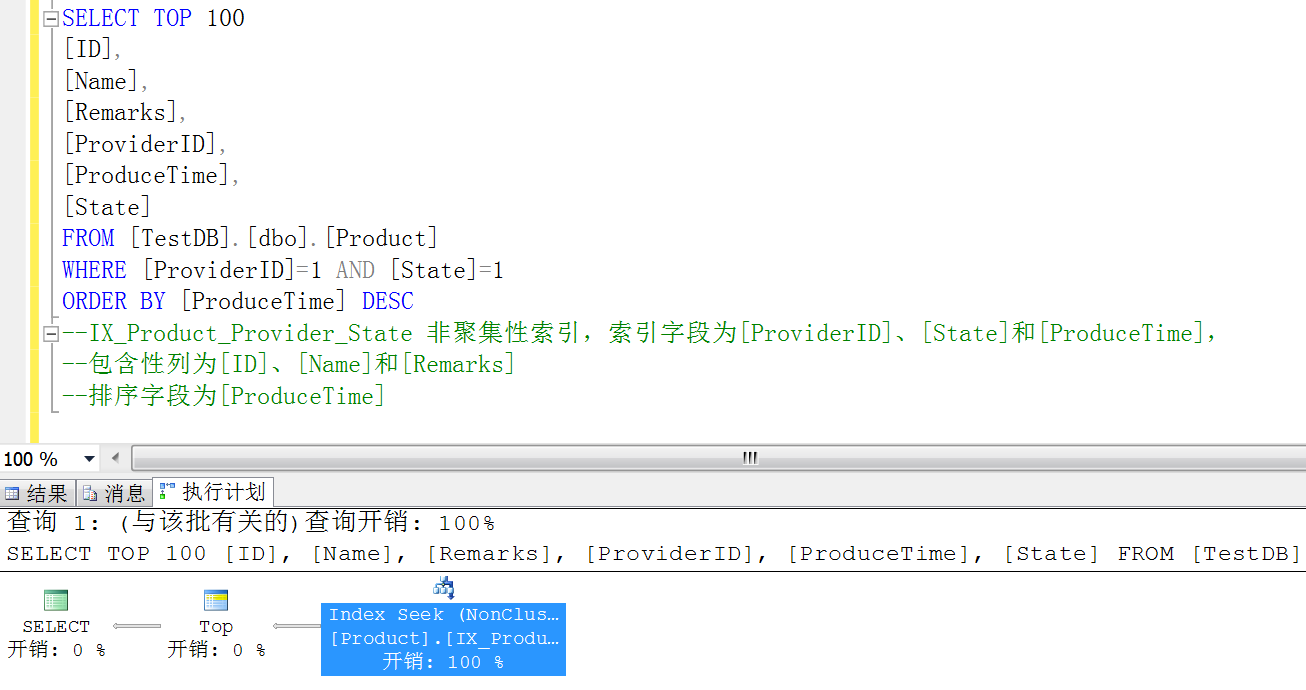
“Index Seek”,这就是我们想要的效果,其实关于索引的创建有很多的现实问题,比如组合字段索引和单个字段索引有何不同?就像上面示例中的查询用例,如果 ProduceTime 排序在其他查询条件中也存在,是不是应该拉出来创建一个索引?还是像上面一样,和查询条件一起创建一个组合字段索引?还有一种情况就是,在一个应用程序查询中,存在单个字段的查询,也存在组合字段的查询,那这时候我们是创建单个字段索引?还是创建组合字段索引呢?这几个问题,你创建一下索引,然后用“ SQL 执行计划”试试就知道了。
总结
针对上面的查询用例,我个人觉得,最好的方案是:排序字段使用 ID,按照实际应用场景,提取出需要查询的字段,避免 SELECT *,这样会减少在添加“包含性 列”的字段,创建 IX_Product_Provider_State 非聚集索引,索引字段为:ProviderID 和 State,如果 State 的值不是多变的(比如值为 1 和 0),尽量不要创建 State 字段的非聚集索引。
做完这些,你会发现,你的应用程序像飞的一样。
摘自:https://www.cnblogs.com/xishuai/p/sql-server-clustered-index-order-by.html
SQL Server-执行计划教会我如何创建索引的更多相关文章
- 程序员眼中的 SQL Server-执行计划教会我如何创建索引?
先说点废话 以前有 DBA 在身边的时候,从来不曾考虑过数据库性能的问题,但是,当一个应用程序从头到脚都由自己完成,而且数据库面对的是接近百万的数据,看着一个页面加载速度像乌龟一样,自己心里真是有种挫 ...
- SQL Server 执行计划缓存
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/内存池/缓冲区 概述 了解执行计划对数据库性能分析很重要,其中涉及到了语句性能分析与存储,这也是写这篇文章的目的,在了解执行计划之 ...
- SQL Server执行计划那些事儿(3)——书签查找
接下来的文章是记录自己曾经的盲点,同时也透漏了自己的发展历程(可能发展也算不上,只能说是瞎混).当然,一些盲点也在工作和探究过程中慢慢有些眉目,现在也愿意发扬博客园的奉献精神,拿出来和大家分享一下. ...
- SQL Server执行计划那些事儿(2)——查找和扫描
接下来的文章是记录自己曾经的盲点,同时也透漏了自己的发展历程(可能发展也算不上,只能说是瞎混).当然,一些盲点也在工作和探究过程中慢慢有些眉目,现在也愿意发扬博客园的奉献精神,拿出来和大家分享一下. ...
- SQL Server 执行计划操作符详解(3)——计算标量(Compute Scalar)
接上文:SQL Server 执行计划操作符详解(2)--串联(Concatenation ) 前言: 前面两篇文章介绍了关于串联(Concatenation)和断言(Assert)操作符,本文介绍第 ...
- SQL Server 执行计划操作符详解(2)——串联(Concatenation )
本文接上文:SQL Server 执行计划操作符详解(1)--断言(Assert) 前言: 根据计划,本文开始讲述另外一个操作符串联(Concatenation),读者可以根据这个词(中英文均可)先幻 ...
- sql server 执行计划(execution plan)介绍
大纲:目的介绍sql server 中执行计划的大致使用,当遇到查询性能瓶颈时,可以发挥用处,而且带有比较详细的学习文档和计划,阅读者可以按照我计划进行,从而达到对执行计划一个比较系统的学习. 什么是 ...
- SQL Server 执行计划中的扫描方式举例说明
SQL Server 执行计划中的扫描方式举例说明 原文地址:http://www.cnblogs.com/zihunqingxin/p/3201155.html 1.执行计划使用方式 选中需要执行的 ...
- 引用:初探Sql Server 执行计划及Sql查询优化
原文:引用:初探Sql Server 执行计划及Sql查询优化 初探Sql Server 执行计划及Sql查询优化 收藏 MSSQL优化之————探索MSSQL执行计划 作者:no_mIss 最近总想 ...
随机推荐
- 【Tools】-NO.89.Tools.4.Visual Studio 2017.1.001-【Visual Studio 2017 安装与卸载】-
1.0.0 Summary Tittle:[Tools]-NO.89.Tools.4.Visual Studio 2017.1.001-[Visual Studio 2017 安装与卸载]- Styl ...
- Git环境配置
1,下载Git-2.16.2-64-bit.exe并安装, 全部为默认设置 下载地址:http://git-scm.com/download/win 2 在开始菜单中,单击Git CMD,执行下面命令 ...
- 墨刀联合有赞Vant组件库,让你轻松设计出电商原型
继上周新上线了简历模板之后,本周墨刀的原型模板库又欢喜地增添一名新成员! 有赞Vant组件库 (做电商的宝宝要捂嘴笑了) Vant 组件库是有赞前端团队开源的一套基于Vue的UI组件库,目前版本收 ...
- Python subprocess.Popen() error (No such file or directory)
这个错误很容易引起误解,一般人都会认为是命令执行了,但是命令找不到作为参数对应的文件或者目录.其实还有一层含义,就是这个命令找不到,命令找不到,也会报没有这个文件或者目录的错误. 为什么找不到这个命令 ...
- django-ajax post与get请求
客户端 访问 服务器 方式: 地址栏 get a标签 get form表单 get/post ajax ...
- MySql使用存储过程清除数据库所有表数据,保存数据结构
BEGIN DECLARE strClear VARCHAR(256); DECLARE done INT DEFAULT 0; #定义游标 DECLARE curOne CURSOR FOR sel ...
- [macOS] Error: /usr/local must be writable!" (Sierra 10.12 )
Error: /usr/local must be writable!" (Sierra 10.12 ) solution: sudo chown -R $(whoami) /usr/loc ...
- Openstack-Namespaces
介绍OpenStack neutron使用Linux网络命名空间来避免物理网络和虚拟网络间的冲突,或者不同虚拟网络间的冲突. 网络命名空间就是一个独立的网络协议栈,它有自己的网络接口,路由,以及防火墙 ...
- Oracle表空间碎片整理SHRINK与MOVE
整理表碎片通常的方法是move表,当然move是不能在线进行的,而且move后相应的索引也会失效,oracle针对上述不足,在10g时加入了shrink,那这个方法能不能在生产中使用呢? ...
- 51Nod 1085 背包问题 (01背包)
在N件物品取出若干件放在容量为W的背包里,每件物品的体积为W1,W2……Wn(Wi为整数),与之相对应的价值为P1,P2……Pn(Pi为整数).求背包能够容纳的最大价值. 收起 输入 第1行,2个 ...