OSLab多线程
日期:2019/3/26
内容:多线程。
一、基本知识
- 线程的定义
线程(thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
一个进程至少有一个线程(记为主线程),多开线程称为工作线程。
- 并发特性
当前的进程可以理解为一个主线程,新建的进程称为工作线程。主线程与工作线程交织并发执行。(见2.1的代码实例)
- 线程互斥
多个线程之间有共享资源(shared resource)时会出现互斥现象。
例如设有若干线程共享某个变量,而且都对变量有修改。如果它们之间不考虑相互协调工作,就会产生混乱。比如,线程A和B共用变量x,都对x执行增1操作。由于A和B没有协调,两线程对x的读取、修改和写入操作相互交叉,可能两个线程读取相同个x值,一个线程将修改后的x新值写入到x后,另一个线程也把自己对x修改后的新值写入到x。这样,x只记录后一个线程的修改作用。
- 使用线程时,需要链接pthread库
|
gcc f.c -o f -lpthread |
二、线程的系统调用
2.1 创建线程(pthread_create)
- 原型:int pthread_create(pthread_t *tid, pthread_attr_t *attr, void *(*start_routine)(void *), void *arg);
- 功能:
>>创建一个线程
>>新线程从start_routine开始执行
>>新线程的ID保存在tid指向的位置
- 返回值:成功0,失败非0。(实际是返回-1,但是习惯上使用!=0判断更好)
- 参数解析
|
参数 |
功能 |
|
tid |
该参数是一个指针, 新线程的ID保存在tid指向的位置 pthread_t等同于unsigned long int (8 bytes) |
|
attr |
线程属性。如果为空,则使用缺省的属性值 |
|
start_routine |
该参数是一个函数指针, 新线程从start_routine开始执行 |
|
arg |
提供给start_routine的参数 |
- attr解析(需要用时补充)
- arg解析
>>对于整型变量
|
int ivalue = 123; void *arg = (void *) ivalue; |
>>字符串(如下代码实例)
>>结构体
|
struct person { char *name; int age; } p; void *arg = (void *) &p; |
- 并发代码实例
|
void *thread_run(void *args) { int i = 5; const while(i--) { printf("%s running...\n", str); sleep(1); } return }
int main() { pthread_t ptid; pthread_create(&ptid, NULL, &thread_run, "subthread");
int i = 5; while(i--) { puts("main thread running..."); sleep(1); } return }
|

2.2 等待线程(pthread_join)
- 原型:int pthread_join(pthread_t tid, void **result);
- 功能:等待线程结束
- 参数:
>>tid: 目标线程的id
>>result: 用于存放线程的计算结果
- 返回值:成功0,失败非0。
- 代码实例1(线程并行计算,全局变量记录结果)
|
#include <stdio.h> #include <pthread.h>
int array[] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; int master_res = 0; int worker_res = 0;
void master_run() { int i=0; for(i=0; i<=4; i++) master_res += array[i]; } void *worker_run(void *args) { int i; for(i=5; i<=9; i++) worker_res += array[i]; }
int main() { pthread_t tid; pthread_create(&tid, NULL, &worker_run, NULL); master_run(); pthread_join(tid, NULL); printf("master = %d, worker = %d, total = %d...\n", master_res, worker_res, master_res + worker_res); return
}
|

- 代码实例2(线程并行计算,局部变量记录结果)
|
#include <stdio.h> #include <string.h> #include <pthread.h> #define NR_TOTAL 100 #define NR_CPU 4 #define NR_CHILD (NR_TOTAL / NR_CPU) typedef { int *array; int start, end; } param; typedef { int sum; } result;
int array[NR_TOTAL] = {0};
void *worker_run(void *args) { param *p = (param *)(args); result *res = (result *)malloc(sizeof(result)); int i; int sum = 0; for (i = p->start; i <= p->end; i++) { sum += p->array[i]; } res->sum = sum; return (void *)res; }
int main() { int i; int sum = 0; pthread_t tid[NR_CPU] = {0}; param params[NR_CPU];
for (i = 0; i < NR_TOTAL; i++) array[i] = i + 1;
for (i = 0; i < NR_CPU; i++) { param *p = ¶ms[i]; p->array = array; p->start = i * NR_CHILD; p->end = p->start + NR_CHILD - 1; pthread_create(&tid[i], NULL, &worker_run, (void *)p); }
for (i = 0; i < NR_CPU; i++) { result *res = NULL; pthread_join(tid[i], (void **)(&res)); sum += res->sum; free(res); }
printf("sum = %d\n", sum); }
|

- 代码实例3(多线程求和与单线程求和对比,1亿个数据求和)
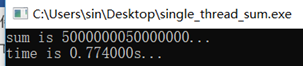
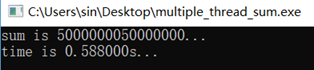
运行结果和代码如下。可见单线程与多线程做一亿次加法的时间差不多。自己想了一下原因:代码在阿里云的机器上跑的,买的学生版,CPU是单核的,这种情况下NR_CPU个线程只能轮流使用CPU,本质上就是单线程。而且还多出来线程切换的开销,更不划算。
后来把代码拉到本地运行,本地CPU配置4核4线程,单线程结果稳定在0.77s,多线程结果稳定在0.57-0.58s,说明多线程计算确实是比单线程要快的。
|
单线程 #define SIZE (100000000) static uint32_t array[SIZE] = {0}; static uint64_t sum = 0; clock_t start, end; int main() { start = clock(); uint32_t i = 0; for (i = 0; i < SIZE; i++) array[i] = i + 1; for (i = 0; i < SIZE; i++) sum += array[i]; end = clock(); printf("sum is %lld...\n", sum); printf("time is %lfs...\n", ((double)end - start) / CLOCKS_PER_SEC); } 输出(sum的值无意义,因为溢出,用于检验2次求和结果是否一致)
本地机器
|



|
多线程 #include <stdio.h> #include <stdlib.h> #include <pthread.h> #include <time.h> #include <stdint.h> #include <string.h> #define SIZE (100000000) #define NR_TOTAL SIZE #define NR_CPU (32) #define NR_CHILD (NR_TOTAL / NR_CPU) typedef { uint32_t *array; uint32_t start, end; } param; typedef { uint64_t sum; } result; uint32_t array[SIZE] = { 0 }; uint64_t sum = 0; clock_t start, end; param params[NR_CPU]; result res[NR_CPU]; pthread_t tid[NR_CPU];
void *worker_run(void *args) { uint32_t i = 0; uint64_t sum = 0; param *p = (param *)args; result *r = (result *)malloc(sizeof(result)); for(i = p->start; i <= p->end; i++) { sum += p->array[i]; } r->sum = sum; return (void *)r; }
int main() { uint32_t i = 0; start = clock(); for (i = 0; i < SIZE; i++) array[i] = i + 1; for (i = 0; i < NR_CPU; i++) { param *p = ¶ms[i]; p->array = array; p->start = i * NR_CHILD; p->end = p->start + NR_CHILD - 1; pthread_create(&tid[i], NULL, &worker_run, (void *)p); }
for (i = 0; i < NR_CPU; i++) { result *r; pthread_join(tid[i], (void **)&r); sum += r->sum; free(r); } end = clock(); printf("sum is %lld...\n", sum); printf("time is %lfs...\n", ((double)end - start)/CLOCKS_PER_SEC); }
输出
本地机器
|



2.3 线程互斥(pthread_mutex)
- 原型
>> int pthread_mutex_init(pthread_mutex_t *mutex, pthread_mutexattr_t *attr);
>> int pthread_mutex_destroy(pthread_mutex_t *mutex);
>> int pthread_mutex_lock(pthread_mutex_t *mutex);
>> int pthread_mutex_unlock(pthread_mutex_t *mutex);
- 功能
>> pthread_mutex_init初始化互斥量
>> pthread_mutex_destroy释放互斥量
>> pthread_mutex_lock将互斥量加锁
>> pthread_mutex_unlock将互斥量解锁
- 补充说明
当pthread_mutex_lock()返回时,该互斥锁已被锁定。线程调用该函数让互斥锁上锁,如果该互斥锁已被另一个线程锁定和拥有,则调用的线程将阻塞,直到该互斥锁变为可用为止。
- 返回值:成功0,失败非0(上述4个函数均如此)
- 参数
>>pthread_mutex_t是一个结构体。(具体形式比较复杂,需要时再补充)
>>如果attr等于NULL,则使用缺省的属性进行初始化
- 使用说明
|
开启线程时 |
线程入口函数 |
|
|
- 实例代码(一点存留疑问:这样代码效率跟单线程相比有提高?)
|
static pthread_mutex_t mutex; void *worker_run(void *args) { int i = 0; for(i = 0; i < 1000000; i++) { pthread_mutex_lock(&mutex); global++; pthread_mutex_unlock(&mutex); } return } int main() { pthread_t tid[3] = { 0 }; pthread_mutex_init(&mutex, NULL); int i = 0; for(i = 0; i < 3; i++) pthread_create(&tid[i], NULL, &worker_run, NULL); for(i = 0; i < 3; i++) pthread_join(tid[i], NULL); pthread_mutex_destroy(&mutex); printf("global = %d \n", global); return }
|

2.4 条件变量(pthread_cond)
- 初始化与销毁
- 原型
>> int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *attr);
>> int pthread_cond_destroy(pthread_cond_t *cond);
- 功能
>> pthread_cond_init初始化条件变量
>> pthread_cond_destroy释放条件变量
- 参数
>>如果attr等于NULL,则使用缺省的属性进行初始化
>> pthread_condattr_t是一个结构体,见文献1的blog
>> pthread_cond_t是一个union,见文献1的blog
- 等待
- 原型:int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
- 功能:阻塞当前线程的运行
- 参数:cond表示当前线程阻塞直到满足cond条件;mutex表示当前线程阻塞时所在的临界区。
- 返回值:成功0,失败非0。
- 原型:int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
- 唤醒
- 原型
>>int pthread_cond_signal(pthread_cond_t *cond);
>>int pthread_cond_broadcast(pthread_cond_t *cond);
- 功能
>>pthread_cond_signal唤醒阻塞在条件变量上的一个线程
>>pthread_cond_broadcast唤醒阻塞在条件变量上的所有线程
- 返回值:成功0,失败非0.
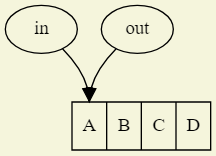
- 共享缓冲区
|
初始状态 |
加入数据 |
缓冲区满 |
非法状态(缓冲区溢出) |
|
|
|
|
|



- 代码实例1——生产者与消费者(条件变量完成同步)
|
#define BUFFER_SIZE (4) #define BUFFER_CAPACITY (BUFFER_SIZE - #define PRODUCE_SIZE (BUFFER_SIZE * #define CONSUME_SIZE (BUFFER_SIZE * typedef char buffer[BUFFER_SIZE] = ""; int in = 0; int out = 0; pthread_mutex_t mutex; pthread_cond_t wait_until_full; pthread_cond_t wait_until_empty;
void print_buffer_state() { int i = 0; for(i = 0; i < BUFFER_SIZE; i++) if(buffer[i] != '\0') printf("%c ", buffer[i]); printf("\n"); } bool buffer_is_empty() { return in == out; } bool buffer_is_full() { return (in + 1) % BUFFER_SIZE == out; } void put_item(char item) { buffer[in] = item; in = (in + 1) % BUFFER_SIZE; } char get_item() { char item = buffer[out]; buffer[out] = '\0'; out = (out + 1) % BUFFER_SIZE; return item; }
void *consume_run(void *args) { int i = 0; for(i = 0; i < CONSUME_SIZE; i++) { pthread_mutex_lock(&mutex); while (buffer_is_empty()) pthread_cond_wait(&wait_until_full, &mutex); printf("\t consume item = %c\n", get_item()); //print_buffer_state(); pthread_cond_signal(&wait_until_empty); //wake up producer pthread_mutex_unlock(&mutex); } return }
void produce_run() { int i = 0; for(i = 0; i < PRODUCE_SIZE; i++) { pthread_mutex_lock(&mutex); while (buffer_is_full()) pthread_cond_wait(&wait_until_empty, &mutex); char item = 'a' + i; printf("produce item = %c\n", item); put_item(item); //print_buffer_state(); pthread_cond_signal(&wait_until_full); //wake up consume pthread_mutex_unlock(&mutex); } }
int main() { pthread_mutex_init(&mutex, NULL); pthread_cond_init(&wait_until_full, NULL); pthread_cond_init(&wait_until_empty, NULL);
pthread_t consume_tid = 0; pthread_create(&consume_tid, NULL, &consume_run, NULL); produce_run(); pthread_join(consume_tid, NULL); return }
|
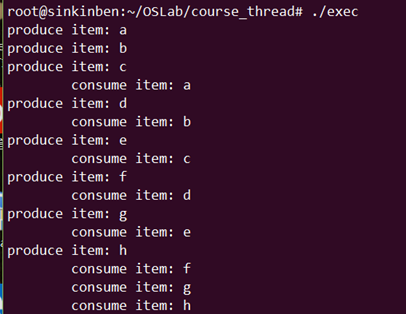
运行结果
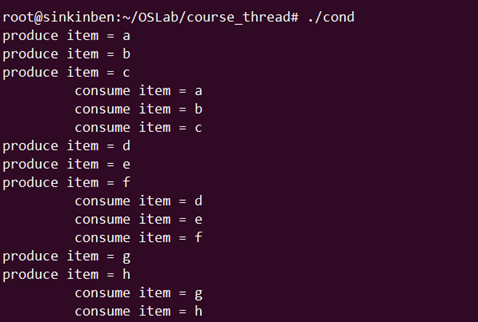

结果分析:
实际上,produce不必等到buffer为空才执行,consume也不必等到buffer为满才执行,produce和consume是并发执行的,所以才会有第二次的运行结果。
- 代码实例2——生产者与消费者(信号量完成同步)
|
#include <stdio.h> #include <pthread.h> #define BUFF_SIZE 4 #define ITEM_COUNT (BUFF_SIZE * typedef unsigned typedef struct { int value; pthread_mutex_t mutex; pthread_cond_t cond; } sema_t; char buffer[BUFF_SIZE]; int pin = 0; int pout = 0; sema_t mutex_sema;//threads mutex to access buffer sema_t buffer_notfull_sema;// thread sync sema_t buffer_notempty_sema; bool is_empty() { return pin == pout; } bool is_full() { return ((pin + 1) % BUFF_SIZE) == pout; } char get_item() { char item; item = buffer[pout]; pout = (pout + 1) % BUFF_SIZE; return item; } void put_item(char item) { buffer[pin] = item; pin = (pin + 1) % BUFF_SIZE; } void sema_init(sema_t *sema, int value) { sema->value = value; pthread_mutex_init(&sema->mutex, NULL); pthread_cond_init(&sema->cond, NULL); } //wait //if value<=0 then wait until meet the cond //else value-- void sema_wait(sema_t *sema) { pthread_mutex_lock(&sema->mutex); while (sema->value <= 0) pthread_cond_wait(&sema->cond, &sema->mutex); sema->value--; pthread_mutex_unlock(&sema->mutex); } void sema_signal(sema_t *sema) { pthread_mutex_lock(&sema->mutex); sema->value++; pthread_cond_signal(&sema->cond);//wake up another thread pthread_mutex_unlock(&sema->mutex); } void *consume_run(void *arg) { int i; char item; for(i = 0; i < ITEM_COUNT; i++) { sema_wait(&buffer_notempty_sema); sema_wait(&mutex_sema); printf("\tconsume item: %c\n", get_item()); sema_signal(&mutex_sema); sema_signal(&buffer_notfull_sema); } return } void *produce_run() { int i; char item; for (i = 0; i < ITEM_COUNT; i++) { sema_wait(&buffer_notfull_sema); sema_wait(&mutex_sema); item = i + 'a'; put_item(item); printf("produce item: %c\n", item); sema_signal(&mutex_sema); sema_signal(&buffer_notempty_sema); } return }
int main() { pthread_t consume_tid; sema_init(&mutex_sema, 1); sema_init(&buffer_notfull_sema, BUFF_SIZE - 1); sema_init(&buffer_notempty_sema, 0); pthread_create(&consume_tid, NULL, consume_run, NULL); produce_run(); pthread_join(consume_tid, NULL); return }
|
运行结果

三、名词解析
- pthread:p的含义是POSIX
- POSIX:Portable Operating System Interface of Unix,可移植操作系统接口。
- mutex:意为互斥体。
参考文献
OSLab多线程的更多相关文章
- Python中的多进程与多线程(一)
一.背景 最近在Azkaban的测试工作中,需要在测试环境下模拟线上的调度场景进行稳定性测试.故而重操python旧业,通过python编写脚本来构造类似线上的调度场景.在脚本编写过程中,碰到这样一个 ...
- 多线程爬坑之路-Thread和Runable源码解析之基本方法的运用实例
前面的文章:多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类) 多线程爬坑之路-Thread和Runable源码解析 前面 ...
- 多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类)
前言:刚学习了一段机器学习,最近需要重构一个java项目,又赶过来看java.大多是线程代码,没办法,那时候总觉得多线程是个很难的部分很少用到,所以一直没下决定去啃,那些年留下的坑,总是得自己跳进去填 ...
- Java多线程
一:进程与线程 概述:几乎任何的操作系统都支持运行多个任务,通常一个任务就是一个程序,而一个程序就是一个进程.当一个进程运行时,内部可能包括多个顺序执行流,每个顺序执行流就是一个线程. 进程:进程 ...
- .NET基础拾遗(5)多线程开发基础
Index : (1)类型语法.内存管理和垃圾回收基础 (2)面向对象的实现和异常的处理基础 (3)字符串.集合与流 (4)委托.事件.反射与特性 (5)多线程开发基础 (6)ADO.NET与数据库开 ...
- Java多线程基础——对象及变量并发访问
在开发多线程程序时,如果每个多线程处理的事情都不一样,每个线程都互不相关,这样开发的过程就非常轻松.但是很多时候,多线程程序是需要同时访问同一个对象,或者变量的.这样,一个对象同时被多个线程访问,会出 ...
- C#多线程之线程池篇3
在上一篇C#多线程之线程池篇2中,我们主要学习了线程池和并行度以及如何实现取消选项的相关知识.在这一篇中,我们主要学习如何使用等待句柄和超时.使用计时器和使用BackgroundWorker组件的相关 ...
- C#多线程之线程池篇2
在上一篇C#多线程之线程池篇1中,我们主要学习了如何在线程池中调用委托以及如何在线程池中执行异步操作,在这篇中,我们将学习线程池和并行度.实现取消选项的相关知识. 三.线程池和并行度 在这一小节中,我 ...
- C#多线程之线程池篇1
在C#多线程之线程池篇中,我们将学习多线程访问共享资源的一些通用的技术,我们将学习到以下知识点: 在线程池中调用委托 在线程池中执行异步操作 线程池和并行度 实现取消选项 使用等待句柄和超时 使用计时 ...
随机推荐
- JEECG-Swagger UI的使用说明
一.代码生成 (此步骤为代码生成器的使用,如不清楚请查阅相关文档视频) 1.进入菜单[在线开发]-->[Online表单开发],选中一张单表/主表,点击代码生成按钮. 2.弹出页面中填写代码生成 ...
- ABAP-IDOC配置
转载路径: http://www.cnblogs.com/jiangzhengjun/p/4292135.html#_Toc411677431 https://wenku.baidu.com/view ...
- [C语言]进阶|指针与字符串
------------------------------------------------------------------------------------ 回顾:[C语言]指针与字符串 ...
- Unity网格合并_材质合并
[转]Unity网格合并_材质合并 原帖请戳:Unity网格合并_材质合并 写在前面: 从优化角度,Mesh需要合并. 从换装的角度(这里指的是换形状.换组成部件的换装,而不是挂点型的换装),都需要网 ...
- js 菜单收起和展开
- 坑之mysql 字符串与数字操作
select "123"+1 = 124; select "1a23"+1 = 2; select "aa23"+1 = 1; select ...
- MongoDB入门(一)
文档 文档是MongoDB中的基本数据结构,型如:{"name":"Jack","lastname":"xi"} 键值对 ...
- WebApi上传文件
上网搜了下Web Api上传文件的功能,发现都写的好麻烦,就自己写了一个,比较简单,直接上传文件就可以,可以用Postman测试. 简单的举例 /// <summary> /// 超级简单 ...
- scrollIntoView()窗口滚动
1.某DIV窗口滚动到顶部: document.getElementById("某DIV的ID").scrollIntoView(true); 2.某DIV窗口滚动到底部: doc ...
- 学习Hibernate的体会
这个学期老师让我们做一个系统(服务器和客户端),语言自选,我也随大家开始学习java web 和android . 下面是我自学的一些体会和遇到的问题. 关于jar包. jsds.jar javasi ...