时间序列预测——Tensorflow.Keras.LSTM
1、测试数据下载
https://datamarket.com/data/set/22w6/portland-oregon-average-monthly-bus-ridership-100-january-1973-through-june-1982-n114#!ds=22w6&display=line
2、LSTM预测
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import datetime
from dateutil.relativedelta import relativedelta df = pd.read_csv("C:\\Users\\\Administrator\\Downloads\\portland-oregon-average-monthly-.csv",
index_col=0) df.index.name=None #将index的name取消
df.reset_index(inplace=True)
df.drop(df.index[114], inplace=True)
start = datetime.datetime.strptime("1973-01-01", "%Y-%m-%d") #把一个时间字符串解析为时间元组
date_list = [start + relativedelta(months=x) for x in range(0,114)] #从1973-01-01开始逐月增加组成list
df['index'] =date_list
df.set_index(['index'], inplace=True)
df.index.name=None
df.columns= ['riders']
df['riders'] = df.riders.apply(lambda x: int(x)*100)
df.riders.plot(figsize=(12,8), title= 'Monthly Ridership', fontsize=14)
plt.show() data = df.iloc[:,0].tolist() def data_processing(raw_data, scale=True):
if scale == True:
return (raw_data-np.mean(raw_data))/np.std(raw_data)#标准化
else:
return (raw_data-np.min(raw_data))/(np.max(raw_data)-np.min(raw_data))#极差规格化
TIMESTEPS = 12 '''样本数据生成函数'''
def generate_data(seq):
X = []#初始化输入序列X
Y= []#初始化输出序列Y
'''生成连贯的时间序列类型样本集,每一个X内的一行对应指定步长的输入序列,Y内的每一行对应比X滞后一期的目标数值'''
for i in range(len(seq) - TIMESTEPS - 1):
X.append([seq[i:i + TIMESTEPS]])#从输入序列第一期出发,等步长连续不间断采样
Y.append([seq[i + TIMESTEPS]])#对应每个X序列的滞后一期序列值
return np.array(X, dtype=np.float32), np.array(Y, dtype=np.float32) '''对原数据进行尺度缩放'''
data = data_processing(data) '''将所有样本来作为训练样本'''
train_X, train_y = generate_data(data) '''将所有样本作为测试样本'''
test_X, test_y = generate_data(data) from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM model = Sequential()
model.add(LSTM(16, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dense(train_y.shape[1]))
model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
model.fit(train_X, train_y, epochs=1000, batch_size=len(train_X), verbose=2, shuffle=False) #scores = model.evaluate(train_X, train_y, verbose=0)
#print("Model Accuracy: %.2f%%" % (scores[1] * 100)) result = model.predict(train_X, verbose=0) '''自定义反标准化函数'''
def scale_inv(raw_data,scale=True):
data1 = df.iloc[:, 0].tolist()
if scale == True:
return raw_data*np.std(data1)+np.mean(data1)
else:
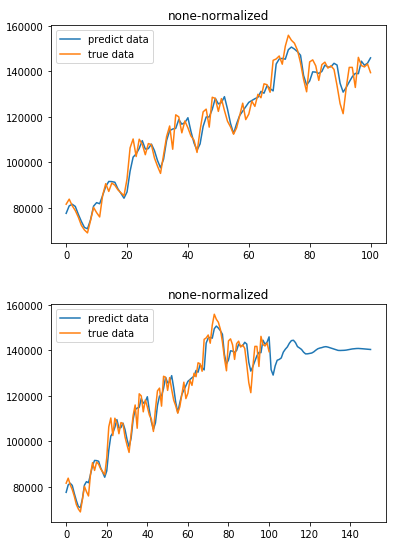
return raw_data*(np.max(data1)-np.min(data1))+np.min(data1) '''绘制反标准化之前的真实值与预测值对比图'''
plt.figure()
plt.plot(scale_inv(result), label='predict data')
plt.plot(scale_inv(test_y), label='true data')
plt.title('none-normalized')
plt.legend()
plt.show() def generate_predata(seq):
X = []#初始化输入序列X
X.append(seq)
return np.array(X, dtype=np.float32) datalist = data.tolist()
pre_result = []
for i in range(50):
pre_x = generate_predata(datalist[len(datalist) - TIMESTEPS:])
#pre_x = pre_x[np.newaxis,:,:]
pre_x = np.reshape(pre_x, (1, 1, TIMESTEPS))
pre_y = model.predict(pre_x)
pre_result.append(pre_y.tolist()[0])
datalist.append(pre_y.tolist()[0][0])
all = result.tolist()
all.extend(pre_result)
'''绘制反标准化之前的真实值与预测值对比图'''
plt.figure()
plt.plot(scale_inv(np.array(all)), label='predict data')
plt.plot(scale_inv(test_y), label='true data')
plt.title('none-normalized')
plt.legend()
plt.show()
3、运行效果

时间序列预测——Tensorflow.Keras.LSTM的更多相关文章
- Kesci: Keras 实现 LSTM——时间序列预测
博主之前参与的一个科研项目是用 LSTM 结合 Attention 机制依据作物生长期内气象环境因素预测作物产量.本篇博客将介绍如何用 keras 深度学习的框架搭建 LSTM 模型对时间序列做预测. ...
- 使用tensorflow的lstm网络进行时间序列预测
https://blog.csdn.net/flying_sfeng/article/details/78852816 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog. ...
- 基于 Keras 用 LSTM 网络做时间序列预测
目录 基于 Keras 用 LSTM 网络做时间序列预测 问题描述 长短记忆网络 LSTM 网络回归 LSTM 网络回归结合窗口法 基于时间步的 LSTM 网络回归 在批量训练之间保持 LSTM 的记 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- Python中利用LSTM模型进行时间序列预测分析
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺 ...
- TensorFlow实现时间序列预测
常常会碰到各种各样时间序列预测问题,如商场人流量的预测.商品价格的预测.股价的预测,等等.TensorFlow新引入了一个TensorFlow Time Series库(以下简称为TFTS),它可以帮 ...
- Pytorch循环神经网络LSTM时间序列预测风速
#时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大 ...
- facebook开源的prophet时间序列预测工具---识别多种周期性、趋势性(线性,logistic)、节假日效应,以及部分异常值
简单使用 代码如下 这是官网的quickstart的内容,csv文件也可以下到,这个入门以后后面调试加入其它参数就很简单了. import pandas as pd import numpy as n ...
- tensorflow keras导包混用
tensoboard 导入:导入包注意 否者会报错 :keras FailedPreconditionError: Attempting to use uninitialized value trai ...
随机推荐
- CentOS 7下安装samba
Samba是一种软件,它可以运行在非Windows平台上,比如UNIX, Linux, IBM System 390, OpenVMS或其他操作系统.Samba使用安装在主机上的TCP/IP协议.当正 ...
- 判断当前的Activity的是否处于栈顶
lockAppName 是需要判断Activity的全称(包括包名). private boolean getTopApp(Context mContext) { String lockAppName ...
- array_walk与array_map的区别
1.array_walk是用于用户自定义的函数,所以想用array_walk($aIds, "trim");去掉数据元素中的空格是达不到目的的只能用array_walk($aIds ...
- 神经网络和误差逆传播算法(BP)
本人弱学校的CS 渣硕一枚,在找工作的时候,发现好多公司都对深度学习有要求,尤其是CNN和RNN,好吧,啥也不说了,拿过来好好看看.以前看习西瓜书的时候神经网络这块就是一个看的很模糊的块,包括台大的视 ...
- 在iPhone手机上写了input type="date" 显示不出来的原因
在iPhone手机上写了input type="date" 显示不出来的原因 今天在手机页面上使用新的input类型,这样子写,在chrome浏览器上浏览,很好,显示出来.然后用i ...
- 线程的条件Condiition
条件Condition相当于给锁造钥匙,但是这钥匙是一次性的.一个线程拿到钥匙进去,出来之后钥匙没有归还,而是没了. 如下代码: from threading import Thread, Condi ...
- R 540
好久没写题解了嘻嘻嘻,昨天补edu自闭了一天还没补完fg这div3令人愉悦. A: #include <bits/stdc++.h> #define mk(a,b) make_pair(a ...
- css hsla和rgba的区别
在CSS3里可以使用RGBA和HSLA两种色彩模式,都可以用来在设置颜色的同时也可以设置它的透明度.RGBA指的是“红色.绿色.蓝色和Alpha透明度”(Red-Green-Blue-Alpha),而 ...
- PHP(控制语句,随机数,循环语法)
1.随机数:Math.random():0到1 不包括1 永远取不到2.控制语句if(){} for循环 语法 运行步骤(过程,原理) 1.初始化 2.判断条件 3.变量改变 index:下 ...
- Python学习之旅(八)
Python基础知识(7):数据基本类型之元组.字典 一.元组 用括号把元素括起来中间用逗号隔开.用逗号分开一些值便可创建元组 1,2,3 结果: (1, 2, 3) 空元组可以用没有包含任何内容的两 ...