[MapReduce_add_2] MapReduce 实现年度最高气温统计
0. 说明
编写 MapReduce 程序实现年度最高气温统计
1. 气温数据分析
气温数据样例如下:
++023450FM-+000599999V0202701N015919999999N0000001N9-+99999102001ADDGF108991999999999999999999
++023450FM-+000599999V0202901N008219999999N0000001N9-+99999102001ADDGF104991999999999999999999
++023450FM-+000599999V0209991C000019999999N0000001N9-+99999102001ADDGF108991999999999999999999
++023450FM-+000599999V0201801N008219999999N0000001N9-+99999101831ADDGF108991999999999999999999
++023450FM-+000599999V0201801N009819999999N0000001N9-+99999101761ADDGF108991999999999999999999
对气温数据进行分析可以得出以下的结论
1. 年份的索引为 15-19 ,以此作为 Key
2. 气温的索引为 87-92 ,以此作为 Value
【思路】
在 Map 阶段将原始数据映射成满足要求的 K-V 对,在 Reduce 阶段对相同 Key 的值进行比较,得到最大值
2. 代码编写
[2.1 MaxTempMapper.java]
package hadoop.mr.maxtemp; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* Mapper 类
*/
public class MaxTempMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将 value 变为 String 格式
String line = value.toString();
// 获得年份
String year = line.substring(15, 19);
// 获得温度
int temp = Integer.parseInt(line.substring(87, 92)); // 存在脏数据 9999,所以要将其过滤
if (temp != 9999) {
// 输出年份与温度
context.write(new Text(year), new IntWritable(temp));
} }
}
[2.2 MaxTempReducer.java]
package hadoop.mr.maxtemp; import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**
* Reducer 类
*/
public class MaxTempReducer extends Reducer<Text, IntWritable, Text, DoubleWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
Integer max = Integer.MIN_VALUE; // 得到最大值
for (IntWritable value : values) {
max = Math.max(max, value.get());
} // 输出年份与最大温度
context.write(key, new DoubleWritable(max / 10.0));
}
}
[2.3 MaxTempApp.java]
package hadoop.mr.maxtemp; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* max Temp APP
*/
public class MaxTempApp {
public static void main(String[] args) throws Exception {
// 初始化配置文件
Configuration conf = new Configuration(); // 仅在本地开发时使用
conf.set("fs.defaultFS", "file:///"); // 初始化文件系统
FileSystem fs = FileSystem.get(conf); // 通过配置文件初始化 job
Job job = Job.getInstance(conf); // 设置 job 名称
job.setJobName("max Temp"); // job 入口函数类
job.setJarByClass(MaxTempApp.class); // 设置 mapper 类
job.setMapperClass(MaxTempMapper.class); // 设置 reducer 类
job.setReducerClass(MaxTempReducer.class); // 设置 map 的输出 K-V 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class); // 新建输入输出路径
Path pin = new Path("E:/file/temp");
Path pout = new Path("E:/test/wc/out"); // 打包后自定义输入输出路径
// Path pin = new Path(args[0]);
// Path pout = new Path(args[1]); // 设置输入路径和输出路径
FileInputFormat.addInputPath(job, pin);
FileOutputFormat.setOutputPath(job, pout); // 判断输出路径是否已经存在,若存在则删除
if (fs.exists(pout)) {
fs.delete(pout, true);
} // 执行 job
job.waitForCompletion(true);
}
}
3. 测试
本地模式下运行代码的结果如下
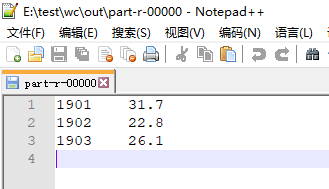
4. 部署到集群上
【4.1 修改代码 MaxTempApp.java】


【4.2 打包程序】


【4.3 运行程序】
开启 Hadoop 集群,然后将 temp 数据文件上传到 HDFS 中,过程略
运行以下命令
hadoop jar myhadoop-1.0-SNAPSHOT.jar hadoop.mr.maxtemp.MaxTempApp /testdata/temp /testdata/out
【查看结果】
命令行下可以看到结果,Web UI 查看 http://s101:8088

[MapReduce_add_2] MapReduce 实现年度最高气温统计的更多相关文章
- [Hive_add_7] Hive 实现最高气温统计
0. 说明 Hive 通过 substr() 函数实现最高气温统计 1. Hive 实现最高气温统计 1.1 思路 将一行文本加载为 String 通过 substr() 函数截取年份和温度 1.2 ...
- MapReduce项目之气温统计
在本博文,我们要学习一个挖掘气象数据的程序.气象数据是通过分布在美国全国各地区的很多气象传感器每隔一小时进行收集,这些数据是半结构化数据且是按照记录方式存储的,因此非常适合使用 MapReduce 程 ...
- [Spark Core] Spark 实现气温统计
0. 说明 聚合气温数据,聚合出 MAX . MIN . AVG 1. Spark Shell 实现 1.1 MAX 分步实现 # 加载文档 val rdd1 = sc.textFile(" ...
- Mapreduce的序列化和流量统计程序开发
一.Hadoop数据序列化的数据类型 Java数据类型 => Hadoop数据类型 int IntWritable float FloatWritable long LongWritable d ...
- P1567 气温统计
P1567 题目描述 炎热的夏日,KC 非常的不爽.他宁可忍受北极的寒冷,也不愿忍受厦门的夏天.最近,他开始研究天气的变化.他希望用研究的结果预测未来的天气. 经历千辛万苦,他收集了连续 N(1≤N≤ ...
- Hadoop工程师面试题(1)--MapReduce实现单表汇总统计
数据源格式描述: 输入t1.txt源数据,数据文件分隔符"*&*",字段说明如下: 字段序号 字段英文名称 字段中文名称 字段类型 字段长度 1 TIME_ID 时间(到时 ...
- [MapReduce_5] MapReduce 中的 Combiner 组件应用
0. 说明 Combiner 介绍 && 在 MapReduce 中的应用 1. 介绍 Combiner: Map 端的 Reduce,有自己的使用场景 在相同 Key 过多的情况下 ...
- 【合集】Hadoop 合集
0. 说明 Hadoop 随笔的目录 1. HDFS 主要内容: [HDFS_1] HDFS 的概念和特性 [HDFS_2] HDFS 的 Shell 操作 [HDFS_3] HDFS 工作机制 [H ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
随机推荐
- 课程四(Convolutional Neural Networks),第一周(Foundations of Convolutional Neural Networks) —— 1.Practice questions:The basics of ConvNets
[解释] 100*(300*300*3)+ 100=27000100 [解释] (5*5*3+1)*100=7600 [中文翻译] 您有一个输入是 63x63x16, 并 将他与32个滤波器卷积, 每 ...
- (转)Linux开启路由转发功能
原文:https://www.linuxidc.com/Linux/2016-12/138661.htm 标记一下,今天想让一台Red Hat Enterprise Linux 7开通iptables ...
- 从零开始学 Web 之 移动Web(二)JD移动端网页,移动触屏事件
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...
- Vue + Element UI 实现权限管理系统 前端篇(十):动态加载菜单
动态加载菜单 之前我们的导航树都是写死在页面里的,而实际应用中是需要从后台服务器获取菜单数据之后动态生成的. 我们在这里就用上一篇准备好的数据格式Mock出模拟数据,然后动态生成我们的导航菜单. 接口 ...
- docker学习系列(四):数据持久化
需要搞清楚一个概念的是,docker的容器设计理念是可以即开即用,用完可以随意删除,而新建容器是根据镜像进行渲染,容器的修改是不会影响到镜像,但是有时候容器里面运行的产生的数据(如mysql)或者配置 ...
- [HEOI2017] 相逢是问候
Description 支持以下两个操作: 将第 \(l\) 个数到第 \(r\) 个数 \(a_l,a_{l+1},\dots a_r\) 中的每个数 \(a_i\) 替换为 \(c^{a_i}\) ...
- C++的静态联编和动态联编
联编的概念 联编是指一个计算机程序自身彼此关联的过程,在这个联编过程中,需要确定程序中的操作调用(函数调用)与执行该操作(函数)的代码段之间的映射关系. 意思就是这个函数的实现有多种,联编就是把调用和 ...
- c#cookie读取写入操作
public static void SetCookie(string cname, string value, int effective) { HttpCookie cookie = new Ht ...
- SQL Server 数据类型映射(转载)
SQL Server 数据类型映射 SQL Server 和 .NET Framework 基于不同的类型系统. 例如,.NET Framework Decimal 结构的最大小数位数为 28,而 S ...
- vb.net 使用NPOI控制Excel檔
'導入命名空間 Imports NPOI.HSSF.UserModelImports NPOI.HPSFImports NPOI.POIFS.FileSystem Private Sub A1()'方 ...