基于TensorFlow进行TensorBoard可视化
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 1 17:51:28 2018 @author: zhen
""" import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data max_steps = 1000
learning_rate = 0.001
dropout = 0.9
data_dir = 'C:/Users/zhen/MNIST_data_bak/'
log_dir = 'C:/Users/zhen/MNIST_log_bak/' mnist = input_data.read_data_sets(data_dir, one_hot=True) # 加载数据,把数据转换成one_hot编码
sess = tf.InteractiveSession() # 创建内置sess with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-inpupt')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input') with tf.name_scope("input_reshape"):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10) # 输出包含图像的summary,该图像有四维张量构建,用于可视化 # 定义神经网络的初始化方法
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1) #从截断的正态分布中输出随机值,类似tf.random_normal从正态分布中输出随机值
return tf.Variable(initial) def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial) # 定义Variable变量的数据汇总函数
def variable_summaries(var):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var) # 求平均值
tf.summary.scalar('mean', mean) # 输出一个含有标量值的summary protocal buffer,用于可视化
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var) # 用于显示直方图信息 # 创建MLP多层神经网络
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
with tf.name_scope(layer_name):
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases # 矩阵乘
tf.summary.histogram('pre_activations', preactivate)
activations = act(preactivate, name='activation') # 激活函数relu
tf.summary.histogram('activations', activations)
return activations hidden1 = nn_layer(x, 784, 500, 'layer1') with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep_probability', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob) # 训练过程中随机舍弃部分神经元,为了防止或减轻过拟合 y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity) with tf.name_scope('scross_entropy'):
diff = tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_) # 求交叉熵
with tf.name_scope('total'):
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar('cross_entropy', cross_entropy) with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy) #Adam优化算法,全局最优,引入了二次方梯度矫正
with tf.name_scope('accuracy'):
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) tf.summary.scalar('accuracy', accuracy) merged = tf.summary.merge_all() # 整合之前定义的所有summary,在此处才开始执行,summary为延迟加载
train_writer = tf.summary.FileWriter(log_dir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(log_dir + '/test') # 可视化数据存储在日志文件中
tf.global_variables_initializer().run() def feed_dict(train):
if train:
xs, ys = mnist.train.next_batch(100)
k = dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x:xs, y_:ys, keep_prob:k} saver = tf.train.Saver()
for i in range(max_steps):
if i % 100 == 0:
summary, acc = sess.run([merged, accuracy], feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuray at step %s:%s' % (i, acc))
else:
if i % 100 == 99:
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE) # 定义TensorFlow运行选项
run_metadata = tf.RunMetadata() # 定义TensorFlow运行元信息,记录训练运行时间及内存占用等信息
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_run_metadata(run_metadata, 'stp%03d' % i)
train_writer.add_summary(summary, 1)
saver.save(sess, log_dir + 'model.ckpt', i)
else:
summary, _ = sess.run([merged,train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i) train_writer.close()
test_writer.close()
程序执行完成后,在dos命令窗口或linux窗口运行 命令,参数logdir是你程序保存log日志设置的地址。
命令,参数logdir是你程序保存log日志设置的地址。
效果如下:

结果:

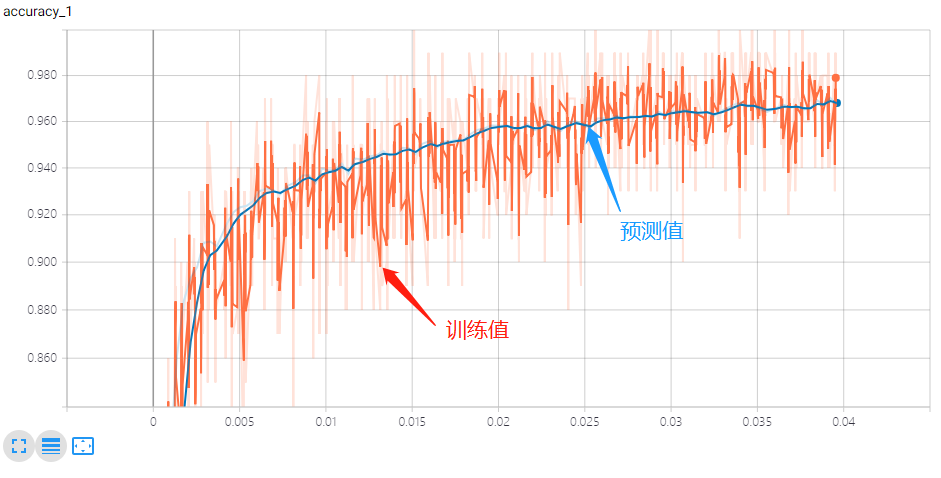
一层神经网络:

二层神经网络:
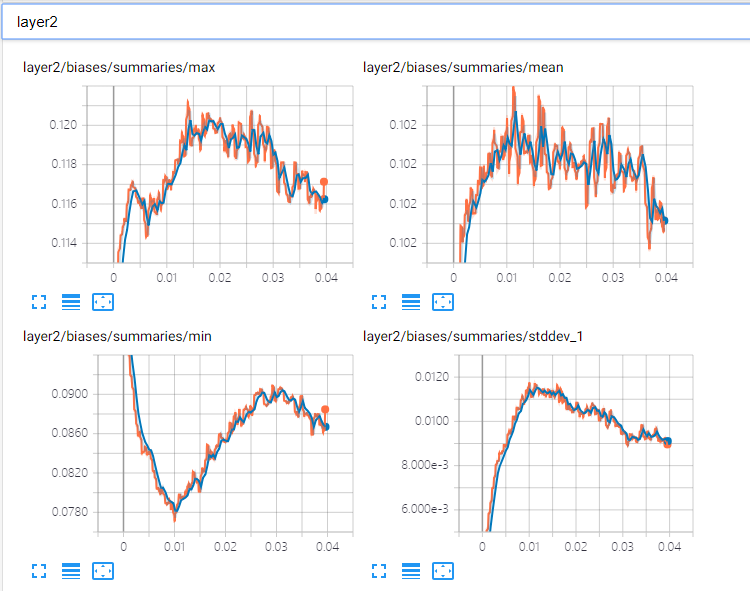
神经网络计算图:
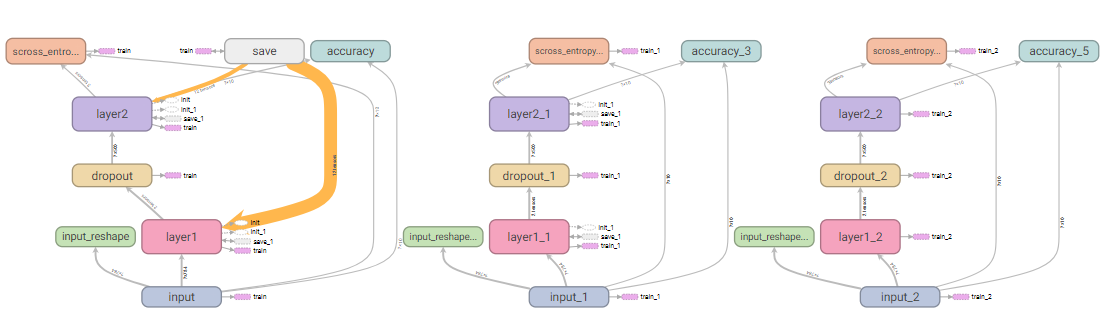
神经元输出的分布:
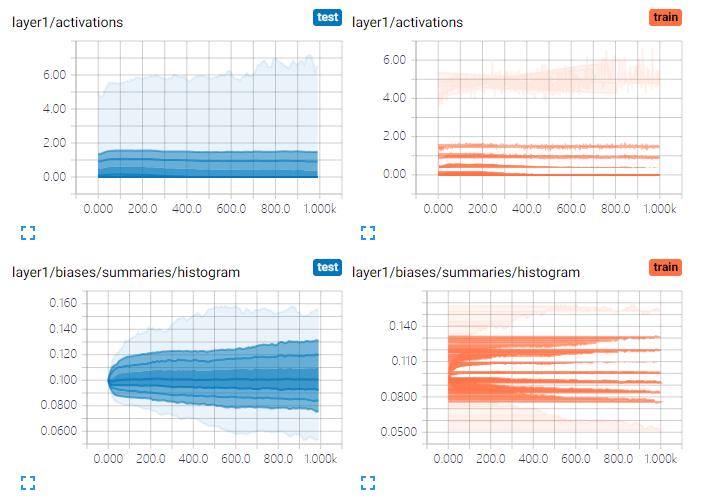
数据分布直方图:

数据可视化:
基于TensorFlow进行TensorBoard可视化的更多相关文章
- 学习TensorFlow,TensorBoard可视化网络结构和参数
在学习深度网络框架的过程中,我们发现一个问题,就是如何输出各层网络参数,用于更好地理解,调试和优化网络?针对这个问题,TensorFlow开发了一个特别有用的可视化工具包:TensorBoard,既可 ...
- Tensorflow 之 TensorBoard可视化Graph和Embeddings
windows下使用tensorboard tensorflow 官网上的例子程序都是针对Linux下的:文件路径需要更改 tensorflow1.1和1.3的启动方式不一样 :参考:Running ...
- Tensorflow细节-Tensorboard可视化-简介
先搞点基础的 注意注意注意,这里虽然很基础,但是代码应注意: 1.从writer开始后边就错开了 2.writer后可以直接接writer.close,也就是说可以: writer = tf.summ ...
- Tensorflow学习笔记3:TensorBoard可视化学习
TensorBoard简介 Tensorflow发布包中提供了TensorBoard,用于展示Tensorflow任务在计算过程中的Graph.定量指标图以及附加数据.大致的效果如下所示, Tenso ...
- 超简单tensorflow入门优化程序&&tensorboard可视化
程序1 任务描述: x = 3.0, y = 100.0, 运算公式 x×W+b = y,求 W和b的最优解. 使用tensorflow编程实现: #-*- coding: utf-8 -*-) im ...
- TensorFlow(八):tensorboard可视化
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data from tensorflow.c ...
- TensorFlow从0到1之TensorBoard可视化数据流图(8)
TensorFlow 使用 TensorBoard 来提供计算图形的图形图像.这使得理解.调试和优化复杂的神经网络程序变得很方便.TensorBoard 也可以提供有关网络执行的量化指标.它读取 Te ...
- 基于TensorFlow的深度学习系列教程 1——Hello World!
最近看到一份不错的深度学习资源--Stanford中的CS20SI:<TensorFlow for Deep Learning Research>,正好跟着学习一下TensorFlow的基 ...
- 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(二)
前言 已完成数据预处理工作,具体参照: 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(一) 设置配置文件 新建目录face_faster_rcn ...
随机推荐
- Redis主从和集群
主从概念 一个master可以拥有多个slave,一个slave又可以拥有多个slave.如此下去,形成了强大的多级服务器集群架构. master用写数据,经统计:网站的读写比率是10:1 通过主从分 ...
- 我从来不理解 JavaScript 闭包,直到有人这样向我解释它...
正如标题所述,JavaScript 闭包对我来说一直有点神秘,看过很多闭包的文章,在工作使用过闭包,有时甚至在项目中使用闭包,但我确实是这是在使用闭包的知识. 最近看国外的一些文章,终于,有人用于一种 ...
- [每天解决一问题系列 - 0011] 如何清除Windows中的Icon缓存
问题描述: 当更换一个应用或者快捷方式的图标后,会看到图标并没有及时更新 问题原因: 原因是Windows为了使图标显示更快,做了缓存%localappdata%\IconCache.db 解决方案: ...
- (转)mtr命令详解诊断网络路由
原文:https://blog.51cto.com/6226001001/1941355 http://www.zzbiji.com/2212.html----Linux下使用mtr做路由图进行网络分 ...
- postgresql 获取修改列的值
使用returning CREATE TABLE users (firstname text, lastname text, id serial primary key); INSERT INTO u ...
- 关于JAVAweb的一些东西
1.Servlet 1.Servlet访问URL映射配置 <servlet> <servlet-name>ServletDemo1</servlet-name> & ...
- 与LINQ有关的语言特性
在说LINQ之前必须先说说几个重要的C#语言特性 一:与LINQ有关的语言特性 1.隐式类型 (1)源起 在隐式类型出现之前, 我们在声明一个变量的时候, 总是要为一个变量指定他的类型 甚至在fore ...
- Hibernate学习(五)———— hibernate一对一关系映射详解
一.一对一关系的概述 一对一关系看起来简单,其实也挺复杂的.其中关系就包含了四种,单向双向和主键关联外键关联. 什么意思呢,也就是包含了单向一对一主键关联.双向一对一主键关联,单向一对一外键关联,双向 ...
- java.. C# 使用AES加密互解 采用AES-128-ECB加密模式
java需要下载外部包, commons codec.jar 1.6 較新的JAVA版本把Base64的方法改成靜態方法,可能會寫成Base64.encodeToString(encrypted, ...
- 漫画揭秘Hadoop MapReduce | 轻松理解大数据
网址:http://www.iqiyi.com/w_19rtz04nh9.html