[Spark] Spark 安装配置
原文地址:https://www.cnblogs.com/memento/p/9148732.html
Windows 上的单机版安装
下载地址:http://spark.apache.org/downloads.html
本文以 Spark 2.3.0 为例
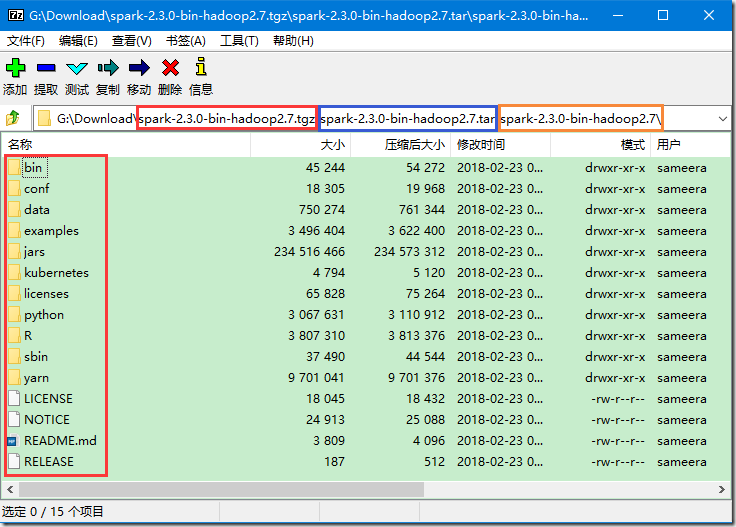
>>> 下载下来的文件是 tgz 格式的压缩文件,直接利用压缩软件将其打开,可以看见里面有一个 tar 格式的压缩文件,继续用压缩软件打开,最终如下图所示:
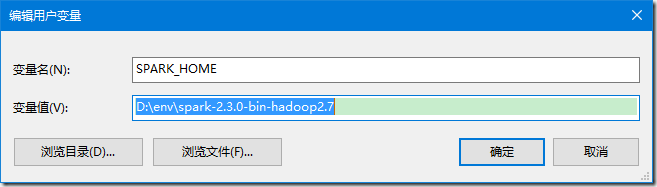
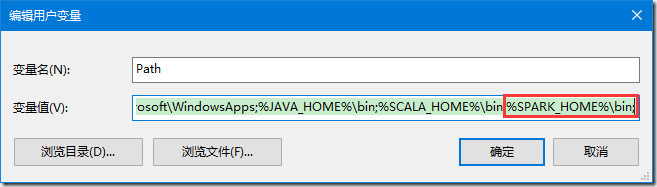
>>> 将其中的 spark-2.3.0-bin-hadoop2.7 文件夹解压,新增 SPARK_HOME 环境变量,设置为解压路径,并将其追加到 PATH 环境变量;
>>> 此时在 cmd 窗口中执行 "spark-shell" 命令可得到如下提示:
C:\Users\Memento>spark-shell
2018-06-06 23:39:36 ERROR Shell:397 - Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:379)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:394)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:387)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80)
at org.apache.hadoop.security.SecurityUtil.getAuthenticationMethod(SecurityUtil.java:611)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:273)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:261)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:791)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:761)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:634)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2464)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2464)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2464)
at org.apache.spark.SecurityManager.<init>(SecurityManager.scala:222)
at org.apache.spark.deploy.SparkSubmit$.secMgr$lzycompute$1(SparkSubmit.scala:393)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$secMgr$1(SparkSubmit.scala:393)
at org.apache.spark.deploy.SparkSubmit$$anonfun$prepareSubmitEnvironment$7.apply(SparkSubmit.scala:401)
at org.apache.spark.deploy.SparkSubmit$$anonfun$prepareSubmitEnvironment$7.apply(SparkSubmit.scala:401)
at scala.Option.map(Option.scala:146)
at org.apache.spark.deploy.SparkSubmit$.prepareSubmitEnvironment(SparkSubmit.scala:400)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:170)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:136)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
2018-06-06 23:39:36 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://Memento-PC:4040
Spark context available as 'sc' (master = local[*], app id = local-1528299586814).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.0
/_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_151)
Type in expressions to have them evaluated.
Type :help for more information.
提示说在 hadoop 路径下无法定位到 winutils,所以接下来需要配置 Hadoop;
>>> 详见:Windows 下的 Hadoop 2.7.5 环境搭建
>>> 随后再重新执行 "spark-shell" 命令即可;
By. Memento
[Spark] Spark 安装配置的更多相关文章
- spark HA 安装配置和使用(spark1.2-cdh5.3)
安装环境如下: 操作系统:CentOs 6.6 Hadoop 版本:CDH-5.3.0 Spark 版本:1.2 集群5个节点 node01~05 node01~03 为worker. node04. ...
- Spark_安装配置_运行模式
一.Spark支持的安装模式: 1.伪分布式(一台机器即可) 2.全分布式(至少需要3台机器) 二.Spark的安装配置 1.准备工作 安装Linux和JDK1.8 配置Linux:关闭防火墙.主机名 ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark standlone安装与配置
spark的安装简单,去官网下载与集群hadoop版本相一致的文件即可. 解压后,主要需要修改spark-evn.sh文件. 以spark standlone为例,配置dn1,nn2为master,使 ...
- Spark(三): 安装与配置
参见 HDP2.4安装(五):集群及组件安装 ,安装配置的spark版本为1.6, 在已安装HBase.hadoop集群的基础上通过 ambari 自动安装Spark集群,基于hadoop yarn ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
- 安装配置最强Spark IDE--IDEA
1.安装IntelliJ IDEA IDEA 全称 IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手.代码自动提示 ...
- centOS7下Spark安装配置
环境说明: 操作系统: centos7 64位 3台 centos7-1 192.168.190.130 master centos7-2 192.168.190.129 slave1 centos7 ...
- 安装配置Spark集群
首先准备3台电脑或虚拟机,分别是Master,Worker1,Worker2,安装操作系统(本文中使用CentOS7). 1.配置集群,以下步骤在Master机器上执行 1.1.关闭防火墙:syste ...
- ubuntu下spark安装配置
一.安装vmware虚拟机 二.在虚拟机上安装ubuntu12.04操作系统 三.安装jdk1.8.0_25 http://www.oracle.com/technetwork/java/javase ...
随机推荐
- .NET手记-JS获取Url参数
最近为App做活动专区,其中很多活动都是采用html 5页面来制作的.一方面体量较小,制作快速,更新维护容易:另一方面,嵌入App后适配效果也不会很差. 这里我们采用混编形式来从native app传 ...
- Apache Kafka: 优化部署的10个最佳实践
原文作者:Ben Bromhead 译者:江玮 原文地址:https://www.infoq.com/articles/apache-kafka-best-practices-to-opti ...
- 经典面试题SALES TAXES思路分析和源码分享
题目: SALES TAXES Basic sales tax is applicable at a rate of 10% on all goods, except books, food, and ...
- mybatis教程之原理剖析
MyBatis是目前非常流行的ORM框架,功能很强大,然而其实现却比较简单.优雅.本文通过代理的方式来看下其实现 方式一:传统API方式 @Test public void add() throws ...
- Java中的静态变量、静态方法问题
由关键字static所定义的变量与方法,分别称为静态变量和静态方法,它们又都被称为静态成员 1.静态方法 无需本类的对象也可以调用此方法,调用形式为“类名.方法名”,静态方法常常为其他类提供一些方法而 ...
- 模块,import,from xxx import xxx
一,模块 模块就是一个包含了python定义和声明的文件,文件名就是模块的名字加上.py后缀,总体来说,import加载的模块一共分成四个通用的类别: 1,使用python编写的py文件 2,已被变异 ...
- Visual Studio 2015 激活码
专业版:HMGNV-WCYXV-X7G9W-YCX63-B98R2 企业版:HM6NR-QXX7C-DFW2Y-8B82K-WTYJV
- 新建 .NET Core 控制台项目
1. 安装 .NET Core SDK 1.0 参考微软官方网站 https://www.microsoft.com/net/download/windows 2. 打开命令提示符:输入以下代码验证S ...
- jquery 截取屏幕
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- 性能监控(2)–linux下的vmstat命令
vmstat它可以统计CPU.内存使用情况.swap使用情况等信息.它还可以指定采样周期和次数.