What’s new for Spark SQL in Apache Spark 1.3(中英双语)
文章标题
What’s new for Spark SQL in Apache Spark 1.3
作者介绍
文章正文
The Apache Spark 1.3 release represents a major milestone for Spark SQL. In addition to several major features, we are very excited to announce that the project has officially graduated from Alpha, after being introduced only a little under a year ago. In this blog post we will discuss exactly what this step means for compatibility moving forward, as well as highlight some of the major features of the release.
- exactly [ɪɡˈzæktli] 恰恰;确切地;精确地;完全地,全然
- compatibility [kəmˌpætəˈbɪlətɪ] 适合;互换性; 通用性;和睦相处 兼容性
- highlight [ˈhaɪˌlaɪt] 强调,突出;把…照亮;标示记号;为…中最突出的事物
1、Graduation from Alpha
While we know many organizations (including all of Databricks’ customers) have already begun using Spark SQL in production, the graduation from Alpha comes with a promise of stability for those building applications using this component. Like the rest of the Spark stack, we now promise binary compatibility for all public interfaces through the Apache Spark 1.X release series.
- rest [rest] 休息;剩余部分;支持物;宁静,安宁 休息;静止;停止;安心
- the rest of 其余的;剩下的
- binary compatibility [计] 二进制兼容性
Since the SQL language itself and our interaction with Apache Hive represent a very large interface, we also wanted to take this chance to articulate our vision for how the project will continue to evolve. A large number of Spark SQL users have data in Hive metastores and legacy workloads which rely on Hive QL. As a result, Hive compatibility will remain a major focus for Spark SQL moving forward.
- interaction [ˌɪntɚˈækʃən] 互动;一起活动;合作;互相影响
- articulate [ɑ:rˈtɪkjuleɪt] 清晰地发(音);言语表达;(用关节)连接 表达
- vision [ˈvɪʒən] 视力,视觉;美景,绝妙的东西;幻影;想像力 视野
- evolve [iˈvɑ:lv] 使发展;使进化;设计,制订出;发出,散发 演变
- legacy [ˈlɛɡəsi] 遗产;遗赠
More specifically, the HiveQL interface provided by the HiveContext remains the most complete dialect of SQL that we support and we are committed to continuing to maintain compatibility with this interface. In places where our semantics differ in minor ways from Hive’s (i.e. SPARK-5680), we continue to aim to provide a superset of Hive’s functionality. Additionally, while we are excited about all of the new data sources that are available through the improved native Data Sources API (see more below), we will continue to support reading tables from the Hive Metastore using Hive’s SerDes.
- dialect [ˈdaɪəˌlɛkt] 方言,土语;语调;[语]语支;专业用语
- in minor ways 在小的方面
- minor [ˈmaɪnɚ] 较小的,少数的,小…;未成年的;[乐]小调的,小音阶的;
The new DataFrames API (also discussed below) is currently marked experimental. Since this is the first release of this new interface, we wanted an opportunity to get feedback from users on the API before it is set in stone. That said, we do not anticipate making any major breaking changes to DataFrames, and hope to remove the experimental tag from this part of Spark SQL in Apache Spark 1.4. You can track progress and report any issues at SPARK-6116.
- experimental [ɪkˌspɛrəˈmɛntl] 实验的;根据实验的;试验性的
- it is set in stone 坚如磐石、坚定不移、绝不动摇、不可改变
- anticipate [ænˈtɪsəˌpet] 预见;预料;预感;先于…行动
2、Improved Data Sources API
The Data Sources API was another major focus for this release, and provides a single interface for loading and storing data using Spark SQL. In addition to the sources that come prepackaged with the Apache Spark distribution, this API provides an integration point for external developers to add support for custom data sources. At Databricks, we have already contributed libraries for reading data stored in Apache Avro or CSV and we look forward to contributions from others in the community (check out spark packages for a full list of sources that are currently available).
- prepackaged [pri:'pækɪdʒd] 出售以前先包装( prepackage的过去式和过去分词 )
- integration point 集成点;积分点;整合点

3、Unified Load/Save Interface
In this release we added a unified interface to SQLContext and DataFrame for loading and storing data using both the built-in and external data sources. These functions provide a simple way to load and store data, independent of whether you are writing in Python, Scala, Java, R or SQL. The examples below show how easy it is to both load data from Avro and convert it into parquet in different languages.
- independent of [ˌɪndɪˈpɛndənt ʌv] 不依赖…,独立于…
3.1 Scala
val df = sqlContext.load("/home/michael/data.avro", "com.databricks.spark.avro")
df.save("/home/michael/data.parquet", "parquet")
3.2 Python
df = sqlContext.load("/home/michael/data.avro", "com.databricks.spark.avro")
df.save("/home/michael/data.parquet", "parquet")
3.3 Java
DataFrame df = sqlContext.load("/home/michael/data.avro", "com.databricks.spark.avro")
df.save("/home/michael/data.parquet", "parquet")
3.4 SQL
> CREATE TABLE avroData
USING com.databricks.spark.avro
OPTIONS (
path "/home/michael/data.avro"
) > CREATE TABLE parquetData
USING parquet
OPTIONS (
path "/home/michael/data/parquet")
AS SELECT * FROM avroData
4、Automatic Partition Discovery and Schema Migration for Parquet
Parquet has long been one of the fastest data sources supported by Spark SQL. With its columnar format, queries against parquet tables can execute quickly by avoiding the cost of reading unneeded data.
In the Apache Spark 1.3 release we added two major features to this source. First, organizations that store lots of data in parquet often find themselves evolving the schema over time by adding or removing columns. With this release we add a new feature that will scan the metadata for all files, merging the schemas to come up with a unified representation of the data. This functionality allows developers to read data where the schema has changed overtime, without the need to perform expensive manual conversions.
- organizations [ˌɔ:ɡənaɪ'zeɪʃnz] 组织( organization的名词复数 );组织性;组织工作;安排
- come up with 拿出来
- representation 表示
- perform [pərˈfɔ:rm] 执行;履行;表演;扮演
- expensive [ɪkˈspɛnsɪv] 昂贵的,花钱多的;豪华的
- manual [ˈmænjuəl] 用手的;手制的,手工的;[法]占有的;体力的
- conversions [kən'vɜ:ʃnz] 变换( conversion的名词复数 );(宗教、信仰等)彻底改变;
Additionally, the parquet datasource now supports auto-discovering data that has been partitioned into folders, and then prunes which folders are scanned based on predicates in queries made against this data. This optimization means that you can greatly speed up may queries simply by breaking up your data into folders. For example:
- prune [prun] 删除;减少
- predicate ['predɪkət] 断言,断定;宣布,宣讲;使基于
- breaking up 破裂 分手 分解
/data/year=2014/file.parquet
/data/year=2015/file.parquet
... SELECT * FROM table WHERE year = 2015
In Apache Spark 1.4, we plan to provide an interface that will allow other formats, such as ORC, JSON and CSV, to take advantage of this partitioning functionality.
5、Persistent Data Source Tables
Another feature that has been added in Apache Spark 1.3 is the ability to persist metadata about Spark SQL Data Source tables to the Hive metastore. These tables allow multiple users to share the metadata about where data is located in a convenient manner. Data Source tables can live alongside native Hive tables, which can also be read by Spark SQL.
- alongside [əˌlɔ:ŋˈsaɪd] 在…的侧面;在…旁边;与…并排
6、Reading from JDBC Sources
Finally, a Data Source for reading from JDBC has been added as built-in source for Spark SQL. Using this library, Spark SQL can extract data from any existing relational databases that supports JDBC. Examples include mysql, postgres, H2, and more. Reading data from one of these systems is as simple as creating a virtual table that points to the external table. Data from this table can then be easily read in and joined with any of the other sources that Spark SQL supports.
> CREATE TEMPORARY TABLE impressions
USING org.apache.spark.sql.jdbc
OPTIONS (
url "jdbc:postgresql:dbserver",
dbtable "impressions"
) > SELECT COUNT(*) FROM impressions
This functionality is a great improvement over Spark’s earlier support for JDBC (i.e., JdbcRDD). Unlike the pure RDD implementation, this new DataSource supports automatically pushing down predicates, converts the data into a DataFrame that can be easily joined, and is accessible from Python, Java, and SQL in addition to Scala.
- pure [pjʊr] 纯的;单纯的;纯真的;干净的 纯粹的
7、Introducing DataFrames
While we have already talked about the DataFrames in other blog posts and talks at the Spark Summit East, any post about Apache Spark 1.3 would be remiss if it didn’t mention this important new API. DataFrames evolve Spark’s RDD model, making it faster and easier for Spark developers to work with structured data by providing simplified methods for filtering, aggregating, and projecting over large datasets. Our DataFrame implementation was inspired by Pandas’ and R’s data frames, and are fully interoperable with these implementations. Additionally, Spark SQL DataFrames are available in Spark’s Java, Scala, and Python API’s as well as the upcoming (unreleased) R API.
- remiss [rɪˈmɪs] 玩忽职守的,马虎 失职
- inspired [ɪnˈspaɪərd] 有创造力的;品质优秀的;有雄心壮志的; 受到启发的
- available [əˈveləbəl] 可获得的;有空的;可购得的;能找到的
- upcoming [ˈʌpˌkʌmɪŋ] 即将到来;即将来到的,即将出现的
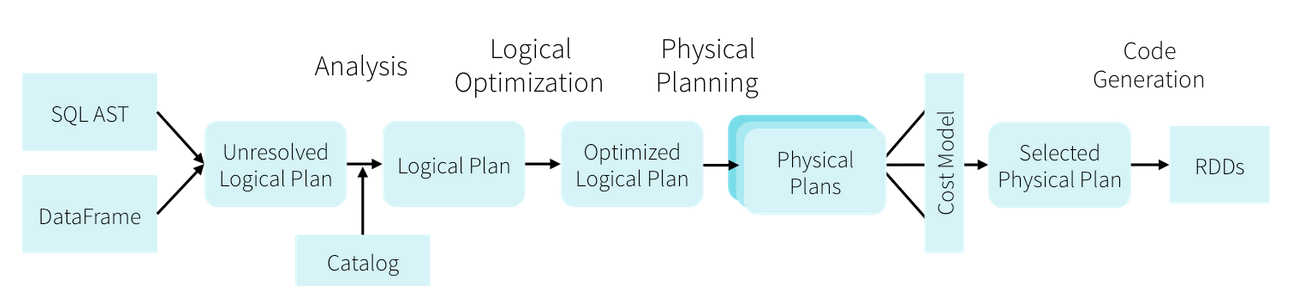
Internally, DataFrames take advantage of the Catalyst query optimizer to intelligently plan the execution of your big data analyses. This planning permeates all the way into physical storage, where optimizations such as predicate pushdown are applied based on analysis of user programs. Since this planning is happening at the logical level, optimizations can even occur across function calls, as shown in the example below.
- advantage [ədˈvæntɪdʒ] 有利条件;益处;优越(性);处于支配地位 优势
- permeate [ˈpɜ:rmieɪt] 渗透;渗入;弥漫;遍布
- pushdown 下推
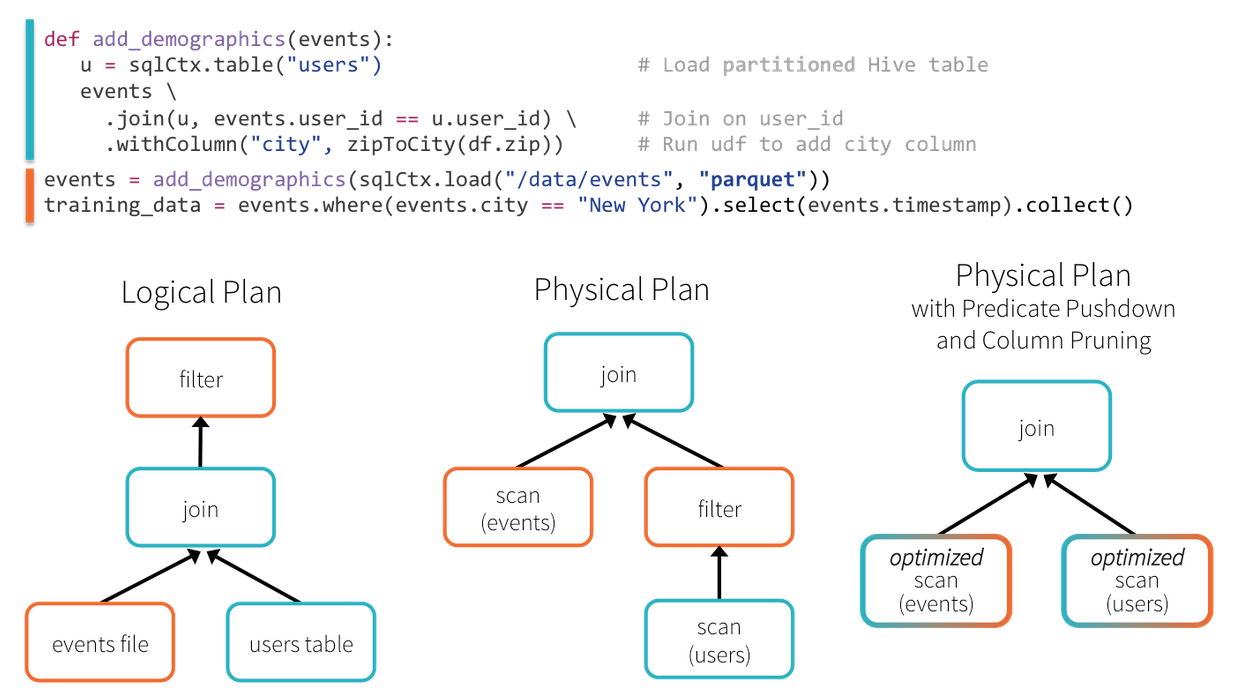
- predicate pushdown 谓词下推,属于逻辑优化。优化器可以将谓词过滤下推到数据源,从而使物理执行跳过无关数据。在使用Parquet的情况下,更可能存在文件被整块跳过的情况,同时系统还通过字典编码把字符串对比转换为开销更小的整数对比。在关系型数据库中,谓词则被下推到外部数据库用以减少数据传输。
- column pruning 列裁剪,在读数据的时候,只读取查询中需要用到的列,而忽略其他列。
In this example, Spark SQL is able to push the filtering of users by their location through the join, greatly reducing its cost to execute. This optimization is possible even though the original author of the add_demographics function did not provide a parameter for specifying how to filter users!
- specifying ['spesɪfaɪʃ] 指定( specify的现在分词 );详述;提出…的条件;使具有特性
This is only example of how Spark SQL DataFrames can make developers more efficient by providing a simple interface coupled with powerful optimization.
To learn more about Spark SQL, Dataframes, or Apache Spark 1.3, checkout the SQL programming guide on the Apache Spark website. Stay tuned to this blog for updates on other components of the Apache Spark 1.3 release!
参考文献
- https://databricks.com/blog/2015/03/24/spark-sql-graduates-from-alpha-in-spark-1-3.html
What’s new for Spark SQL in Apache Spark 1.3(中英双语)的更多相关文章
- A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets(中英双语)
文章标题 A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets 且谈Apache Spark的API三剑客:RDD.Dat ...
- Introducing DataFrames in Apache Spark for Large Scale Data Science(中英双语)
文章标题 Introducing DataFrames in Apache Spark for Large Scale Data Science 一个用于大规模数据科学的API——DataFrame ...
- 理解Spark SQL(三)—— Spark SQL程序举例
上一篇说到,在Spark 2.x当中,实际上SQLContext和HiveContext是过时的,相反是采用SparkSession对象的sql函数来操作SQL语句的.使用这个函数执行SQL语句前需要 ...
- 【Spark学习】Apache Spark配置
Spark版本:1.1.1 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4137969.html Spar ...
- 【Spark学习】Apache Spark调优
Spark版本:1.1.0 本文系以开源中国社区的译文为基础,结合官方文档翻译修订而来,转载请注明以下链接: http://www.cnblogs.com/zhangningbo/p/4117981. ...
- 一条 SQL 在 Apache Spark 之旅
转载自过往记忆大数据 https://www.iteblog.com/archives/2561.html Spark SQL 是 Spark 众多组件中技术最复杂的组件之一,它同时支持 SQL 查询 ...
- 【Spark学习】Apache Spark项目简介
引言:本文直接翻译自Spark官方网站首页 Lightning-fast cluster computing 从Spark官方网站给出的标题可以看出:Spark——像闪电一样快的集群计算 Apache ...
- Introducing Apache Spark Datasets(中英双语)
文章标题 Introducing Apache Spark Datasets 作者介绍 Michael Armbrust, Wenchen Fan, Reynold Xin and Matei Zah ...
- spark SQL学习(spark连接 mysql)
spark连接mysql(打jar包方式) package wujiadong_sparkSQL import java.util.Properties import org.apache.spark ...
随机推荐
- numpy 用于图像处理
1. 转换为灰度图 灰度图的数据可以看成是二维数组,元素取值为0 ~ 255,其中,0为黑色,255为白色.从0到255逐渐由暗色变为亮色. 灰度图转换(ITU-R 601-2亮度变换): L = R ...
- 一种表达式语言的解析引擎JEXL简单使用
Jexl 是一个 Expression Language 的解析引擎, 是为了方便嵌入你的系统或者程序框架的开发中, 他算是实现了 JSTL 中 EL 的延伸版本. 不过也采用了一些 Velocity ...
- shell编程第四天
- superset链接本地mysql数据库
刚安装好superset的时候大家都知道是用的其自动生成的sqllite数据库,如果我们想让器链接到自己数据库,给大家分享一下我的方法,以mysql为例: 1.安装好数据库mysql: $ sudo ...
- AGC 002E.Candy Piles(博弈论)
题目链接 \(Description\) 给定\(n\)堆糖,数量分别为\(a_i\).Alice和Bob轮流操作.每次可以吃掉最多的一堆,也可以每堆各吃掉一个.无法操作的人输,求谁能赢. \(n\l ...
- 2018.12.1 Test
目录 2018.12.1 Test A 串string(思路) B 变量variable(最小割ISAP) C 取石子stone(思路 博弈) 考试代码 B C 2018.12.1 Test 题目为2 ...
- php error_log() 范例
<?php// 如果无法连接到数据库,发送通知到服务器日志if (!Ora_Logon($username, $password)) { error_log("Oracle da ...
- (转)JavaWeb学习之Servlet(二)----Servlet的生命周期、继承结构、修改Servlet模板
[声明] 欢迎转载,但请保留文章原始出处→_→ 文章来源:http://www.cnblogs.com/smyhvae/p/4140466.html 一.http协议回顾: 在上一篇文章中:JavaW ...
- NodeJS多进程
NodeJS多进程 Node以单线程的方式运行,通过事件驱动的方式来减少开销车,处理并发.我们可以注册多进程,然后监听子进程的事件来实现并发 简介 Node提供了child_process模块来处理子 ...
- 11-22 JS中级复习
1.this js的关键字, 用途:指向某一个对象. 如何判断this指向 函数(方法)内 一种以函数的方式调用(不带.) this指向winodw 一种以方法的形式调用(函数名前面带.)this指向 ...