【JAVA面试】java面试题整理(4)
java面试题整理(4)
JAVA常考点4
文件夹
9、servlet里面有哪些方法?说一说get和post方法的差别 5
11、具体解释synchronized与Lock的差别与使用 6
12、悲观锁。乐观锁,行锁。表锁,页锁,共享锁。排他锁 17
- Set集合怎样保证不反复
弄清怎么个逻辑达到元素不反复的,源代码先上
HashSet 类中的add()方法:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
类中map和PARENT的定义:
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map用来匹配Map中后面的对象的一个虚拟值
private static final Object PRESENT = new Object();
put()方法:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
能够看到for循环中,遍历table中的元素,
假设hash码值不同样。说明是一个新元素,存。
假设没有元素和传入对象(也就是add的元素)的hash值相等,那么就觉得这个元素在table中不存在,将其加入进table;
假设hash码值同样,且equles推断相等,说明元素已经存在,不存;
假设hash码值同样,且equles推断不相等。说明元素不存在,存;
假设有元素和传入对象的hash值相等,那么,继续进行equles()推断,假设仍然相等,那么就觉得传入元素已经存在,不再加入。结束,否则仍然加入;
可见hashcode()和equles()在此显得非常关键了,以下就来解读一下hashcode和equles:
首先要明白:仅仅通过hash码值来推断两个对象时否同样合适吗?答案是不合适的,由于有可能两个不同的对象的hash码值同样;
什么是hash码值?
在java中存在一种hash表结构,它通过一个算法,计算出的结果就是hash码值;这个算法叫hash算法。
hash算法是怎么计算的呢?
是通过对象中的成员来计算出来的结果;
假设成员变量是基本数据类型的值。 那么用这个值 直接參与计算;
假设成员变量是引用数据类型的值,那么获取到这个成员变量的哈希码值后。再參数计算
如:新建一个Person对象。重写hashCode方法
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ?
0 : name.hashCode());
return result;
}
能够看出,Person对象内两个參数name,age。hash码值是这两者计算后的记过,那么全然有可能两个对象name。age都不同,hash码值同样;
以下看下equles()方法:
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
equles方法内部是分别对name,age进行推断,是否相等。
综合上述,在向hashSet中add()元素时。推断元素是否存在的根据,不仅仅是hash码值就能够确定的,同一时候还要结合equles方法。
2、Java中Integer型和int型的差别
a.Java 中的数据类型分为基本数据类型和引用数据类型。int是基本数据类型,直接存放值。而而Integer是对象。用一个引用指向这个对象。Ingeter是int的包装类。int的初值为0。Ingeter的初值为null。
b.初始化
int i =1。
Integer i= new Integer(1)。
有了自己主动装箱和拆箱。使得对Integer类也可使用:
Integer i= 100;
实际上上面这个代码调用了:
Integer i = Integer.valueOf(100);
c.Integer是int的封装类,int和Integer都能够表示某一个数值,int和Integer不能够互用,由于他们两种不同的数据类型。
3、接口能够继承接口吗?抽象类能够继承接口吗?
接口不仅能够继承接口,并且一个接口能够继承多个接口,接口是特殊的抽象类。
抽象类不能够继承接口。但能够实现接口。抽象类能够继承实体类,可是不能继承接口。
4、数据库索引的作用
长处:创建索引主要能够大大提高系统性能,主要优势有以下5点:
通过创建唯一性索引,能够保证数据库表中每一行数据的唯一性。
能够大大加快 数据的检索速度,这也是创建索引的最基本的原因。
能够加速表和表之间的连接,特别是在实现数据的參考完整性方面特别有意义。
在使用分组和排序 子句进行数据检索时,同样能够显著降低查询中分组和排序的时间。
通过使用索引。能够在查询的过程中。使用优化隐藏器,提高系统的性能。
缺点:
创建索引和维护索引要耗费时间。这样的时间随着数据 量的添加而添加。
索引须要占物理空间,除了数据表占数据空间之外,每个索引还要占一定的物理空间,假设要建立聚簇索引,那么须要的空间就会更大。
当对表中的数据进行添加、删除和改动的时候,索引也要动态的维护。这样就降低了数据的维护速度。
索引主要有两个特征:唯一性索引和复合索引。
5、怎样改动数据库中的字段类型
ALTER TABLE 表名 MODIFY COLUMN 字段名 字段类型定义;(注意不是update)
6、having的作用
HAVING 就像WHERE条件一样。按指定要求来取数据集。
仅仅只是WHERE一般数据查询来指定条件,HAVING是用在GROUP BY 分组来指定条件。
HAVING 子句运做起来非常象 WHERE 子句。 仅仅用于对那些满足 HAVING 子句里面给出的条件的组进行计算。
事实上,WHERE 在分组和聚集之前过滤掉我们不须要的输入行, 而 HAVING 在 GROUP 之后那些不须要的组. 因此,WHERE 无法使用一个聚集函数的结果. 而另一方面,我们也没有理由写一个不涉及聚集函数的 HAVING. 假设你的条件不包括聚集。那么你也能够把它写在 WHERE 里面。 这样就能够避免对那些你准备抛弃的行进行的聚集运算.
7、高速排序与归并排序的差别
归并排序:简单来说就是先将数组不断细分成最小的单位,然后每个单位分别排序,排序完成后合并,反复以上过程最后就能够得到排序结果。
复杂度:O(nlogn) 稳当
高速排序:简单来说就是先选定一个基准元素,然后以该基准元素划分数组,再在被划分的部分反复以上过程,最后能够得到排序结果。
复杂度:O(nlogn) 不稳定
两者都是用分治法的思想。只是最后归并排序的合并操作比高速排序的要繁琐。
8、final关键词作用有哪些?
final修饰类,类不能被继承
final修饰方法。方法不能被覆写
final修饰的变量初始化后则不能被改动。
9、servlet里面有哪些方法?说一说get和post方法的差别
init() 、destroy() 、service()等。
在servlet开发中,以doGet()和doPost()分别处理get和post方法。另外另一个doService(), 它是一个调度方法,当一个请求发生时,首先运行doService(),无论是get还是post。在HttpServlet这个基类中实现了一个角度。首先推断是请求时get还是post,假设是get就调用doGet(), 假设是post就调用doPost()。
你也能够直接过载doService()方法,这样你能够无论是get还是post。都会运行这种方法。
get和post方法的差别:
10、线性表的的顺序存储与链式存储的特点
a)顺序存储结构:
长处:
随机读取(时间复杂度为O(1))
无需为表示表中元素之间的逻辑关系而添加额外的存储空间
缺点:
插入、删除操作须要移动大量元素。效率低(时间复杂度为O(n))。
表的长度难以确定
b)链式存储结构.
长处:
插入、删除不须要移动数据。效率高(时间复杂度为O(1));
缺点:
存取时须要遍历,效率低(时间复杂度为O(n));
顺序存储结构一般用于:频繁查找,非常少插入、删除;而链式存储结构一般用于频繁插入、删除;
11、具体解释synchronized与Lock的差别与使用
引言:
昨天在学习别人分享的面试经验时,看到Lock的使用。
想起自己在上次面试也遇到了synchronized与Lock的差别与使用。
于是。我整理了两者的差别和使用情况,同一时候,对synchronized的使用过程一些常见问题的总结。最后是參照源代码和说明文档。对Lock的使用写了几个简单的Demo。
请大家批评指正。
技术点:
(1)线程与进程:
在開始之前先把进程与线程进行区分一下。一个程序最少须要一个进程,而一个进程最少须要一个线程。
关系是线程–>进程–>程序的大致组成结构。所以线程是程序运行流的最小单位。而进程是系统进行资源分配和调度的一个独立单位。以下我们全部讨论的都是建立在线程基础之上。
(2)Thread的几个重要方法:
我们先了解一下Thread的几个重要方法。
a、start()方法,调用该方法開始运行该线程;b、stop()方法,调用该方法强制结束该线程运行。c、join方法,调用该方法等待该线程结束。d、sleep()方法,调用该方法该线程进入等待。
e、run()方法,调用该方法直接运行线程的run()方法,可是线程调用start()方法时也会运行run()方法。差别就是一个是由线程调度运行run()方法,一个是直接调用了线程中的run()方法!
!
看到这里,可能有些人就会问啦。那wait()和notify()呢?要注意。事实上wait()与notify()方法是Object的方法。不是Thread的方法。!同一时候,wait()与notify()会配合使用,分别表示线程挂起和线程恢复。
这里另一个非经常见的问题,顺带提一下:wait()与sleep()的差别。简单来说wait()会释放对象锁而sleep()不会释放对象锁。
这些问题有非常多的资料,不再赘述。
(3)线程状态:

线程总共同拥有5大状态,通过上面第二个知识点的介绍。理解起来就简单了。
新建状态:新建线程对象。并没有调用start()方法之前
就绪状态:调用start()方法之后线程就进入就绪状态。可是并非说仅仅要调用start()方法线程就立即变为当前线程,在变为当前线程之前都是为就绪状态。
值得一提的是,线程在睡眠和挂起中恢复的时候也会进入就绪状态哦。
运行状态:线程被设置为当前线程,開始运行run()方法。就是线程进入运行状态
堵塞状态:线程被暂停,比方说调用sleep()方法后线程就进入堵塞状态
死亡状态:线程运行结束
(4)锁类型
可重入锁:在运行对象中全部同步方法不用再次获得锁
可中断锁:在等待获取锁过程中可中断
公平锁: 按等待获取锁的线程的等待时间进行获取,等待时间长的具有优先获取锁权利
读写锁:对资源读取和写入的时候拆分为2部分处理。读的时候能够多线程一起读,写的时候必须同步地写
synchronized与Lock的差别
(1))我把两者的差别分类到了一个表中,方便大家对照:
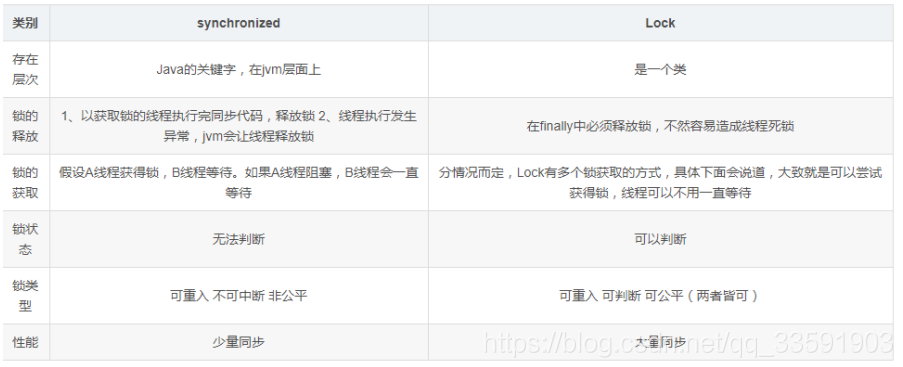
也许,看到这里还对LOCK所知甚少,那么接下来,我们进入LOCK的深入学习。
Lock具体介绍与Demo
以下是Lock接口的源代码。笔者修剪之后的结果:
public interface Lock {
/**
* Acquires the lock.
*/
void lock();
/**
* Acquires the lock unless the current thread is
* {@linkplain Thread#interrupt interrupted}.
*/
void lockInterruptibly() throws InterruptedException;
/**
* Acquires the lock only if it is free at the time of invocation.
*/
boolean tryLock();
/**
* Acquires the lock if it is free within the given waiting time and the
* current thread has not been {@linkplain Thread#interrupt interrupted}.
*/
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
/**
* Releases the lock.
*/
void unlock();
}
从Lock接口中我们能够看到主要有个方法。这些方法的功能从凝视中能够看出:
lock():获取锁,假设锁被暂用则一直等待
unlock():释放锁
tryLock(): 注意返回类型是boolean。假设获取锁的时候锁被占用就返回false,否则返回true
tryLock(long time, TimeUnit unit):比起tryLock()就是给了一个时间期限,保证等待參数时间
lockInterruptibly():用该锁的获得方式,假设线程在获取锁的阶段进入了等待,那么能够中断此线程,先去做别的事
通过 以上的解释,大致能够解释在上个部分中“锁类型(lockInterruptibly())”,“锁状态(tryLock())”等问题。还有就是前面子所获取的过程我所写的“大致就是能够尝试获得锁,线程能够不会一直等待”用了“能够”的原因。
以下是Lock一般使用的样例,注意ReentrantLock是Lock接口的实现。
lock():
package com.brickworkers;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class LockTest {
private Lock lock = new ReentrantLock();
//须要參与同步的方法
private void method(Thread thread){
lock.lock();
try {
System.out.println("线程名"+thread.getName() + "获得了锁");
}catch(Exception e){
e.printStackTrace();
} finally {
System.out.println("线程名"+thread.getName() + "释放了锁");
lock.unlock();
}
}
public static void main(String[] args) {
LockTest lockTest = new LockTest();
//线程1
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
lockTest.method(Thread.currentThread());
}
}, "t1");
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
lockTest.method(Thread.currentThread());
}
}, "t2");
。t1.start();
。t2.start();
}
}
//运行情况:线程名t1获得了锁
// 线程名t1释放了锁
// 线程名t2获得了锁
// 线程名t2释放了锁
tryLock():
package com.brickworkers;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class LockTest {
private Lock lock = new ReentrantLock();
//须要參与同步的方法
private void method(Thread thread){
/* lock.lock();
try {
System.out.println("线程名"+thread.getName() + "获得了锁");
}catch(Exception e){
e.printStackTrace();
} finally {
System.out.println("线程名"+thread.getName() + "释放了锁");
lock.unlock();
}*/
if(lock.tryLock()){
try {
System.out.println("线程名"+thread.getName() + "获得了锁");
}catch(Exception e){
e.printStackTrace();
} finally {
System.out.println("线程名"+thread.getName() + "释放了锁");
lock.unlock();
}
}else{
System.out.println("我是"+Thread.currentThread().getName()+"有人占着锁,我就不要啦");
}
}
public static void main(String[] args) {
LockTest lockTest = new LockTest();
//线程1
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
lockTest.method(Thread.currentThread());
}
}, "t1");
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
lockTest.method(Thread.currentThread());
}
}, "t2");
。t1.start();
。t2.start();
}
}
//运行结果: 线程名t2获得了锁
// 我是t1有人占着锁,我就不要啦
// 线程名t2释放了锁
看到这里相信大家也都会使用怎样使用Lock了吧。关于tryLock(long time, TimeUnit unit)和lockInterruptibly()不再赘述。前者主要存在一个等待时间,在測试代码中写入一个等待时间。后者主要是等待中断,会抛出一个中断异常,经常使用度不高,喜欢探究能够自己深入研究。
前面比較重提到“公平锁”。在这里能够提一下ReentrantLock对于平衡锁的定义。在源代码中有这么两段:
/**
* Sync object for non-fair locks
*/
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
/**
* Performs lock. Try immediate barge, backing up to normal
* acquire on failure.
*/
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
/**
* Sync object for fair locks
*/
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
从以上源代码能够看出在Lock中能够自己控制锁是否公平,并且,默认的是非公平锁,以下是ReentrantLock的构造函数:
public ReentrantLock() {
sync = new NonfairSync();//默认非公平锁
}
尾记录:
笔者水平一般,只是此博客在引言中的目的已全部达到。这仅仅是笔者在学习过程中的总结与概括,如存在不对的,欢迎大家批评指出。
延伸学习:对于LOCK底层的实现。大家能够參考:
点击Lock底层介绍博客
两种同步方式性能測试,大家能够參考:
点击查看两种同步方式性能測试博客
博主18年3月新增:
回来看自己博客。
发现东西阐述的不够完整。这里在做补充,由于这篇博客訪问较大,所以为了不误导大家,尽量介绍给大家正确的表述:
(1)两种锁的底层实现方式:
synchronized:我们知道java是用字节码指令来控制程序(这里不包括热点代码编译成机器码)。在字节指令中,存在有synchronized所包括的代码块。那么会形成2段流程的运行。
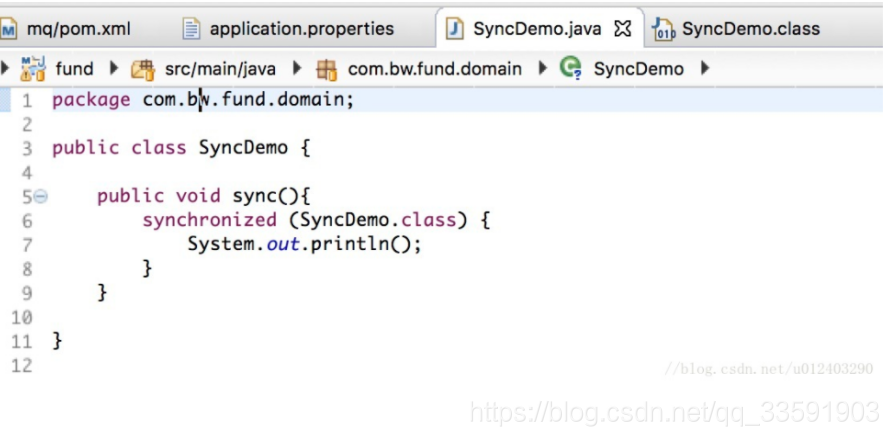
我们点击查看SyncDemo.java的源代码SyncDemo.class,能够看到例如以下:
x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMzNTkxOTAz,size_27,color_FFFFFF,t_70" width="904" />
如上就是这段代码段字节码指令。没你想的那么难吧。言归正传。我们能够清晰段看到。事实上synchronized映射成字节码指令就是添加来两个指令:monitorenter和monitorexit。
当一条线程进行运行的遇到monitorenter指令的时候,它会去尝试获得锁。假设获得锁那么锁计数+1(为什么会加一呢,由于它是一个可重入锁,所以须要用这个锁计数推断锁的情况),假设没有获得锁,那么堵塞。当它遇到monitorexit的时候,锁计数器-1,当计数器为0。那么就释放锁。
那么有的朋友看到这里就疑惑了,那图上有2个monitorexit呀?立即回答这个问题:上面我曾经写的文章也有表述过,synchronized锁释放有两种机制,一种就是运行完释放;第二种就是发送异常。虚拟机释放。图中第二个monitorexit就是发生异常时运行的流程,这就是我开头说的“会有2个流程存在“。
并且,从图中我们也能够看到在第13行。有一个goto指令,也就是说假设正常运行结束会跳转到19行运行。
这下,你对synchronized是不是了解的非常清晰了呢。接下来我们再聊一聊Lock。
Lock:Lock实现和synchronized不一样。后者是一种悲观锁,它胆子非常小,它非常怕有人和它抢吃的,所以它每次吃东西前都把自己关起来。
而Lock呢底层事实上是CAS乐观锁的体现,它无所谓。别人抢了它吃的,它又一次去拿吃的就好啦,所以它非常乐观。具体底层怎么实现,博主不在细述。有机会的话。我会对concurrent包以下的机制好好和大家说说,假设面试问起。你就说底层主要靠volatile和CAS操作实现的。
如今,才是我真正想在这篇博文后面加的,我要说的是:尽可能去使用synchronized而不要去使用LOCK
什么概念呢?我和大家打个比方:你叫jdk,你生了一个孩子叫synchronized,后来呢,你领养了一个孩子叫LOCK。起初。LOCK刚来到新家的时候,它非常乖,非常懂事。各个方面都表现的比synchronized好。
你非常开心,可是你内心深处又有一点淡淡的忧伤。你不希望你自己亲生的孩子居然还不如一个领养的孩子乖巧。这个时候,你对亲生的孩子教育更加深刻了。你想证明。你的亲生孩子synchronized并不会比领养的孩子LOCK差。(博主仅仅是打个比方)
那怎样教育呢?
在jdk1.6~jdk1.7的时候,也就是synchronized16、7岁的时候。你作为爸爸,你给他优化了,具体优化在哪里呢:
(1)线程自旋和适应性自旋
我们知道。java’线程事实上是映射在内核之上的。线程的挂起和恢复会极大的影响开销。
并且jdk官方人员发现,非常多线程在等待锁的时候。在非常短的一段时间就获得了锁,所以它们在线程等待的时候,并不须要把线程挂起,而是让他无目的的循环。一般设置10次。这样就避免了线程切换的开销,极大的提升了性能。
而适应性自旋,是赋予了自旋一种学习能力。它并不固定自旋10次一下。
他能够根据它前面线程的自旋情况,从而调整它的自旋,甚至是不经过自旋而直接挂起。
(2)锁消除
什么叫锁消除呢?就是把不必要的同步在编译阶段进行移除。
那么有的小伙伴又迷糊了,我自己写的代码我会不知道这里要不要加锁?我加了锁就是表示这边会有同步呀?
并非这样。这里所说的锁消除并不一定指代是你写的代码的锁消除,我打一个比方:
在jdk1.5曾经。我们的String字符串拼接操作事实上底层是StringBuffer来实现的(这个大家能够用我前面介绍的方法。写一个简单的demo,然后查看class文件里的字节码指令就清晰了),而在jdk1.5之后,那么是用StringBuilder来拼接的。
我们考虑前面的情况,比方例如以下代码:
String str1="qwe";
String str2="asd";
String str3=str1+str2;
底层实现会变成这样:
StringBuffer sb = new StringBuffer();
sb.append("qwe");
sb.append("asd");
我们知道。StringBuffer是一个线程安全的类。也就是说两个append方法都会同步。通过指针逃逸分析(就是变量不会外泄),我们发如今这段代码并不存在线程安全问题。这个时候就会把这个同步锁消除。
(3)锁粗化
在用synchronized的时候,我们都讲究为了避免大开销,尽量同步代码块要小。那么为什么还要加粗呢?
我们继续以上面的字符串拼接为例,我们知道在这一段代码中,每个append都须要同步一次。那么我能够把锁粗化到第一个append和最后一个append(这里不要去纠结前面的锁消除。我仅仅是打个比方)
(4)轻量级锁
(5)偏向锁
关于最后这两种,我希望留个有缘的读者自己去查找,我不希望我把一件事情描写叙述的那么具体,自己动手得到才是你自己的,博主能够告诉你的是。最后两种并不难。
。加油吧,各位。
12、悲观锁,乐观锁。行锁,表锁,页锁,共享锁。排他锁
悲观锁:
顾名思义,非常悲观,就是每次拿数据的时候都觉得别的线程会改动数据,所以在每次拿的时候都会给数据上锁。上锁之后,当别的线程想要拿数据时。就会堵塞。直到给数据上锁的线程将事务提交或者回滚。传统的关系型数据库里就用到了非常多这样的锁机制,比方行锁。表锁。共享锁,排他锁等,都是在做操作之前先上锁。
行锁:
以下演示行锁,打开两个mysql命令行界面。两个线程分别运行例如以下操作:(左边先运行)
x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMzNTkxOTAz,size_27,color_FFFFFF,t_70" width="901" />
左边的线程,在事务中通过select for update语句给sid = 1的数据行上了锁。右边的线程此时能够使用select语句读取数据,可是假设也使用select for update语句,就会堵塞,使用update。add,delete也会堵塞。
当左边的线程将事务提交(或者回滚),右边的线程就会获取锁,线程不再堵塞:
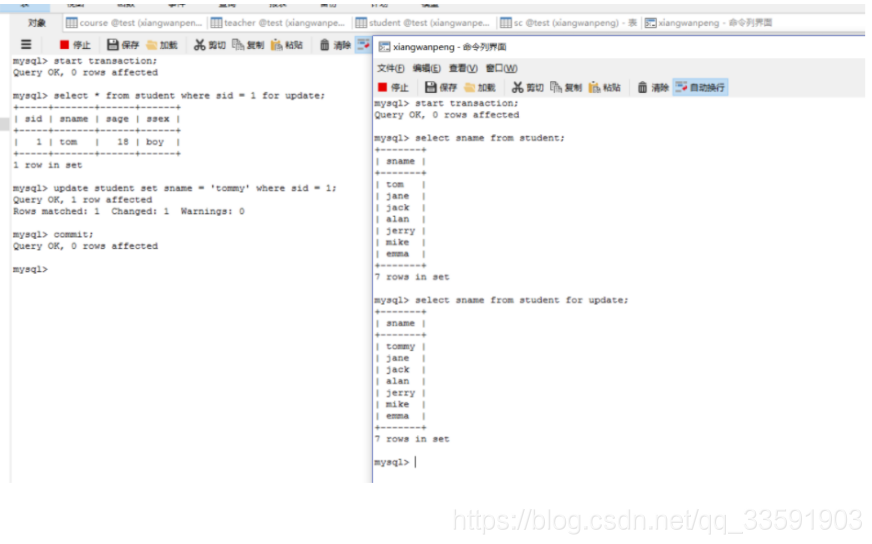
此时,右边的线程获取锁。左边的线程假设运行相似操作,也会被堵塞:
x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMzNTkxOTAz,size_27,color_FFFFFF,t_70" width="897" />
表锁:
上述样例中,假设使用例如以下语句就是使用的表锁:
select * from student for update;
页锁:
行锁锁指定行。表锁锁整张表。页锁是折中实现。即一次锁定相邻的一组记录。
共享锁:
共享锁又称为读锁,一个线程给数据加上共享锁后,其它线程仅仅能读数据,不能改动。
排他锁:
排他锁又称为写锁。和共享锁的差别在于。其它线程既不能读也不能改动。
乐观锁:
乐观锁事实上不会上锁。顾名思义。非常乐观,它默认别的线程不会改动数据,所以不会上锁。
仅仅是在更新前去推断别的线程在此期间有没有改动数据。假设改动了。会交给业务层去处理。
经常使用的实现方式是使用版本号戳,比如在一张表中加入一个整型字段version,每更新version++,比方某个时刻version=1,线程A读取了此version=1,线程B也读取了此version=1,当线程A更新数据之前,推断version仍然为1。更新成功。version++变为2。可是当线程B再提交更新时,发现version变为2了,与之前读的version=1不一致,就知道有别的线程更新了数据,这个时候就会进行业务逻辑的处理。
通常情况下,写操作较少时,使用乐观锁,写操作较多时,使用悲观锁。
【JAVA面试】java面试题整理(4)的更多相关文章
- Java面试,面试题
Java面试,面试题 HashMap,HashTable,ConcurrentHash的共同点和区别 HashMap HashTable ConcurrentHashMap ArrayList和Lin ...
- Java面试——多线程面试题总结
)两者都在等待对方所持有但是双方都不释放的锁,这时便会一直阻塞形成死锁. //存放两个资源等待被使用 public class Resource { public static Object obj1 ...
- 关于初级java面试问题的一些整理 (部分转自他人)
1.面向对象的特征有哪些方面 1.抽象: 抽象就是忽略一个主题中与当前目标无关的那些方面,以便更充分地注意与当前目标有关的方面.抽象并不打算了解全部问题,而只是选择其中的一部分,暂时不用部 ...
- 125条常见的java面试、笔试题大汇总
1.抽象: 抽象就是忽略一个主题中与当前目标无关的那些方面,以便更充分地注意与当前目标有关的方面.抽象并不打算了解所有问题,而仅仅是选择当中的一部分,临时不用部分细节.抽象包含两个方面,一是过程抽象. ...
- Java常考面试题整理(一)
1.什么是java虚拟机?为什么java被称作是"平台无关的编程语言". 参考答案: java虚拟级是一个可以执行java字节码的虚拟机进程,java源文件被编译成能被java虚拟 ...
- JAVA面试-java虚拟机
1.JVM简析: 作为一名Java使用者,掌握JVM的体系结构也是很有必要的. 说起Java,我们首先想到的是Java编程语言,然而事实上,Java是一种技术,它由四方面组成:Ja ...
- 最近面试前端面试题整理(css部分)
对最近面试的面试题坐下总结: 一,css部分 1,html元素的垂直居中 答案: <div id="box"> <div> 测试 </div> ...
- 85道Java微服务面试题整理(助力2020面试)
微服务 面试题 1.您对微服务有何了解? 2.微服务架构有哪些优势? 3.微服务有哪些特点? 4.设计微服务的最佳实践是什么? 5.微服务架构如何运作? 6.微服务架构的优缺点是什么? 7.单片,SO ...
- java面试| 线程面试题集合
集合的面试题就不罗列了,基本上在深入理解集合系列已覆盖 「 深入浅出 」java集合Collection和Map 「 深入浅出 」集合List 「 深入浅出 」集合Set 这里搜罗网上常用线程面试题, ...
- Java面试中笔试题——Java代码真题,这些题会做,笔试完全可拿下!
大家好,我是上海尚学堂Java培训老师,以下这些Java笔试真题是上海尚学堂Java学员在找工作中笔试遇到的真题.现在分享出来,也写了参考答案,供大家学习借鉴.想要更多学习资料和视频请留言联系或者上海 ...
随机推荐
- tar 打包压缩
tar命令详解 -c: 建立压缩档案 -x:解压 -t:查看内容 -r:向压缩归档文件末尾追加文件 -u:更新原压缩包中的文件 这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用 ...
- MySQL Unable to convert MySQL datetime value to System.DateTime 解决方案
Unable to convert MySQL date/time value to System.DateTime 解决方案 这个问题发生在MySQL数据里面有Date类型数据,在C#中查询出来时候 ...
- 南阳236----心急的C小加
#include<cstdio> #include<algorithm> #define inf 1<<30 using namespace std; typede ...
- Redis自学笔记:3.3入门-散列类型
3.3散列类型 3.3.1介绍 散列类型不能嵌套其他数据类型,一个散列类型可以包含至多232-1个字段 散列类型适合存储对象:使用对象类别和ID构成键名,使用字段表示对象的数据, 而字段值则存储属性值 ...
- web前端知识大纲:系列三 html篇
web前端庞大而复杂的知识体系的组成:html.css和 javascript 三.HTML 1.BOM BOM 是 Browser Object Model的缩写,即浏览器对象模型,当一个浏览器页面 ...
- 【DWM1000】 code 解密3一ANCHOR RUN起来
int done = INST_NOT_DONE_YET; #define INST_DONE_WAIT_FOR_NEXT_EVENT 1 //this signifies that the curr ...
- make、makefile、cmake、qmake对比
作者:玟清链接:https://www.zhihu.com/question/27455963/answer/36722992来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出 ...
- PAT Basic 1046
1046 划拳 (15 分) 划拳是古老中国酒文化的一个有趣的组成部分.酒桌上两人划拳的方法为:每人口中喊出一个数字,同时用手比划出一个数字.如果谁比划出的数字正好等于两人喊出的数字之和,谁就赢了,输 ...
- jmeter接口测试实例1-添加学生信息
jmeter实例1:添加学生信息 进入jmeter,添加线程组改名称为添加学生信息(为了好区分接口),添加http请求,输入IP,方法,路径,在body data中输入json串,同上面postman ...
- android面试题总结加强再加强版(一)
在加强版的基础上又再加强的android应用面试题集 有些补充略显臃肿,只为学习 1.activity的生命周期. 方法 描述 可被杀死 下一个 onCreate() 在activity第一次被创建的 ...