SVM笔记
1.前言
SVM(Support Vector Machine)是一种寻求最大分类间隔的机器学习方法,广泛应用于各个领域,许多人把SVM当做首选方法,它也被称之为最优分类器,这是为什么呢?这篇文章将系统介绍SVM的原理、推导过程及代码实践。
2.初识SVM
首先我们先来看看SVM做的是什么样的事,我们先看下面一张图
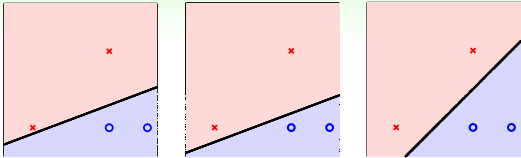
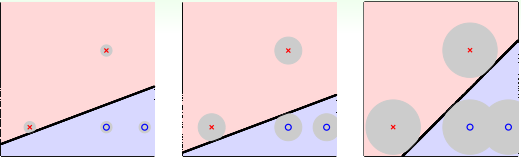
图中有三个分类实例,都将数据正确分类,我们直观上看,会觉得图中第三个效果会比较好,这是为什么呢?个人觉得人的直观感受更偏向于数据均匀对称的结构。当然,这只是直观感受,我们从专业的角度出发,第三种情况更优的原因在于它能容忍更多的数据噪声(tolerate more data noise),从而这个系统更加稳健(Robust),如下图所示,灰色的圈圈代表容忍噪声的大小门限,第三个门限最大,它比前面两个更优,而SVM就是寻求最大门限,构成分离数据正确且抗噪声强的稳健超平面(图中分类线是直线,一般数据维度是高维,对应的分类平面就是超平面)。
3.线性SVM
好了,现在我们知道SVM是那个抗噪声门限最大的超平面(一般说的是间隔margin最大,意思一样),那我们怎样找到这个超平面呢?我们先来分析,这个超平面需要满足那些条件:
- (1) 需要满足将数据都分类正确,以上图为例,超平面为\(w^Tx+b=0\),超平面以上的数据Label为+1,超平面以下的数据Label为-1,则分类正确需要满足\(y_n(w^Tx+b)>0\) ( \(y_n\)是数据Label )
- (2) 这个超平面关于数据集的最大间隔等于超平面到所有数据集中的样本点的距离的最小值,即\(margin(w,b)=\underset{n=1,\cdots,N}{min}distance(x_n,w,b)\)
根据上面的条件,我们可以对SVM建立一个最优化模型,目标是最大化间隔,但是这个最优化模型是有限制条件的,即上面提的两个条件.
\[\underset{w,b}{max} \space\space\space margin(w,b) \\ subject\ to\space\space\space every\space\space\ y_n(w^Tx+b)>0 \\ \space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space margin(w,b)=\underset{n=1,\cdots,N}{min}distance(x_n,w,b)
\]
这样看起来不知道怎么求,那我们现在再进一步地简化这个模型,先简化样本点到超平面的距离\(distance(x_n,w,b)\),先看下面这一张图
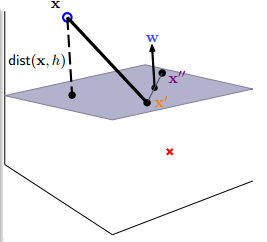
可以取超平面任意点\(x'\)和\(x''\),它们满足\(w^Tx'+b=0\)和\(w^Tx''+b=0\),将两式相减,得到\(w^T(x'-x'')=0\),这个说明什么呢?由于\(x'-x''\)表示平面上的任意向量,而\(w^T\)和它们点乘为0,说明\(w^T\)是这个平面的法向量,那距离就好办了,样本点\(x\)与超平面任一点\(x'\)组成向量,根据我们学过的数学知识知道,平面外一点到平面的距离等于改点与平面内任一点组成的向量点乘上法向量,然后除以法向量的模,即
\[distance(x_n,w,b)= \left|\frac{w^T(x_n-x')}{\left ||w\right||} \right|=\left | \frac{w^Tx_n+b}{\left ||w\right||} \right |= \frac { y_n(w^Tx_n+b)}{\left ||w\right||}
\]
现在,我们把得到的结果带到原来的模型当中去,得到一个简化模型
\[\underset{w,b}{max} \space\space\space margin(w,b) \\ subject\ to\space\space\space every\space\space\ y_n(w^Tx+b)>0 \\ \space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space margin(w,b)=\underset{n=1,\cdots,N}{min}\frac { y_n(w^Tx_n+b)}{\left ||w\right||}
\]
现在看看,好像这个模型还是挺复杂的,不知道怎么解,我们在来简化简化,\(\frac { y_n(w^Tx_n+b)}{\left ||w\right||}\)这一项是有些特别的,同倍放大\(w\)和\(b\),这项距离(书上一般写的是几何间隔)是不会变的,我们下面做出了一个强硬的化简:
\[\underset{n=1,\cdots,N}{min}\space\space\space y_n(w^Tx_n+b) = 1
\]
上面的表达式\(y_n(w^Tx_n+b)\)书上叫做函数间隔,为什么可以这样做呢?实际上我们求距离是用几何间隔,缩放函数间隔不影响几何间隔,举个例子吧,样本点\(x_1\)是离超平面最近的点,但是\(y_n(w^Tx_1+b)=3.24\),我们把\(w\)和\(b\)同时放缩3.24倍,\(y_n(w^Tx_1+b)=1\),几何间隔和以前没变的一样,因为上下是同时缩放的,我们再来看看超平面\(w^Tx_n+b=0\),也没什么变化,\(2x+2=0\)和\(x+1=0\)还是代表同一个超平面.这样缩放后,\(margin(w,b)=\frac {1}{\left ||w\right||}\),而且参数\(b\)不见了,可以去掉b好了,最小函数间隔为1,所以约束条件也发生了变化。这样简化后,我们再来看看模型变成啥样了
\[\underset{b,w}{max} \space\space\space \frac {1}{\left ||w\right||} \\ subject\ to\space\space\space every\space\space\ y_n(w^Tx_n+b)\geq1
\]
比之前看着简单多了吧,但是这样变换有没有问题呢?其实有一个充要转必要问题,不够直观,原始条件(充要问题)是\(y_n(w^Tx_n+b)>0\)和\(\underset{n=1,\cdots,N}{min} \space y_n(w^Tx_n+b)=1\),我们把它合起来了,变成\(y_n(w^Tx_n+b)\geq1\)(必要问题),后面这个条件其实没有前面两个条件严谨,后面条件不能保证最小值就等于\(1\),大于1也同样满足,但其实这里必要问题是等价于充要问题的,为什么呢?我们假设最优\((w_1,b_1)\)在\(y_n(w_1^Tx_n+b_1)=1.127\)上,满足\(y_n(w^Tx_n+b)\geq1\),可是我们可以找到更优的\((w_2,b_2)=(\frac{w_1}{1.127},\frac{b_1}{1.127})\),同样满足\(y_n(w^Tx_n+b)\geq1\),所以不管怎样,最优\((w,b)\)一定会在\(y_n(w^Tx_n+b)=1\)上,所以原问题是等价于简化后的模型的。
为了习惯表示,我们再把最大化问题转化成最小化问题(例如我们习惯用梯度下降法最小化代价函数一样),将\(\underset{w}{max} \space \frac {1}{\left ||w\right||}\)变成\(\underset{w}{min}\frac{1}{2}w^Tw\)(\(\left ||w\right||=\sqrt{w^Tw}\),这里去掉了根号和加了一个\(\frac{1}{2}\),加\(\frac{1}{2}\)是为了后面求导方便,不影响最优化问题),所以原模型也可以再进一步化简:
\[\underset{b,w}{min}\space \frac{1}{2}w^Tw \\ subject\ to\space\space\space \space\ y_n(w^Tx_n+b)\geq1\space for\space all \space n
\]
好了,我们已经得到非常精简的模型,那么我们现在该想想,要用什么方法去得到这个最优解呢?梯度下降法可不可以呢?好像不太适用,梯度下降法没有约束条件,那怎么办?幸运的是,这是一个二次规划(quadratic programming)问题,简称QP问题,QP问题需要符合两个条件:
- (1) 一个是目标函数是关于自变量的二次函数,而且函数需要是凸(convex)函数,显然,\(\frac{1}{2}w^Tw\)是二次函数,而且确实是凸函数。
- (2) 约束条件必须是关于自变量的线性约束条件,可以看出最后的模型约束条件确实是线性约束条件。
下面举个小例子 $$X=\left[ \begin{matrix}0 & 0\2 & 2 \2 & 0\3 & 0
\end{matrix}\right], y=\left[ \begin{matrix}-1 \-1 \1 \1\end{matrix}\right]$$
\(X\)是二维平面上的点,分别是\((0,0),(2,2),(2,0),(3,0)\),对应\(y\)中的\(label(-1,-1,1,1)\),现在用上面最优化的模型进行求解超平面,带入所有数据点,可得到如下限制条件:
\[ -b\geq1 \space\space\space\space(i)\\ -2w_1-2w_2-b\geq1\space\space\space\space(ii)\\
2w_1+b\geq1 \space\space\space\space(iii)\\
3w_1+b\geq1\space\space\space\space(iv)\]
结合(i)~(iv),得到\(w_1\geq1\)和\(w_2\leq-1\),从而得到\(\frac{1}{2}w^Tw=\frac{1}{2}(w_1^2+w_2^2)\geq1\),所以最优解\((w_1,w_2,b)=(1,-1,-1)\),最后可画出如下图像
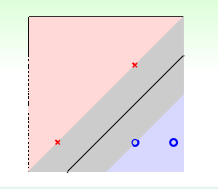
四个点我们算起来可能很容易,但40000个点呢,手算就不切实际了,自己编工作量太大,而且规范性差,还好,前辈们建立很多解优化问题的库,例如libsvm,cvxpy等等。一般求解二次规划函数都可以用以下格式表示:
\[optimal\space u\leftarrow QP(q,p,A,c) \\ \underset{u}{min} \space\space\space\space \frac{1}{2}u^TQu+p^Tu \\ subject\space to\space\space A^Tu\geq c_n \space\space for\space all\space samples
\]
将上面的模型带入这个优化函数,参数分别如下:
\[objective \space function: u = \left [ \begin{matrix}b\\w \end{matrix}\right ];Q=\left[\begin{matrix}0&0_d^T\\0_d&I_d\end{matrix}\right];p=\left[\begin{matrix}0_{d+1}\end{matrix}\right]\\constraints:A=y_n\left[\begin{matrix}1&x_n\end{matrix}\right];c_n=1
\]
下面用matlab(使用quadprog函数)和python(基于cvxpy)分别生成一个线性可分数据集的分类器
MATLAB版
% 实现线性可分SVM
clear all ; close all;
file = importdata('testSet.txt');
[m,n] =size(file);
x_1 = file(:,1);
x_2 = file(:,2);
y_n = file(:,3);
file_1 = sortrows(file,3);%根据第三列进行排序
CountNegative1 = sum(y_n==-1);
x_3 = file_1(1:CountNegative1,1); %当y_n 是-1的时候,存对应的x_1
x_4 = file_1(1:CountNegative1,2); %当y_n 是-1的时候,存对应的x_2
x_5 = file_1(CountNegative1+1:m,1); %当y_n 是1的时候,存对应的x_1
x_6 = file_1(CountNegative1+1:m,2); %当y_n 是1的时候,存对应的x_2
figure;
scatter(x_3,x_4,'red','fill');
hold on;
scatter(x_5,x_6,'blue','fill');
H = [0 0 0;0 1 0;0 0 1];
p = [0;0;0];
A = [ones(CountNegative1,1),file_1(1:CountNegative1,1:2);
-ones(m-CountNegative1,1),- file_1(CountNegative1+1:m,1:2)];
c = -ones(m,1);
u = quadprog(H,p,A,c); %求出参数[b,w]
x = linspace(2,8,400);
y = -(u(1)/u(3)+u(2)/u(3)*x);
plot(x,y,'green');
sv_index = find(abs(u'*[ones(m,1),file_1(:,1:2)]')-1<1e-5);
[m1,n1]=size(sv_index);
for i = 1:n1
x_sv =file_1(sv_index(i),1);
y_sv =file_1(sv_index(i),2);
plot(x_sv,y_sv,'o','Markersize',20);
end
这里程序不多讲,懂上面原理,理解程序还是挺简单的,函数不懂的请看MATLAB的帮助文档,这里用的testSet.txt其实是机器学习实战SVM一节的数据集(下载链接),最后运行的结果如下图所示(那些用圈圈圈起来的点叫支持向量Support vecter,是离超平面最近的点)
python版
import cvxpy as cvx
import numpy as np
f = open('testSet.txt')
X1_Neg1 = []
X1_Pos1 = []
X2_Neg1 = []
X2_Pos1 = []
constraints = []
for line in f.readlines():
lineSplit = line.strip().split('\t')
xAxis = float(lineSplit[0])
yAxis = float(lineSplit[1])
label = int(lineSplit[2])
if label == 1:
X1_Pos1.append(xAxis)
X2_Pos1.append(yAxis)
else:
X1_Neg1.append(xAxis)
X2_Neg1.append(yAxis)
u = cvx.Variable(3)
H = np.array([[0,0,0],[0,1,0],[0,0,1]])
objective = cvx.Minimize(1.0/2*cvx.quad_form(u,H))
for X_Pos1 in zip(X1_Pos1,X2_Pos1):
temp1 = np.zeros([3,1])
temp1[0] = 1
temp1[1] = X_Pos1[0]
temp1[2] = X_Pos1[1]
constraints.append(temp1.T*u >= 1)
for X_Neg1 in zip(X1_Neg1,X2_Neg1):
temp2 = np.zeros([3,1])
temp2[0] = 1
temp2[1] = X_Neg1[0]
temp2[2] = X_Neg1[1]
constraints.append(-(temp2.T*u) >= 1)
prob = cvx.Problem(objective,constraints)
prob.solve()
print('optimal var:\n\r',u.value)
这里图就不画了,和上面一样。
4.非线性SVM
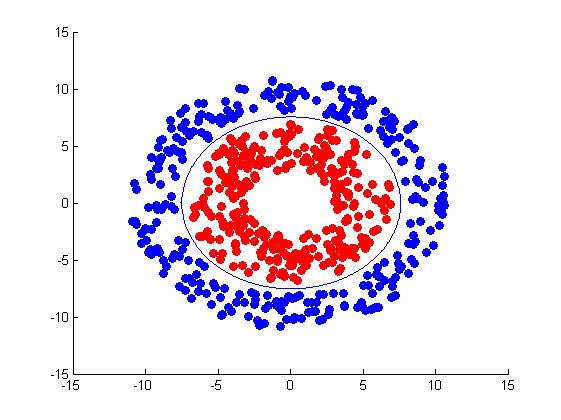
线性SVM是有很大的局限性的,并不是所有数据都能用线性SVM分类,以下图为例,你很难用线性SVM进行分类达到高准确,线性SVM最高只能达到75%准确度。
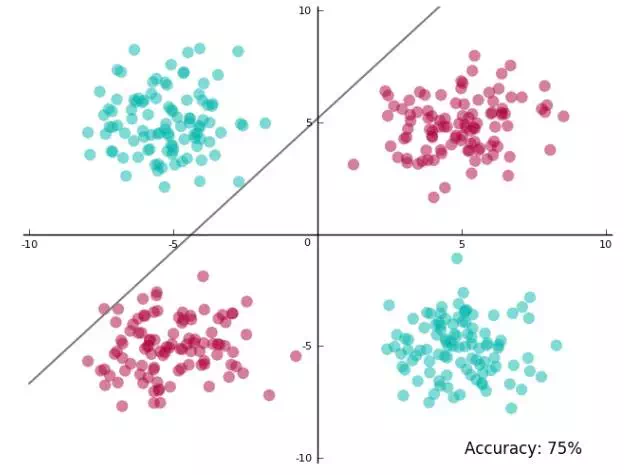
这时候就需要用到一个知识————特征转换(feature transform)
我们将二维数据映射到三维上,转换关系如下
\[X_1 = x_1^2 \\ X_2 = x_2^2 \\ X_3 = \sqrt{2}x_1x_2
\]
原始数据集分布就变成下图分布
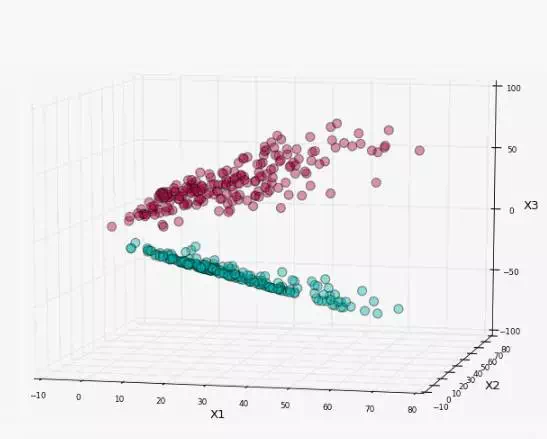
我们就可以在当前三维分布利用线性SVM进行分类,如图所示
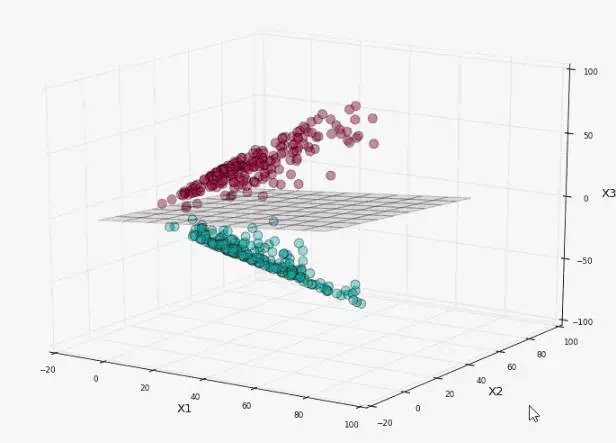
看起来分离得很好,我们再将平面映射回初始的二维空间中,看看决策边界时什么样子
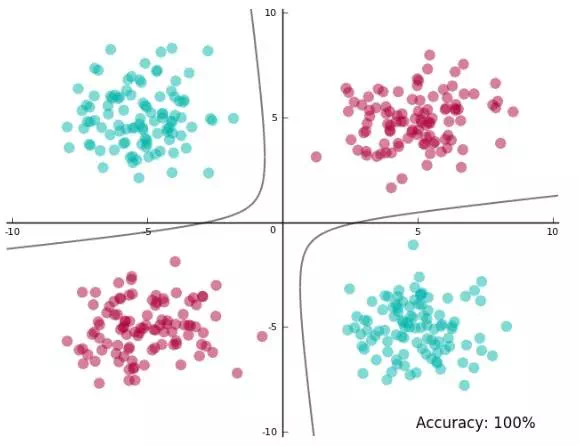
可以看到决策边界不是线性的了,还是两条歪曲的曲线构成的,这就是非线性SVM的一个典型例子,它将数据映射到更高维空间,然后在高维进行线性SVM,最后映射回到原来的状态,得到复杂的决策边界————曲面形(原因在于特征转换是非线性的,所以映射回来,高维线性变成低维非线性)。
我们再来看看非线性SVM模型
\[\underset{b,w}{min}\space \frac{1}{2}w^Tw \\ subject\ to\space\space\space \space\ y_n(w^T z_n+b)\geq1\space for\space all \space n
\]
这样看起来和线性SVM的模型一样,但其实有区别,约束条件中的\(z_n\)是\(x_n\)经过特征转换得到的,由于\(z_n\)是高维的,\(w\)也会发生相应的变化,具体要看\(z_n\)的维度(和\(z_n\)维度相同),我们利用优化库去解这个二次规划问题的方法和之前提到的线性SVM方法几乎一样,假设\(z_n\)的维度是\(\overset{\sim}{d}\),我们可以列出下面的表达式
- \(Q=\left[\begin{matrix}0&0_\overset{\sim}{d}^T\\0_\overset{\sim}{d}&I_\overset{\sim}{d}\end{matrix}\right];p=\left[\begin{matrix}0_{\overset{\sim}{d}+1}\end{matrix}\right]\\A=y_n\left[\begin{matrix}1&z_n^T\end{matrix}\right];c_n=1\)
- $optimal\space \left [ \begin{matrix}b\w \end{matrix}\right ]\leftarrow QP(Q,p,A,c) $
- \(g_{svm}(x)=sign(w^Tz_n+b)\)
看起来非线性SVM已经介绍完了,其实这里遗留了一个问题,我们现在的变量维度是\(\overset{\sim}{d}+1\),限制条件的个数为N(N为样本数),我们要特别注意这个\(\overset{\sim}{d}\),它的维度会非常高,以64x64x3的图片为例,它映射后的\(z_n\)是百万级的,这样\(w\)也是百万级的,这无疑是巨大的计算量,前辈们对这一问题,提出了一个非常好的解决方案————引入拉格朗日对偶,将原始问题转换对偶问题,从而极大简化了计算量
Original SVM \(\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\Longrightarrow\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\) Equivalent SVM
\(\overset{\sim}{d}+1\space Variables\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space N+1\space Variables\)
\(N\space\space\space\space constraints\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space N\space\space\space\space constraints\)
我们接下来来看看这个转换是如何做到的,首先这里要引入一个拉格朗日乘子法,将原始带有限制条件问题,转换成没有限制条件的问题,原始问题经过拉格朗日乘子法后,得到如下表达式(其中\(\alpha_n\)是拉格朗日乘子):
\[L(w,b,\alpha)=\underbrace{\frac{1}{2}w^Tw}_{objective}+\sum_{n=0}^N \alpha_n\underbrace{(1-y_n(w^Tz_n+b))}_{constraint}
\]
这样,原始问题就可以转化成求解\(\underset{b,w}{min}(\underset{all \space \alpha_n\geq0}{max}L(w,b,\alpha))\),那么为什么可以这样转换呢?我们可以先分析里面\(\underset{all \space \alpha_n\geq0}{max}L(w,b,\alpha)\)这一项,里面最大化的自变量只有\(\alpha_n\),我们现在可以分情况讨论了
- 如果\((w,b)\)使得\((1-y_n(w^Tz_n+b)>0\),由于是取最大值且\(\alpha_n\geq0\),那么\(\alpha_n(1-y_n(w^Tz_n+b)\)会趋近于无穷大,这样我们在最外层的最小化会将它淘汰掉(最小化无穷大没有意义)
- 如果\((w,b)\)使得\((1-y_n(w^Tz_n+b)<0\),那么\(\alpha_n(1-y_n(w^Tz_n+b)\)会趋近于0,我们的最大值就是\(\frac{1}{2}w^Tw\),这样外层最小化才可以进行.
- 所以这里\((1-y_n(w^Tz_n+b)<0\)是隐藏在最大化中,也就是原始约束条件并没有消失,只是换了一种方式。
好了,现在我们已经将原始问题转化成求解\(\underset{b,w}{min}(\underset{all \space \alpha_n\geq0}{max}L(w,b,\alpha))\),那我们在进行下一步地操作吧,我们知道对于任意\(\alpha'\),有$$\underset{b,w}{min}(\underset{all \space \alpha_n\geq0}{max}L(w,b,\alpha))\geq\underset{b,w}{min}L(w,b,\alpha')$$
这是因为最大值大于等于任意取值,然后我们再往右边加一个最大化,得
\]
加上后依然成立,这是因为最好的\(\alpha'\)也是任意中的一个。
然后,我们是可以把\(\geq\)换成\(=\),这是由于原问题满足以下三个条件
- 原问题是一个凸的二次规划问题
- 原问题是有解的
- 限制条件是线性约束条件
满足上面三个条件,就可以将\(\geq\)的弱对偶转换成\(=\)的强对偶,具体证明我也不清楚,这是前辈们推导出来了,知道就行了,好了,这就完成了拉格朗日对偶,如下
\]
我们接下来用对偶SVM来求解原问题,对偶SVM如下
\]
里面的最小化是没有约束条件的,约束条件在最大化上,于是我们可以取梯度为0来求极值,由\(\frac{\partial L(w,b,\alpha)}{\partial b}\)=0,得\(\sum_{n=1}^N\alpha_ny_n=0\),代入对偶SVM,化简得
\]
再由\(\frac{\partial L(w,b,\alpha)}{\partial w}\)=0,得\(w=\sum_{n=1}^N\alpha_ny_nz_n\),代入对偶SVM,化简得$$\underset{all\space\alpha_n\geq0,\sum_{n=1}N\alpha_ny_n=0,w=\sum_{n=0}N\alpha_ny_nz_n}{max}(-\frac{1}{2}{\left|\sum_{n=1}N\alpha_ny_nz_n\right|}2+\sum_{n=1}^N \alpha_n)$$
将上面的表达式再变换一下,得
\]
好了,到现在,我们终于把原始的\(\overset{\sim}{d}+1\space Variables\)转换成\(N+1\space Variables\)。
我们根据上面的推导知道,原始和对偶\(w,b,\alpha\)之间是满足一些条件的,Karush,Kuhn,Tucker三位科学家总结了它们之间的关系,包含四个条件:
primal-dual optimal(w,b,\(\alpha\))
(1) 原问题需满足\(y_n(w^Tx_n+b)\geq1\)
(2) 对偶问题\(\alpha_n\geq0\)
(3) 对偶问题最优解\(\sum_{n=1}^N\alpha_ny_n=0,w=\sum_{n=0}^N\alpha_ny_nz_n\)
(4) \(\alpha_n(1-y_n(w^Tx_n+b))\)=0
后人命名为KKT条件(Karush-Kuhn-Tucker,以三位科学家命名),根据KKT条件,我们就可以通过\(\alpha\)求解\((w,b)\),求\(w\)显而易见,这里说一下\(b\),根据KKT第四个条件,当\(\alpha\)的一个分量\(\alpha_j\)大于0时,对应的点必须满足\(1-y_n(w^Tx_n+b)=0\),从而可以求出\(b\)
下面进行代码实践
matlab版
%非线性SVM
clear all ; close all;
data = csvread('test_nonlinear_SVM.csv');
[m,n] = size(data);
figure;
scatter(data(1:300,1),data(1:300,2),'red','fill');
hold on;
scatter(data(301:600,1),data(301:600,2),'blue','fill');
%feature transfrom x3 = x1^2+x2^2(x1,x2不变)
data_z = [data(:,1),data(:,2),data(:,1).^2+data(:,2).^2,data(:,3)];
H = (kron(data_z(:,4),ones(1,3)).*data_z(:,1:3))*(data_z(:,1:3)'.*kron(data_z(:,4),ones(1,3))');
f = -ones(m,1);
A = -eye(m);
b = zeros(m,1);
Aeq = data_z(:,4)';
beq = 0;
alpha = quadprog(H,f,A,b,Aeq,beq);%每个参数的具体意义请参考quadprog函数
w = (alpha.*data_z(:,4))'*data_z(:,1:3);
b = -1-w*data_z(377,1:3)'; %第377个点的alpha大于0
x = linspace(-7.6,7.6,400);
y1 = sqrt((-(b+w(1)*x+w(3)*x.^2)/w(3))+((w(2)^2)/(4*w(3))))-w(2)/(2*w(3));
y2 = -sqrt((-(b+w(1)*x+w(3)*x.^2)/w(3))+((w(2)^2)/(4*w(3))))-w(2)/(2*w(3));
plot(x,y1);
plot(x,y2);
这里cmd markdown有一个高亮bug,代码单引号与markdown的单引号冲突,不用管,直接复制用就可以了,test_nonlinear_SVM.csv和生成它的matlab代码请在这个百度云链接下载,这里说一下y1和y2,我们知道决策边界是\(w^Tz+b=0\),而\(z=(x1,x2,x3)\),x1已经用linspace生成,画图,我们需要求x2,根据方程\(w^T(x1,x2,x1^2+x2^2)+b=0\),我们可以求出x2的两个解(即y1和y2),最后运行结果如下
import numpy as np
import cvxpy as cvx
tmp = np.loadtxt(open("test_nonlinear_SVM.csv","rb"),delimiter=',',skiprows=0)
X,Y = tmp[:,0:2],tmp[:,2]
X_z = np.array([X[:,0],X[:,1],X[:,0]**2+X[:,1]**2])
alpha = cvx.Variable(X.shape[0],1)
H = np.dot((X_z*np.kron(Y,np.ones([3,1]))).T,(X_z*np.kron(Y,np.ones([3,1]))))
f = -np.ones([X.shape[0],1])
objective = cvx.Minimize(1.0/2*cvx.quad_form(alpha,H)+cvx.sum_entries(cvx.mul_elemwise(f,alpha)))
constraints = [alpha>=0,cvx.sum_entries(cvx.mul_elemwise(Y,alpha))==0]
prob = cvx.Problem(objective,constraints)
prob.solve()
print('alpha_value:',alpha.value)
w = np.dot((np.array(alpha.value)*Y.reshape((X.shape[0],1))).T,X_z.T)
b = Y[np.argmax(alpha.value)]-np.dot(w,X_z[0:3,np.argmax(alpha.value)].reshape(3,1))
print('w:',w,'\r\n','b:',b)
图就不画了,和matlab的差不多,大家可以将结果与matlab的最优w和最优b进行比较
5.kernel SVM
核SVM的引入,将大大减少上面非线性SVM的计算量,我们知道,根据上面非线性SVM问题,需要计算\(Q=y_ny_mz_n^Tz_m\),而我们要注意一下,\(z_n\)的维度通常情况是远远大于\(x_n\)的维度的,甚至可以是无限大(上面实例为了简单,画图方便,差的维度看不太出来),当转换到非常高的维度时,\(z_nz_m\)的内积计算量会是非常大的,这时发现了一种新的方法,使用它,大大减少了计算量,这个方法叫核方法。
以二次多项式变换为例,原始\(x_n\)的维度是\(d\),变换后\(z_n\)的维度是\(d^2\)
$$zz^T=\phi(x)\phi(x')=1+\sum_{i=1}^dx_ix_i'+\sum_{i=1}^d\sum_{j=1}^dx_ix_jx_i'x_j'=1+\sum_{i=1}^dx_ix_i'+\sum_{i=1}^dx_ix_i'\sum_{j=1}^dx_jx_j'\\\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space=1+x^Tx'+(x^Tx')(x^Tx')$$我们发现这个表达式可以用原始$x_n$的内积表示,我们将这个问题简化成求原始$x_n$的内积,然后套上一个核函数,就得到转换后的$z_n$的内积(*计算量从原来的$\omicron(d^2)$转化成了$\omicron(d)$*),上面过程可以用下面一个表达式表示
$$zz^T=K_{\phi}(x,x')=1+x^Tx'+(x^Tx')(x^Tx')\]
所以
\(Q=y_ny_mK_{\phi}(x_n,x_m)\)
\(optimal\space b=y_s-w^Tz_s=y_s-(\sum_{n=1}^Na_ny_nz_n)z_s=y_s-\sum_{n=1}^Na_ny_n(K_{\phi}(z_n,z_s))\)
\(g_{svm}(x)=sign(\sum_{n=1}^Na_ny_n(K_{\phi}(x_n,x))+b)\)
一般的二次项核(更常用)可以表达为如下形式
![1.jpg-621.1kB][11]
通用**多项式核**可以如下表示
$$K_Q(x,x')=(\zeta+\gamma x^Tx')^Q\space with\space\zeta\geq0\space \gamma>0$$多项式核的优点
> (1)比线性核(xx')强大,限制更小
> (2)Q值具有强控制性
多项式核的缺陷
> (1)数值计算困难,$(\zeta+\gamma x^Tx')>1$时,$(\zeta+\gamma x^Tx')^Q$会非常大,当$(\zeta+\gamma x^Tx')<1$时,$(\zeta+\gamma x^Tx')^Q$会非常小,趋近于0
> (2)三个参数($\zeta,\gamma,Q$)很不好选
下面介绍**高斯核**,也叫RBF kernel,高斯核是可以表示无限维度的,下图是原理推导
![image_1c12bvfgn1rbj1svg1cjiok6alb22.png-74kB][12]
一般的高斯核可以表示为如下表达式$$K(x,x')=exp(-\gamma\|x-x'\|^2)$$高斯核的**优点**
> (1)比多项式核和线性核更强大
> (2)数值计算困难程度比多项式核小
> (3)只有一个参数,比较好选择
高斯核的**缺陷**
> (1)没有w(无限维度的原因)
> (2)运算速度比线性慢
> (3)太强大,容易过拟合,如下图
![image_1c12d9lfr1t64fsn1o1o1vvr8vn2f.png-57.4kB][13]
给定一个函数K,我们如何怎样判断它是否是一个有效的核函数呢?
给定m个训练样本$\{x^{(1)},x^{(2)},\cdots,x_{(m)}\}$,每一个$x^{(i)}$对应一个特征向量。那么,我们可以将任意两个$x^{(i)}$和$x^{(j)}$带入K中,计算得到。i可以从1到m,j可以从1到m,这样可以计算出m*m的核函数矩阵。如果假设K是有效地核函数,则有$$K_{ij}=K(x^{(i)},x^{(j)})=\phi(x^{(i)})^T\phi(x^{(j)})=\phi(x^{(j)})^T\phi(x^{(i)})=K(x^{(j)},x^{(i)})=K_{ji}$$可见,矩阵K一定是**对称**的矩阵。
下面来看看另一个条件,对于任意向量z,有
![image_1c12klkbqc0p1le532f7m1hlv2s.png-26.2kB][14]
由此知道矩阵K需要是**半正定**的,综合起来**K是有效的核函数 <==> 核函数矩阵K是对称半正定的。**
**python实践**(仅供参考,cvx.quad_form(alpha,Q)不遵守DCP,我用非线性SVM算出的Q没问题,这个就有问题,具体原因不清楚)
```python
import numpy as np
import h5py
import cvxpy as cvx
def load_dataset():
train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
for i in range(train_set_y_orig.shape[1]):
if(train_set_y_orig[0,i]==0):
train_set_y_orig[0,i]=-1
for i in range(test_set_y_orig.shape[1]):
if(test_set_y_orig[0,i]==0):
test_set_y_orig[0,i]=-1
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
def main():
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()
train_set_x_orig=train_set_x_orig.reshape((train_set_x_orig.shape[0],-1))
alpha = cvx.Variable(train_set_x_orig.shape[0],1)
f = -np.ones([train_set_x_orig.shape[0],1])
K2 = (np.ones([train_set_x_orig.shape[0],train_set_x_orig.shape[0]])+1.0/2*np.dot(train_set_x_orig,train_set_x_orig.T))**2
y_m=np.kron(train_set_y,np.ones([train_set_x_orig.shape[0],1]))
Q=np.array(y_m.T*K2*y_m)
objective = cvx.Minimize(1.0/2*cvx.quad_form(alpha,Q)+cvx.sum_entries(cvx.mul_elemwise(f,alpha)))
constraints = [alpha>=0,cvx.sum_entries(cvx.mul_elemwise(train_set_y.T,alpha))==0]
prob = cvx.Problem(objective,constraints)
prob.solve()
if __name__ == '__main__':
main()
```
## 6.软间隔SVM
有的时候,我们强行要把所有的样本点都分隔正确,会产生过拟合。如下图所示
![image_1c12lu9hdsph70edlgbu164s39.png-12kB][15]
这个时候,我们可以放低标准,容许分类器有一定的错误,像下图一样
![image_1c12m1iejsek1s0d6ak7131c0243.png-8.6kB][16]
这样做的好处是使分类器准确地泛化了样本的分布,这样的SVM分类器叫软间隔SVM,那么怎样实现它呢?
首先,我们需要对原始问题进行修改
![image_1c12o6sqp13gk1ahh1t4hcceoic9.png-34.3kB][17]
这里引入了变量C,它是用来平衡大间隔和容忍噪声的,C越大,对噪声容忍度越小,希望分类错误的点越少越好,反之,C越小,则希望我们的大间隔越大越好
将上面两个条件合起来,得到如下问题
![2.jpg-10.3kB][18]
但这里出现两个问题了,**一个是【$y_n\neq sign(w^Tz_n+b)$】非线性的**,这样导致这个问题不是QP问题,对偶和核函数都用不了,第二个是这样的问题**不能区分小错误和大错误**,比如,一个分类错误样本离边界0.001和离边界1000,这样分类器认为这两种是一样的,这显然也不合适。
于是,我们引入$\varepsilon_n$参数,表示**错误的点离间隔边界的距离**,用它替换条件中的【$y_n\neq sign(w^Tz_n+b)$】,这样限制条件变成了线性的,同时,最小化中的错误个数计数也被错误程度取代,问题也变成了QP问题,皆大欢喜!
**soft-margin SVM:**
$$\underset{b,w,\varepsilon_n}{min}\space \frac{1}{2}w^Tw+C\sum_{i=1}^N\varepsilon_n \\ subject\ to\space\space\space \space\ y_n(w^Tz_n+b)\geq1-\varepsilon_n\space and\space \varepsilon_n\geq0for\space all \space n\]
现在我们来看看这个QP问题的变量和条件,变量有\(\overset{\sim}{d}+1+N\)(\(w_n\)有\(\overset{\sim}{d}\),\(b\)有1个,\(\varepsilon_n\)有\(N\)个),限制条件有\(2N\)个
接下来就是用拉格朗日对偶来去掉\(\overset{\sim}{d}\),过程详细解说就不写了,原理和上面对偶SVM类似,这里附上过程
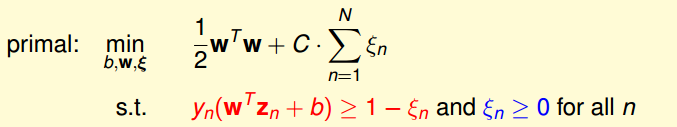
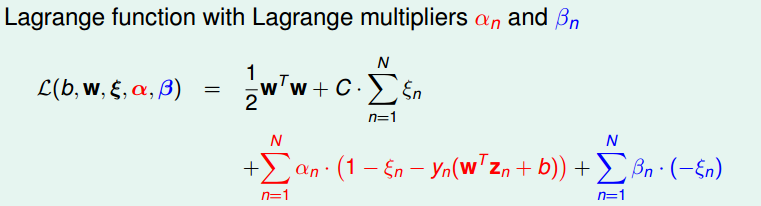

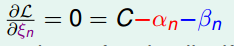
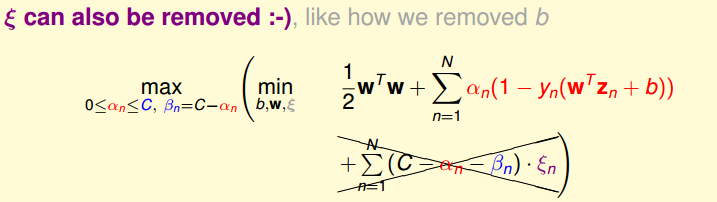

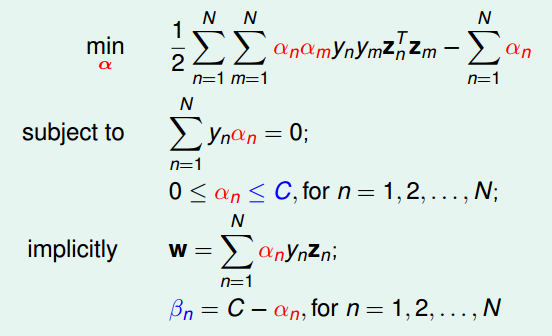
最后得到N个变量和2N+1个限制条件的QP问题。
参考:
1 林轩田——机器学习技法课程
2 http://blog.csdn.net/myarrow/article/details/51261971
SVM笔记的更多相关文章
- SVM 笔记整理
支持向量机 一.支持向量机综述 1.研究思路,从最特殊.最简单的情况开始研究 基本的线性的可分 SVM 解决二分类问题,是参数化的模型.定义类标记为 \(+1\) 和 \(-1\)(区别于感知机,感知 ...
- 机器学习支持向量机SVM笔记
SVM简述: SVM是一个线性二类分类器,当然通过选取特定的核函数也可也建立一个非线性支持向量机.SVM也可以做一些回归任务,但是它预测的时效性不是太长,他通过训练只能预测比较近的数据变化,至于再往后 ...
- Jordan Lecture Note-8: The Sequential Minimal Optimization Algorithm (SMO).
The Sequential Minimal Optimization Algorithm (SMO) 本文主要介绍用于解决SVM对偶模型的算法,它于1998年由John Platt在论文“Seque ...
- 机器学习实战笔记(Python实现)-05-支持向量机(SVM)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- SVM基本思想和对偶推导笔记-记录毕业论文1
快毕业啦~~记得上一篇论文利用JointBoost+CRF做手绘草图的分割项目在3月份完结后,6月份去实习,9月份也没怎么认真找工作就立刻回来赶论文(由于分割项目与人合作难以写入毕业论文),从9月到1 ...
- 机器学习技法--学习笔记04--Soft SVM
背景 之前所讨论的SVM都是非常严格的hard版本,必须要求每个点都被正确的区分开.但是,实际情况时很少出现这种情况的,因为噪声数据时无法避免的.所以,需要在hard SVM上添加容错机制,使得可以容 ...
- 机器学习实战 - 读书笔记(06) – SVM支持向量机
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第6章:SVM 支持向量机. 支持向量机不是很好被理解,主要是因为里面涉及到了许多数学知 ...
- opencv学习笔记(七)SVM+HOG
opencv学习笔记(七)SVM+HOG 一.简介 方向梯度直方图(Histogram of Oriented Gradient,HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子 ...
- [置顶] 最优间隔分类器、原始/对偶问题、SVM的对偶问题——斯坦福ML公开课笔记7
转载请注明:http://blog.csdn.net/xinzhangyanxiang/article/details/9774135 本篇笔记针对ML公开课的第七个视频,主要内容包括最优间隔分类器( ...
随机推荐
- 单点登录(SSO)原理与案例
单点登录业务流程 概要 详细流程 单点登录系统一共有三个模块,1.服务端 2.客户端 3.代理模块端 用户发送访问客户端的请求,被客户端的代理模块的拦截器拦截,判断cookie中是否含有token(令 ...
- Volatile 关键字 内存可见性
1.问题引入 实现线程: public class ThreadDemo implements Runnable { private boolean flag = false; @Override p ...
- AUTEL MaxiSys MS908S Pro MS908SP Diagnostic Platform
AUTEL MaxiSys MS908S Pro Description : One of the MaxiSys series devices, the MS908S Pro Diagnostic ...
- boost asio 学习(一)io_service的基础
原文 http://www.gamedev.net/blog/950/entry-2249317-a-guide-to-getting- started-with-boostasio/ 编译环境 b ...
- VBA找相似体积的单元格值
在VBA中做了一个比较体积,如果体积相似就显示隔壁单元格的内容 Function VC(a, b As Range) 'VolumeCompare体积比较 Dim arry() As Variant ...
- ABP框架系列之九:(Abp-Session-会话)
Introduction ASP.NET Boilerplate provides IAbpSession interface to obtain current user and tenant wi ...
- AJAX笔记整理
AJAX: Asynchronous JavaScript and XML,异步的Javascirpt和Xml. Asynchronous:异步 与之对应的是 synchronous:同步,我们要知道 ...
- 卷积在深度学习中的作用(转自http://timdettmers.com/2015/03/26/convolution-deep-learning/)
卷积可能是现在深入学习中最重要的概念.卷积网络和卷积网络将深度学习推向了几乎所有机器学习任务的最前沿.但是,卷积如此强大呢?它是如何工作的?在这篇博客文章中,我将解释卷积并将其与其他概念联系起来,以帮 ...
- Linux/unix 查看端口占用
有的时候我们想找到某个端口被那个程序.程序占用,然后 kill 掉他,所以今天就来探讨一下. 1.netstat -apn|grep port | 关键字(java/kafka/nginx) 图中所示 ...
- [UWP]在UWP平台中使用Lottie动画
最近QQ影音久违的更新了,因为记得QQ影音之前体验还算不错(FFmepg的事另说),我也第一时间去官网下载体验了一下,结果发现一些有趣的事情. 是的,你没看错,QQ影音主界面上这个动画效果是使用Lot ...