JStorm-介绍
1.概述
JStorm 是一个类似于 Hadoop 的MapReduce的计算系统,它是由Alibaba开源的实时计算模型,它使用Java重写了原生的Storm模型(Clojure和Java混合编写的),并且再原来的基础上做了许多改进。用户只需按照指定的接口实现一个任务,然后将这个任务提交给JStorm系统,JStorm在接受了任务指令后,会无间断运行任务,一旦出现异常导致某个Worker发送故障,调度器立刻会分配一个新的Worker去顶替异常的Worker。下面是本次分享的目录结构:
- 应用场景
- 基本术语
- JStorm比较
- JStorm架构
- 总结
下面开始今天的内容分享。
2.应用场景
从应用的角度来说,JStorm它是一种分布式的应用;从系统层面来说,它又类似于MapReduce这样的调度系统;而从数据方面来说,它又是一种基于流水数据的实时处理解决方案。如今,DT时代的当下,用户和企业也不仅仅只满足于离线数据,对于数据的实时性要求也越来越高了。
在早期,Storm和JStorm未问世之前,业界有很多实时计算系统,可谓百家争鸣,自Storm和JStorm出世之后,基本这两者占据主要地位,原因如下:
- 易开发:接口简单,上手容易,只需要按照Spout,Bolt以及Topology的编程规范即可开发一个扩展性良好的应用,底层的细节我们可以不用去深究其原因。
- 扩展性:可线性扩展性能。
- 容错:当Worker异常或挂起,会自动分配新的Worker去工作。
- 数据精准:其包含Ack机制,规避了数据丢失的风险。使用事物机制,提高数据精度。
JStorm处理数据的方式流程是基于流式处理,因此,我们会用它做以下处理:
- 日志分析:从收集的日志当中,统计出特定的数据结果,并将统计后的结果持久化到外界存储介质中,如:DB。当下,实时统计主流使用JStorm和Storm。
- 消息转移:将接受的消息进行Filter后,定向的存储到另外的消息中间件中。
3.基本术语
3.1 Stream
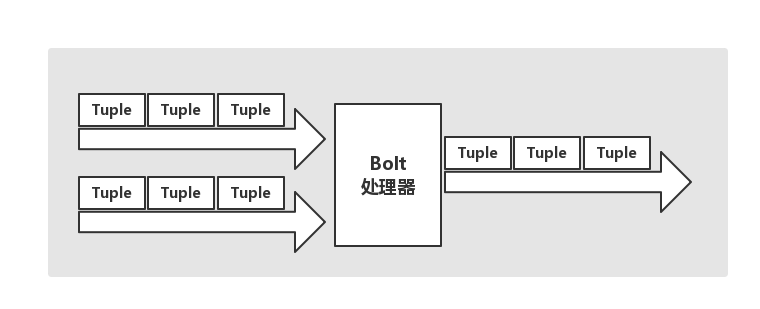
在JStorm当中,有对Stream的抽象,它是一个不间断的无界的连续Tuple,而JStorm在建模事件流时,把流中的事件抽象未Tuple,流程如下图所示:
3.2 Spout和Bolt
在JStorm中,它认为每个Stream都有一个Stream的来源,即Tuple的源头,所以它将这个源头抽象为Spout,而Spout可能是一个消息中间件,如:MQ,Kafka等。并不断的发出消息,也可能是从某个队列中不断读取队列的元数据。
在有了Spout后,接下来如何去处理相关内容,以类似的思想,将JStorm的处理过程抽象为Bolt,Bolt可以消费任意数量的输入流,只要将流方向导到该Bolt即可,同时,它也可以发送新的流给其他的Bolt使用,因而,我们只需要开启特定的Spout,将Spout流出的Tuple导向特定的Bolt,然后Bolt对导入的流做处理后再导向其它的Bolt等。
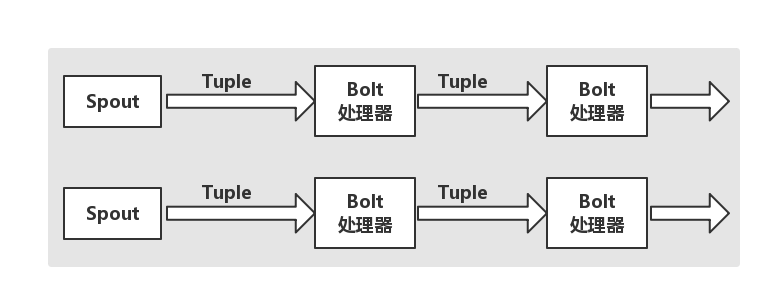
那么,通过上述描述,其实,我们可以用一个形象的比喻来理解这个流程。我们可以认为Spout就是一个个的水龙头,并且每个水龙头中的水是不同的,我们想要消费那种水就去开启对应的水龙头,然后使用管道将水龙头中的水导向一个水处理器,即Bolt,水处理器处理完后会再使用管道导向到另外的处理器或者落地到存储介质。流程如下图所示:
3.3 Topology
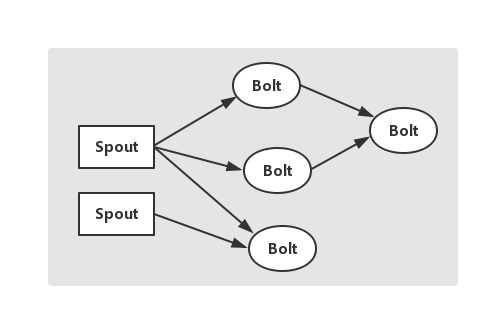
如图所示,这是一个有向无环图,JStorm将这个图抽象为Topology,它是JStorm中最高层次的一个抽象概念,它可以处理代码层面当中直接于JStorm打交道的,可以被提交到JStorm集群执行对应的任务,一个Topology即为一个数据流转换图,图中的每个节点是一个Spout或者Bolt,当Spout或Bolt发送Tuple到流时,它就发送Tuple到每个订阅了该流的Bolt上。
3.4 Tuple
JStorm当中将Stream中数据抽象为了Tuple,一个Tuple就是一个Value List,List值的每个Value都有一个Name,并且该Value可以是基本类型,字符类型,字节数组等,当然也可以是其它可序列化的类型。Topology的每个节点都要说明它所发射出的Tuple的字段的Name,其它节点只需要订阅该Name就可以接收处理相应的内容。
3.5 Worker和Task
Work和Task在JStorm中的职责是一个执行单元,一个Worker表示一个进程,一个Task表示一个线程,一个Worker可以运行多个Task。而Worker可以通过setNumWorkers(int workers)方法来设置对应的数目,表示这个Topology运行在多个JVM(PS:一个JVM为一个进程,即一个Worker);另外setSpout(String id, IRichSpout spout, Number parallelism_hint)和setBolt(String id, IRichBolt bolt,Number parallelism_hint)方法中的参数parallelism_hint代表这样一个Spout或Bolt有多少个实例,即对应多少个线程,一个实例对应一个线程。
3.6 Slot
在JStorm当中,Slot的类型分为四种,他们分别是:CPU,Memory,Disk,Port;与Storm有所区别(Storm局限于Port)。一个Supervisor可以提供的对象有:CPU Slot、Memory Slot、Disk Slot以及Port Slot。
- 在JStorm中,一个Worker消耗一个Port Slot,默认一个Task会消耗一个CPU Slot和一个Memory Slot
- 在Task执行较多的任务时,可以申请更多的CPU Slot
- 在Task需要更多的内存时,可以申请更多的额Memory Slot
- 在Task磁盘IO较多时,可以申请Disk Slot
4.JStorm比较
当前JStorm已经更新到2.x版本了,较于Storm而言,JStorm在一个Nimbus宕机后,会自动的热切到备份的Nimbus,实现了HA特性。对比与其它的数据产品而言,如下所示:
- Flume:一个成熟的产品,目前很多企业的日志收集系统均基于此套件开发,可以将数据收集后做一些计算与分析。
- S4:它是一个通用的,可扩展的,分布式的,容错,可插拔的平台,使程序员可以很容易地开发用于处理无界的连续数据流应用。数据准确性较差,数据丢失的风险无法规避,导致其发展不是很迅速,社区活跃度不够高。
- AKKA:一个Actor模型,系统模型强大,可以做任何你想做的时,当时很多工作都需要自己亲自动手去实现,如序列化、Topology的生成等。
- Spark:基于内存计算的MapReduce模型,偏重于数据批量处理。
5.JStorm架构
从设计层面来说,JStorm是一个典型的调度系统。在这个系统中,有以下内容:
| 角色 | 作用 |
| Nimbus | 调度器 |
| Supervisor | Worker的代理角色,负责Kill掉Worker和运行Worker |
| Worker | Task的容器 |
| Task | 任务的执行者 |
| ZooKeeper | 系统的协调者 |
其整体架构图,如下所示:

6.总结
本篇博客给大家分享了JStorm的相关内容,其中包含一些基本概念,与Storm的区别,它的架构图等内容,后续会大家介绍如何去部署JStorm的相关内容,以及它的编程方式,API的用法等内容会用一些案例给大家去一一的赘述。
7.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
JStorm-介绍的更多相关文章
- 在虚拟机搭建JStrom
原文:http://blog.csdn.net/u014134180/article/details/51810311 一 安装步骤 二 搭建Zookeeper集群 1 ZooKeeper 单机安装与 ...
- JStorm中的并行( parallelismction )介绍
JStorm中的并行( parallelismction )介绍 JStrom中.一个计算任务通过多台机器使得计算分解为多个独立并行执行在集群内执行的任务(tasks).从而得到水平扩展. JStor ...
- JStorm之Nimbus简介
本文导读: ——JStorm之Nimbus简介 .简介 .系统框架与原理 .实现逻辑和代码剖析 )Nimbus启动 )Topology提交 )任务调度 )任务监控 .结束语 .参考文献 附:JStor ...
- Storm和JStorm(阿里的流处理框架)
本文导读: 1.What——JStorm是什么? 1.1 概述 .2优点 .3应用场景 .4JStorm架构 2.Why——为什么启动JStorm项目?(与storm的区别) .1storm的现状.缺 ...
- JStorm第一个程序WordCount详解
一.Strom基本知识(回顾) 1,首先明确Storm各个组件的作用,包括Nimbus,Supervisor,Spout,Bolt,Task,Worker,Tuple nimbus是整个storm任务 ...
- jstorm简介(转)
Jstorm是参考storm的实时流式计算框架,在网络IO.线程模型.资源调度.可用性及稳定性上做了持续改进,已被越来越多企业使用 作为commiter和user,我还是非常看好它的应用前景,下面是在 ...
- 流式计算-Jstorm提交Topology过程(上)
Topology是Jstorm对有向无环图的抽象,内部封装了数据来源spout和数据处理单元bolt,以及spout和bolt.bolt和bolt之间的关系.它能够被提交到Jstorm集群. 本文以J ...
- Jstorm调度定制化接口(0.9.5 及高版本)
从JStorm 0.9.0 开始, JStorm 提供非常强大的调度功能, 基本上可以满足大部分的需求. 在学习如何使用新调度前, 麻烦先学习 JStorm 0.9.0介绍 提供哪些功能 接口 设置每 ...
- StreamCQL编写jstorm拓扑任务入门
一,什么是 StreamCQL StreamCQL(Stream Continuous Query Language)是一个类似SQL的声明式语言, 目的是在流计算平台(目前也就是jstrom)的基础 ...
随机推荐
- 【转载】Sql Server参数化查询之where in和like实现详解
文章导读 拼SQL实现where in查询 使用CHARINDEX或like实现where in 参数化 使用exec动态执行SQl实现where in 参数化 为每一个参数生成一个参数实现where ...
- android 设置LOGO和app名称
mipmap和drawable目录都可以存放图片,一般情况下,将LOGO文件存放在mipmap目录,普通图片放到drawable目录. 一.在mipmap目录添加LOGO图片 在mipmap目录右键- ...
- wince sqlite c#
无法找到 PInvoke DLL“SQLite.Interop.084.dll 按下面步骤操作
- 13. The Impact of New Technology on Business 新科技对商务的影响
13. The Impact of New Technology on Business 新科技对商务的影响 (1) New technology links the world as never b ...
- KeepAlived+Nginx 安装
yum install -y gcc gcc-c++ openssl openssl-devel 目前keepalived最新版本下载:[root@rhel ~]#wget -c http://www ...
- GitHub(从安装到使用)
一.安装Git for Windows(又名msysgit) 下载地址: https://git-for-windows.github.io/ 在官方下载完后,安装到Windows Explore ...
- poj3281构图题
题目大意:有F种食物,D种饮料N头奶牛,只能吃某种食物和饮料(而且只能吃特定的一份)一种食物被一头牛吃了之后,其余牛就不能吃了第一行有N,F,D三个整数接着2-N+1行代表第i头牛,前面两个整数是Fi ...
- java中的io系统详解
相关读书笔记.心得文章列表 Java 流在处理上分为字符流和字节流.字符流处理的单元为 2 个字节的 Unicode 字符,分别操作字符.字符数组或字符串,而字节流处理单元为 1 个字节,操作字节和字 ...
- JavaScript中的定时事件
这两个函数都是在给定的时间之后开始执行的,并不是立即执行. var timeId = window.setTimeout("method()",1000); //定时执行,还可以这 ...
- 《你不知道的javascript》读书笔记2
概述 放假读完了<你不知道的javascript>上篇,学到了很多东西,记录下来,供以后开发时参考,相信对其他人也有用. 这篇笔记是这本书的下半部分,上半部分请见<你不知道的java ...