通过Solr所提供的Dataimporthandler实现数据源的导入
如需要使用到Solr中的dataimporthandler增量导入功能,则还需要引入两个所依赖的jar包,在上一篇随笔中所提到的下载的Solr项目文件solr-4.10.3\dist目录下可以找到所依赖的两个jar包,即
将这两个jar包复制到我们本地Solr服务器下的WEB-INF\lib目录下,同时需在索引库中的conf目录下,添加data-config.xml配置文件
,data-config.xml则是用来配置数据源,dataimport.properties则是记录生成索引库的时间,该文件会在索引库数据创建完毕后,自动生成。
完成以上两步后,还有非常重要的一步就是,将dataimport-handler处理器与data-config.xml相结合的配置
在索引库中的conf目录下存有一个名为solrconfig.xml的配置文件,需要在该配置文件中添加以下配置文件
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
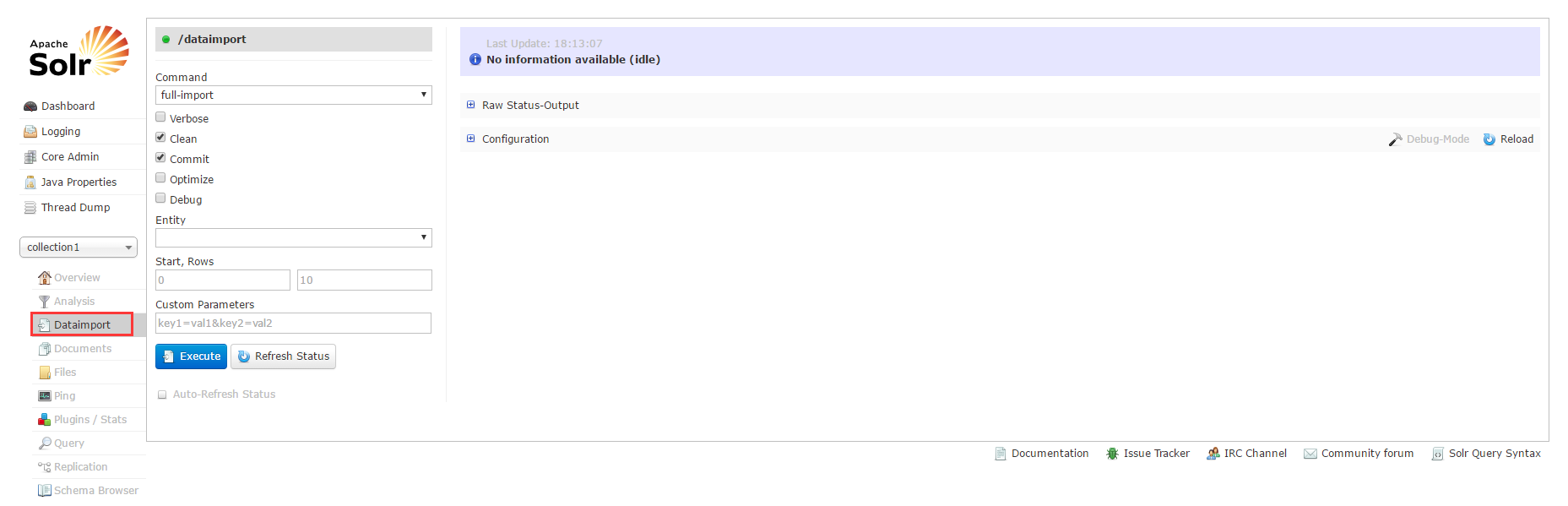
从而在Solr可视化管理页面中的Dataimport菜单中可以看到如下效果
接下来就是对data-config.xml文件与相匹配的schema.xml进行相应的配置,才能最终实现数据源的导入
data-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource driver="oracle.jdbc.driver.OracleDriver" url="jdbc:oracle:thin:@192.168.10.32:2016:sxlib" user="TT" password="TT"/>
<document> <entity name="CIP_Book" transformer="ClobTransformer" pk="GID" query="select cb.gid gid,
cb.gid bibGid,
decode(cb.bib_name,
null,
'未知',
regexp_replace(cb.bib_name, '[,|,|\|| | |\(|\)|\.|\[|\]|\+|-|!|\{|\}|^|~|\#|\?|:|;|&|]', '')) bibName,
decode(cb.author,
null,
'未知',
regexp_replace(cb.author, '[,|,|\|| | |\(|\)|\.|\[|\]|\+|-|!|\{|\}|^|~|\#|\?|:|;|&|]', '')) author,
decode(cb.pub_name, null, '未知', cb.pub_name) pubName,
ct.cre_date updatetime
from cip_bookinfo cb
join cip_bookdetail ct on cb.gid = ct.bib_gid" > <field column="gid" name="gid"/> <field column="bibGid" name="bibGid"/>
<field column="bibName" name="bibName"/>
<field column="author" name="author"/> <field column="updatetime" name="updateTime"/> </entity>
</document>
</dataConfig>在schema.xml中,Solr已经内置了很多field,但是为了符合开发需要,需要自定义符合自身需求的field,如在data-config.xml中,根据数据所查询出的书名、作者、出版社三个字段,那么在schema.xml则定义三个与之匹配的三个field,这样数据源的数据才能最终交予Solr进行管理
<field name="bibName" type="text_ik" indexed="true" stored="true"/>
<field name="author" type="text_ik" indexed="true" stored="true"/>
<field name="pubName" type="text_ik" indexed="true" stored="true"/>另外需要注意的是,根据数据源数据库的类型,导入对应的数据库依赖包。
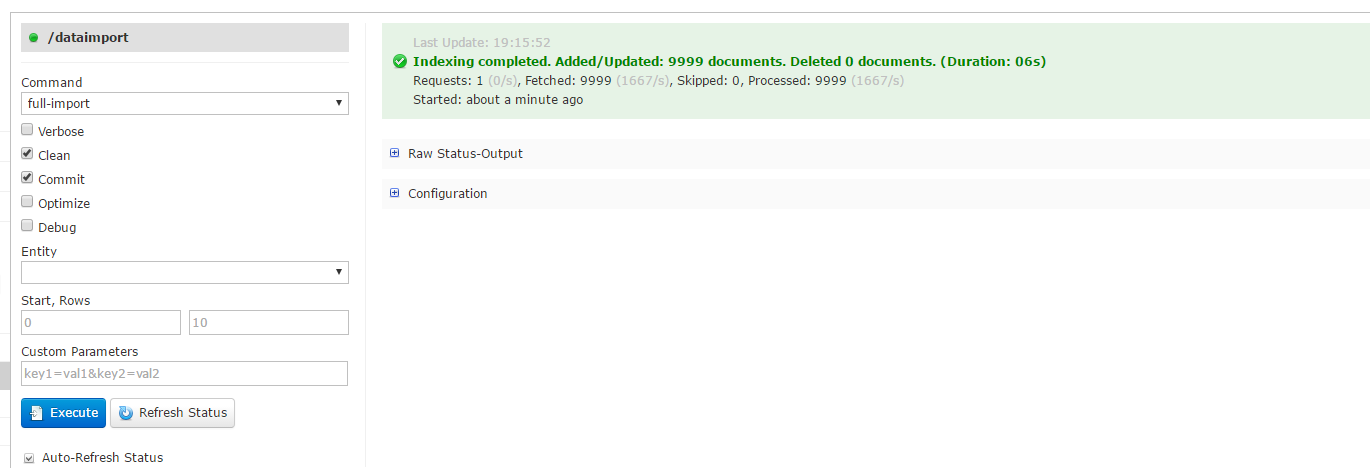
在Dataimport菜单页中点击Exceute,则会根据所配置好的数据源,实现数据导入
数据导入完毕后,通过Query菜单页可实现对数据的查询功能




通过Solr所提供的Dataimporthandler实现数据源的导入的更多相关文章
- [转]solr DataImportHandler 解决mysql 表导入内存溢出问题
最近一个项目要用到solr做全文检索,开始盲人摸象. 用tomcat 7 开始配置,开始正常,但是遇到cookie里有中文就报错. 无奈,换tomcat 6, 结果DataImportHandler ...
- solr搜索引擎配置使用mongodb作为数据源
环境说明: 操作系统:由于是使用的docker直接拉取的镜像部署的,系统是LINUX环境 mongodb: 4.0.3 solr: 7.5.0 python: 3.5 配置mongodb 1.拉取mo ...
- CDH离线数据导入solr:利用MapReduceIndexerTool将json文件批量导入到solr
场景描述:前段时间,将实时数据通过kafka+flume+morphline的方式接入到solr中.新进来的数据已经可以在solr中看到了,但是以前的历史数据还没有导入solr. CDH提供利用Map ...
- solr特点六: DIH (从数据源导入数据)
在这个结构化数据和非结构化数据的数量都很庞大的年代,经常需要从数据库.XML/HTML 文件或其他数据源导入数据,并使数据可搜索.过去,要编写自定义代码才能创建到数据库.文件系统或 RSS 提要的自定 ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
- solr与.net系列课程(三)solr连接数据库
solr与.net系列课程(三)solr连接数据库 上一章直接讲述的配置文件把大部分人看的很迷惑,大家都想听的是solr到底是怎么用的,好,这一节我们就开始链接数据库,首先讲一下连接之前都要配置哪些 ...
- 【转】Solr从数据库导入数据(DIH)
本文转自:http://blog.csdn.net/xiaoyu714543065/article/details/11849115 一. 数据导入(DataImportHandler-DIH) DI ...
- SOLR (全文检索)
SOLR (全文检索) http://sinykk.iteye.com/ 1. 什么是SOLR 官方网站 http://wiki.apache.org/solr http://wiki.apach ...
- solr连接数据库
solr与.net系列课程(三)solr连接数据库 solr与.net系列课程(三)solr连接数据库 上一章直接讲述的配置文件把大部分人看的很迷惑,大家都想听的是solr到底是怎么用的,好,这 ...
随机推荐
- Zookeeper 集群搭建--单机伪分布式集群
一. zk集群,主从节点,心跳机制(选举模式) 二.Zookeeper集群搭建注意点 1.配置数据文件 myid 1/2/3 对应 server.1/2/3 2.通过./zkCli.sh -serve ...
- 关于各种BUF源语的研究
关于各种BUF源语的研究 资料来源: 单端信号需要用到的BUF 关于这些源语的约束: 增大驱动电流 关于管脚的上拉与下拉约束: ODDR的两种操作模式 关于ODDR输出时钟的应用 为什么ODDR需要这 ...
- FPGA 中三角函数的实现
FPGA 中三角函数的实现
- Python模块hashlib
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等. 什么是摘要算法呢?摘要算法又称哈希算法.散列算法.它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制 ...
- docker容器内存占用 之 系统cache,docker下java的内存该如何配置
缘起: 监控(docker stats)显示容器内存被用完了,进入容器瞅了瞅,没有发现使用内存多的进程,使用awk等工具把容器所有进程使用的内存加起来看看,距离用完还远了去了,何故? 分析: 该不会d ...
- ArrayList add方法(转)
由于 BrowerList 输出结果都是最后一条记录,后来网上查到了 if (dRead.HasRows) { List<Class_RejectQuery> BrowerList = n ...
- 红外NEC协议
注意: 用示波器在接收头抓的电平看起来和NEC协议刚好相反, 那是因为:HS0038B 这个红外一体化接收头,当收到有载波的信号的时候,会输出一个低电平,空闲的时候会输出高电平. 具体情况,具体分析. ...
- RabbitMQ--windows10环境下的RabbitMQ安装步骤(转)
https://blog.csdn.net/weixin_39735923/article/details/79288578
- 格式化hdfs后,hadoop集群启动hdfs,namenode启动成功,datanode未启动
集群格式化hdfs后,在主节点运行启动hdfs后,发现namenode启动了,而datanode没有启动,在其他节点上jps后没有datanode进程!原因: 当我们使用hdfs namenode - ...
- echarts属性的设置(完整大全)
// 全图默认背景 // backgroundColor: ‘rgba(0,0,0,0)’, // 默认色板 color: ['#ff7f50','#87cefa','#da70d6','#32cd ...