Delta Lake在Soul的应用实践
简介: 传统离线数仓模式下,日志入库前首要阶段便是ETL,我们面临如下问题:天级ETL任务耗时久,影响下游依赖的产出时间;凌晨占用资源庞大,任务高峰期抢占大量集群资源;ETL任务稳定性不佳且出错需凌晨解决、影响范围大。为了解决天级ETL逐渐尖锐的问题,所以这次我们选择了近来逐渐进入大家视野的数据湖架构,基于阿里云EMR的Delta Lake,我们进一步打造优化实时数仓结构,提升部分业务指标实时性,满足更多更实时的业务需求。
一、背景介绍
(一)业务场景
传统离线数仓模式下,日志入库前首要阶段便是ETL,Soul的埋点日志数据量庞大且需动态分区入库,在按day分区的基础上,每天的动态分区1200+,分区数据量大小不均,数万条到数十亿条不等。下图为我们之前的ETL过程,埋点日志输入Kafka,由Flume采集到HDFS,再经由天级Spark ETL任务,落表入Hive。任务凌晨开始运行,数据处理阶段约1h,Load阶段1h+,整体执行时间为2-3h。

(二)存在的问题
在上面的架构下,我们面临如下问题:
1.天级ETL任务耗时久,影响下游依赖的产出时间。
2.凌晨占用资源庞大,任务高峰期抢占大量集群资源。
3.ETL任务稳定性不佳且出错需凌晨解决、影响范围大。
二、为什么选择Delta?
为了解决天级ETL逐渐尖锐的问题,减少资源成本、提前数据产出,我们决定将T+1级ETL任务转换成T+0实时日志入库,在保证数据一致的前提下,做到数据落地即可用。
之前我们也实现了Lambda架构下离线、实时分别维护一份数据,但在实际使用中仍存在一些棘手问题,比如:无法保证事务性,小文件过多带来的集群压力及查询性能等问题,最终没能达到理想化使用。
所以这次我们选择了近来逐渐进入大家视野的数据湖架构,数据湖的概念在此我就不过多赘述了,我理解它就是一种将元数据视为大数据的Table Format。目前主流的数据湖分别有Delta Lake(分为开源版和商业版)、Hudi、Iceberg,三者都支持了ACID语义、Upsert、Schema动态变更、Time Travel等功能,其他方面我们做些简单的总结对比:
开源版Delta
优势:
1.支持作为source流式读
2.Spark3.0支持sql操作
劣势:
1.引擎强绑定Spark
2.手动Compaction
3.Join式Merge,成本高
Hudi
优势:
1.基于主键的快速Upsert/Delete
2.Copy on Write / Merge on Read 两种merge方式,分别适配读写场景优化
3.自动Compaction
劣势:
1.写入绑定Spark/DeltaStreamer
2.API较为复杂
Iceberg
优势:
1.可插拔引擎
劣势:
1.调研时还在发展阶段,部分功能尚未完善
2.Join式Merge,成本高
调研时期,阿里云的同学提供了EMR版本的Delta,在开源版本的基础上进行了功能和性能上的优化,诸如:SparkSQL/Spark Streaming SQL的集成,自动同步Delta元数据信息到HiveMetaStore(MetaSync功能),自动Compaction,适配Tez、Hive、Presto等更多查询引擎,优化查询性能(Zorder/DataSkipping/Merge性能)等等
三、实践过程
测试阶段,我们反馈了多个EMR Delta的bug,比如:Delta表无法自动创建Hive映射表,Tez引擎无法正常读取Delta类型的Hive表,Presto和Tez读取Delta表数据不一致,均得到了阿里云同学的快速支持并一一解决。
引入Delta后,我们实时日志入库架构如下所示:
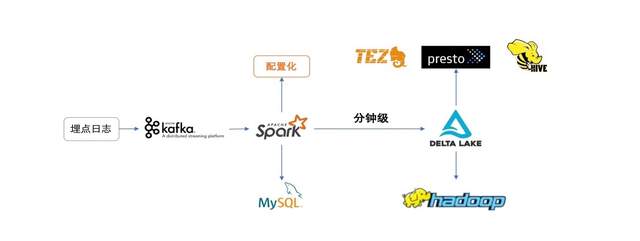
数据由各端埋点上报至Kafka,通过Spark任务分钟级以Delta的形式写入HDFS,然后在Hive中自动化创建Delta表的映射表,即可通过Hive MR、Tez、Presto等查询引擎直接进行数据查询及分析。
我们基于Spark,封装了通用化ETL工具,实现了配置化接入,用户无需写代码即可实现源数据到Hive的整体流程接入。并且,为了更加适配业务场景,我们在封装层实现了多种实用功能:
1. 实现了类似Iceberg的hidden partition功能,用户可选择某些列做适当变化形成一个新的列,此列可作为分区列,也可作为新增列,使用SparkSql操作。如:有日期列date,那么可以通过 'substr(date,1,4) as year' 生成新列,并可以作为分区。
2. 为避免脏数据导致分区出错,实现了对动态分区的正则检测功能,比如:Hive中不支持中文分区,用户可以对动态分区加上'\w+'的正则检测,分区字段不符合的脏数据则会被过滤。
3. 实现自定义事件时间字段功能,用户可选数据中的任意时间字段作为事件时间落入对应分区,避免数据漂移问题。
4. 嵌套Json自定义层数解析,我们的日志数据大都为Json格式,其中难免有很多嵌套Json,此功能支持用户选择对嵌套Json的解析层数,嵌套字段也会被以单列的形式落入表中。
5. 实现SQL化自定义配置动态分区的功能,解决埋点数据倾斜导致的实时任务性能问题,优化资源使用,此场景后面会详细介绍。
平台化建设:我们已经把日志接入Hive的整体流程嵌入了Soul的数据平台中,用户可通过此平台申请日志接入,由审批人员审批后进行相应参数配置,即可将日志实时接入Hive表中,简单易用,降低操作成本。
为了解决小文件过多的问题,EMR Delta实现了Optimize/Vacuum语法,可以定期对Delta表执行Optimize语法进行小文件的合并,执行Vacuum语法对过期文件进行清理,使HDFS上的文件保持合适的大小及数量。值得一提的是,EMR Delta目前也实现了一些auto-compaction的策略,可以通过配置来自动触发compaction,比如:小文件数量达到一定值时,在流式作业阶段启动minor compaction任务,在对实时任务影响较小的情况下,达到合并小文件的目的。
四、问题 & 方案
接下来介绍一下我们在落地Delta的过程中遇到过的问题
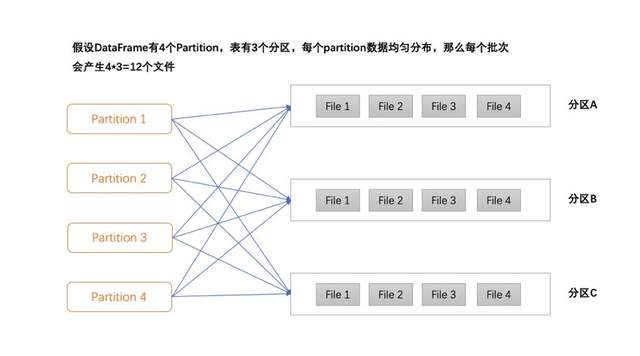
(一)埋点数据动态分区数据量分布不均导致的数据倾斜问题
Soul的埋点数据是落入分区宽表中的,按埋点类型分区,不同类型的埋点数据量分布不均,例如:通过Spark写入Delta的过程中,5min为一个Batch,大部分类型的埋点,5min的数据量很小(10M以下),但少量埋点数据量却在5min能达到1G或更多。数据落地时,我们假设DataFrame有M个partition,表有N个动态分区,每个partition中的数据都是均匀且混乱的,那么每个partition中都会生成N个文件分别对应N个动态分区,那么每个Batch就会生成M*N个小文件。
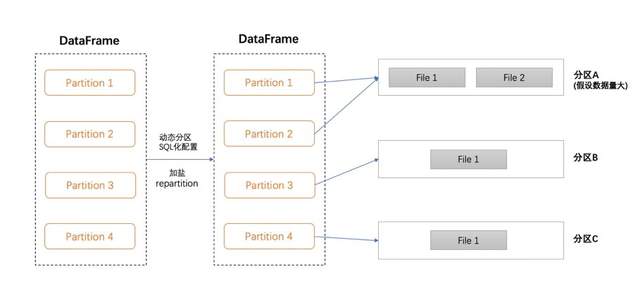
为了解决上述问题,数据落地前对DataFrame按动态分区字段repartition,这样就能保证每个partition中分别有不同分区的数据,这样每个Batch就只会生成N个文件,即每个动态分区一个文件,这样解决了小文件膨胀的问题。但与此同时,有几个数据量过大的分区的数据也会只分布在一个partition中,就导致了某几个partition数据倾斜,且这些分区每个Batch产生的文件过大等问题。
解决方案:如下图,我们实现了用户通过SQL自定义配置repartition列的功能,简单来说,用户可以使用SQL,把数据量过大的几个埋点,通过加盐方式打散到多个partition,对于数据量正常的埋点则无需操作。通过此方案,我们把Spark任务中每个Batch执行最慢的partition的执行时间从3min提升到了40s,解决了文件过小或过大的问题,以及数据倾斜导致的性能问题。
(二)应用层基于元数据的动态schema变更
数据湖支持了动态schema变更,但在Spark写入之前,构造DataFrame时,是需要获取数据schema的,如果此时无法动态变更,那么便无法把新字段写入Delta表,Delta的动态schena便也成了摆设。埋点数据由于类型不同,每条埋点数据的字段并不完全相同,那么在落表时,必须取所有数据的字段并集,作为Delta表的schema,这就需要我们在构建DataFrame时便能感知是否有新增字段。
解决方案:我们额外设计了一套元数据,在Spark构建DataFrame时,首先根据此元数据判断是否有新增字段,如有,就把新增字段更新至元数据,以此元数据为schema构建DataFrame,就能保证我们在应用层动态感知schema变更,配合Delta的动态schema变更,新字段自动写入Delta表,并把变化同步到对应的Hive表中。
(三)Spark Kafka偏移量提交机制导致的数据重复
我们在使用Spark Streaming时,会在数据处理完成后将消费者偏移量提交至Kafka,调用的是
spark-streaming-kafka-0-10中的commitAsync API。我一直处于一个误区,以为数据在处理完成后便会提交当前Batch消费偏移量。但后来遇到Delta表有数据重复现象,排查发现偏移量提交时机为下一个Batch开始时,并不是当前Batch数据处理完成后就提交。那么问题来了:假如一个批次5min,在3min时数据处理完成,此时成功将数据写入Delta表,但偏移量却在5min后(第二个批次开始时)才成功提交,如果在3min-5min这个时间段中,重启任务,那么就会重复消费当前批次的数据,造成数据重复。
解决方案:
1.StructStreaming支持了对Delta的exactly-once,可以使用StructStreaming适配解决。
2.可以通过其他方式维护消费偏移量解决。
(四)查询时解析元数据耗时较多
因为Delta单独维护了自己的元数据,在使用外部查询引擎查询时,需要先解析元数据以获取数据文件信息。随着Delta表的数据增长,元数据也逐渐增大,此操作耗时也逐渐变长。
解决方案:阿里云同学也在不断优化查询方案,通过缓存等方式尽量减少对元数据的解析成本。
(五)关于CDC场景
目前我们基于Delta实现的是日志的Append场景,还有另外一种经典业务场景CDC场景。Delta本身是支持Update/Delete的,是可以应用在CDC场景中的。但是基于我们的业务考量,暂时没有将Delta使用在CDC场景下,原因是Delta表的Update/Delete方式是Join式的Merge方式,我们的业务表数据量比较大,更新频繁,并且更新数据涉及的分区较广泛,在Merge上可能存在性能问题。
阿里云的同学也在持续在做Merge的性能优化,比如Join的分区裁剪、Bloomfilter等,能有效减少Join时的文件数量,尤其对于分区集中的数据更新,性能更有大幅提升,后续我们也会尝试将Delta应用在CDC场景。
五、后续计划
1.基于Delta Lake,进一步打造优化实时数仓结构,提升部分业务指标实时性,满足更多更实时的业务需求。
2.打通我们内部的元数据平台,实现日志接入->实时入库->元数据+血缘关系一体化、规范化管理。
3.持续观察优化Delta表查询计算性能,尝试使用Delta的更多功能,比如Z-Ordering,提升在即席查询及数据分析场景下的性能。
作者:张宏博,Soul大数据工程师
本文为阿里云原创内容,未经允许不得转载
Delta Lake在Soul的应用实践的更多相关文章
- Delta Lake源码分析
目录 Delta Lake源码分析 Delta Lake元数据 snapshot生成 日志提交 冲突检测(并发控制) delete update merge Delta Lake源码分析 Delta ...
- Delta Lake基础操作和原理
目录 Delta Lake 特性 maven依赖 使用aws s3文件系统快速启动 基础表操作 merge操作 delta lake更改现有数据的具体过程 delta表schema 事务日志 delt ...
- Apache Hudi vs Delta Lake:透明TPC-DS Lakehouse性能基准
1. 介绍 最近几周,人们对比较 Hudi.Delta 和 Iceberg 的表现越来越感兴趣. 我们认为社区应该得到更透明和可重复的分析. 我们想就如何执行和呈现这些基准.它们带来什么价值以及我们应 ...
- 李呈祥:bilibili在湖仓一体查询加速上的实践与探索
导读: 本文主要介绍哔哩哔哩在数据湖与数据仓库一体架构下,探索查询加速以及索引增强的一些实践.主要内容包括: 什么是湖仓一体架构 哔哩哔哩目前的湖仓一体架构 湖仓一体架构下,数据的排序组织优化 湖仓一 ...
- 初创电商公司Drop的数据湖实践
欢迎关注微信公众号:ApacheHudi 1. 引入 Drop是一个智能的奖励平台,旨在通过奖励会员在他们喜爱的品牌购物时获得的Drop积分来提升会员的生活,同时帮助他们发现与他们生活方式产生共鸣的新 ...
- 深度对比Apache CarbonData、Hudi和Open Delta三大开源数据湖方案
摘要:今天我们就来解构数据湖的核心需求,同时深度对比Apache CarbonData.Hudi和Open Delta三大解决方案,帮助用户更好地针对自身场景来做数据湖方案选型. 背景 我们已经看到, ...
- Apache Spark 3.0 预览版正式发布,多项重大功能发布
2019年11月08日 数砖的 Xingbo Jiang 大佬给社区发了一封邮件,宣布 Apache Spark 3.0 预览版正式发布,这个版本主要是为了对即将发布的 Apache Spark 3. ...
- 大数据分析常用去重算法分析『Bitmap 篇』
大数据分析常用去重算法分析『Bitmap 篇』 mp.weixin.qq.com 去重分析在企业日常分析中的使用频率非常高,如何在大数据场景下快速地进行去重分析一直是一大难点.在近期的 Apache ...
- BigData NoSQL —— ApsaraDB HBase数据存储与分析平台概览
一.引言 时间到了2019年,数据库也发展到了一个新的拐点,有三个明显的趋势: 越来越多的数据库会做云原生(CloudNative),会不断利用新的硬件及云本身的优势打造CloudNative数据库, ...
- 来自马铁大神的Spark10年回忆录
本篇分享来自Martei在Spark AI Submit 2020的开场分享. 马铁是谁 什么!你不知道马铁是谁?Martei Zaharia(说实话,不知道谁给起的中文名字叫马铁,跟着叫就是了),现 ...
随机推荐
- dotNet8 全局异常处理
前言 异常的处理在我们应用程序中是至关重要的,在 dotNet 中有很多异常处理的机制,比如MVC的异常筛选器, 管道中间件定义try catch捕获异常处理亦或者第三方的解决方案Hellang.Mi ...
- View事件机制分析
目录介绍 01.Android中事件分发顺序 1.1 事件分发的对象是谁 1.2 事件分发的本质 1.3 事件在哪些对象间进行传递 1.4 事件分发过程涉及方法 1.5 Android中事件分发顺序 ...
- 【Leetcode】300. 最长递增子序列
题目(链接) 给你一个整数数组nums,找到其中最长严格递增子序列的长度. 子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序.例如,[3,6,2,7]是数组[0,3,1 ...
- 记录--写一个高德地图巡航功能的小DEMO
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 风格设置 加载地图 使用AMapLoader.load加载地图,从控制台 申请一个属于自己的key import AMapLoader f ...
- FreeRTOS教程10 低功耗
1.准备材料 正点原子stm32f407探索者开发板V2.4 STM32CubeMX软件(Version 6.10.0) Keil µVision5 IDE(MDK-Arm) 野火DAP仿真器 XCO ...
- 快速上手系列:CSS
一 选择符 1 通配:*{} 所有元素 类:p{} 如 p 标签等相应元素 ID:#id{} 使用相应 id 属性的元素样式 类:.类名{} 使用相应 class 属性的元素样式 包含:div p{} ...
- replace小数点后保留2位
小数点后保留2位 网上一堆小数点保留2位正则,但大部分都是直接copy,未解决0101和以.开头的这种情况 网上写法 obj.value = obj.value.replace(/[^\d.]/g,& ...
- C#中字典集合的两种遍历
记录一下 Dictionary<string, string> dictionary = new Dictionary<string,string>(); foreach (s ...
- Collation 差异导致 KingbaseES 与 Oracle 查询结果不同
问题引入 前端提了个问题,说是KingbaseES 返回的结果与 Oracle 返回的结果不一样.具体问题如下: oracle 执行结果:oracle 有结果返回. SQL> create ta ...
- python 1992和2006年国家标准学科分类和代码标准化并存入MySQL数据库
数据表 代码 1 import pandas as pd 2 import pymysql 3 4 5 def get_subject_1992(): 6 res={} 7 the_former_co ...