kafka学习笔记03-消息生产者producer
kafka学习笔记03-消息生产者producer
发送消息整体流程示意图
消息发送的流程示意图:
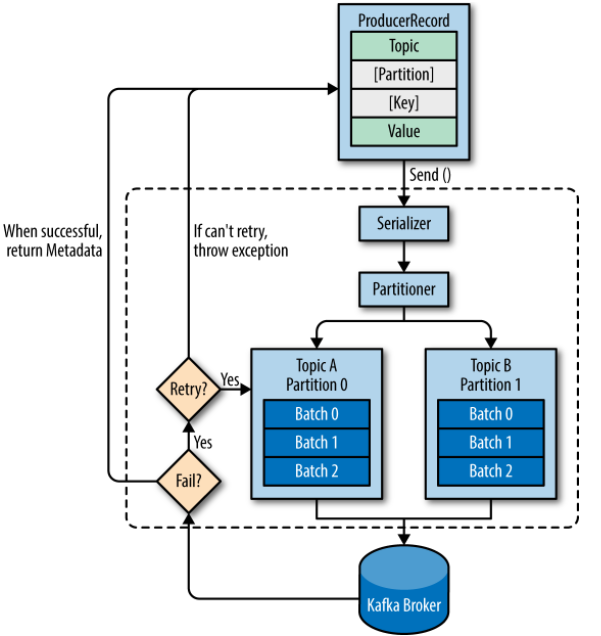
(From:High-level overview of Kafka producer components – Kafka the Definitive Guide Book , 中文书名:kafka权威指南)
一条消息写入 kafka,构造这条消息结构名称叫 ProduceRecord,ProduceRecord 的结构如上图。
大致流程说明:
- 先找到 kafka 集群的 bootstrap server,一般推荐一个kafka集群最少设置 2 个bootstrap server
- 找到一些发送数据需要的元信息,如 topics,partitions,replica-factor 等等信息
- 然后找到 broker 中的 leader topic ,把消息写入到 topic 中的 partiton 里
当然,这当中还有消息的序列化(serializer),分区器(partitioner)对数据的分区分配等步骤。
数据分区分配机制-数据负载均衡
生产者的数据主要发送到 topic 的分区(partition)里,一个 topic 可以有多个分区,同一个topic下的不同分区存储的消息不同,那怎么确定消息发送到哪一个分区partition?
这就需要一种算法来确定数据发送到哪个分区(partition)。
也就是将数据进行均匀分布,分配算法分配数据时不要导致某一个partition数据分配太多,而某一个分区数据又太少。
怎么做到生产数据的负载均衡,kafka 里的 partitioner (分区器)来负责客户端生产层面的负载均衡。
如果提供 key 值
partitioner 会根据 key 的哈希值(采用Murmur2Hash算法)对 partition 数量取模,根据该值决定把消息发送到哪个 partition 上,(hash(key) mod numpartitons)。如果没有提供 key 值
key 为 空(null,无值)时,kafka 2.4 之前有一种策略,轮询算法, 2. 4 之后,又提供了因为一种算法 黏性分区策略。
key 为 null 时,第一次调用时会随机生成一个整数,后面每次在这个整数上自增,然后这个值 对 partition 数量取模,这个就是轮询算法 - roundrobin。
kafka 2.4 之前默认的策略就是这个轮询主题的所有分区,将消息以轮询的方式发送到每一个分区上。
kafka 2.4 之后,社区又引进了 Sticky Partitioning Strategy(黏性分区策略),该策略能显著降低指定分区过程中的延时。具体信息看这里 KIP-480: Sticky Partitioner如果提供了 partition:
如果你指定了 partition分区,那么就用指定的这个分区,不用 hash(key) 的分区算法。
每个消息在被添加到分区partition时,会分配一个 offset ,叫偏移量,它是消息在分区中的唯一编号,也可以理解为数据库中某一张表的唯一id,kafka 通过 offset 保证了消息在某一分区的顺序,offset 不跨区,它只在一个分区内消息是有序。
比如有一个 topic 命名为:topic:student,配置了 3 个分区,分区为:p0,p1,p2,如下图:
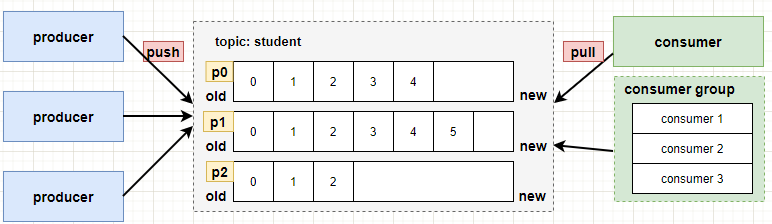
old :表示存储的旧数据,也就是 offset 值小的数据。
new: 表示存储的新数据,新写入的数据,offset 值大的数据。
consumer: 消费者,可以消费 partition 分区的数据。这个可以看作一个消费组只有一个consumer的情况。
consumer group: 消费组,它可以保证每个分区只被组内的一个consumer(消费者)消费。
生产者的一些参数配置
生产端参数配置:http://kafka.apache.org/documentation/#producerconfigs
key.serializer:
key 的序列化
value.serializer :
值的序列化
acks:
acks 指的是有多少个副本接收到数据后发送 ack 成功,生产者才会认为数据接收成功。
- acks = 0,只管发不等服务端确认消息,不负责对发送的消息进行确认是否接收成功。也就是说发送过程中出了问题,导致服务器没有收到消息,生产者无从得知,消息也就丢失了。并且 retries 配置也不会起作用,每次 offset 返回的值都是 -1。
- acks = 1,只要集群的 Leader 接收消息并返回一条 ack 确认消息,就表明成功发送
- acks = all,这个不光要集群的 Leader 接收消息后发送 ack 确认消息,followers 也要发送确认消息,所有的 ack 发送成功,才表明数据发送成功。所以它的延迟比其他2项高。
它还可以设置为 -1, 即是 acks = -1。
buffer.memory:
设置生产者的内存缓冲区,缓冲要发送给服务器的消息。
compression.type:
对消息启用的压缩算法。默认情况下消息不会被压缩。
该参数可以设置为 snappy、gzip 和 lz4
retries:
发送消息遇到错误,重试的次数。
batch.size:
该参数指定了一个批次可以使用的内存大小,按照字节数计算
当有多个消息发到同一个分区时,生产者会把它放到同一个批次里。
bootstrap.servers:
连接到 kafka cluster 列表,也就是 broker 列表。默认为空。
设置:host1:port1,host2:port2,...
linger.ms:
在批量发送前的等待时间
client.id:
可以是任意字符串,服务器用来识别消息来源。可以设置为空,client.id=""
更多配置参数参考这里:http://kafka.apache.org/documentation/#producerconfigs
kafka学习笔记03-消息生产者producer的更多相关文章
- kafka 0.8.2 消息生产者 producer
package com.hashleaf.kafka; import java.util.Properties; import kafka.javaapi.producer.Producer; imp ...
- kafka 0.10.2 消息生产者(producer)
package cn.xiaojf.kafka.producer; import org.apache.kafka.clients.producer.*; import org.apache.kafk ...
- Kafka学习笔记3--Kafka的生产者和消费者配置
下载解压 kafka 后,在 kafka/config 下有 3 个配置文件与主题及其生产.消费相关. server.properties--服务端配置 producer.properties--生产 ...
- AMQ学习笔记 - 03. 消息的接收方式
概述 消息有两种接收方式:同步接收和异步接收. 同步接收:主线程阻塞式等待下一个消息的到来,可以设置timeout,超时则返回null. 异步接收:主线程设置MessageListener,然后继续做 ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer
Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer: 启动Zookeeper 启动Kafka0.11 创建一个新的Topic: ./kafk ...
- C++ GUI Qt4学习笔记03
C++ GUI Qt4学习笔记03 qtc++spreadsheet文档工具resources 本章介绍创建Spreadsheet应用程序的主窗口 1.子类化QMainWindow 通过子类化QM ...
- Redis:学习笔记-03
Redis:学习笔记-03 该部分内容,参考了 bilibili 上讲解 Redis 中,观看数最多的课程 Redis最新超详细版教程通俗易懂,来自 UP主 遇见狂神说 7. Redis配置文件 启动 ...
- Linux进程间通信IPC学习笔记之消息队列(SVR4)
Linux进程间通信IPC学习笔记之消息队列(SVR4)
随机推荐
- [转帖]Percolator 和 TiDB 事务算法
https://cn.pingcap.com/blog/percolator-and-txn 本文先概括的讲一下 Google Percolator 的大致流程.Percolator 是 Google ...
- [转帖]JMeter InfluxDB v2.0 listener plugin
https://github.com/mderevyankoaqa/jmeter-influxdb2-listener-plugin Support my Ukrainian Family ️ Lik ...
- [转帖]Linux常用的一些命令,看你知道多少?
https://zhuanlan.zhihu.com/p/115279009 Linux中命令有很多,而Linux系统中使用命令也是它的一大特点.在Linux系统中使用命令处理问题灵活,高效,所以熟知 ...
- /dev/null 先后顺序的问题
https://blog.csdn.net/x1131230123/article/details/114317752
- 数据结构与算法 第二章线性表(48课时课程笔记)Data Structure and Algorithms
2.1 线性表的类型定义 一个线性表是n个数据元素的有限序列. (1)结构初始化 InitList(&L) 构造一个空的线性表L. (2)销毁结构 DestroyList(&L) (3 ...
- 商智C店H5性能优化实战
前言 商智C店,是依托移动低码能力搭建的一个应用,产品面向B端商家.随着应用体量持续增大,考虑产品定位及用户体验,我们针对性能较差页面做了一次优化,并取得了不错的效果,用户体验值(UEI)从一般提升到 ...
- uni-app 顶部配置搜索框和左右图标
顶部的图标只支持本地图片哈,所以你要将阿里巴巴上的图标下载到本地, 然后只要XXX.ttf这个文件就行了 然后放在static这个文件中 在pages.json中fontSrc进行引入. text:使 ...
- flask session 伪造
flask session 伪造 一.session的作用 由于http协议是一个无状态的协议,也就是说同一个用户第一次请求和第二次请求是完全没有关系的,但是现在的网站基本上有登录使用的功能,这就要求 ...
- vim 从嫌弃到依赖(5)——普通模式的一些操作
通过前面几章内容的铺垫,基本已经介绍完了普通模式的大部分内容,按照进度下面会依次介绍插入模式.命令模式.选择模式的一些操作.根据不同模式提供功能的多少和使用频率,篇幅会有长有短.本来这篇文章应该介绍插 ...
- 19.11 Boost Asio 获取远程目录
远程目录列表的获取也是一种很常用的功能,通常在远程控制软件中都存在此类功能,实现此功能可以通过filesystem.hpp库中的directory_iterator迭代器来做,该迭代器用于遍历目录中的 ...