R4_Elasticsearch Mapping parameters
Elasticsearch的Mapping,定义了索引的结构,类似于关系型数据库的Schema.
Mapping Type:每个索引都拥有唯一的 mapping type,用来决定文档将如何被索引。从7.x开始,不需要在Mapping中指定type信息,默认type为 _doc。mapping type由下面两部分组成
- Meta-fields:元字段用于自定义如何处理文档的相关元数据。 元字段的示例包括文档的_index,_type,_id和_source字段。
- Fields or properties:映射类型包含与文档相关的字段或属性的列表。
Mapping 字段设置流程
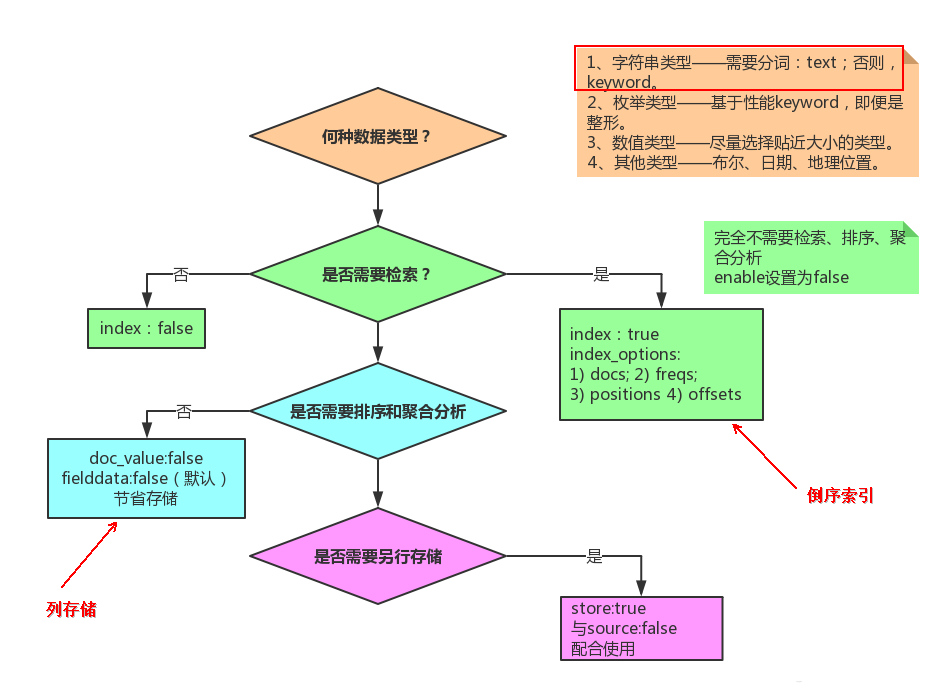
Flag: 啥场景下会用到 enable = false ?
字段类型
ES 字段类型主要有:核心类型、复杂类型、地理类型以及特殊类型,具体的数据类型如下图所示:
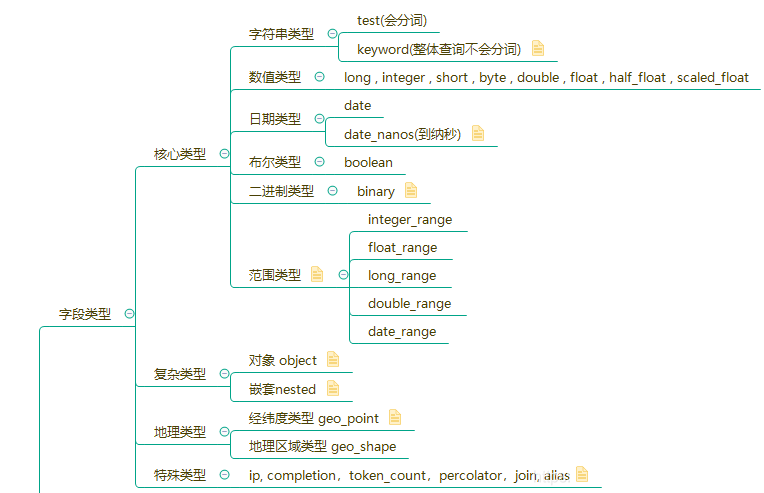
1、text
text类型的字段用来做全文检索,例如邮件的主题、淘宝京东中商品的描述等。这种字段在被索引存储前先进行分词,存储的是分词后的结果,而不是完整的字段。text字段不适合做排序和聚合。
如果是一些结构化字段,分词后无意义的字段建议使用keyword类型,例如邮箱地址、主机名、商品标签等。
常有参数包含以下:
- index:是否可以被搜索到。默认是true
- fields:Multi-fields允许同一个字符串值同时被不同的方式索引,例如用不同的analyzer使一个field用来排序和聚类,另一个同样的string用来分析和全文检索。如下
"IfFullyOpen ": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256, //超过256个字符的文本,将会被忽略,不被索引
"type": "keyword"
}
}
},
Flag : text 类字段默认不被列存?(是)
2、keyword 类型
keyword:不会被分词,适合简短、结构化字符串,例如主机名、姓名、商品名称等,可以用于过滤、排序、聚合检索,也可以用于精确查询。所以在es中应索引完整的字段,而不是分词后的结果。
3、object类型
mapping中不用特意指定field为object类型,因为这是它的默认类型。json类型天生具有层级的概念,文档内部还可以包含object类型进行嵌套。例如:
1 PUT my_index
2 {
3 "mappings": {
4 "properties": {
5 "region": {
6 "type": "keyword"
7 },
8 "manager": {
9 "properties": {
10 "age": { "type": "integer" },
11 "name": {
12 "properties": {
13 "first": { "type": "text" },
14 "last": { "type": "text" }
15 }
16 }
17 }
18 }
19 }
20 }
21 }
4、nest类型
nest类型是一种特殊的object类型,它允许object可以以数组形式被索引,而且数组中的某一项都可以被独立检索。而且es中没有内部类的概念,而是通过简单的列表来实现nest效果,例如下列结构的文档:
映射参数
- 详细映射参数见: Mapping parameters , 选部分参数进行解释
1 "field": {
2 "type": "text", //文本类型
3
4 "index": "false" // 设置成false,字段将不会被索引,倒序存储控制参数
5
6 "analyzer":"ik" //指定分词器
7
8 "boost":1.23 //字段级别的分数加权
9
10 "doc_values":false // 对 not_analyzed 字段,默认都是开启,analyzed字段不能使用,对排序和聚合能提升较大性能,节约内存,如果您确定不需要对字段进行排序或聚合,或者从script访问字段值,则可以禁用doc值以节省磁盘空间:
11
12 "fielddata": {"loading" : "eager" } //Elasticsearch 加载内存 fielddata 的默认行为是 延迟 加载 。 当 Elasticsearch 第一次查询某个字段时,它将会完整加载这个字段所有 Segment 中的倒排索引到内存中,以便于以后的查询能够获取更好的性能。
13
14 "fields":{"keyword": {"type": "keyword","ignore_above": 256}} //可以对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词
15
16 "ignore_above":100 //超过100个字符的文本,将会被忽略,不被索引
17
18 "include_in_all":ture //设置是否此字段包含在_all字段中,默认是true,除非index设置成no选项
19
20 "index_options":"docs" //4个可选参数docs(索引文档号) ,freqs(文档号+词频),positions(文档号+词频+位置,通常用来距离查询),offsets(文档号+词频+位置+偏移量,通常被使用在高亮字段)分词字段默认是position,其他的默认是docs
21
22 "norms":{"enable":true,"loading":"lazy"} //分词字段默认配置,不分词字段:默认{"enable":false},存储长度因子和索引时boost,建议对需要参与评分字段使用 ,会额外增加内存消耗量
23
24 "null_value":"NULL" //设置一些缺失字段的初始化值,只有string可以使用,分词字段的null值也会被分词
25
26 "position_increament_gap":0 //影响距离查询或近似查询,可以设置在多值字段的数据上火分词字段上,查询时可指定slop间隔,默认值是100
27
28 "store":false //是否单独设置此字段的是否存储而从_source字段中分离,默认是false,只能搜索,不能获取值
29
30 "search_analyzer":"ik" //设置搜索时的分词器,默认跟ananlyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能
31
32 "similarity":"BM25" //默认是TF/IDF算法,指定一个字段评分策略,仅仅对字符串型和分词类型有效
33
34 "term_vector":"no"//默认不存储向量信息,支持参数yes(term存储),with_positions(term+位置),with_offsets(term+偏移量),with_positions_offsets(term+位置+偏移量) 对快速高亮fast vector highlighter能提升性能,但开启又会加大索引体积,不适合大数据量用
35 }
小结:
- 与域数据格式及约束相关的参数:normalizer,format,ignore_above,ignore_malformed,coerce
- 与索引相关的参数: index,dynamic,enabled
- 与存储策略相关的参数: store, fielddata,doc_values
- 分析器相关参数: analyzer,search_analyzer
- 其它参数: boost,copy_to,null_value
1、dynamic
是否允许动态的隐式增加字段。对于_source字段中包含一些原先未定义的字段采取的措施,根据dynamic的取值,会进行不同的操作
- true: 默认值,表示新的字段会加入到类型映射中。:
- false:新的字段会被忽略,即不会存入_souce字段中,即不会存储新字段,也无法通过新字段进行查询
- strict:会显示抛出异常,需要新使用put mapping api先显示增加字段映射。
1 "mappings":{
2 "user":{
3 "dynamic": strict,
4 "properties": {
5 "name": {"type": "text"},
6 "address": {"type": "object", "dynamic": true}
7 }
8 }
9 }
2、 doc_values
是为了加快排序、聚合操作,在建立倒排索引的时候,额外增加一个列式存储映射,是一个空间换时间的做法。默认是开启的,对于确定不需要聚合或者排序的字段可以关闭。
"session_id": {
"type": "keyword",
"doc_values": false
}
文本(text)字段不支持 doc_values,为了实现 text 字段的聚合、排序, 替代的方案:文本(text)字段使用查询时内存中的数据结构,称为fielddata
fielddata是 text 型的字段查询时使用一个内存型数据结构。该数据结构是根据需求第一次建立的,用于聚合、排序或脚本。它是通过从磁盘读取每个段的整个倒排索引、反转术语_文档关系并将结果存储在JVM堆的内存中来构建的。
fielddata会占用大量的堆内存,尤其是在加载的高基数的text型字段。 一旦 fielddata 被加载到堆里,它会一直存在于字段的生命周期中。此外,加载字段数据是一个昂贵的过程,这可能会导致用户体验延迟命中。这就是为什么默认情况下禁用fielddata 的原因
4、copy_to
用于将当前字段拷贝到指定字段:
- _all在7.x版本已经被copy_to所代替
- copy_to将字段数值拷贝到目标字段,实现类似_all的作用
- copy_to的目标字段不出现在_source中
- 在设置mapping的时候加上 store:true
1 PUT my_index
2 {
3 "mappings": {
4 "properties": {
5 "first_name": {
6 "type": "text",
7 "copy_to": "full_name"
8 },
9 "last_name": {
10 "type": "text",
11 "copy_to": "full_name"
12 },
13 "full_name": {
14 "type": "text",
15 "store": true
16 }
17 }
18 }
19 }
- 查询 : GET my_index/_doc/1?stored_fields=full_name
- 测试实例可参考:https://blog.csdn.net/pony_maggie/article/details/108397409
Flag:
1、啥场景下会用到 enable = false ? 不能被检索、排序、聚合?
2、text 字段要聚合排序可以用 fields ,为什么又有 fielddata、其与docValues ?
Re: 在ElasticSearch中,doc_values和fielddata就是用来给文档建立正排索引的。他俩一个很显著的区别是,前者的工作地盘主要在磁盘,而后者的工作地盘在内存。
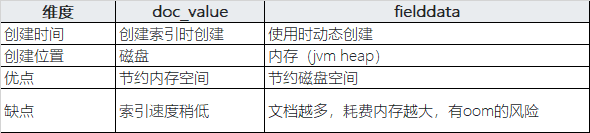
ElasticSearch对于非分词字段,默认doc_value是开启的,如果非常确定某个字段将来不会用来排序或者聚合操作,可以显示地指定关闭doc_value;
对于分词字段,如果未将fielddata显示开启,则对于分词字段的排序、聚合操作将会报错。开启fielddata需要慎重,因为开销是昂贵的,还有oom风险。
3、生产环境订单宽表字段太多,换成 object 类型分层会有性能提升吗?此 object 从_source去掉,开启store?
4、为保证数据结构的统一,业务明细表、汇总表禁用动态mapping?
参考资料
- https://www.elastic.co/guide/en/elasticsearch/reference/6.8/mapping-params.html
- https://www.cnblogs.com/haixiang/p/12040272.html
- Elasticsearch Mapping的解析
- Elasticsearch7.X 入门学习第五课笔记
- https://i.cnblogs.com/posts/edit;postId=14443936
R4_Elasticsearch Mapping parameters的更多相关文章
- [转]SSIS Execute SQL Task : Mapping Parameters And Result Sets
本文转自:http://www.programmersedge.com/post/2013/03/05/ssis-execute-sql-task-mapping-parameters-and-res ...
- Elasticsearch实践(三):Mapping
版本:Elasticsearch 6.2.4. Mapping类似于数据库中的表结构定义,主要作用如下: 定义Index下字段名(Field Name) 定义字段的类型,比如数值型,字符串型.布尔型等 ...
- elasticsearch入门使用(二) Mapping + field type字段类型
Elasticsearch Reference [6.2] » Mapping 参考官方英文文档 https://www.elastic.co/guide/en/elasticsearch/refer ...
- Elasticsearch Mapping类型修改
背景 通常数据库进行分库分表后,目前比较常规的作法,是通过将数据异构到Elasticsearch来提供分页列表查询服务:在创建Elasticsearch索引时,基本都是会参考目前的业务需求.关系数据库 ...
- CSharpGL(5)解析3DS文件并用CSharpGL渲染
CSharpGL(5)解析3DS文件并用CSharpGL渲染 我曾经写过一个简单的*.3ds文件的解析器,但是只能解析最基本的顶点.索引信息,且此解析器是仿照别人的C++代码改写的,设计的也不好,不方 ...
- 自制C#版3DS文件的解析器并用SharpGL显示3DS模型
自制C#版3DS文件的解析器并用SharpGL显示3DS模型 我已经重写了3ds解析器,详情在此(http://www.cnblogs.com/bitzhuwei/p/CSharpGL-2-parse ...
- informatica 学习日记整理
1. INFORMATICA CLIENT的使用 1.1 Repository Manager 的使用 1.1.1 创建Repository. 前提: a.在ODBC数据源管理器中新建一个数据源连接至 ...
- ES3:ElasticSearch 索引
ElasticSearch是文档型数据库,索引(Index)定义了文档的逻辑存储和字段类型,每个索引可以包含多个文档类型,文档类型是文档的集合,文档以索引定义的逻辑存储模型,比如,指定分片和副本的数量 ...
- elasticsearch映射
前面讲到,无论是关系型数据库还是非关系型数据库,乃至elasticsearch这种事实上承担着一定储存作用的搜索引擎,数据类型都是非常重要而基础的概念.但elasticsearch与其它承担着数据存储 ...
- MyElasticsearch
目录 那些必须要知道的事儿 搭建elasticsearch环境 快速上手 elasticsearch分析数据的过程漫谈 建议器:Suggester IK中文分词器 elasticsearch for ...
随机推荐
- KingbaseES 使用百分比函数获取中位数
客户从Oracle数据库迁移至KingbaseES数据库,应用中使用MEDIAN函数来求中位数.KingbaseES数据库中没有MEDIAN函数,但可以通过百分比函数来实现相应的功能. MEDIAN ...
- 【Java基础知识】东软面试(一面)
01 面向对象的特征 封装:隐藏部分对象的属性和实现细节,以不同的访问级别来保护对象内部的数据,防止外部程序的不当访问,对外提供公开的接口.[私有的属性,共有的方法] 继承:子类自动共享父类数据和方法 ...
- FreeSql生产环境自动升级数据库解决方案
项目场景: 使用FreeSql,包含所有的ORM数据库,都会存在这样的问题.在codefirst模式下,根据代码自动更新数据库,都建议不要在生产环境使用.为什么呢? 其实不建议使用,主要是根据代码自动 ...
- 到底什么是AQS?面试时你能说明白吗!
写在开头 上篇文章写到CAS算法时,里面使用AtomicInteger举例说明,这个类在java.unit.concurrent.atomic包中,存储的都是一些原子类,除此之外,"java ...
- #排列组合#CF1550D Excellent Arrays
洛谷传送门 CF1550D 分析 对于excellent的 \(a\) 来说 \(|a_i-i|=x\) 的值是固定的,考虑枚举它 一半正一半负时函数值是最大的,当 \(n\) 为奇数时要分为两种情况 ...
- #并查集#JZOJ 4223 旅游
题目 多次询问有多少个无序点对\((x,y)\), 满足至少有一条最大边权\(\leq d\)的路径 分析 离线询问,用并查集加边,每次产生的贡献为\(2*siz[x]*siz[y]\) 代码 #in ...
- C 语言用户输入详解:scanf、fgets、内存地址解析及实用指南
C 语言中的用户输入 您已经学习了 printf() 函数用于在 C 语言中输出值. 要获取用户输入,可以使用 scanf() 函数: // 声明一个整数变量,用于存储我们从用户那里获得的数字 int ...
- SQL 日期处理和视图创建:常见数据类型、示例查询和防范 SQL 注入方法
SQL处理日期 在数据库操作中,处理日期是一个关键的方面.确保插入的日期格式与数据库中日期列的格式匹配至关重要.以下是一些常见的SQL日期数据类型和处理方法. SQL日期数据类型 MySQL日期数据类 ...
- elasticsearch映射创建查询 和Spring Data ElasticSearch入门
Elasticsearch核心概念 Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document).然而它不仅 仅是存储,还会索引( ...
- MogDB/openGauss如何实现事务的rollback
MogDB/openGauss 如何实现事务的 rollback 本文出处:https://www.modb.pro/db/113262 数据库最主要的功能就是存储数据,然而我们在进行数据库操作时,却 ...