深度学习论文翻译解析(二十三):Segment Angthing
论文标题:Segment Angthing
论文作者: Alexander Kirillov Eric Mintun Nikhila Ravi Hanzi Mao...
声明:小编翻译论文仅为学习,如有侵权请联系小编删除博文,谢谢!
小编是一个机器学习初学者,打算认真研究论文,但是英文水平有限,所以论文翻译中用到了Google,并自己逐句检查过,但还是会有显得晦涩的地方,如有语法/专业名词翻译错误,还请见谅,并欢迎及时指出。
这是我第一次不在博文里面写中文,英文对照这种了。不知道会做成什么样的笔记。
如果需要小编其他论文翻译,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote
首先简单说一下SAM。其实SAM模型是Meta在2023年4月6号开源的一个图像分割模型(Segment Angthing Model)。它一经发布就获得了无数关注。它借助了NLP任务中的Prompt思路,通过给图像分割任务提供一下Prompt提示来完成任务目标的快速分割。提示可以是前景/背景点集,粗略的框或者mask,任意形式的文本或者任何指示图像中需要进行分割的信息。
该任务的输入是原始的图像和一些提示语,输出是图像中不同目标的掩码信息。我们可以先取官网玩一下。它的提示有点,框,文本信息,就产生了高质量的对象掩码。并可用于生成图像中所有对象的淹没。分割效果非常惊艳。可以说是分割模型的SOTA算法。
1,SAM的demo
下面就是Meta的官网:
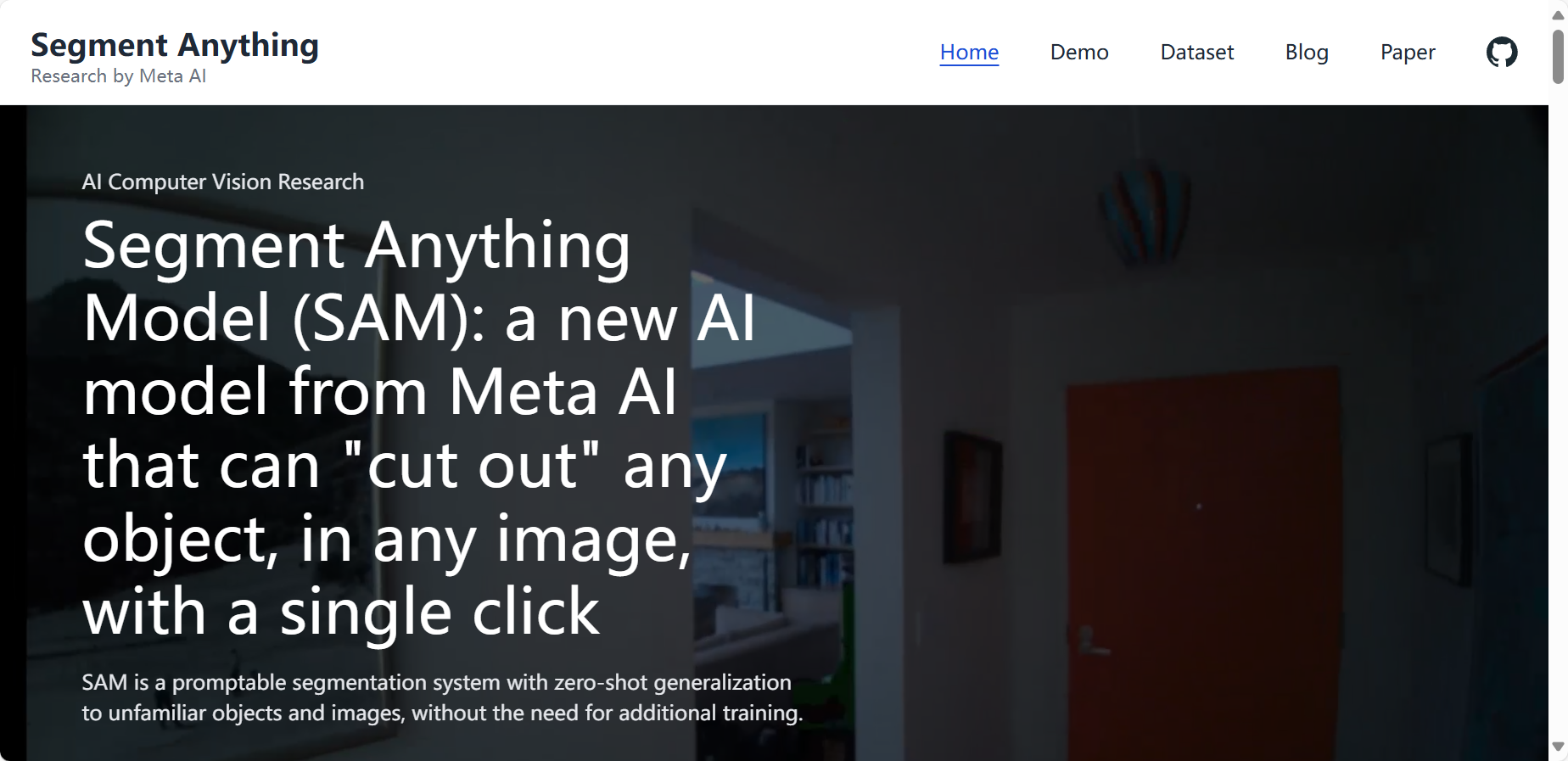
我们使用其demo尝试一下,输入图像和提示语:
注意其模型比较大,所以解析图像稍微慢一下:
上面有提到,提示可以是点,框,文本信息。首先我们使用框试一下,即box:
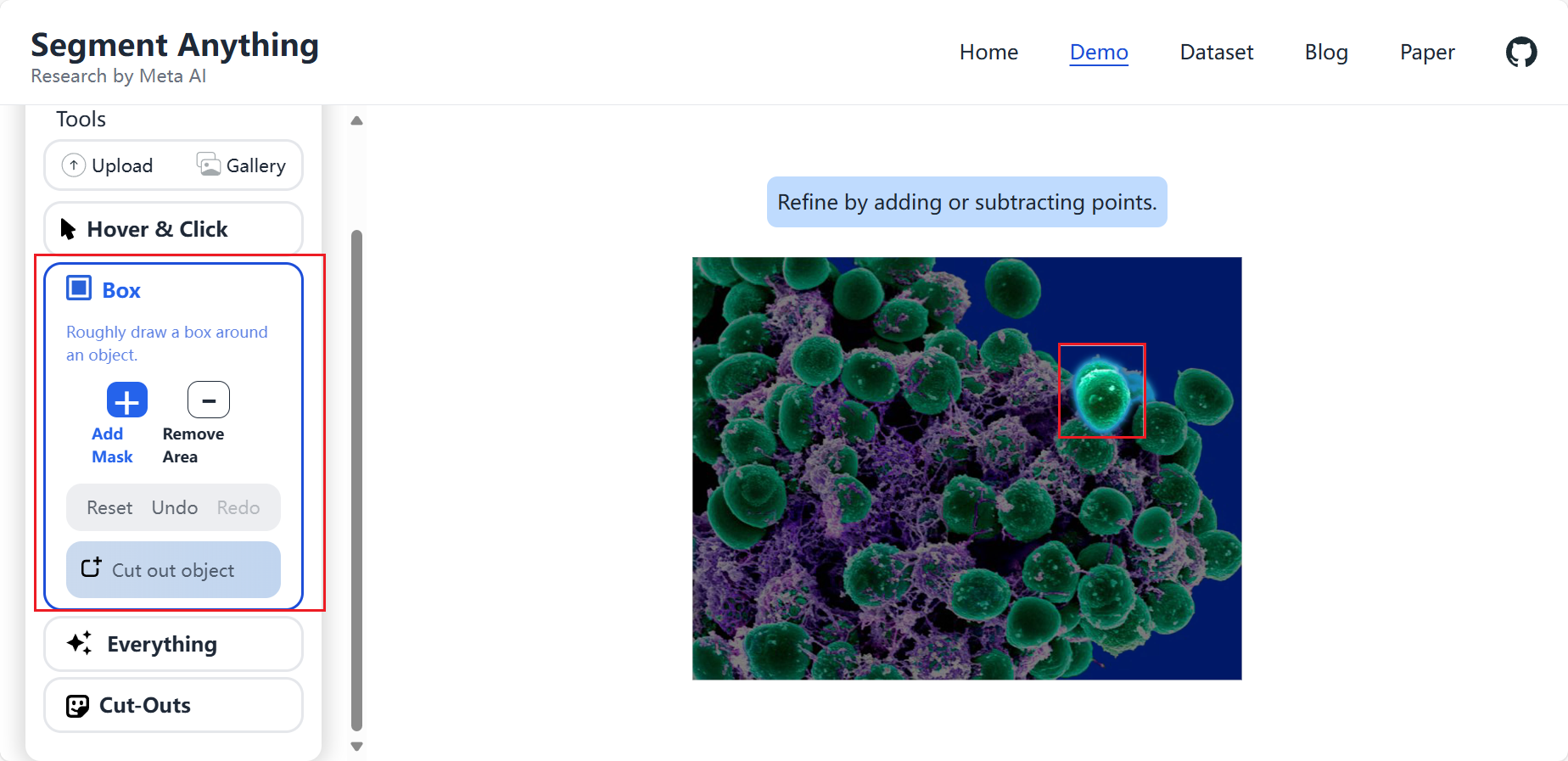
可以看到,它可以很明显将一个球体分割出来。然后我们使用点来试一下:
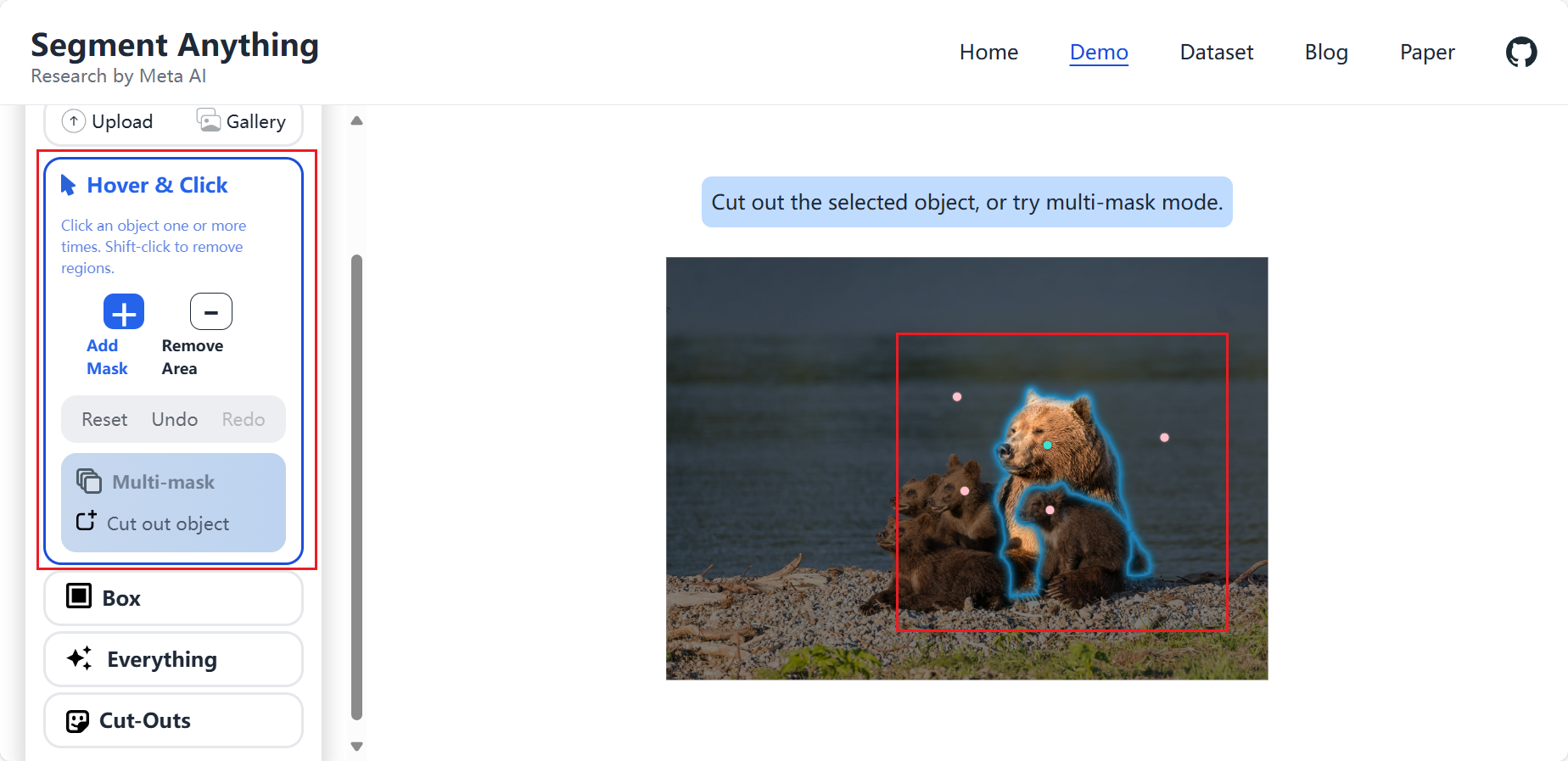
我首先使用绿色的点点了大熊,如果怕分割效果不好,可以使用红色的点点击不需要分割的区域。这就是点的效果。
最后就是使用分割Everything 了。它可以将自己理解的图像,分割开,如下:
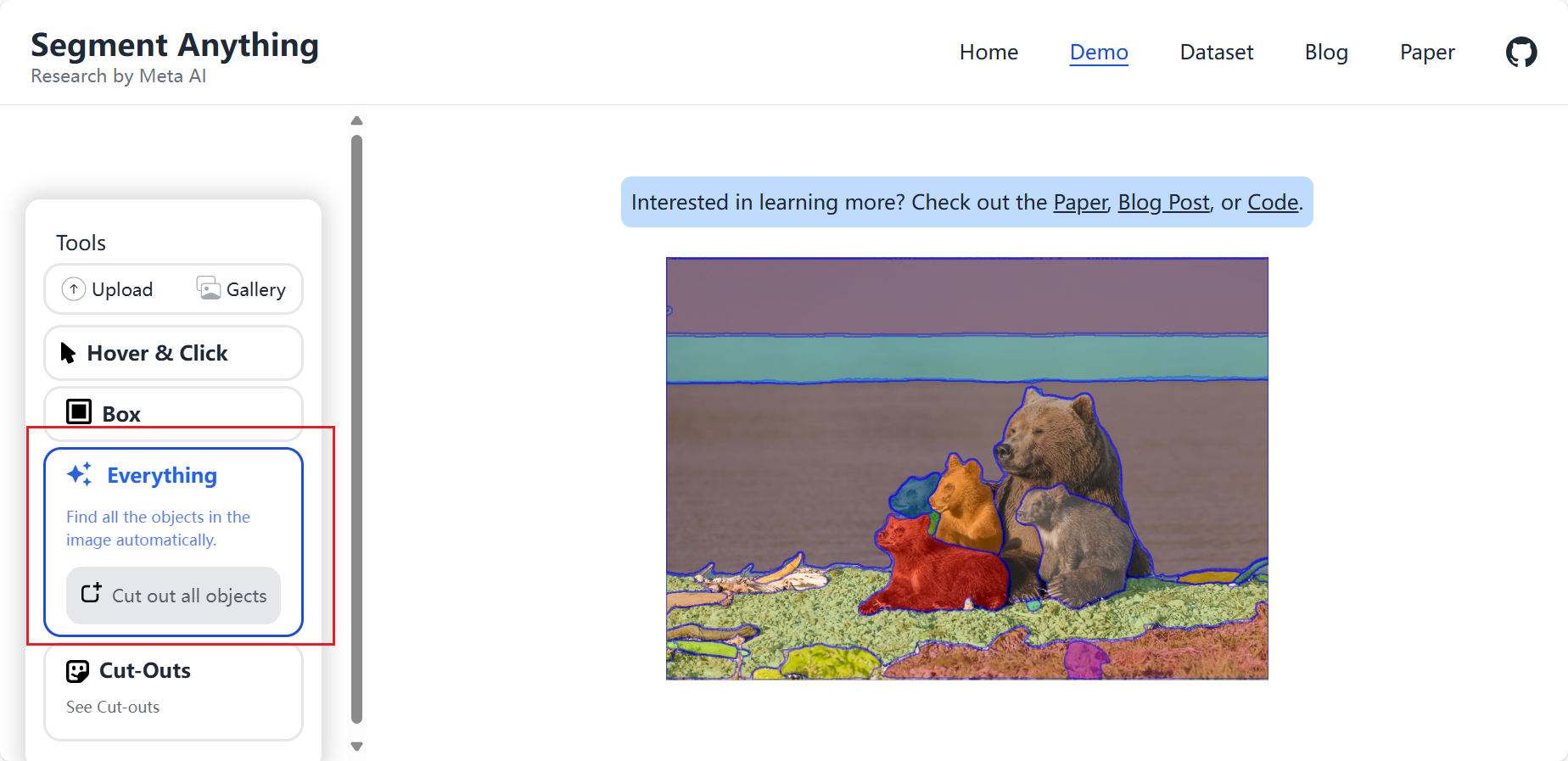
这大概就是SAM的完整操作了,当然你可以将其使用在数据标注上,也可以直接使用SAM大模型进行分割。但是因为这个模型是使用ImageNet等一些泛化性较高的数据集训练的,所以对于这些场景的标注是准确并且精细的。但是对于许多工业中特定场景可能不是非常适应。
大家也都知道,许多工业数据是不开源的,各个行业都是一样的,因为数据就是核心嘛。但是SAM还是非常强大的。正如论文提到的。
2,SAM论文内容
2.1 摘要内容

文章作者提到他们这个方案成功的关键在于三个组成部分,任务,模型和数据。为了开发他们,作者们解决了以下关于图像分割的问题:

作者认为这些问题纠缠不清,需要一个全面的解决方案。他们首先定义一个可提示的分割任务,该任务足够通用,可以提供强大的预训练目标,并支持广泛的下游应用程序。此任务需要一个支持灵活提示的模型,并且可以在提示时实时输出分段掩码,以便进行交互式使用。为了训练作者的模型,他们需要一个多样化的、大规模的数据源。遗憾的是,没有用于细分的网络规模数据源;为了解决这个问题,他们构建了一个“数据引擎”,即在使用他们的高效模型来协助数据收集和使用新收集的数据来改进模型之间进行迭代。
而下图就是文章中提到的task, model, data架构。
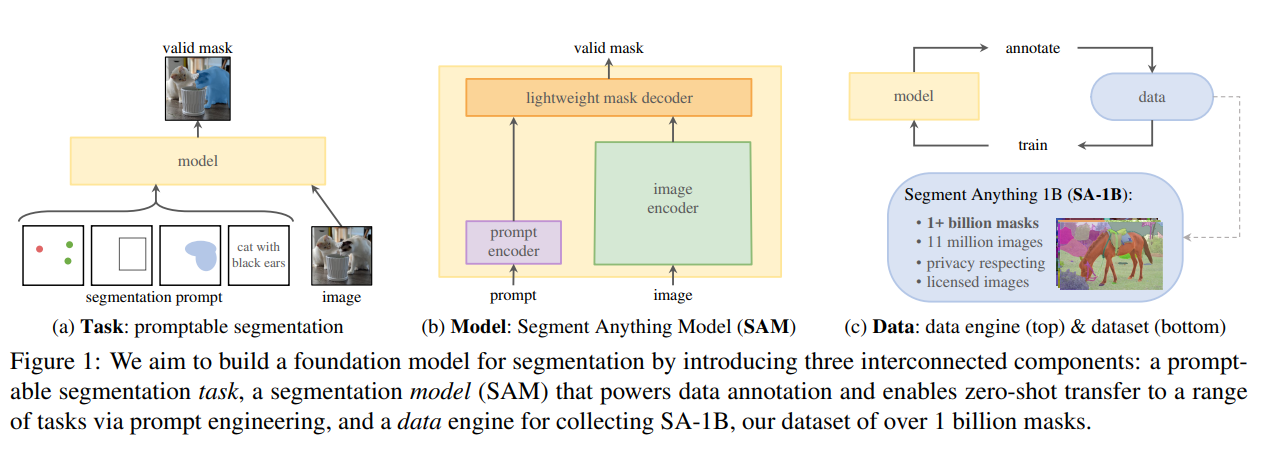
2.2 SAM组件1——task

在 NLP 和最近的计算机视觉中,基础模型是一个很有前途的发展,它可以通常通过使用“提示”技术对新的数据集和任务执行零样本和少样本学习。受这一系列工作的启发,我们提出了可提示的分割任务,其目标是在给定任何分割提示的情况下返回一个有效的分割掩码(见图1a)。提示只是指定要在图像中分割的内容,例如,提示可以包含标识对象的空间或文本信息。有效输出掩码的要求意味着,即使提示不明确并且可能引用多个对象(例如,衬衫上的一个点可能表示衬衫或穿着衬衫的人),输出也应该是这些对象中至少一个的合理掩码。我们使用可提示分割任务作为预训练目标,并通过提示工程解决一般的下游分割任务。

其实SAM就是一个可提示的分割任务。SAM借助了NLP任务中的Prompt思路,通过给图像分割任务提供一下Prompt提示来完成任意目标的快速分割。
- 前景/背景点集、(图中红色的点就是背景,绿色的点就是前景)
- 粗略的框(这个就不解释了,就是上一页的Bounding box)
- 遮罩,即mask
任意形式的文本或者任何指示图像中需要进行分割的信息。该任务的输入是原始的图像和一些提示语,输出是图片中不同目标的掩码信息。
2.3 SAM组件2——Model

可提示的分割任务和实际使用的目标对模型架构施加了约束。具体而言,模型必须支持灵活的提示,需要实时摊销计算掩码以允许交互式使用,并且必须具有模糊性意识。令人惊讶的是,我们发现一个简单的设计满足了所有三个约束:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后将两个信息源组合在一个轻量级的掩码解码器中,该解码器预测分割掩码。我们将此模型称为 Segment Anything Model(SAM)(见图 1b)。通过将 SAM 分为图像编码器和快速提示编码器/掩码解码器,可以重复使用不同的提示替换相同的图像嵌入(并分摊其成本)。给定图像嵌入,提示编码器和掩码解码器在 Web 浏览器中从 ∼50 毫秒的提示中预测掩码。我们专注于指向、框和蒙版提示,并使用自由格式的文本提示来呈现初始结果。为了使 SAM 能够感知歧义,我们将其设计为预测单个提示的多个掩码,使 SAM 能够自然地处理歧义,例如衬衫与人物示例。
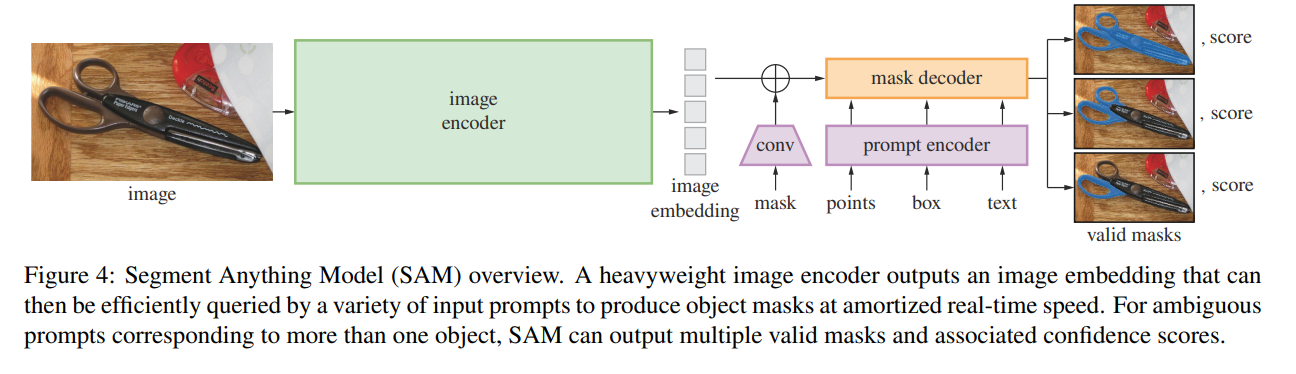
如上图所示SAM模型。就是用于提示式分割的Segment Anything Model (SAM)模型包含三个组件:图像编码器,提示编码器和掩码解码器。
图像编码器 image encoder:基于可扩展性和强大的预训练方法的启发,研究者使用MAE预训练的ViT(Vision Transformer),最小限度地适用于处理高分辨率输入。图像编码器对每张图像运行一次,在提示模型之前进行应用。
提示编码器 prompt encoder :考虑两组prompt:稀疏(点、框、文本 points, box , text)和密集(掩码 mask )。研究者通过位置编码来表示点和框,并将对每个提示类型的学习嵌入和自由形式的文本与CLIP中的现成文本编码相加。密集的提示(即掩码 mask )使用卷积conv 进行嵌入,并通过图像嵌入进行元素求和。
掩码解码器 mask decoder:掩码解码器通过有效地将image embedding图像嵌入,prompt embeddings提示嵌入和输出token映射到掩码来实现。这种设计采用了一个修改的Transformer解码器块,后跟一个动态掩码预测头。修改的解码器块使用提示自注意力和交叉注意力两个方向(提示到图像嵌入和反之亦然)来更新所有嵌入。在运行两个块之后,我们对图像嵌入进行上采样,并且MLP(多层感知器)将输出令牌映射到动态线性分类器,然后在每个图像位置计算掩码前景概率。
原始论文是这样写的:


2.4 SAM组件3——Data

为了实现对新数据分布的强泛化,我们发现有必要在大量且多样化的掩码集上训练 SAM,而不仅仅是任何已经存在的分割数据集。虽然基础模型的典型方法是在线获取数据[82],但掩码并不是自然丰富的,因此我们需要一种替代策略。我们的解决方案是构建一个“数据引擎”,即我们将模型与模型在环数据集注释共同开发(见图1c)。我们的数据引擎有三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM 协助注释者注释掩码,类似于经典的交互式分割设置。在第二阶段,SAM 可以通过提示其可能的对象位置来自动为对象子集生成掩码,而注释者则专注于注释剩余对象,从而帮助增加掩码的多样性。在最后阶段,我们使用规则的前景点网格来提示 SAM,平均每张图像产生 ∼100 个高质量蒙版。

我们的最终数据集 SA-1B 包括来自 11M 许可和隐私保护图像的 1B 多个掩模(见图 2)。SA-1B使用我们数据引擎的最后阶段完全自动收集,比任何现有的分割数据集[66,44,117,60]多400×个掩码,并且随着我们的广泛验证,这些掩码具有高质量和多样性。除了用于训练SAM使其具有鲁棒性和通用性外,我们还希望SA-1B成为旨在构建新基础模型的研究的宝贵资源。
由于互联网上的分割掩码并不丰富,因此我们构建了一个数据引擎来收集我们的 1.1B 掩码数据集 SA-1B。数据引擎有三个阶段:(1)模型辅助的手动注释阶段,(2)混合了自动预测掩码和模型辅助注释的半自动阶段,以及(3)全自动阶段,在这个阶段中,我们的模型在没有注释者输入的情况下生成掩码。接下来我们将详细介绍每一个。
该数据引擎有三个阶段:模型辅助手动标注、半自动标注阶段和全自动阶段。
(1)模型辅助手动标注阶段
该阶段开始之前,研究者首先使用常见的公开图像分割数据集训练SAM,然后使用SAM为SA-1B数据预测图像掩码,由一组专业标注人员在预测掩码的基础上进行掩码细化。这就是手动标注环节。(标注人员可以自由地为掩码赋予标签;此外,标注人员需要按照对象的突出程度来标记对象,并且掩码标注超过30秒就要继续处理下一张图像。在充分的数据标注后,仅使用新标注的掩码对SAM进行重新训练(该阶段总共训练了模型6次)。随着收集到更多的掩码,图像编码器从ViT-B扩展到ViT-H。同时,随着模型的改进。每个掩码的平均标注时间从34秒减少到14秒(比COCO的掩码标注快6.5倍,比2D框标注慢2倍);每个图像的平均掩码数量从20个掩码增加到44个掩码。总的来说,该阶段从12万张图像中收集了4630万个掩码。)
(2)半自动标注阶段
其目标是增加掩码的多样性,以提供模型分割东西的能力。为了使标注者专注于不太突出的对象,首先SAM自动分割高置信度的掩码,然后向标注者展示预填充这些掩码的图像,并要求他们标注任何其他未标注的对象。(该阶段在18万张图像中额外收集590万个掩码(总共1020万个掩码)。与第一阶段一样,定期在新收集的数据集上重新训练模型。每个掩码的平均标注时间回到34秒。每个图像的平均掩码数量从44个增加到72个。)
(3)全自动标注阶段
这个阶段的标注是全自动的,因为模型有两个主要的阶段。首先,在这一阶段的开始,收集了足够多的掩码来大大改进模型;其次,在这一阶段,已经开发了模糊感知模型,它允许在有歧义的情况下预测有效的掩码。(具体来说,用32x32的规则网络点来提示网络,并为每个点预测一组可能对应于有效对象的掩码。在模糊感知模型中,如果一个点位于某个部分或子部分上,模型将返回子部分、局部和整个对象。该模型的IoU模块将选择高置信度的掩码,同时选择稳定掩码(如果阈值化概率图在0.5-σ,0.5+σ)产生相似的掩码,则认为是稳定掩码。最后,在选择高置信度和稳定的掩码后,采用NMS对重复数据进行过滤。该阶段,在1100万张图像上全自动生成11亿个高质量掩码。)
所以这就是SAM厉害的data engine。原始论文如下:



3,SAM的安装和使用
3.1 SAM安装
首先去SAM的git仓库去克隆代码。然后也是最重要的是下载SAM模型文件,大概有2.4GB。

最后就是安装SAM了,这个比较简单,直接到下载的文件中,使用 pip install -e .即可。
3.2 SAM的使用
我这里截取自己的代码展示:
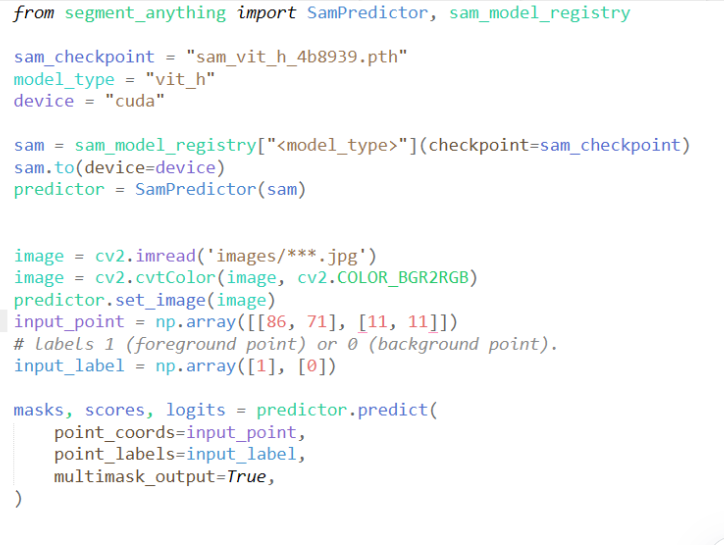
实际上,SAM也给了jupyter的示例,大家可以直接参考,也比较方便。
深度学习论文翻译解析(二十三):Segment Angthing的更多相关文章
- 深度学习论文翻译解析(十三):Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文标题:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 标题翻译:基于区域提议(Regi ...
- 深度学习论文翻译解析(二):An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
论文标题:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application ...
- 深度学习论文翻译解析(十二):Fast R-CNN
论文标题:Fast R-CNN 论文作者:Ross Girshick 论文地址:https://www.cv-foundation.org/openaccess/content_iccv_2015/p ...
- 深度学习论文翻译解析(四):Faster R-CNN: Down the rabbit hole of modern object detection
论文标题:Faster R-CNN: Down the rabbit hole of modern object detection 论文作者:Zhi Tian , Weilin Huang, Ton ...
- 深度学习论文翻译解析(三):Detecting Text in Natural Image with Connectionist Text Proposal Network
论文标题:Detecting Text in Natural Image with Connectionist Text Proposal Network 论文作者:Zhi Tian , Weilin ...
- 深度学习论文翻译解析(五):Siamese Neural Networks for One-shot Image Recognition
论文标题:Siamese Neural Networks for One-shot Image Recognition 论文作者: Gregory Koch Richard Zemel Rusla ...
- 深度学习论文翻译解析(六):MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Appliications
论文标题:MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Appliications 论文作者:Andrew ...
- 深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 标题翻译:丰富的特征层次结构 ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- 深度学习论文翻译解析(十):Visualizing and Understanding Convolutional Networks
论文标题:Visualizing and Understanding Convolutional Networks 标题翻译:可视化和理解卷积网络 论文作者:Matthew D. Zeiler Ro ...
随机推荐
- angular 16 路由守卫更新
在 angular16 中守卫使用方式进行了更新,route 守卫被弃用(取消了CanActivate的使用),新增了功能性守卫(CanActivateFn),支持 inject 注入,官网提供了一个 ...
- mybatis-plus id在高并发下出现重复
mybaits-plus ASSIGN_ID生成 id生成策略 在分布式高并发环境下出现重复id https://github.com/baomidou/mybatis-plus/issues/307 ...
- AIRIOT答疑第3期|如何使用物联网平台的可视化组态引擎?
丰富组件,满足千人千面! AIRIOT物联网低代码平台的可视化组态引擎,具备丰富的可视化看板及组件,满足各类工艺流程图.数据可视化需求.支持三维编辑.图形绘制.图表设计等设计方式,PPT模式设计软件界 ...
- linux下srpm源码包的使用和安装
目录 一.关于srpm包 二.srpm包和rpm包的区别 三.不对srpm包做修改,直接安装srpm包 四.对srpm包的源码进行修改,然后安装srpm包 一.关于srpm包 SRPM包是Sour ...
- Android启动过程-万字长文(Android14)
在计算机启动过程和Linux内核Kernel启动过程介绍了计算机启动和内核加载,本篇文章主要介绍Android系统是如何启动的. 一.Android启动流程 Android系统的启动流程与Linux接 ...
- docker创建容器数据持久化资源限制基础命令
1. docker简介和核心概念 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化.容器是完全使 ...
- itest work 开源接口测试&敏捷测试管理平台 9.5.0 GA_u4发布,优化及修复BUG
(一)itest work 简介 itest work (爱测试) 一站式工作站让测试变得简单.敏捷,"好用.好看,好敏捷" ,是itest wrok 追求的目标.itest w ...
- 如何创建一个线程池,为什么不推荐使用Executors去创建呢?
我们在学线程的时候了解了几种创建线程的方式,比如继承Thread类,实现Runnable接口.Callable接口等,那对于线程池的使用,也需要去创建它,在这里我们提供2种构造线程池的方法: 方法一: ...
- LeetCode 685. Redundant Connection II 冗余连接 II (C++/Java)
题目: In this problem, a rooted tree is a directed graph such that, there is exactly one node (the roo ...
- C# .NET Dictionary 将集合key以ascii码从小到大排序
.NET 不加参数,默认不是按ASC II 排序 .JAVA 默认是按ASC II 排序 . Array.Sort(arrKeys, string.CompareOrdinal); 按ASC II 排 ...