基于MRS-Hudi构建数据湖的典型应用场景介绍
摘要:华为云FunsionInsight MRS已集成Apache Hudi 0.8版本,基于MRS-Hudi构建数据湖解决方案。
本文分享自华为云社区《基于MRS-Hudi构建数据湖的典型应用场景介绍》,作者:受春柏。
一、传统数据湖存在的问题与挑战
传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化。虽然能够在海量批处理场景中取得不错的效果,但依然存在如下现状问题:
问题一:不支持事务
由于传统大数据方案不支持事务,有可能会读到未写完成的数据,造成数据统计错误。为了规避该问题,通常控制读写任务顺序调用,在保证写任务完成后才能启动读任务。但并不是所有读任务都能够被调度系统约束住,在读取时仍存在该问题。
问题二:数据更新效率低
业务系统库的数据,除流水表类的数据都是新增数据外,还有很多状态类数据表需要更新操作(例如:账户余额表,客户状态表,设备状态表等),而传统大数据方案无法满足增量更新,常采用拉链方式,先进行join操作再进行insert overwrite操作,通过覆盖写的方式完成更新操作,该操作往往需要T+1的批处理模式 ,从而导致端到端数据时延T+1,存在效率低、成本高等问题。
问题三:无法及时应对业务表变化
上游业务系统对数据schema发生变更后,会导致数据无法入湖,需要数据湖的表schema进行同步调整。从技术实现上采用数据表重建的方式来满足该场景,导致数据湖的数据表的管理与维护方案复杂,实现成本高。另外该种场景通常需要业务部门与数据团队相配合,通过管理流程来实现表结构的同步。
问题四:历史快照表数据冗余
传统数据湖方案需要对历史的快照表进行存储,采用全量历史存储的方式实现,例如:天级历史快照表,每天都会全量存储全表数据。这样就造成了大量的数据存储冗余,占用大量的存储资源。
问题五:小批量增量数据处理成本高
传统数据湖为了实现增量ETL,通常将增量数据按照分区的方式进行存储,若为了实现T+0的数据处理,增量数据需要按照小时级或者分钟级的分区粒度。该种实现形式会导致小文件问题,大量分区也会导致元数据服务压力增大。
基于以上问题,华为FunsionInsight MRS集成Apache Hudi组件,希望通过Hudi组件来改善传统数据湖存在的问题。
二、MRS云原生数据湖Hudi的关键特性
Apache Hudi是数据湖的文件组织层,对Parquet等格式文件进行管理提供数据湖能力,支持多种计算引擎,提供IUD接口,在 HDFS/OBS的数据集上提供了插入更新和增量拉取的流原语,具有如下特点:
- 支持ACID
- 支持SnapShot数据隔离,保证数据读取完整性,实现读写并发能力
- 数据commit,数据入湖秒级可见
2. 快速Upsert能力
- 支持可插拔索引进制实现新增更新数据快速入湖
- 扩展Merge操作,实现新增、更新、删除混合数据同时入湖
- 支持写入同步小文件合并能力,写入数据自动按照预设文件大小进行文件合并
3. Schema Evolution
- 支持湖内数据schema的同步演进
- 支持多种常见schema变更操作
4. 多种视图读取接口
- 支持实时快照数据读取方式
- 支持历史快照数据读取方式
- 支持当前增量和历史增量数据读取方式
- 支持快速数据探索分析
5. 多版本
- 数据按照提交版本存储,保留历史操作记录,方便数据回溯
- 数据回退操作简单,速度快。
三、MRS-Hudi的典型应用场景
l 基于MRS-CDL组件实现数据实时入湖
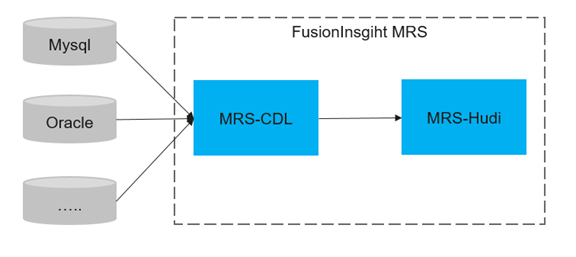
场景说明:
- 可以从业务数据库中直接抽取数据
- 数据入湖需要高实时性,秒级延迟
- 数据表变更需要与数据湖表结构实时同步
方案介绍:
该方案基于MRS-CDL组件构建,由CDL组件实现业务库的操作事件捕获并写入的基于MRS-Hudi的数据湖存储。
MRS-CDL是FusionInsight MRS推出的一种数据实时同步服务,旨在将传统OLTP数据库中的事件信息捕捉并实时推送到数据湖中去。该方案有以下特性支持:
- MRS-CDL支持捕获业务系统库的DDL和DML事件。
- 支持将MRS-Hudi作为数据目标端。
- 可视化操作,采集任务、入湖任务以及任务管理都是可视化操作。
- 入湖任务支持多租户,保证数据权限与湖内权限保持一致。
- 全程任务开发零代码,节省开发成本。
方案收益:
- 入湖操作简单,全程零代码开发。
- 入湖时效快,从业务系统数据调整到入湖,可在分钟内完成。
l 基于Flink SQL入湖
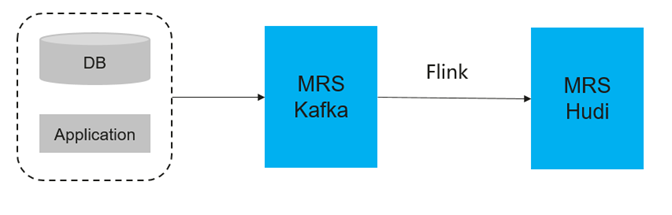
场景说明:
- 无需直接对接数据库,数据由已有采集工具发送到Kafka或者由业务系统直接发送到Kafka。
- 不需要实时同步DDL操作事件。
方案说明:
MRS的FlinkSQL入湖链路是基于Flink+Hudi成的。MRS-Flink以下特性支持该方案:
- 增加了Flink引擎与Hudi的对接能力。支持了对Hudi中COW表以及MOR表的读写操作。
- FlinkServer(Flink开发平台)增加了对Hudi的流量表支持。
- 作业开发与作业维护可视化操作。
方案收益:
- 入湖代码开发简单。
通过FlinkSQL实现入湖的语句如下:
Insert into table_hudi select * from table_kafka;
- 入湖时效快,最快可达秒级数据入湖。
l 湖内数据快速ETL
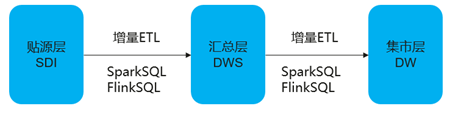
场景说明:
湖内数据通常会采用数仓分层存储,例如:贴源层(SDI)、汇总层(DWS)、集市层(DW),各家企业也会有不同的分层标准。数据在各层直接流转也会有相应的规范。传统数据湖通常采用天级全量数据ETL处理以实现各层之间数据流转。
现在Hudi支持ACID特性、Upsert特性和增量数据查询特性,可以实现增量的ETL,在不同层之间快速的流转。
增量ETL作业与传统ETL作业业务逻辑完全一样,涉及到的增量表读取采用commit_time来获取增量数据,在作业逻辑中的多表关联可以使Hudi表与Hudi表关联,也可以是Hudi表与存量Hive表的关联。 ETL作业开发可以基于SparkSQL、FlinkSQL开发。基于增量视图的ETL语句样例如下:Upsert table_dws select * from table_SDI where commit_time > “2021-07-07 12:12:12”。
由于采用了增量ETL方式,每次所处理的数据量也会下降,具体下降多少有赖于业务实际流量情况和增量的周期粒度。例如:物联网的业务数据,全天24小时流量稳定,采用10分钟级别的增量ETL,那么所处理的数量将全天数据量的1/(24*60/10)。因此在处理数据量大幅下降情况下,所需的计算资源也有相应的下降。
方案收益:
- 单个ETL作业处理时延降低,端到端时间缩短。
- 消耗资源下降,单位ETL作业所处理数据量大幅下降,所需计算资源也会相应下降。
- 原有湖内存储的模型无需调整。
l 支持交互式分析场景
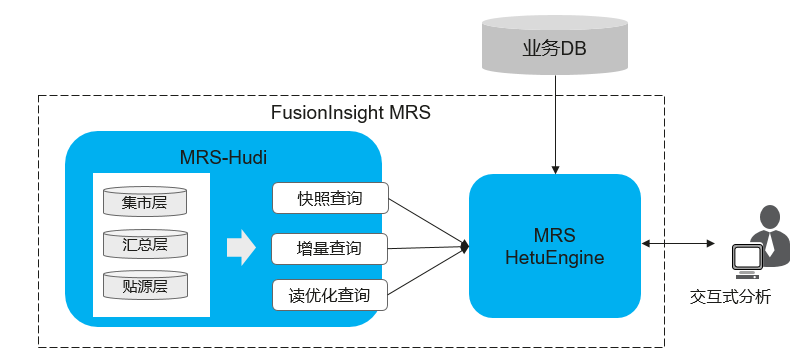
场景说明:
数据湖存储的数据具有数据种类全、维度多、历史周期长的特点,业务所需数据在数据湖中基本都是存在的,因此直接交互式分析引擎直接对接数据湖可以满足业务各类需求数据需求。
在数据探索、BI分析、报表展示等业务场景需要具备针对海量数据查询秒级返回的能力,同时要求分析接口简单SQL化。
方案说明:
在该场景中可以采用MRS-HetuEngine来实现该方案,MRS-HetuEngine是分布式高性能的交互式分析引擎,主要用于数据的快速实时查询场景。MRS-HetuEngine具备以下特性可以很好的支撑该场景:
- MRS-HetuEngine引擎已经完成与MRS-Hudi的对接,能够快速读取Hudi存储的数据。
- 支持读取快照查询,查询当前最新快照数据和历史快照数据。
- 支持增量查询,根据commit_time,查询任一时间段内的增量数据。
- 针对MOR存储模型,尤其在数据探索场景可以通过读优化查询接口,快速分析MOR模型的Hudi表数据。
- 支持多源异构协同,具备跨Hudi与其他DB的联合分析能力,例如:维度数据存在TP库中,可以实现数据湖的事实表与TP维度表的关联分析。
- 查询语句SQL化,支持JDBC接口。
方案收益:
- 结合MRS-CDL数据入湖,业务系统库数据变更可在分钟内实现在数据湖内可见。
- 对TB级到PB的数据量的交互式查询可达到秒级结果返回。
- 可对湖内各层数据进行分析。
l 基于Hudi构建批流一体
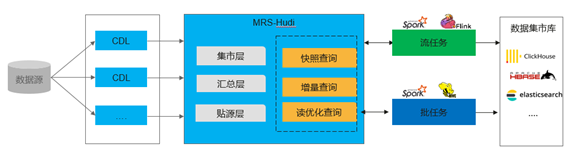
场景说明:
传统处理架构中采用Lambda或者Kappa架构。Lambda使用比较灵活,也可以解决业务场景,但是在该架构中需要两套系统来完成,维护比较复杂。数据分流以后也很难再关联应用。例如:流处理场景使用批处理的结果。Kappa架构是为实时处理的架构,该架构缺少了批处理的能力。
方案说明:
在很多实时场景中,对时延要求可以是分钟级的,这样可以通过MRS-Hudi和实时计算引擎Flink和Spark-Streaming进行增量计算实现数据的快速处理,端到端实现分钟级延迟。另外MRS-Hudi本身就是湖存储,可以存储海量数据,因此也可以支持批量计算,常用的批处理引擎可以采用Hive和Spark。
方案价值:
- 数据统一存储,实时数据与批量数据共用相同的存储。
- 同时支持实时计算与批量计算。相同业务逻辑的处理结果复用。
- 满足分钟级延时的实时处理能力和海量的批量处理。
四、总结
传统大数据由于不支持事务等痛点问题,造成T+1时延,虽然能够基于Flink流式计算实现少量数据在简单场景的秒级数据处理能力,但依然缺乏海量复杂场景的实时更新、事务支持能力。现在基于华为云FusionInsight MRS的Hudi可以构建分钟级数据处理方案,实现较大数据量的复杂计算实时处理能力,大大提升数据时效性,让数据价值近在眼前
基于MRS-Hudi构建数据湖的典型应用场景介绍的更多相关文章
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...
- 使用Apache Hudi + Amazon S3 + Amazon EMR + AWS DMS构建数据湖
1. 引入 数据湖使组织能够在更短的时间内利用多个源的数据,而不同角色用户可以以不同的方式协作和分析数据,从而实现更好.更快的决策.Amazon Simple Storage Service(amaz ...
- 构建数据湖上低延迟数据 Pipeline 的实践
T 摘要 · 云原生与数据湖是当今大数据领域最热的 2 个话题,本文着重从为什么传统数仓 无法满足业务需求? 为何需要建设数据湖?数据湖整体技术架构.Apache Hudi 存储模式与视图.如何解决冷 ...
- 基于Apache Hudi 构建Serverless实时分析平台
NerdWallet 的使命是为生活中的所有财务决策提供清晰的信息. 这涵盖了一系列不同的主题:从选择合适的信用卡到管理您的支出,到找到最好的个人贷款,再到为您的抵押贷款再融资. 因此,NerdWal ...
- 基于 RocketMQ Connect 构建数据流转处理平台
本文作者:周波,阿里云智能高级开发工程师, Apache RocketMQ Committer . 01 从问题中来的RocketMQ Connect 在电商系统.金融系统及物流系统,我们经常可以看到 ...
- 基于Apache Hudi构建分析型数据湖
为了有机地发展业务,每个组织都在迅速采用分析. 在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能. 通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
随机推荐
- Unity 代码调用重新生成csproj文件
结论 先放结论:editor代码中直接调用 Unity.CodeEditor.CodeEditor.CurrentEditor.SyncAll(); 原因 在一些操作后,比如修改csc.rsp的内容之 ...
- VK Cup 2016 - Round 1 (CF639)
A. Bear and Displayed Friends Div2 的题,不写. B. Bear and Forgotten Tree 3 这种东西怎么评蓝的? Description 给定 \(n ...
- P5445 [APIO2019] 路灯 题解
题目链接 题目描述 给你一个 01 串,有 \(q\) 个时刻,每个时刻要么把一位取反,要么问你在过去的所有时刻中有多少个时刻 \(a\) 和 \(b-1\) 之间都为 1. 题目分析 观察题目,我们 ...
- 会自动写代码的AI大模型来了!仅10秒就写出一个飞机大战游戏!
一.写在前面 昨天分享了一款可以帮我们写代码的插件CodeGeex,其实能帮我们解决大部分问题,讲道理已经很好了对不对? but,他就是最好的插件吗? 肯定不是,这不又让我又发现了一款可以平替的插件T ...
- Vue一些进阶知识-基于官网(笔记)
前言 主要根据vue官网文档完成.对一些平时可能会用到的知识.组件进行收集,为的是对vue的可用性有一个大致的了解.博客中的组件介绍可能只涉及简单用法,完整用法还是以官网为准. 基础 启动过程: 主文 ...
- 如何系统学习Python?
学习 Python 可以通过以下系统性的步骤进行: 1. 设定学习目标 确定你学习 Python 的主要目的,是为了编写脚本.数据分析.Web 开发.机器学习还是其他应用?理解这个目标可以帮助你更有针 ...
- 如何在langchain中对大模型的输出进行格式化
简介 我们知道在大语言模型中, 不管模型的能力有多强大,他的输入和输出基本上都是文本格式的,文本格式的输入输出虽然对人来说非常的友好,但是如果我们想要进行一些结构化处理的话还是会有一点点的不方便. 不 ...
- MODBUS转PROFINET网关TS-180 网关连接西门子 PLC 和工业称重仪表
随着科技的高速发展,工业自动化行业对日益多样的称重需求越来越高,上海某公司在国内的一个 工业自动化项目中,监控中心系统需要远程实时采集工业称重仪表测量的各种称重参数.该系统使用的是 西门子 S7-30 ...
- 用元编程来判断STL类型
在此之前,先来回顾元编程当中的一个重要概念. template<typename _Tp, _Tp __v> struct integral_constant { static con ...
- 写入数据或者通过EXCEl批量导入到数据库时报类型转换异常问题
报错日志如下(此处我用的是达梦,实际MySQL和oracle也会有类似的问题): Cause: org.apache.ibatis.type.TypeException: Error setting ...