使用 FHE 实现加密大语言模型
近来,大语言模型 (LLM) 已被证明是提高编程、内容生成、文本分析、网络搜索及远程学习等诸多领域生产力的可靠工具。
大语言模型对用户隐私的影响
尽管 LLM 很有吸引力,但如何保护好 输入给这些模型的用户查询中的隐私 这一问题仍然存在。一方面,我们想充分利用 LLM 的力量,但另一方面,存在向 LLM 服务提供商泄露敏感信息的风险。在某些领域,例如医疗保健、金融或法律,这种隐私风险甚至有一票否决权。
一种备选解决方案是本地化部署,LLM 所有者将其模型部署在客户的计算机上。然而,这不是最佳解决方案,因为构建 LLM 可能需要花费数百万美元 (GPT3 为 460 万美元),而本地部署有泄露模型知识产权 (intellectual property, IP) 的风险。
Zama 相信有两全其美之法: 我们的目标是同时保护用户的隐私和模型的 IP。通过本文,你将了解如何利用 Hugging Face transformers 库并让这些模型的某些部分在加密数据上运行。完整代码见 此处。
全同态加密 (Fully Homomorphic Encryption,FHE) 可以解决 LLM 隐私挑战
针对 LLM 部署的隐私挑战,Zama 的解决方案是使用全同态加密 (FHE),在加密数据上执行函数。这种做法可以实现两难自解,既可以保护模型所有者知识产权,同时又能维护用户的数据隐私。我们的演示表明,在 FHE 中实现的 LLM 模型保持了原始模型的预测质量。为此,我们需要调整 Hugging Face transformers 库 中的 GPT2 实现,使用 Concrete-Python 对推理部分进行改造,这样就可以将 Python 函数转换为其 FHE 等效函数。
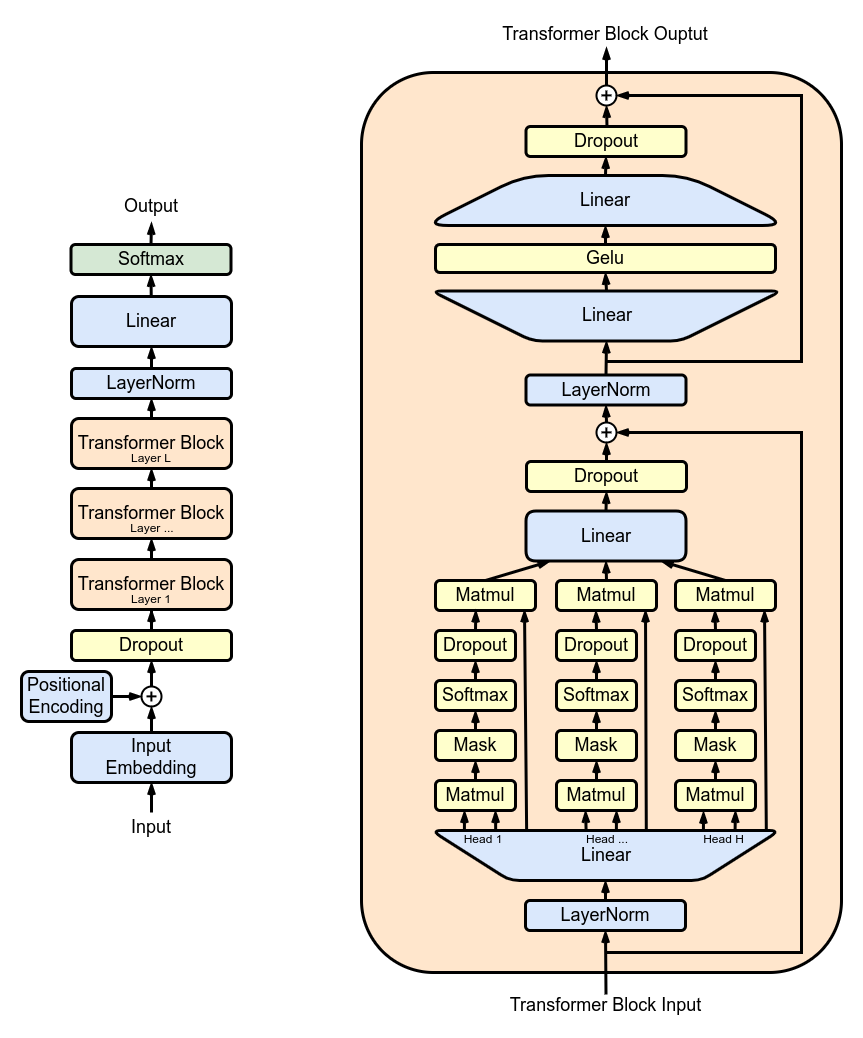
图 1 展示了由多个 transformer block 堆叠而成的 GPT2 架构: 其中最主要的是多头注意力 (multi-head attention,MHA) 层。每个 MHA 层使用模型权重来对输入进行投影,然后各自计算注意力,并将注意力的输出重新投影到新的张量中。
在 TFHE 中,模型权重和激活均用整数表示。非线性函数必须通过可编程自举 (Programmable Bootstrapping,PBS) 操作来实现。PBS 对加密数据实施查表 (table lookup,TLU) 操作,同时刷新密文以支持 任意计算。不好的一面是,此时 PBS 的计算时间在线性运算中占主导地位。利用这两种类型的运算,你可以在 FHE 中表达任何子模型的计算,甚至完整的 LLM 计算。
使用 FHE 实现 LLM 的一层
接下来,你将了解如何加密多头注意力 (MHA) 中的一个注意力头。你可以在 此处 找到完整的 MHA 实现代码。

图 2 概述了一个简化的底层实现。在这个方案中,模型权重会被分成两个部分,分别存储在客户端和服务端。首先,客户端在本地开始推理,直至遇到已第一个不在本地的层。用户将中间结果加密并发送给服务端。服务端对其执行相应的注意力机制计算,然后将结果返回给客户端,客户端对结果进行解密并继续在本地推理。
量化
首先,为了对加密值进行模型推理,模型的权重和激活必须被量化并转换为整数。理想情况是使用 训练后量化,这样就不需要重新训练模型了。这里,我们使用整数和 PBS 来实现 FHE 兼容的注意力机制,并检查其对 LLM 准确率的影响。
要评估量化的影响,我们运行完整的 GPT2 模型,并让其中的一个 LLM 头进行密态计算。然后我们基于此评估权重和激活的量化比特数对准确率的影响。
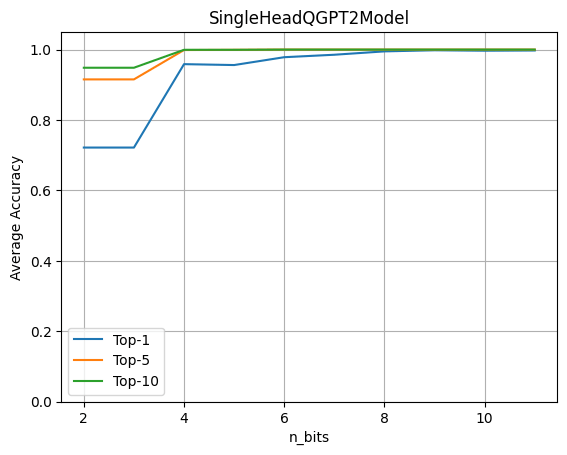
上图表明 4 比特量化保持了原始精度的 96%。该实验基于含有约 80 个句子的数据集,并通过将原始模型的 logits 预测与带有量化注意力头的模型的 logits 预测进行比较来计算最终指标。
在 Hugging Face GPT2 模型中使用 FHE
我们需要在 Hugging Face 的 transformers 库的基础上重写加密模块的前向传播,以使其包含量化算子。首先通过加载 GPT2LMHeadModel 构建一个 SingleHeadQGPT2Model 实例,然后手动使用 QGPT2SingleHeadAttention 替换第一个多头注意力模块,代码如下。你可以在 这里 找到模型的完整实现。
self.transformer.h[0].attn = QGPT2SingleHeadAttention(config, n_bits=n_bits)
至此,前向传播已被重载成用 FHE 算子去执行多头注意力的第一个头,包括构建查询、键和值矩阵的投影。以下代码中的 QGPT2 模块的代码见 此处。
class SingleHeadAttention(QGPT2):
"""Class representing a single attention head implemented with quantization methods."""
def run_numpy(self, q_hidden_states: np.ndarray):
# Convert the input to a DualArray instance
q_x = DualArray(
float_array=self.x_calib,
int_array=q_hidden_states,
quantizer=self.quantizer
)
# Extract the attention base module name
mha_weights_name = f"transformer.h.{self.layer}.attn."
# Extract the query, key and value weight and bias values using the proper indices
head_0_indices = [
list(range(i * self.n_embd, i * self.n_embd + self.head_dim))
for i in range(3)
]
q_qkv_weights = ...
q_qkv_bias = ...
# Apply the first projection in order to extract Q, K and V as a single array
q_qkv = q_x.linear(
weight=q_qkv_weights,
bias=q_qkv_bias,
key=f"attention_qkv_proj_layer_{self.layer}",
)
# Extract the queries, keys and vales
q_qkv = q_qkv.expand_dims(axis=1, key=f"unsqueeze_{self.layer}")
q_q, q_k, q_v = q_qkv.enc_split(
3,
axis=-1,
key=f"qkv_split_layer_{self.layer}"
)
# Compute attention mechanism
q_y = self.attention(q_q, q_k, q_v)
return self.finalize(q_y)
模型中的其他计算仍以浮点形式进行,未加密,并由客户端在本地执行。
将预训练的权重加载到修改后的 GPT2 模型中,然后调用 generate 方法:
qgpt2_model = SingleHeadQGPT2Model.from_pretrained(
"gpt2_model", n_bits=4, use_cache=False
)
output_ids = qgpt2_model.generate(input_ids)
举个例子,你可以要求量化模型补全短语 “Cryptography is a” 。在 FHE 中运行模型时,如果量化精度足够,生成的输出为:
“Cryptography is a very important part of the security of your computer”
当量化精度太低时,您会得到:
“Cryptography is a great way to learn about the world around you”
编译为 FHE
现在,你可以使用以下 Concrete-ML 代码编译注意力头:
circuit_head = qgpt2_model.compile(input_ids)
运行此代码,你将看到以下打印输出: “Circuit compiled with 8 bit-width”。该配置与 FHE 兼容,显示了在 FHE 中执行的操作所需的最大位宽。
复杂度
在 transformer 模型中,计算量最大的操作是注意力机制,它将查询、键和值相乘。在 FHE 中,加密域中乘法的特殊性加剧了成本。此外,随着序列长度的增加,这些乘法的数量还会呈二次方增长。
而就加密注意力头而言,长度为 6 的序列需要 11622 次 PBS 操作。我们目前的实验还很初步,尚未对性能进行优化。虽然可以在几秒钟内运行,但不可否认它需要相当多的计算能力。幸运的是,我们预期,几年后,硬件会将延迟提高 1000 倍到 10000 倍,使原来在 CPU 上需要几分钟的操作缩短到 ASIC 上的低于 100 毫秒。有关这些估算的更多信息,请参阅 此博文。
总结
大语言模型有望使能大量应用场景,但其实现引发了用户隐私的重大关切。在本文中,我们朝着密态 LLM 迈出了第一步,我们的最终愿景是让整个模型完全在云上运行,同时用户的隐私还能得到充分尊重。
当前的做法包括将 GPT2 等模型中的特定部分转换至 FHE 域。我们的实现利用了 transformers 库,用户还能评估模型的一部分在加密数据上运行时对准确率的影响。除了保护用户隐私之外,这种方法还允许模型所有者对其模型的主要部分保密。你可在 此处 找到完整代码。
Zama 库 Concrete 和 Concrete-ML (别忘了给我们的 github 代码库点个星星 ️) 允许直接构建 ML 模型并将其转换至等价的 FHE 域,从而使之能够对加密数据进行计算和预测。
希望你喜欢这篇文章。请随时分享你的想法/反馈!
英文原文: https://hf.co/blog/encrypted-llm
原文作者: Roman Bredehoft,Jordan Frery
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)
使用 FHE 实现加密大语言模型的更多相关文章
- 本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿.130亿.330亿 ...
- Hugging News #0324: 🤖️ 黑客松结果揭晓、一键部署谷歌最新大语言模型、Gradio 新版发布,更新超多!
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 使用 LoRA 和 Hugging Face 高效训练大语言模型
在本文中,我们将展示如何使用 大语言模型低秩适配 (Low-Rank Adaptation of Large Language Models,LoRA) 技术在单 GPU 上微调 110 亿参数的 F ...
- pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例)
pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例) Part1知识准备 在PyTorch中加载预训练的模型时,通常的工作流程是这样的: my_model = ModelClass ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- LLM(大语言模型)解码时是怎么生成文本的?
Part1配置及参数 transformers==4.28.1 源码地址:transformers/configuration_utils.py at v4.28.1 · huggingface/tr ...
- 大语言模型快速推理: 在 Habana Gaudi2 上推理 BLOOMZ
本文将展示如何在 Habana Gaudi2 上使用 Optimum Habana.Optimum Habana 是 Gaudi2 和 Transformers 库之间的桥梁.本文设计并实现了一个大模 ...
- .NET 证书加密 存储保存 IIS授权
最近接到一个任务,加密DotNet项目的配置文件.配置文件里需要加密的地方一共有两块,一个是数据库连接字符串,一个是自定义的所有AppSettings. 一开始接到这个任务我是拒绝的,因为压根不知道怎 ...
- 使用RSA加密方式加密文件
链接:GITHUB 使用RSA对流进行加密并保存到文件中 缺点:速度非常的慢,加密大文件就等着吧 环境 VS2017 + C# 7.0 + .net framwork 4.7.2
- 如何综合运用对称加密技术、非对称加密技术(公钥密码体制)和Hash函数 保证信息的保密性、完整性、可用性和不可否认性?
一.几个问题 在提出问题之前,先创建一个使用场景,发送方(甲方)要给接收方(乙方)发送投标书.大家知道,投标书都包括发送方的标的,这个标的是不能被竞标者知晓,更不能被竞标者修改的.在传输的投标书时,提 ...
随机推荐
- idea的git插件,可以显示每一行代码的git版本记录,很好用
再给大家推荐一款idea的git插件----GitToolBox,可以显示每一行代码的git版本记录,很好用 效果图如下 可以在光标所在行代码的后面显示git的版本记录信息(提交的用户名,提交的时间等 ...
- logstash 配置文件语法介绍
大家好,我是蓝胖子,之前在构建服务监控实践那个系列里,有提到用logstash来做日志的收集,但是对于logstash的配置文件语法没有做很详细的介绍,今天就来详细聊聊logstash配置文件的语法. ...
- 使用nacos配置,启动服务时一直报 Error starting ApplicationContext. To display the conditions report re-run your application with 'debug' enabled. APPLICATION FAILED TO START
报错日志如下: Error starting ApplicationContext. To display the conditions report re-run your application ...
- Vue2.0 学习 第三组 条件语句
本笔记主要参考菜鸟教程和官方文档编写.1.v-if在div或者之类的dom中使用v-if可以控制是否插入该dom,控制由v-if的true和false决定.如:<div id="app ...
- Filter拦截问题
关于Filter拦截问题 刚开始我创建了个servlet项目一直拦截不成功 首先是因为导包的问题 import javax.servlet.*; 必须是这个包才有 第一个这个Javax.se ...
- MybatisPlus查询时过滤不需要的字段~
解释一下:乍一看标题可能有点懵~,其实就是想查询的时候过滤掉某些字段 例如: select name,email,password from user; --改为-> select name,e ...
- FOJ有奖月赛-2015年11月 Problem B 函数求解
Problem B 函数求解 Accept: 171 Submit: 540Time Limit: 1000 mSec Memory Limit : 32768 KB Problem D ...
- 关于eclipse中找不到recyclerview的问题
在eclipse中直接引入v7包之后,还是找不到recyclerview的问题,我们可以通过 sdk\extras\android\support\v7\recyclerview\libs这个目录找到 ...
- python自动化测试相关资料
java神功: https://yuedu.baidu.com/ebook/10f4bf7530126edb6f1aff00bed5b9f3f80f7212 selenium书:https:// ...
- ChatGPT API来了 附调用方法及文档
3月1日,OpenAI 放出了ChatGPT API(GPT-3.5-turbo 模型),1000个tokens为$0.002美元,等于每输出 100 万个单词,价格才 2.7 美金(约 18 元人民 ...