基于pulp的线性优化问题:微电网日前优化调度(复现)
摘录来源:(71条消息) 微电网日前优化调度入门:求解一道数学建模题_我不是玉的博客-CSDN博客
学习记录与复现
问题描述
问题出自第十届“中国电机工程学会杯”全国大学生电工数学建模竞赛A题:微电网日前优化调度。
下图示意了一个含有风机、光伏、蓄电池及常见负荷的微电网系统。日前经济调度问题是指在对风机出力、光伏出力、常规负荷进行日前(未来24h)预测的基础上,考虑电网测的分时电价,充分利用微网中的蓄电池等可调控手段,使微电网运行的经济性最优。
。
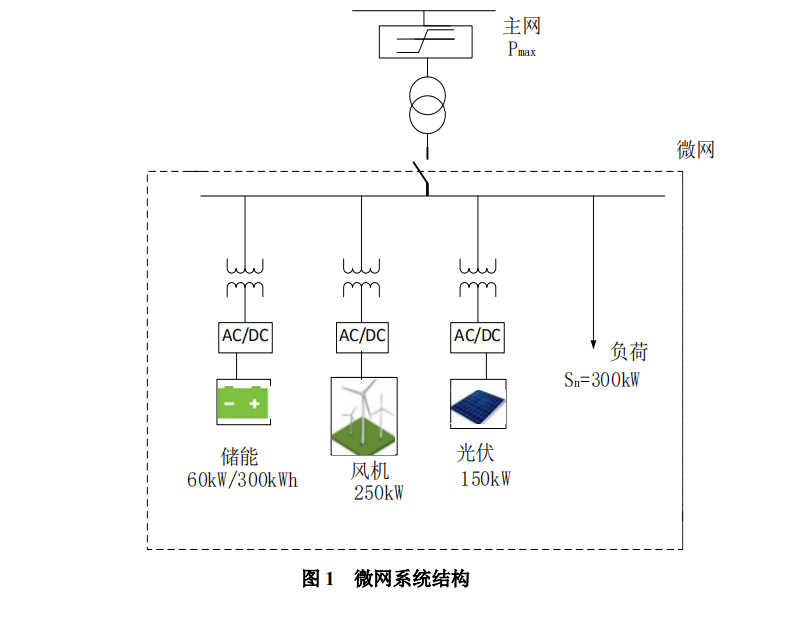
题目要求在如下已知条件下,求不同调度方案的平均用电成本:
- 未来24h、每隔15min共96个时间点的负荷、光伏、风机出力预测,及分时电价数据;
- 风机容量250kW,发电成本0.52元/kWh;
- 光伏容量150kW,发电成本0.75元/kWh;
- 蓄电池容量300kWh;SOC初始值0.4,运行范围[0.3, 0.95];由充电至放电成本为0.2元/kWh;日充放电次数限制均为8;忽略蓄电池损耗
完整问题描述参考:
风光储优化调度模型
题目涉及电网、新能源(风机、光伏)、蓄电池及负荷四类资源,我们依次建立其线性规划模型,然后交给求解器求解。一个线性规划模型包含:
- 设计变量:各类资源的实时出力数据
- 约束条件:能量平衡及各类资源应该满足的技术参数,例如蓄电池的容量限制、SOC限制、充放电次数限制等
- 目标函数:运行成本,具体到本题即用电成本
本文基于 Python 第三方库PuLP实现。PuLP是一个线性规划问题建模库,将数学模型转换为 MPS 或者 LP 文件,然后调用 LP 求解器如 CBC、GLPK、CPLEX、Gurobi 等求解。具体用法参考下面链接,本文不再赘述。
开始之前先抽象一个模型基类,表示各类调度设备,包含名称、容量、使用成本等基本属性,同时提供一个create_model()方法,用于实现设计变量、约束条件、目标函数等线性规划模型三要素。模型求解后,调用output属性获取变量值,即每个时刻的出力。
import pulp
import numpy as np
class Model:
def __init__(self, name:str,
capacity:float, # resource capacity
unit_cost:float): # unit cost when using the energy
'''Base class for resource model, e.g., Grid, Renewable and Storage.'''
# technical parameters
self.name = name
self.capacity = capacity
self.unit_cost = unit_cost
# linear programming model: variables, constraints and objective
self.variables = None
self.constraints = None
self.objective = None
def create_model(self, time_points:int, dt:float):
'''How to create the LP model.'''
raise NotImplementedError
@property
def output(self): return np.array([v.value() for v in self.variables])
接下来依次建立电网、新能源(风机、光伏)及蓄电池的模型。
(1) 电网模型
电网模型继承自Model基类,同时新增了 卖电收益 属性,并且满足容量约束即每个时刻的出力不能超过限定值,目标函数为运行成本即用电费用与卖电收益的差值。
直观地,任意时刻可以用一个变量 来表示电网的出力:正值表示从电网买电,或者负值表示卖电给电网。但是,事先并不知道 的正负,也就没法计算此刻的运行成本(不能将线性规划变量直接用于if-else语句中)。因此,引入买电、卖电两个中间变量来分开描述:
- 表示 i 时刻从电网买电量;
- 表示 i 时刻向电网卖电量;
因为同一时刻电流只能单向流动,即 和至少有一个等于0:。
但这并不是一个合法的线性约束,需要再引入一个0-1变量:
- :1 表示从电网买电即,0 表示卖电到电网即
于是线性约束表示为:
其中,C为电网容量(交换功率)限制值,上限。
最终,电网 i 时刻实际出力 及用电成本(买电或卖电):
其中,分别为该时刻单位买电成本、卖电收益(元/kWh),dt 为时间步长。
class Grid(Model):
def __init__(self, name:str,
capacity:float,
unit_cost:np.ndarray, # unit cost when buying electricity from utility grid
unit_profit:np.ndarray): # unit profit when selling electricity to utility grid
super().__init__(name, capacity, unit_cost)
self.unit_profit = unit_profit
def create_model(self, time_points:int, dt:float):
# define variables at each time point
vars_from = [pulp.LpVariable(name=f'{self.name}_from_{i}', lowBound=0) for i in range(time_points)]
vars_to = [pulp.LpVariable(name=f'{self.name}_to_{i}', lowBound=0) for i in range(time_points)]
self.variables = [v1-v2 for v1,v2 in zip(vars_from, vars_to)]
# constraints: capacity limit
# 0<=var_from<=C*b
# 0<=var_to<=C*(1-b)
self.constraints = []
vars_b = [pulp.LpVariable(name=f'{self.name}_binary_{i}', cat=pulp.LpInteger) for i in range(time_points)]
for v1,v2,b in zip(vars_from, vars_to, vars_b):
self.constraints.append(v1<=self.capacity*b)
self.constraints.append(v2<=self.capacity*(1-b))
# objective
self.objective = pulp.lpSum([v*x for v,x in zip(vars_from, self.unit_cost)])*dt - \
pulp.lpSum([v*x for v,x in zip(vars_to, self.unit_profit)])*dt
(2) 新能源发电模型
将风机和光伏抽象为新能源发电模型,约束条件为 每一时刻的电力供应不大于预测出力,如果不允许弃风弃光的话,则等于预测出力值。因此,在Model类基础上增加两个输入参数:
- forecast:每一时刻的出力预测,即一个列向量/数组/时间序列;
- allow_curtailment:是否允许弃风弃光,默认允许。
相应地,提供一个utilization输出属性表示新能源发电的实际利用率。
class Renewable(Model):
def __init__(self, name:str,
capacity:float,
unit_cost:float,
forecast:np.ndarray, # forecasting output
allow_curtailment:bool=True): # allow curtailment or not
super().__init__(name, capacity, unit_cost)
self.forecast = forecast
self.allow_curtailment = allow_curtailment
def create_model(self, time_points:int, dt:float):
# define variables at each time point
self.variables = [pulp.LpVariable(name=f'{self.name}_{i}', lowBound=0) for i in range(time_points)]
# constraints: v<=forecast
if self.allow_curtailment:
self.constraints = [v<=x for v,x in zip(self.variables, self.forecast)]
else:
self.constraints = [v==x for v,x in zip(self.variables, self.forecast)]
# objective
self.objective = pulp.lpSum(self.variables)*self.unit_cost*dt
@property
def utilization(self): return self.output.sum() / self.forecast.sum()
(3) 蓄电池模型
原题已经给出了蓄电池的混合整数规划数学模型,除了基类中的容量、单位用电成本外,还有如下主要参数:
- capacity_limit:爬坡限制值,即原题公式(5)中的数值 20%
- init_soc:初始SOC状态
- soc_limit:电量范围SOC限制
- cycle_limit:充放电次数限制
参考原题的约束:
- 爬坡约束:公式(3)(5)
- 容量约束:公式(1)(2)
- 调度周期始末电量相等:公式(4)
- 充放电次数约束:公式(6)




类比上文对电网买电、卖电行为的建模,同一时刻也需要三个中间变量:充电功率 、放电功率、充放电0-1状态(1-放电,0-充电)来描述电池的出力。前三个约束的实现不再赘述,下面重点解析充放电次数约束。
充放电状态序列,引入辅助的0-1变量 t表示相邻状态相减的绝对值,即
当 时,即相邻的充放电状态由0变成了1,或者由1变成了0,表示完成了一次充放电周期。于是总的充放电次数限制约束可以表示为:
那么如何将含有绝对值的等式 变换为线性约束呢?结合本文场景,将等式松弛一下:
- 正是我们需要计数的情况;
- 没有增加计数,此时 表明并未发生充放电状态变化,恰好可以对应上。
于是,上述绝对值等式约束等效为:
class Storage(Model):
def __init__(self, name:str,
capacity:float,
unit_cost:float,
capacity_limit:float, # charging / discharging ramping limit
init_soc:float, # initial state of charge
soc_limit:list, # SOC limit
cycle_limit:int): # charing / discharging cycle counts limit
super().__init__(name, capacity, unit_cost)
self.init_soc = init_soc
self.soc_limit = soc_limit
self.cycle_limit = cycle_limit
self.capacity_limit = capacity_limit
def create_model(self, time_points: int, dt: float):
# define variables at each time point
vars_ch = [pulp.LpVariable(name=f'{self.name}_charge_{i}', lowBound=0) for i in range(time_points)]
vars_dis = [pulp.LpVariable(name=f'{self.name}_discharge_{i}', lowBound=0) for i in range(time_points)]
self.variables = [v1-v2 for v1,v2 in zip(vars_dis, vars_ch)]
# constraints 1: ramping limit
# 0<=var_dis<=C*b
# 0<=var_ch<=C*(1-b)
self.constraints = []
vars_b = [pulp.LpVariable(name=f'{self.name}_binary_{i}', cat=pulp.LpInteger) for i in range(time_points)]
C = self.capacity * self.capacity_limit
for v1,v2,b in zip(vars_dis, vars_ch, vars_b):
self.constraints.append(v1<=C*b)
self.constraints.append(v2<=C*(1-b))
# constraints 2: SOC limit
soc = self.init_soc
s1, s2 = self.soc_limit
for v1,v2 in zip(vars_ch, vars_dis):
soc += (v1*dt - v2*dt) / self.capacity
self.constraints.append(soc>=s1)
self.constraints.append(soc<=s2)
# constraints 3: same SOC at the scheduling end
self.constraints.append(pulp.lpSum(self.variables)==0)
# constraints 4: charging / discharging cycle limit
# t = |b_i-b_{i+1}|
# sum(t)<=N
vars_db = [vars_b[i+1]-vars_b[i] for i in range(time_points-1)]
vars_t = [pulp.LpVariable(name=f'{self.name}_binary_t_{i}', cat=pulp.LpInteger) for i in range(time_points-1)]
for db, t in zip(vars_db, vars_t):
self.constraints.append(db>=-t)
self.constraints.append(db<=t)
self.constraints.append(pulp.lpSum(vars_t)<=self.cycle_limit)
# objective
self.objective = pulp.lpSum(vars_dis)*self.unit_cost*dt
(4) 风光储优化调度模型
最后,我们抽象出一个微电网类,包含上述能源设备resources及负荷load,同时引入系统能量平衡约束,建立最终的优化模型。其中的几个方法:
- optimize():建模和求解过程
- operation_cost:目标函数值即总用电费用
- average_cost:平均用电成本
import matplotlib.pyplot as plt
class MicroGrid:
def __init__(self, resources:list, load:np.ndarray, time_step:float) -> None:
self.resources = resources
self.load = load
self.time_step = time_step
# create problem: minimize the operation cost
self.prob = pulp.LpProblem(name='microgrid_optimization', sense=pulp.LpMinimize)
@property
def operation_cost(self): return self.prob.objective.value()
@property
def average_cost(self): return self.operation_cost / (self.load.sum()*self.time_step)
def optimize(self):
'''Micro-grid operation optimization.'''
# collect resources models
d_variables, constraints, objective = [], [], 0.0
time_points = self.load.size
for resource in self.resources:
resource.create_model(time_points, self.time_step)
d_variables.append(resource.variables)
constraints.extend(resource.constraints)
objective += resource.objective
# add constraints: resource level
for c in constraints: self.prob += c
# add constraint: energy balance
for i in range(time_points):
_vars = [variables[i] for variables in d_variables]
self.prob += pulp.lpSum(_vars)==self.load[i]
# objective
self.prob += objective
# solve
self.prob.solve()
# output
self._summary()
def _summary(self):
print(f'Status: {pulp.LpStatus[self.prob.status]}')
print(f'全天总供电费用:{round(self.operation_cost,4)} 元,负荷平均购电单价:{round(self.average_cost,4)} 元/kWh')
# plot
for r in self.resources: plt.plot(r.output, label=r.name)
plt.plot(self.load, label='load')
plt.legend()
求解典型场景
根据上文建立的优化调度模型,求解提问中的不同调度策略。
先导入全天96个时刻的时间序列数据:
(1) 经济性评估方案
问题:微网中蓄电池不作用,微网与电网交换功率无约束,无可再生能源情况下,分别计算各时段负荷的供电构成(kW)、全天总供电费用(元)和负荷平均购电单价(元/kWh)。
这一问不用优化模型也能解,多余的电卖给电网、不足的电从电网购买即可,参考这篇文章的解析过程。但既然我们已经建立了统一的优化调度模型,本例只要引入电网一种资源,将其作为一个特例直接求解即可。
因为电网交换功率没有限制,直接设一个较大的数例如10^6即可。
# set a large value 1e6 as no limit on energy exchanging with grid
grid = Grid(name='grid', capacity=1e6, unit_cost=unit_cost, unit_profit=unit_profit)
# microgrid
resources = [grid]
mg = MicroGrid(resources=resources, load=data_load, time_step=15/60) # 15min
mg.optimize()
输出:
Status: Optimal
全天总供电费用:1976.4142 元,负荷平均购电单价:0.5976 元/kWh
12
问题:微网中蓄电池不作用,微网与电网交换功率无约束,可再生能源全额利用情况下,分别计算各时段负荷的供电构成(kW)、全天总供电费用(元)和负荷平均购电单价(元/kWh)。
这一问将风机和光伏加入微网,同时注意设置不可弃风弃光(可再生能源全额利用)
# set a large value 1e6 as no limit on energy exchanging with grid
grid = Grid(name='grid', capacity=1e6, unit_cost=unit_cost, unit_profit=unit_profit)
# wind turbine: allow_curtailment=False
wt = Renewable(name='wind', capacity=250, unit_cost=0.52, forecast=data_wt, allow_curtailment=False)
# pv: allow_curtailment=False
pv = Renewable(name='pv', capacity=150, unit_cost=0.75, forecast=data_pv, allow_curtailment=False)
# microgrid
resources = [grid, wt, pv]
mg = MicroGrid(resources=resources, load=data_load, time_step=15/60) # 15min
mg.optimize()
print(f'弃风率:{round(1-wt.utilization,4)},弃光率:{round(1-pv.utilization, 4)}')
输出:
Status: Optimal
全天总供电费用:2275.1698 元,负荷平均购电单价:0.6879 元/kWh
弃风率:0.0,弃光率:0.0
因为限定全额利用可再生能源,所以弃风弃光率都是0。风机、光伏的用电成本较高,即便可以将风机、光伏的电卖给电网,其最终收益还不如低电价时刻从电网直接买电,所以全额利用可再生能源情况下,这一小问的平均用电成本高于上一问的纯网电。
(2) 最优日前调度方案一
问题:不计蓄电池作用,微网与电网交换功率无约束,以平均负荷供电单价最小为目标(允许弃风弃光),分别计算各时段负荷的供电构成(kW)、全天总供电费用(元)和平均购电单价(元/kWh),分析可再生能源的利用情况。
这个调度方案是在上一问的基础上允许弃风弃光,即合理选择使用新能源发电还是网电。同样,我们设置输入参数,然后交给优化模型即可。注意和上一段代码的唯一区别是设置允许弃风弃光 allow_curtailment=True。
# set a large value 1e6 as no limit on energy exchanging with grid
grid = Grid(name='grid', capacity=1e6, unit_cost=unit_cost, unit_profit=unit_profit)
# wind turbine: allow_curtailment=True
wt = Renewable(name='wind', capacity=250, unit_cost=0.52, forecast=data_wt, allow_curtailment=True)
# pv: allow_curtailment=True
pv = Renewable(name='pv', capacity=150, unit_cost=0.75, forecast=data_pv, allow_curtailment=True)
# microgrid
resources=[grid, wt, pv]
mg = MicroGrid(resources=resources, load=data_load, time_step=15/60) # 15min
mg.optimize()
print(f'弃风率:{round(1-wt.utilization,4)},弃光率:{round(1-pv.utilization, 4)}')
输出:
Status: Optimal
全天总供电费用:1785.1532 元,负荷平均购电单价:0.5397 元/kWh
弃风率:0.5399,弃光率:0.6923
因为可以根据经济最优选择合适的电力来源,这一调度方案的平均用电成本低于前两问。例如,凌晨时段网电电价本来就低,所以选择直接弃掉此时的风机和光伏电力(参见弃风弃光率);网电峰电时段择机考虑风电和光伏。这篇文章 从电价解析的角度分析了这个问题,人为分析的策略与本文优化的结果很接近,可以作为参考。
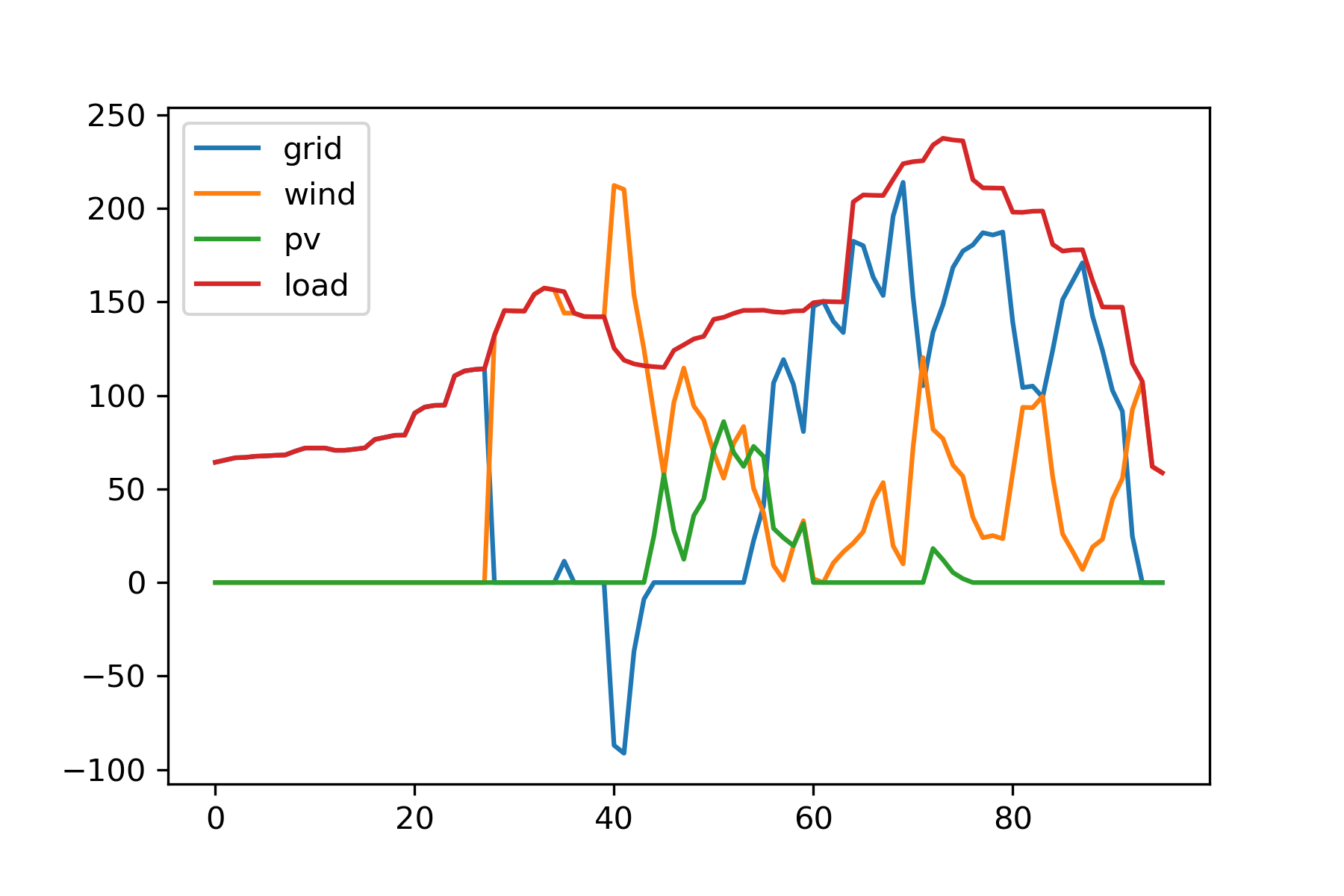
(3) 最优日前调度方案二
问题:考虑蓄电池作用,且微网与电网允许交换功率不超过150kW,在可再生能源全额利用的条件下,以负荷平均供电单价最小为目标,建立优化模型,给出最优调度方案,包括各时段负荷的供电构成(kW)、全天总供电费用(元)和平均购电单价(元/kWh),分析蓄电池参与调节后产生的影响。
这个调度方案在基础场景(1)第二问的基础上引入了蓄电池,同时限制了电网交换功率。
# grid
grid = Grid(name='grid', capacity=150, unit_cost=unit_cost, unit_profit=unit_profit)
# wind turbine
wt = Renewable(name='wind', capacity=250, unit_cost=0.52, forecast=data_wt, allow_curtailment=False)
# pv: allow_curtailment=False
pv = Renewable(name='pv', capacity=150, unit_cost=0.75, forecast=data_pv, allow_curtailment=False)
# battery: allow_curtailment=False
bt = Storage(name='battery', capacity=300, unit_cost=0.2, capacity_limit=0.2, init_soc=0.4, soc_limit=[0.3,0.95], cycle_limit=8)
# microgrid
resources=[grid, wt, pv, bt]
mg = MicroGrid(resources=resources, load=data_load, time_step=15/60) # 15min
mg.optimize()
print(f'弃风率:{round(1-wt.utilization,4)},弃光率:{round(1-pv.utilization, 4)}')
输出:
Status: Optimal
全天总供电费用:2210.4672 元,负荷平均购电单价:0.6683 元/kWh
弃风率:0.0,弃光率:0.0
123
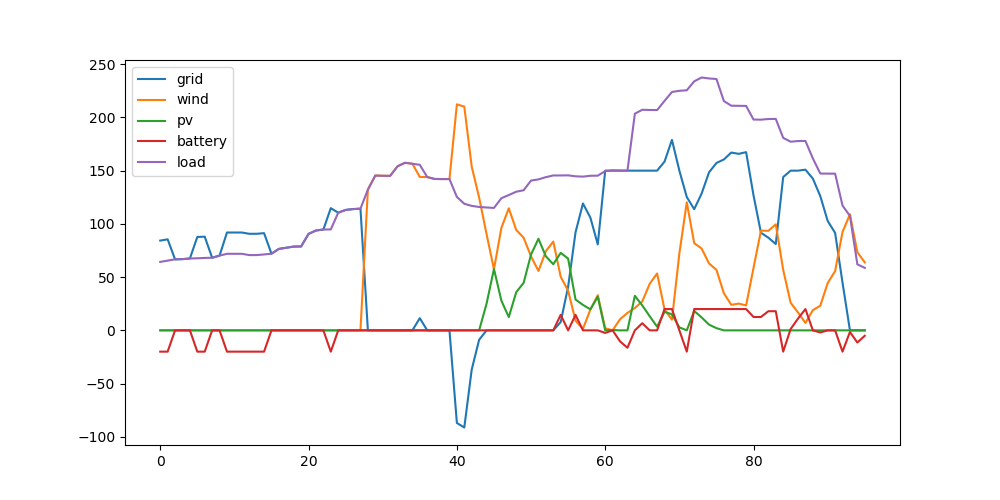
相比基础场景(1)第二问的平均用电成本0.6879,本方案用电成本有所降低。结合下图具体调度可知,蓄电池将凌晨高成本的新能源电力转移到了网电的峰电时段,因此比直接在凌晨时段卖高成本的新能源电力更为划算。这篇文章也解答了本问题,可以作为参考。
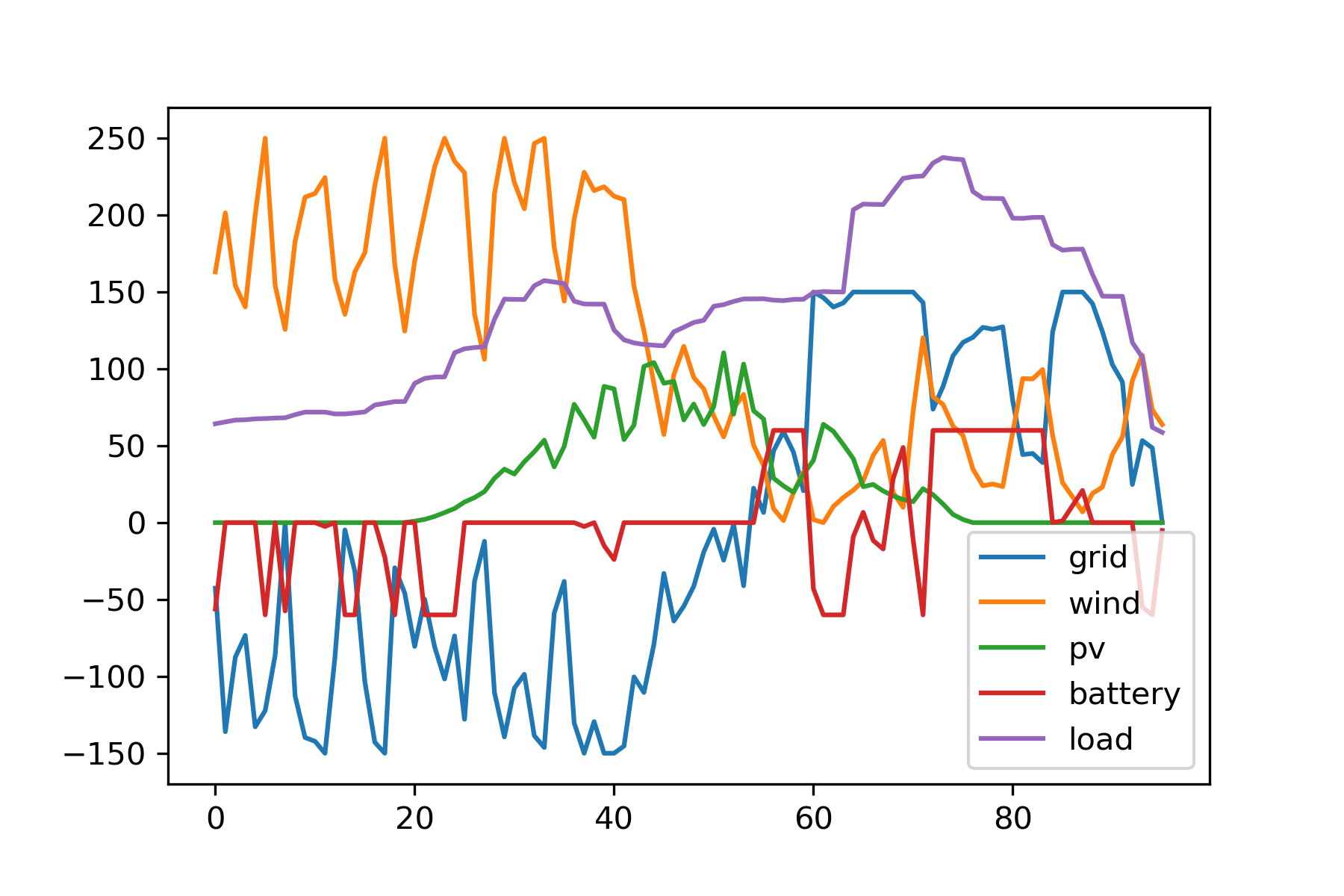
(4) 最优日前调度方案三
问题:考虑蓄电池作用,且微网与电网允许交换功率不超过150kW,以负荷供电成本最小为目标(允许弃风弃光),建立优化模型,给出最优调度方案,包括各时段负荷的供电构成(kW)、全天总供电费用(元)和平均购电单价(元/kWh),分析可再生能源的利用情况及蓄电池参与调节后产生的影响。
这一调度方案是在问题(3)的基础上允许弃风弃光,同理略作修改即可。
# grid
grid = Grid(name='grid', capacity=150, unit_cost=unit_cost, unit_profit=unit_profit)
# wind turbine
wt = Renewable(name='wind', capacity=250, unit_cost=0.52, forecast=data_wt, allow_curtailment=True)
# pv: allow_curtailment=True
pv = Renewable(name='pv', capacity=150, unit_cost=0.75, forecast=data_pv, allow_curtailment=True)
# battery: allow_curtailment=True
bt = Storage(name='battery', capacity=300, unit_cost=0.2, capacity_limit=0.2, init_soc=0.4, soc_limit=[0.3,0.95], cycle_limit=8)
# microgrid
resources=[grid, wt, pv, bt]
mg = MicroGrid(resources=resources, load=data_load, time_step=15/60) # 15min
mg.optimize()
print(f'弃风率:{round(1-wt.utilization,4)},弃光率:{round(1-pv.utilization, 4)}')
输出
Status: Optimal
全天总供电费用:1733.5558 元,负荷平均购电单价:0.5241 元/kWh
弃风率:0.5383,弃光率:0.6494
相比问题(3),本方案允许放弃高电价的新能源电力,因此可以进一步降低平均用电成本;相比问题(2),本方案多了蓄电池的调节作用(峰谷电价转移),因此也降低了平均用电成本,同时因为电池对新能源的消纳,本方案相对问题(2)也略微降低了弃风弃光率。
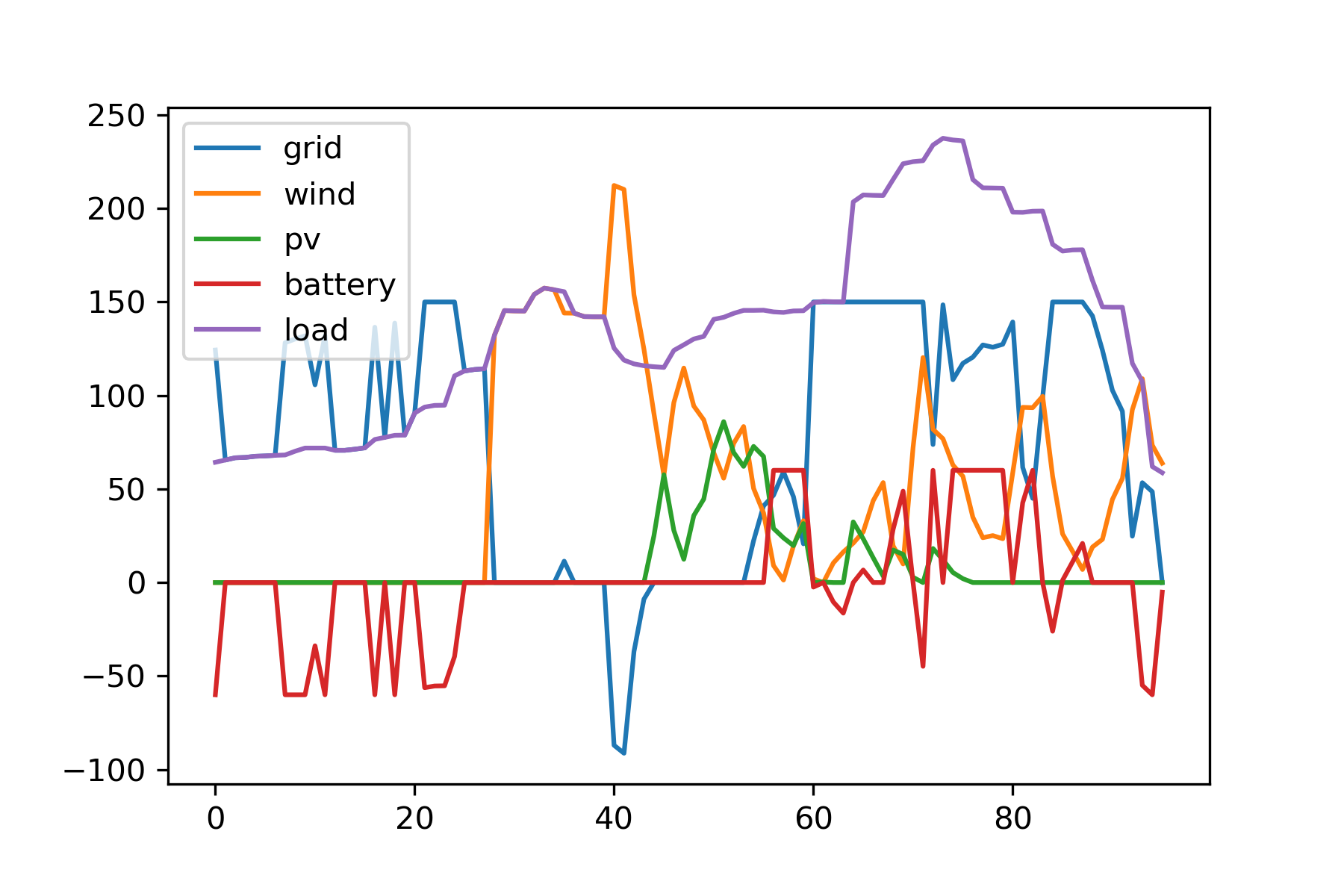
在调度方法三的基础上,调整储能容量为100kw
Status: Optimal
全天总供电费用:1773.9713 元,负荷平均购电单价:0.5364 元/kWh
弃风率:0.5383,弃光率:0.6494
PuLP库
PuLP是一个开源的第三方工具包,可以求解线性规划、整数规划、混合整数规划问题。
(1)定义一个规划问题
self.prob = pulp.LpProblem(
name='microgrid_optimization',
sense=pulp.LpMinimize)
pulp.LpProblem 是定义问题的构造函数。
"microgrid_optimization"是用户定义的问题名。
参数 sense 用来指定求最小值/最大值问题,可选参数值:LpMinimize、LpMaximize 。
(2)定义决策变量
# 在每个时间点定义变量 define variables at each time point
vars_from = [
pulp.LpVariable(
name=f'{self.name}_from_{i}',
lowBound=0) for i in range(time_points)] # 每个时刻的买电量
vars_to = [
pulp.LpVariable(
name=f'{self.name}_to_{i}',
lowBound=0) for i in range(time_points)] # 每个时刻的卖电量
vars_b = [
pulp.LpVariable(
name=f'{self.name}_binary_{i}',
cat=pulp.LpInteger) for i in range(time_points)]
pulp.LpVariable 是定义决策变量的函数。
f'{self.name}from'’ 是用户定义的变量名。
参数 lowBound、upBound 用来设定决策变量的下界、上界;可以不定义下界/上界,默认的下界/上界是负无穷/正无穷。
参数 cat 用来设定变量类型,可选参数值:‘Continuous’ 表示连续变量(默认值)、’ Integer ’ 表示离散变量(用于整数规划问题)、’ Binary ’ 表示0/1变量(用于0/1规划问题)。
(3)求解
# Solve the optimization problem
status = model.solve()
调用的是 puip 内置的 CBC求解器
PuLP也很容易集成各种开源或者商业的线性规划求解器。
PuLP函数库只能用于线性模型,非线性问题需要用其他的。
CBC 是开源基金会 COIN-OR (Computational Infrastructure for Operations Research) 开发的线性规划求解器。该基金会开发了大量的运筹学工具,截止 2011 年,已经开发并维护了 48 个项目。
(4)其他求解器
线性整数规划问题的各种求解器的评测结果如下所示:
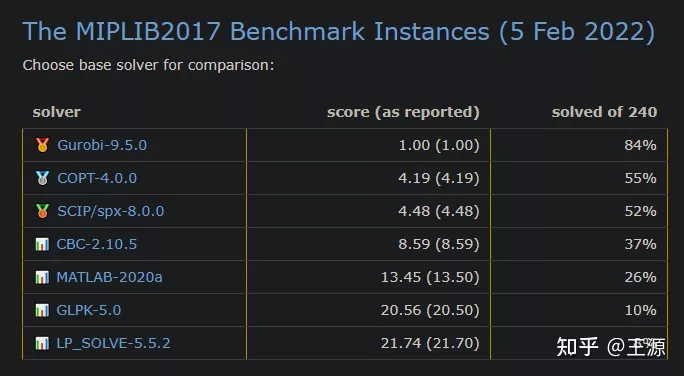
图中最左边一列是各种参与测试的求解器。可以看到第一行的求解器是 Gurobi 9.5.0 版本,它排名所有求解器中第一名。第二行的求解器是 COPT 4.0.0 版本,它排名所有求解器中第二名,以此类推。中间一列是各种求解器的求解速度,以求解速度第一名的 Gurobi 9.5.0 为单位。第二名的 COPT 4.0.0 求解时间是第一名的4.19倍。(以上排名仅针对线性整数规划问题,其它规划问题也可以在上述评测网站上查阅到)。
需要注意的是上述排名中的求解器分为商业求解器(商用需要付费)和开源求解器(商用无需付费)两大类:
商业求解器:Gurobi, COPT, SCIP/spx, Matlab
开源求解器:CBC, GLPK, LP_SOLVE
- 商业求解器 Gurobi, COPT, SCIP/spx 都可以非常方便的申请学术版授权,如果仅仅是做学术研究的话,学术版授权完全就足够了。当然学术版授权只能用于非商业目的的学术研究,如想以商业为目的话,要么购买商业版授权,要么采用开源求解器。
- 商业求解器的效果远远好于开源求解器,开源求解器中最好的是CBC,它的求解时间也要比商业求解器中最好的Gurobi要慢8.59倍。
- 商业求解器的价格大致在5-200瓶茅台的价格之间,一般来说排名越靠前的求解器价格越高。以上价格仅供参考,具体价格还要结合授权类型,授权年限,多核心支持,多用户支持等服务内容。
其他求解器的介绍干货 | 运筹学、数学规划、离散优化求解器大PK,总有一款适合你 - 腾讯云开发者社区-腾讯云 (tencent.com)
线性规划求解器总结与比较 | Blog of Zhikun Zhang (zhangzhk.com)
【整数规划(十一)】整数规划求解器简介 - 知乎 (zhihu.com)
其他优化工具库
(1)ortools系列:运筹优化工具google ortools简介
ortools系列:运筹优化工具google ortools简介 - 知乎 (zhihu.com)
OR-Tools是一个用于优化的开源软件套件,用于解决车辆路径、流程、整数和线性规划以及约束编程等世界上最棘手的问题。
同时OR-Tools提供了C++,Python,Java,.NET的接口,同时提供统一接口封装来调用商业求解器如Gurobi, CPLEX等,也包括开源求解器如SCIP, GLPK, ortools等。提供运筹优化工具统一接口的概念和coin-or正在做的事情有点像呢。
当前ortools提供的优化器包括: - 约束规划 - 线性与混合整数规划 - 路径规划 - 调度规划 - 网络规划 - 装箱
通过查阅官方提供的案列,基本能解决大部分的优化问题,美中不足的是,装箱问题提供的只要背包问题解法,对于三维装箱问题,需要使用约束规划来求解。
ortools文档托管在developers.google.cn上,需要越墙,所以我把官方文档copy了一份到github上,地址是:google_ortools_guide
(2)CVXOPT
CVXOPT 实际上是一个凸优化工具包,并自带有线性规划求解器,但效率不是很高。但它可以调用外部求解器 [8],包括 GLPK, MOSEK 和 DSDP。
CVXOPT 的使用方法可以参考它的官方文档 [9]。
(3)CVXPY
CVXPY 是 Stanford 的 Steven Boyd 课题组开发的,做凸优化的同学肯定看过他的《Convex Optimization》这本书。CVXPY 也可以用 conda 进行安装:
1 2 |
conda install -c conda-forge lapack conda install -c cvxgrp cvxpy |
|---|---|
CVXPY 是一个纯粹的 python 优化工具接口,它本身并没有实现任何求解器,都是根据问题类型调用相应的外部求解器 [10],然后解析结果。对于线性规划问题,可以调用外部的 CBC, GLPK, CPLEX, GUROBI, MOSEK 等。需要注意的是,当需要调用 CBC 时,必须先安装其官方 python 接口 CyLP;当需要调用 CPLEX 时也需要先安装其官方 python 接口。
CVXPY 的建模过程非常直观,可以使用 numpy 的 ndarray。具体使用方法可以参考它的官方文档 [11]
(4)Pyomo
Pyomo 是基于 Python 的开源软件包,主要功能是建立数学规划模型,包括线性规划,二次规划,整数规划,随机规划,含有微分代数方程的优化问题。
这里需要注意两个问题:
- Pyomo 只负责建模,求解还需要调用求解器来求解
- Pyomo 是开源免费的,但是只能适用于Python环境
你可能会产生一个疑问,在Gurobi/Cplex之类的求解器中也可以直接写模型啊,为何还需要专门单独搞一个Pyomo来写模型呢?主要是因为如下原因:
- Pyomo 的建模功能比一般求解器中自带的建模功能强大,例如 Pyomo 可以建模含有微分方程约束的优化问题,可以建模随机规划问题。这些都是 Gurobi/Cplex 所不具备的。
- 采用 Pyomo 建模可以实现一次建模,通用求解。在 Pyomo 中建模后 可以非常方便地调用其它多种求解器来求解,例如 Gurobi,Cplex,SCIP,CBC等。
所以是否选用 Pyomo 大家可以根据以上两条对照自己的需求来决定。最后 Pyomo 的安装也非常方便,在Anaconda环境中直接采用pip即可安装
pip install pyomo
本文章中完整代码在GitHub中可以下载到,按照代码对照本文学习起来更加高效:
https://github.com/WenYuZhi/Pyo
Pyomo支持全功能编程语言中的分析和脚本编制。此外,Pyomo还证明了开发高级优化和分析工具的有效框架。例如,PySP包提供了随机规划的通用求解程序。PySP利用了Pyomo的建模对象嵌入在功能全面的高级编程语言中的事实,这种语言允许使用Python并行通信库透明地并行化子问题。
(5)Geatpy遗传和进化算法框架
Python遗传和进化算法框架
Geatpy是一个高性能实用型的Python遗传算法工具箱,提供一个面向对象的进化算法框架,经过全面改版后,新版Geatpy2目前由华南农业大学、暨南大学、华南理工等本硕博学生联合团队开发及维护。
- Website (including documentation): http://www.geatpy.com
- Demo : https://github.com/geatpy-dev/geatpy/tree/master/geatpy/demo
- Pypi page : geatpy · PyPI
- Contact us: 关于 – Geatpy
- Bug reports: Issues · geatpy-dev/geatpy · GitHub
- Notice: 公告 – Geatpy
- FAQ: 常见问题 – Geatpy
Geatpy提供了许多已实现的遗传和进化算法相关算子的库函数,如初始化种群、选择、交叉、变异、重插入、多目标优化非支配排序等,并且提供诸多已实现的进化算法模板来实现多样化的进化算法。其执行效率高于Matlab、Java和Python编写的一些知名工具箱、平台或框架等,学习成本低、模块高度脱耦、扩展性高。
Geatpy支持二进制/格雷码编码种群、实数值种群、整数值种群、排列编码种群。支持轮盘赌选择、随机抽样选择、锦标赛选择。提供单点交叉、两点交叉、洗牌交叉、部分匹配交叉(PMX)、顺序交叉(OX)、线性重组、离散重组、中间重组等重组算子。提供简单离散变异、实数值变异、整数值变异、互换变异等变异算子。支持随机重插入、精英重插入。支持awGA、rwGA、nsga2、快速非支配排序等多目标优化的库函数、提供进化算法框架下的常用进化算法模板等。
关于遗传算法、进化算法的学习资料,在官网中https://www.geatpy.com 有详细讲解以及相关的学术论文链接。
基于pulp的线性优化问题:微电网日前优化调度(复现)的更多相关文章
- 近期业务大量突增微服务性能优化总结-3.针对 x86 云环境改进异步日志等待策略
最近,业务增长的很迅猛,对于我们后台这块也是一个不小的挑战,这次遇到的核心业务接口的性能瓶颈,并不是单独的一个问题导致的,而是几个问题揉在一起:我们解决一个之后,发上线,之后发现还有另一个的性能瓶颈问 ...
- JS组件系列——基于Bootstrap Ace模板的菜单Tab页效果优化
前言:之前发表过一篇 JS组件系列——基于Bootstrap Ace模板的菜单和Tab页效果分享(你值得拥有) ,收到很多园友的反馈,当然也包括很多诟病,因为上篇只是将功能实现了,很多细节都没有处理 ...
- 基于Spring Cloud、JWT 的微服务权限系统设计
基于Spring Cloud.JWT 的微服务权限系统设计 https://gitee.com/log4j/pig https://github.com/kioyong/spring-cloud-de ...
- Cola Cloud 基于 Spring Boot, Spring Cloud 构建微服务架构企业级开发平台
Cola Cloud 基于 Spring Boot, Spring Cloud 构建微服务架构企业级开发平台: https://gitee.com/leecho/cola-cloud
- Spring Boot 是 Spring 的一套快速配置脚手架,可以基于Spring Boot 快速开发单个微服务
Spring Boot 是 Spring 的一套快速配置脚手架,可以基于Spring Boot 快速开发单个微服务,Spring Cloud是一个基于Spring Boot实现的云应用开发工具:Spr ...
- Tomcat 8.5 基于 Apache Portable Runtime(APR)库性能优化
Tomcat可以使用Apache Portable Runtime来提供卓越的性能及可扩展性,更好地与本地服务器技术的集成.Apache Portable Runtime是一个高度可移植的库,位于Ap ...
- 基于 orange(nginx+openresty) + docker 实现微服务 网关功能
摘要 基于 orange(nginx+openresty) + docker 实现微服务 网关功能 ;以实现 docker 独立容器 来跑 独立语言独立环境 在 同一个授权下 运行相关组合程序..年初 ...
- 039.[转] 基于 Kubernetes 和 Spring Cloud 的微服务化实践
http://dockone.io/article/2967 基于 Kubernetes 和 Spring Cloud 的微服务化实践 写在前面 网易云容器平台期望能给实施了微服务架构的团队提供完整的 ...
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
- JVM性能优化系列-(6) 晚期编译优化
6. 晚期编译优化 晚期编译优化主要是在运行时做的一些优化手段. 6.1 JIT编译器 在部分的商用虚拟机中,java程序最初是通过解释器(Interpreter) 进行解释执行的,当虚拟机发现某个方 ...
随机推荐
- 在 RedHat、 CentOS、 Fedora 和 Debian、 Ubuntu、 Linux Mint、 Xubuntu 等这些系统中安装 Teamviewer
这篇指南介绍了怎么样在 RedHat. CentOS. Fedora 和 Debian. Ubuntu. Linux Mint. Xubuntu 等这些系统中安装 Teamviewer 9.Teamv ...
- mongodb基础整理篇————副本原理篇[外篇]
前言 简单介绍一下副本集的原理篇. 正文 下面是几个基本的原理: 副本之间是如何复制的? mongodb 实现此功能的方式是保存操作日志,其中包含了主节点执行的每一次操作,这和mysql比较像. op ...
- IIS 出现405
前言 在一次配置服务器中,出现一个问题,那就是使用put和delete 出现405. 当时我蒙了,调试的时候好好的,部署405. 原因是put和delete是非简单请求,也就是说非安全请求了. 这时候 ...
- nohup训练pytorch模型时的报错以及tmux的简单使用
问题: 在使用nohup命令后台训练pytorch模型时,关闭ssh窗口,有时会遇到下面报错: WARNING:torch.distributed.elastic.agent.server.api:R ...
- 07cj031,07CJ03-1图集免费下载
简介 07CJ03-1轻钢龙骨石膏板隔墙.吊顶图集是中国建筑标准设计研究院组织编写的一部针对轻钢龙骨.石膏板材料用于非承重隔墙.室内吊顶装修的装修.建造参考资料,为用户提供专业的建造参考 下载 有需要 ...
- 飞桨PaddlePaddle的安装
飞桨PaddlePaddle的安装 MacOS 下的 PIP 安装 一.环境准备 1.1 如何查看您的环境 可以使用以下命令查看本机的操作系统和位数信息: uname -m && ca ...
- HarmonyOS NEXT应用开发之异常处理案例
介绍 本示例介绍了通过应用事件打点hiAppEvent获取上一次应用异常信息的方法,主要分为应用崩溃.应用卡死以及系统查杀三种. 效果图预览 使用说明: 点击构建应用崩溃事件,3s之后应用退出,然后打 ...
- KubeVela v1.3 多集群初体验,轻松管理应用分发和差异化配置
简介:KubeVela v1.3 在之前的多集群功能上进行了迭代,本文将为你揭示,如何使用 KubeVela 进行多集群应用的部署与管理,实现以上的业务需求. 作者:段威(段少) 在当今的多集群业务 ...
- 走近Quick Audience,了解消费者运营产品的发展和演变
简介: Quick Audience产品是一款云原生面向消费者的营销产品,自诞生以来,经历了三个发展阶段.每个阶段的转变,都与互联网环境和消费者行为的变迁有着极大的关联. Quick Audien ...
- 技术干货 | 应用性能提升 70%,探究 mPaaS 全链路压测的实现原理和实施路径
简介: 全链路压测方案下,非加密场景下至少有 70% 的性能提升,加密场景下 10%的性能提升,并在 MGS 扩容完成后可实现大幅的性能提升,调优的结果远超预期. 业务背景 随着移动开发行业的步 ...