Spark Streaming快速入门
Spark Streaming快速入门
一、简介
Spark Streaming 是构建在 Spark Core 基础之上的流处理框架(但实际上是微批次处理框架),是 Spark 非常重要的组成部分。严格意义上来讲,Spark Streaming 是一个准实时,微批次的流处理框架。
特点:Easy to use:简单易用;
Unified batch and streaming APIs:统一的 API(统一了批处理和流处理的 API);
Low latency and cost effective:构建低延迟流应用程序和有效的成本管理。
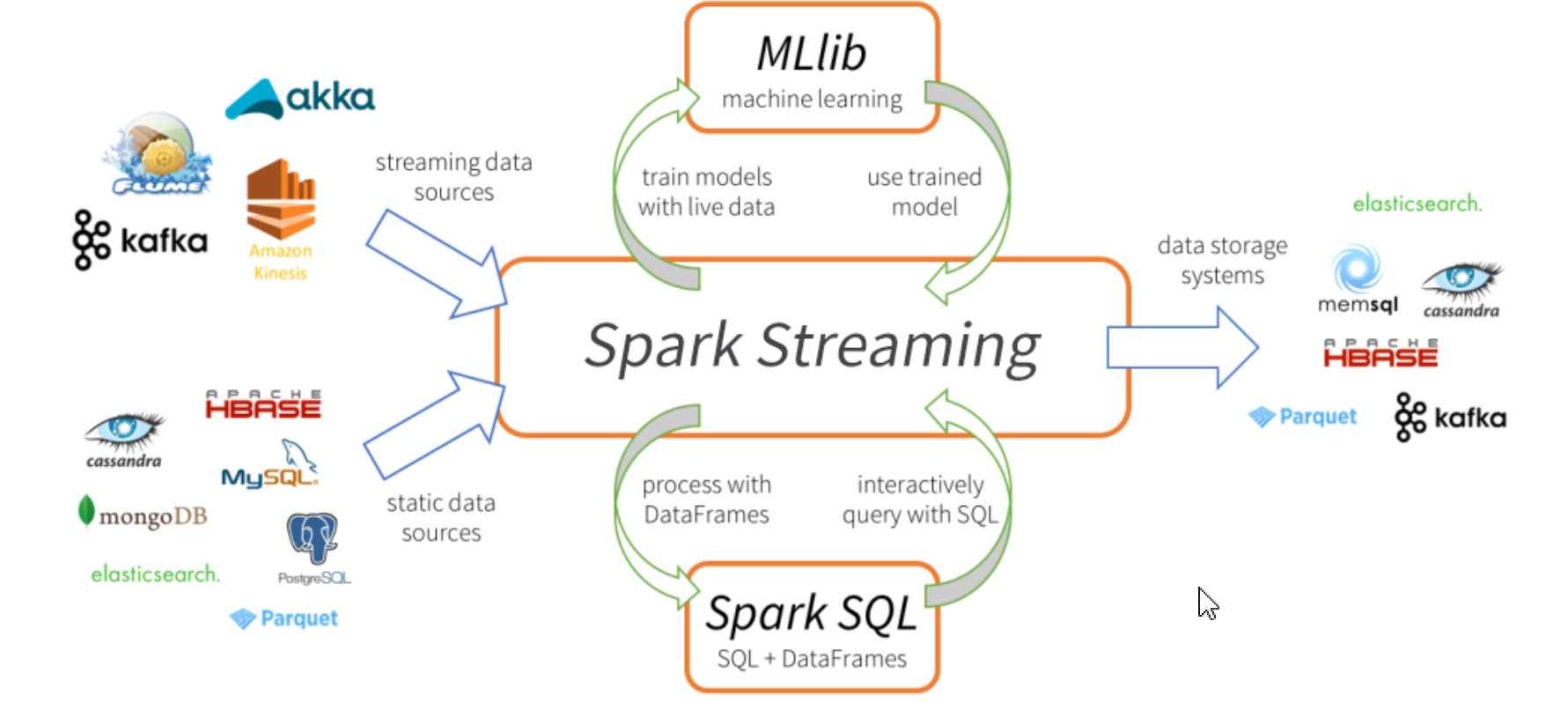
- 计算流程
数据源:实时计算的数据源头都在哪里?以各大电商网站为例,实时的用户行为日志(点击、收藏、购买等)。除此之外,比 较热门的还有一些比如说,实时的金融系统、实时的舆情监控系统,接收的都是实时的金融交易数据、实时的社会上的一 些舆论数据(微博、微信、博客及各种社交平台)
消息中间件:缓冲大数据读写,否则系统会撑不住!常用的中间件是kafka
分布式:从中间件中拉取数据,分布式架构并行处理,增加了实时计算的能力。
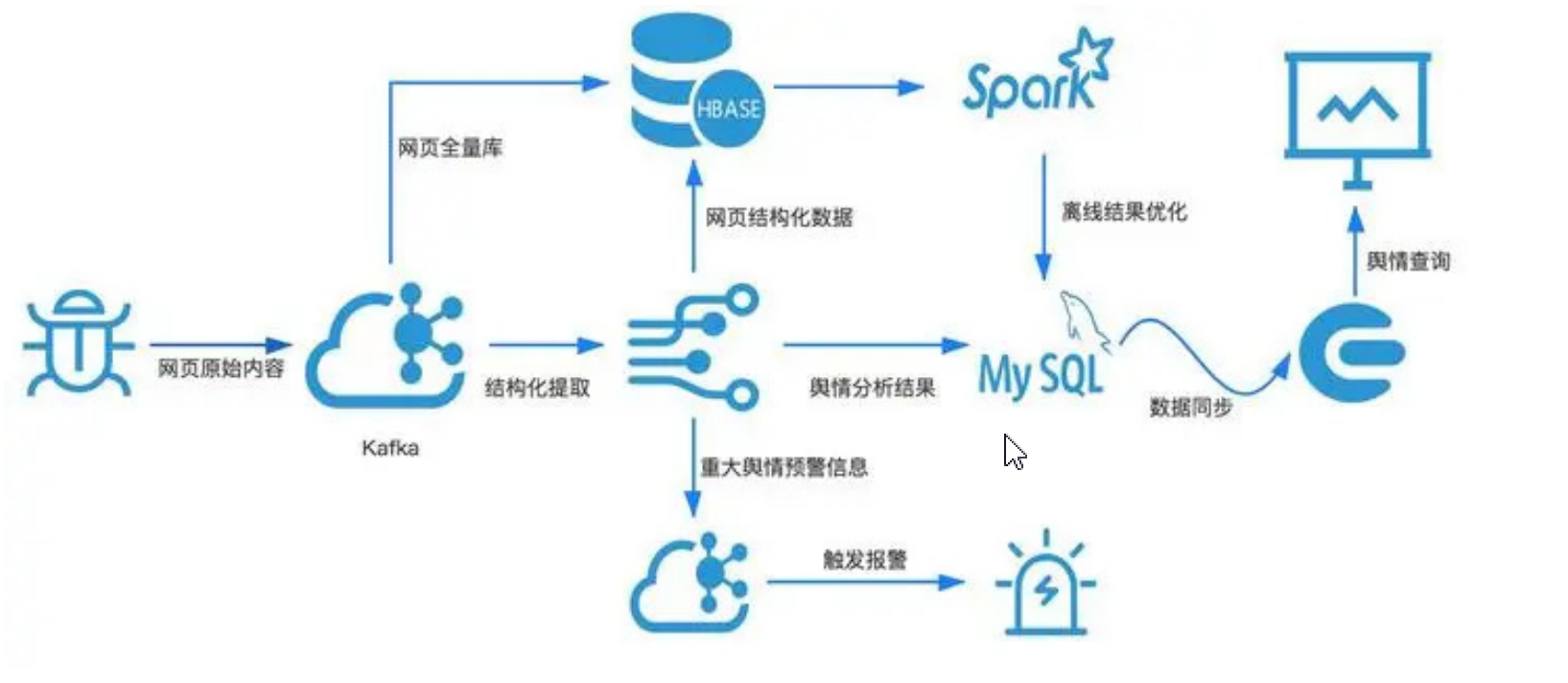
二、数据模型
- DStream
DStream把一系列时间上连续的RDD,使用离散化流进行封装,即:DStream = Seq[RDD]
- DStream和RDD的关系
DStream与RDD是包含关系,DStream对RDD功能进行增强,行为和RDD是基本相差不大。DStream可以从各种输入源创建,比如Flume、kafka、HDFS,创建的DStream可以通过转化操作变成新的DStream。另一种是输出操作,可以把数据写入外部系统中。
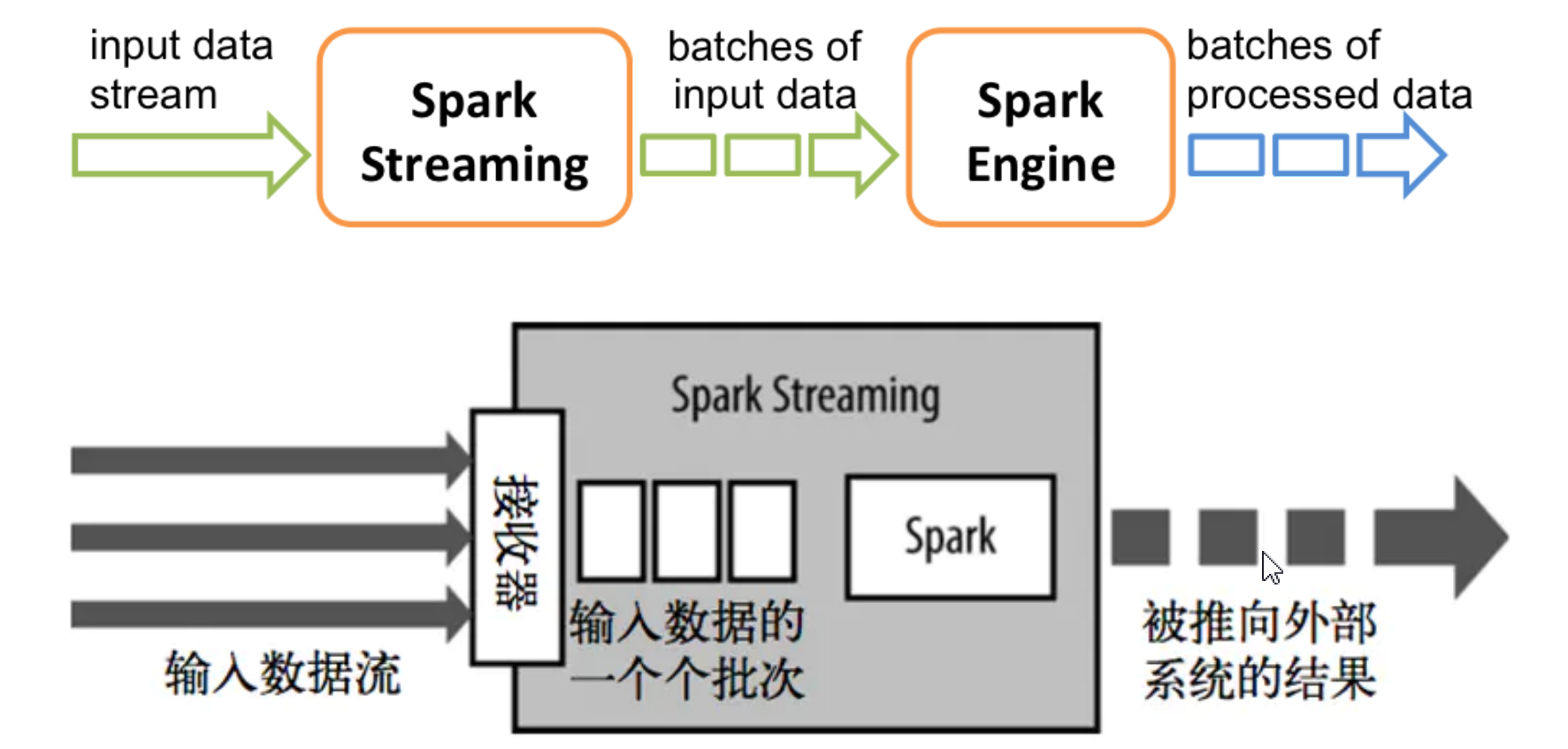
三、工作原理
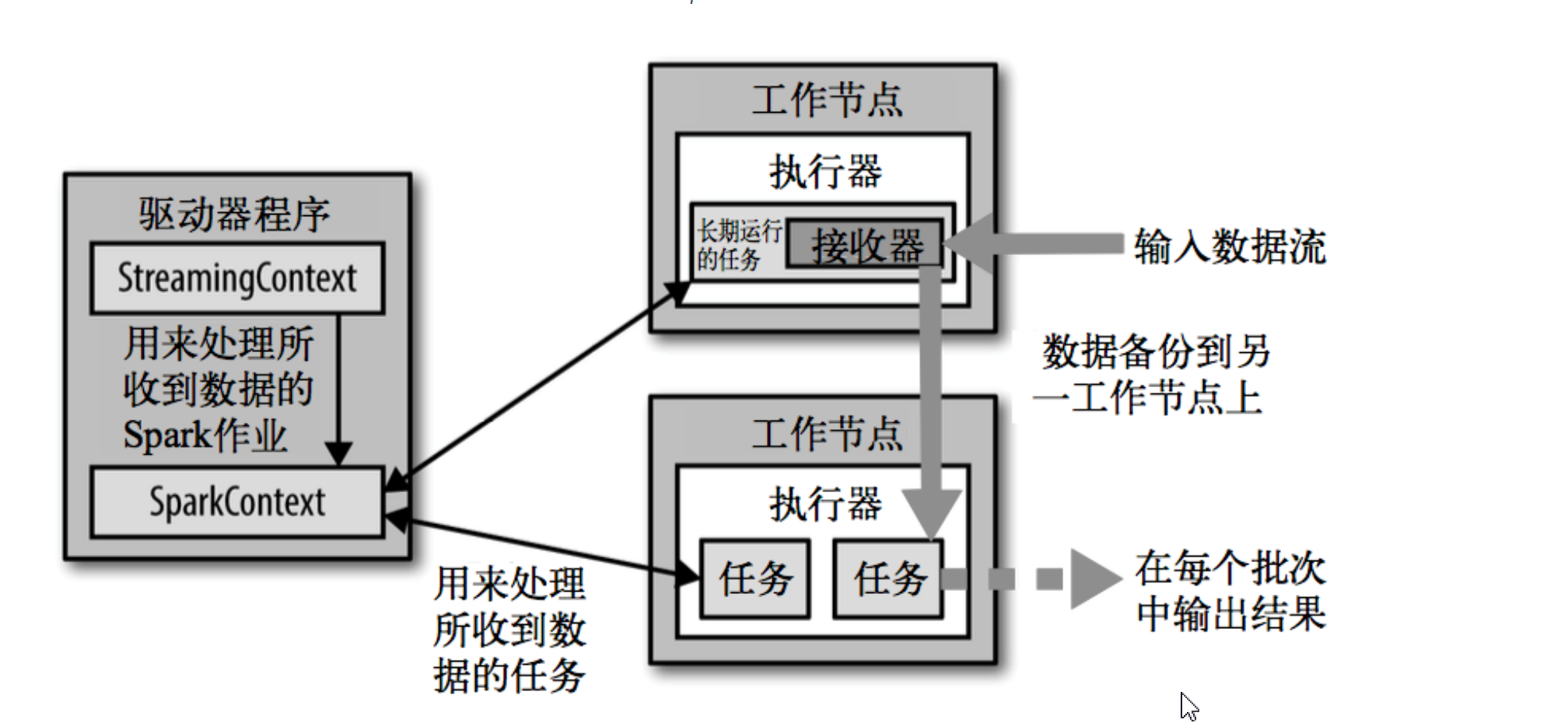
SparkStream从输入源获取源数据,把Spark Streaming的输入数据按照batch size分成一段一段的数据,每一段数据都转换spark中的RDD。然后Spark Streaming对DStream的转换操作变成spark对RDD的转换操作,最后将中间结果保存在内存中,整个流式计算根据业务的需求可以对中间的结果进行叠加或存储到外部设备。
接收器接收到数据会把数据复制到另一个执行器进程来保障容错性,数据保存在执行器进程内存中,和RDD缓存一样。驱动器程序中的StreamingContext会周期性地运行Spark作业来处理这些数据,把这些数据与之前时间区间中的RDD进行整合。
Spark Streaming 架构由三个模块组成:
Client:负责向 Spark Streaming 中灌入数据(Flume Kafka)
Worker: 从网络接收数据并存储到内存中 执行 RDD 计算
Master:记录 DStream 之间的依赖关系或者血缘关系,并负责任务调度以生成新的 RDD
- 输入算子(数据源)
基本数据源(内置的):通过文件系统或 Socket 连接接收的数据创建 Dstream;
自定义数据源:通过自定义接收器接收的数据流创建 Dstream.
第三方数据源:通过 Kafka,Flume 等灌入 Spark Streaming 的数据流创建 Dstream。
- 转换算子
与Spark core中转换算子一样!DStream 上的算子操作与 RDD 类似,分为 Transformations(转换)和 Output Operations(输出)两种,
此外转换 操作中还有一些比较特殊的算子,如:updateStateByKey()、transform() 以及各种 Window 相关的算子。
- 特殊的转换算子
transform算子:transform 允许 DStream 上执行任意的 RDD 函数,即使这些函数并没有在 DStream 的 API 中暴露出来,通过该函数可以很方便的扩展 Spark Streaming API。该函数每一批次会调度一次。在transform函数中不调用rdd参数,一个批次只执行一次(Driver 端周期性执行)。

- 无状态转换
无状态转换就是把 RDD 的转换操作简单的应用到每个批次上,也就是只转换 DStream 中的每个 RDD 一次。部分无状态转换操作如下。在整个流上一样,但事实上每个 DStream 在内部是由许多 RDD(批次)组 成,且无状态转化操作是分别应用到每个 RDD 上的。
- 有状态转换
spark将应用程序状态存储在内部或者分布式文件系统中。由于spark是一个分布式系统,因此需要保护本地状态防止在应用程序或计算机故障时数据丢失。spark定期将应用程序状态的一致性检查点写入远程且持久的存储,来保证数据有状态!
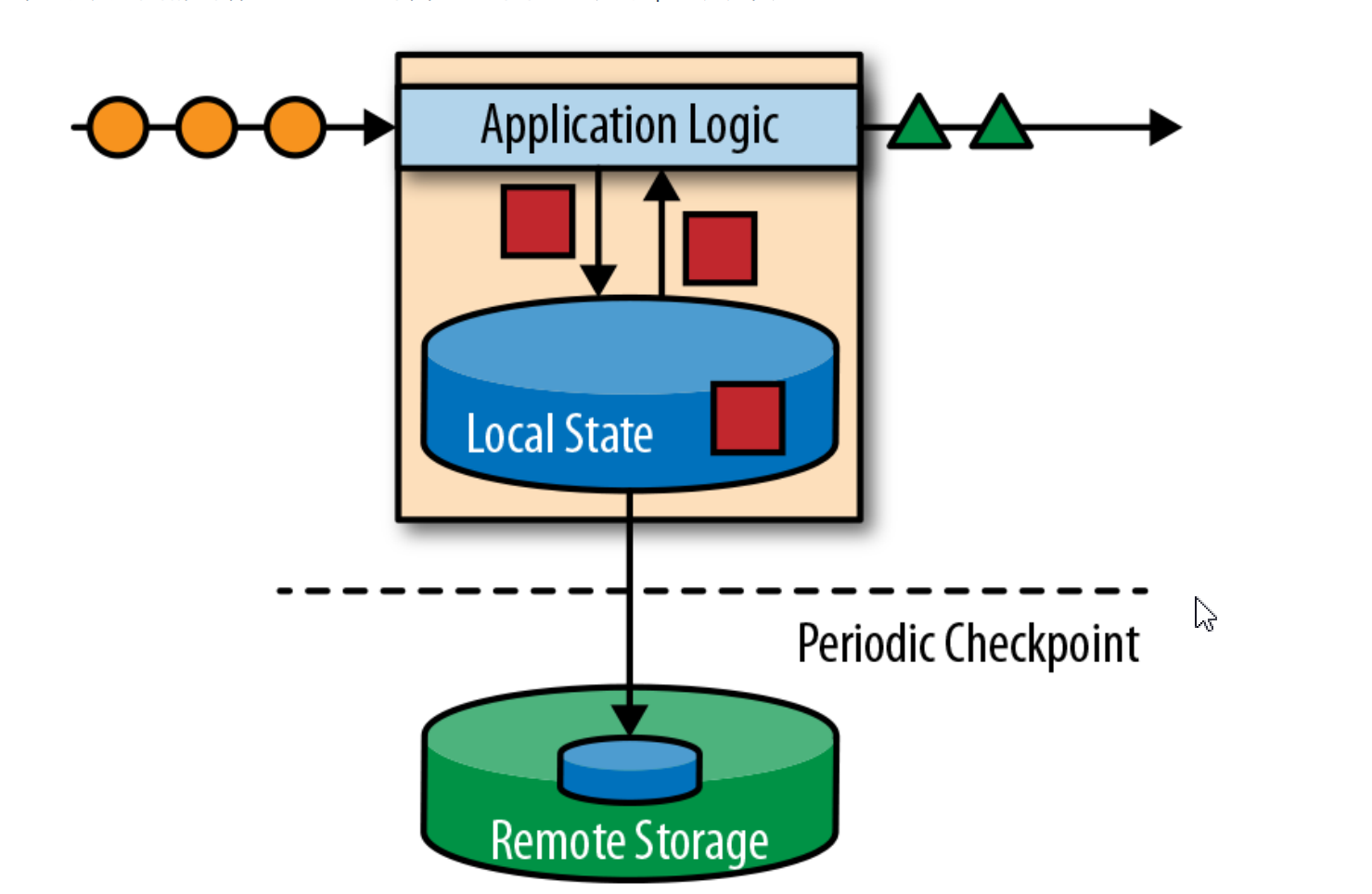
updateStateByKey:根据RDD的key保存每个value值的状态,通过每个Key值的状态进行数据流的批处理。而且每次计算都会返回上一次的状态数据,性能要低。
mapWithState:保存每个RDD的状态,进行批处理计算,但是mapWithState算子可以设置超时时间,之前批次超时的有状态的数据会被忽略,在后面重新计算,并且不会每次返回上一次有状态的数据,要有更新操作才会返回。
以上两个算子都要开启检查点(checkpoint)否则会报错!
spark为了防止程序非正常退出导致数据丢失,引入了StreamingContext HA概念,需要将StreamingContext对象存储在持久化系统中。checkpointDriectory 目录中是不存在 StreamingContext 对象的,所以会创建。第
二次运行的时候,就不会再创建,而是从 checkpointDriectory 目录中读取并进行恢复。正常情况下,使用这种方式的
HA,只能持久状态数据到持久化的文件中,默认情况是不会持久化 StreamingContext 对象到 CheckPointDriectory 中的。
- 使用方式如下图:

四、窗口操作(转换算子)
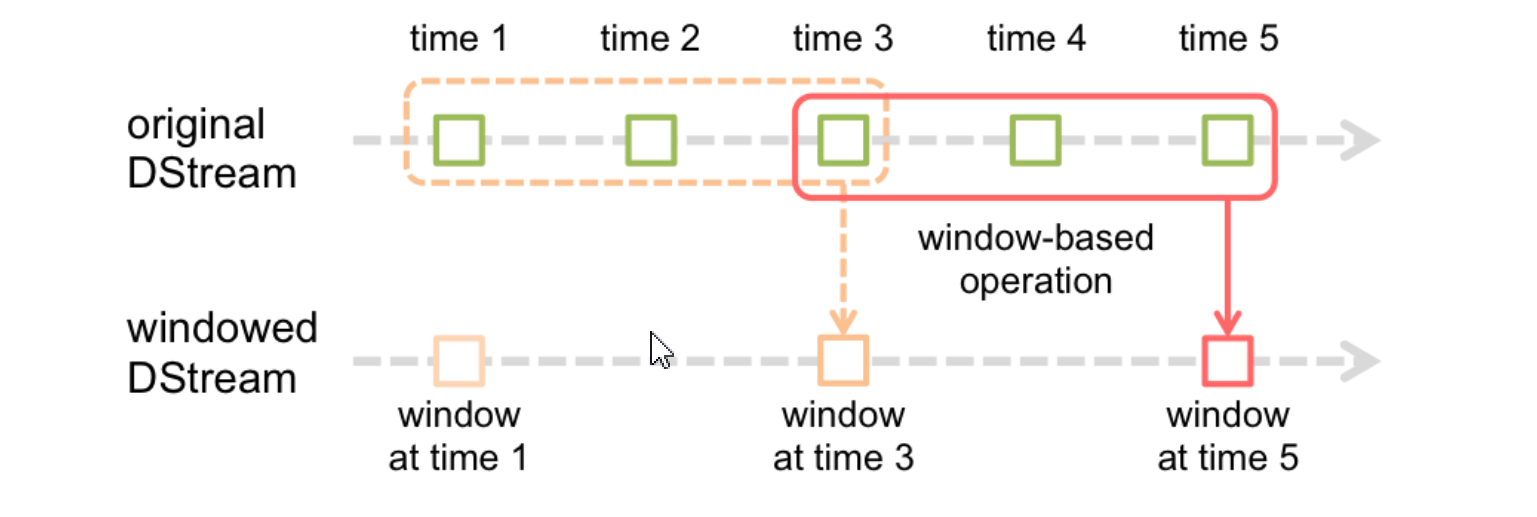
在spark流数据处理中,要计算一个时间段中的数据,我们就要引入窗口概念,对时间窗内的数据进行处理,也就是所谓的窗口计算,spark给窗口提供了滑动窗口的操作,我们对一个滑动窗口内的执行数据执行计算操作。每次掉落在窗口内多个RDD会被聚合起来执行计算操作,生成一个新的统一RDD作为窗口中的RDD。
窗口时长:计算数据的时间范围; 滑动间隔:隔多久触发一次计算。
窗口操作也属于转换操作,也就是说窗口下的算子都是转换算子;
窗口时长和滑动间隔应该是批处理的间隔时间的整数倍;
窗口默认的滑动间隔为一个批处理的间隔时间;
当窗口时长是批处理的间隔时间的整数倍,滑动间隔又小于窗口时长时,会出现重复数据。(数据有状态)
- 使用方式:

常用的窗口算子:
countByWindow(shuffle): 统计滑动窗口的 DStream 中的元素的数量。:countByWindow 操作必须开启checkpoint,否则报错。

reduceByWindow(shuffle):基于滑动窗口对源 DStream 中的元素进行聚合操作,得到一个新的 DStream。

reduceByKeyAndWindow(shuffle):基于滑动窗口对(K,V)键值对类型的 DStream 中的值按 K 使用聚合函数 func 进行聚合操作,得到一个新的DStream。reduce 任务的数量可以通过一个可选参数进行配置。

reduceByKeyAndWindow 算子的设计理念是:当滑动窗口的时间 Seconds(2) < Seconds(3)(窗口时长)时,
两个统计的部分会有重复,那么我们就可以不用重新获取或者计算,而是通过获取旧信息来更新新的信息,这样即节省了
空间又提升了效率

countByValueAndWindow(shuffle):基于滑动窗口计算源 DStream 中每个 RDD 内元素出现的频次并返回 DStream[(K,Long)],其中 K 是 RDD 中元素的类型,Long 是元素频次。与 countByValue 一样,reduce 任务的数量可以通过一个可选参数进行配置。countByValueAndWindow 操作必须开启 checkpoint,否则报错

- 总结
在 Spark Streaming 中,数据的处理是按批进行的,而数据的采集是逐条进行的,因此在 Spark Streaming 中会先设置好批处理间隔(batch duration),当超过批处理间隔的时候就会把采集到的数据汇总起来成为一批数据交给系统去处理;
五、输出算子
输出算子简单的理解就是:生成作业并触发任务的调度和执行。输出操作允许将 DStream 中的数据推送到外部系统, 比如数据库或者文件系统。与 RDD 中的惰性执行类似,如果一个 DStream 及其派生出的 DStream 都没有被执行输出操 作,那么这些 DStream 就不会被执行。如果 StreamingContext 中没有设定输出操作,那么整个 Context 就不会被启动
- 常用的输出的算子
saveAsObjectFiles(prefix, [suffix]):将 DSteam 的内容保存为一个序列化的对象文件(对于 HDFS,默认采用 SequenceFile 保存),使用 Java 的 Object 序列化,每一个批次生成一个文件,文件目录名以 prefix-TIME_IN_MS[.suffix] 的方式命名。prefix 表示文件目录的前缀,TIME_IN_MS 为毫秒时间戳,suffix 表示文件目录的后缀。
saveAsNewAPIHadoopFiles(prefix, [suffix]):将 DSteam 的内容保存至 Hadoop 的 HDFS,每一个批次生成一个文件,文件目录名以 prefixTIME_IN_MS[.suffix] 的方式命名。prefix 表示文件目录的前缀,TIME_IN_MS 为毫秒时间戳,suffix 表示文件目录的后
缀。
foreachRDD(func):会处理DStream中每个RDD,这个操作会输出数据到外部系统,比如保存数据或者数据库。但是如果直接把数据连接信息放进函数中进行连接,没处理一个RDD就连接一次,会导致数据库连接过多,数据库崩溃!
foreachPartition:对每个分区的RDD进行操作。正确的做法就是对每个分区进行数据库连接,配置数据库连接池进行操作,数据库传输完数据,就把连接放回池中,不会真正的关闭,防止连接次数过多。
六、Structured Streaming
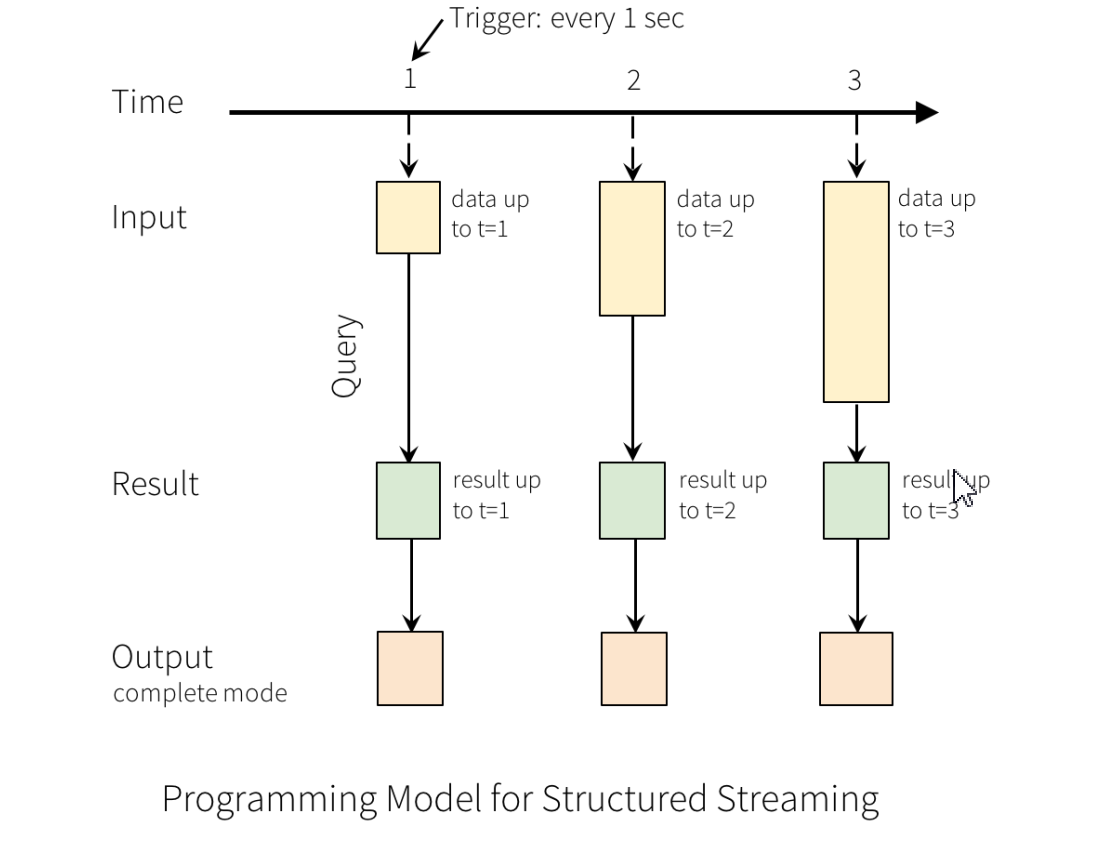
Structured Streaming 是构建在 Spark SQL 之上的流处理引擎,可以让用户使用 DataSet/DataFreame API 来进行流处理.
Structured Streaming 的核心思想是把持续不断的流式数据当做一个不断追加的表来处理。这使得新的流式处理模型同 批处理模型非常相像,这意味着我们的流式计算将可以使用标准的数据表上的批处理查询,Spark 在一个无界表上以增量 查询的方式来运行。
输入表:把输入数据流当做输入表(Input Table),到达流中的每个数据项(Data Item)类似于被追加到输入表中的一行.
结果表:作用在输入表上的查询将会产生“结果表(Result Table)”,每个触发间隔(Trigger Interval,例如 1s),新行会被追加到输入表,最终会更新结果表。无论何时更新结果表,最终目的是将更改的结果行写入到外部接收器(External Sink)
- 输出模型
将结果行写入到外部接收器,输出模式有3种:

- 输出类型
Structured Streaming 也可以将数据输出到文件或者数据库,以下为 Structured Streaming 内置的输出类型:
File:将输出存储到文件中。
Kafka:将输出存储到 Kafka 中的一个或多个主题。
Foreach:对输出中的记录运行任意计算,会遍历表中的每一行,允许将流查询结果按开发者指定的逻辑输出。例如 将每条记录保存至数据库。
Console:将输出打印到控制台。
Memory:将输出存储到内存。同时支持 Append 和 Complete 输出模式。建议应用于低数据量的调试程序,因为整个 输出会被收集并存储在 Driver 端的内存中。因此,要谨慎使用它。
七、Watermark 水位线
在分布式系统,每个节点各自为政,在通过网络通信时出现网络波动,会导致时间处理时间和事件发生时间不一致,对数据的收集按照时间窗口来进行收集计算时,必须要统一标准。因为产生了两个概念:事件发生时间:数据本身时间。处理时间:数据真正被处理的时刻。处理时间相对事件发生的时间更滞后。
- 处理时间
处理时间的概念非常简单,就是指执行处理操作的机器的系统时间。
- 事件时间
事件时间,是指每个事件在对应的设备上发生的时间,也就是数据生成的时间.在事件时间语义下,我们对于时间的衡量,就不看任何机器的系统时间了,而是依赖于数据本身。
- 水位线
水位线”的概念,已经知道了它其实就是用来度量事件时间的。
- 有序流中的水位线

- 无序流中的水位线

- 水位线特点

- 总结
水位线是为了解决分布式并行处理数据,由于并行触发的事件时间是一样的,由于网络波动传输,导致数据进行处理无序或者不能同时被处理,就需要设置水位线,在处理时间后追加设置水位线。
迟到数据:在窗口结束时间的水位线前未处理的数据。也就是在延迟时间内未处理的数据。
延迟时间:从窗口开始时间到窗口关闭时间水位线之间的时间段,延迟时间会大于窗口结束时间。engine(引擎看到的最大事件时间) - late threshold(延迟阈值,可以设置) > T(窗口结束时间)
水位线是不断增长,时间一直向前推进,水位线不断增长。
水位线是基于数据的时间戳生成。

八、优雅关闭
方案一

方案二(推荐) 取代 SIGTERM 信号,可以通过另外一种方式来完成优雅地关闭。一种方式是,在 HDFS 或 ZooKeeper 中设置一个标记 文件,定期地校验该标记文件,如果该文件存在,则调用 ssc.stop(true, true) 。或者启动一个监听端口,当该端口 监听到信号时,则触发优雅关闭。
def main(args: Array[String]): Unit = {
// ==================== 建立连接 ====================
val conf = new SparkConf().setMaster("local[*]").setAppName("QuietStopDemo")
// 使用 Duration 对象构建批处理的间隔时间,单位毫秒
//val streaming = new StreamingContext(conf, Duration(2 * 1000))
// 使用 Milliseconds、Seconds、Minutes 对象构建批处理的间隔时间
val ssc = new StreamingContext(conf, Seconds(2))
// 日志级别
ssc.sparkContext.setLogLevel("ERROR")
// ==================== 业务处理 ====================
// 监听 localhost:9999
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
// 处理发送给 localhost:9999 端口的数据
val ds: DStream[(String, Int)] = lines.flatMap(_.split("\\s+")).map(_ -> 1).reduceByKey(_ + _)
// 打印数据,默认输出每个 RDD 的前 10 个元素
ds.print()
// ==================== 启动流式计算 ====================
// 启动流式计算
ssc.start()
new Thread(() => {
/*
var whileFlag = true
while (whileFlag) {
var ifFlag = ... // 从第三方组件远程获取
if (ifFlag) {
val state: StreamingContextState = ssc.getState()
if (state == StreamingContextState.ACTIVE) {
ssc.stop(true, true)
whileFlag = false
}
}
}
*/
// 伪代码如下
var whileFlag = true
while (whileFlag) {
// 假如 Thread.sleep(5000) 后校验到标记存在
Thread.sleep(5000)
var ifFlag = true // 从第三方组件远程获取到标记为 true
if (ifFlag) {
val state: StreamingContextState = ssc.getState()
if (state == StreamingContextState.ACTIVE) {
ssc.stop(true, true)
whileFlag = false
}
}
}
}).start()
// 调用 awaitTermination 防止应用退出
ssc.awaitTermination()
}
}
九、检查点
检查点数据包含两种类型,分别是元数据检查点和数据检查点。
- 元数据检查点
元数据检查点:配置:用于创建流应用程序的配置;
DStream 操作:定义流应用程序的 DStream 操作集;
不完整的批次:在任务队列中而尚未完成的批次
- 数据检查点
将生成的 RDD 保存到可靠的存储系统。在一些跨多个批次组合数据的有状态转换中,这是必须的。在这种转换中,生 成的 RDD 依赖于先前批次的 RDD,这导致依赖关系链的长度随着时间而增加。
为了避免恢复时时间的无限增加(与依赖链成正比),有状态变换的中间 RDD 周期性地检查以存储到可靠的存储系统 中,以切断依赖链。
- 总结
检查点是为了让DStream在处理时,DStream中的一个个RDD能通过落盘,让数据有状态,因为在流中数据是无状态的,设置检查点让数据在进行RDD计算时有状态,更好的计算DStream。
检查点还能防止在进行流批处理时非正常关闭,或者系统崩溃,数据丢失的风险。
十、反压机制
反压机制的核心就是:通过动态控制数据接收速率来适配集群数据处理的能力,反压机制是Spark默认开启的。反压机制主要解决DStream中每个RDD流处理的时间过慢,导致DStream队列阻塞造成内存OOM,维持队列与处理速率之间平衡。
注意: 反压机制真正起作用时需要至少处理一个批:由于反压机制需要根据当前批的速率,预估新批的速率,所以反压机制 真正起作用前,应至少保证处理一个批。
如何保证反压机制真正起作用前应用不会崩溃?要保证反压机制真正起作用前应用不会崩溃,需要控制每个批次最大摄入速率。
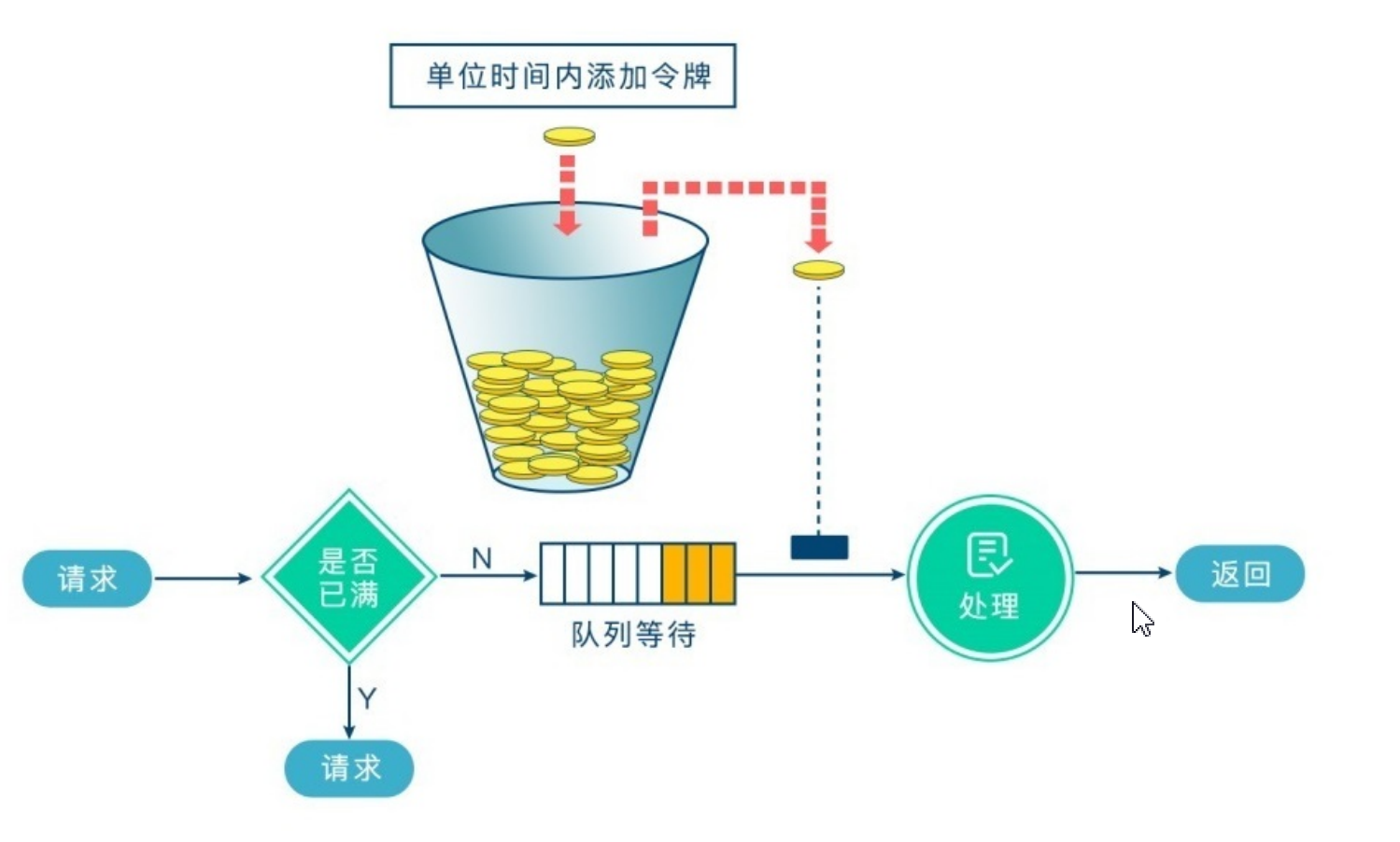
RateLimiter:RateLimiter 是一个抽象类,它并不是 Spark 本身实现的,而是借助了第三方 Google 的 GuavaRateLimiter 来实现的。它实质上就是一个限流器,也可以叫做令牌桶,如果 Executor 中 Task 每秒计算的速度大于该值则阻塞,如 果小于该值则通过,并将流数据加入缓存中进行计算。
Spark Streaming快速入门的更多相关文章
- Spark Streaming 快速入门
一.简介 1.便于使用 Spark Streaming将Apache Spark的 语言集成API 引入流处理,使您可以像编写批处理作业一样编写流式作业.它支持Java,Scala和Python. 2 ...
- 学习笔记:spark Streaming的入门
spark Streaming的入门 1.概述 spark streaming 是spark core api的一个扩展,可实现实时数据的可扩展,高吞吐量,容错流处理. 从上图可以看出,数据可以有很多 ...
- Spark2.x学习笔记:Spark SQL快速入门
Spark SQL快速入门 本地表 (1)准备数据 [root@node1 ~]# mkdir /tmp/data [root@node1 ~]# cat data/ml-1m/users.dat | ...
- Spark Streaming 编程入门指南
Spark Streaming 是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理.可以从许多数据源(例如Kafka,Flume,Kinesis或TCP sockets)中 ...
- Spark GraphX快速入门
GraphX是Spark用于图形并行计算的新组件.在较高的层次上,GraphX通过引入一个新的Graph抽象来扩展Spark RDD:一个定向的多图,其属性附加到每个定点和边.为了支持图计算,Grap ...
- Apache Spark 2.2.0 中文文档 - 快速入门 | ApacheCN
快速入门 使用 Spark Shell 进行交互式分析 基础 Dataset 上的更多操作 缓存 独立的应用 快速跳转 本教程提供了如何使用 Spark 的快速入门介绍.首先通过运行 Spark 交互 ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark Streaming入门
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文将帮助您使用基于HBase的Apache Spark Streaming.Spark Streaming是Spark API核心的一个扩 ...
- [转] Spark快速入门指南 – Spark安装与基础使用
[From] https://blog.csdn.net/w405722907/article/details/77943331 Spark快速入门指南 – Spark安装与基础使用 2017年09月 ...
- Spark快速入门 - Spark 1.6.0
Spark快速入门 - Spark 1.6.0 转载请注明出处:http://www.cnblogs.com/BYRans/ 快速入门(Quick Start) 本文简单介绍了Spark的使用方式.首 ...
随机推荐
- Python 提取PDF文本和图片
从PDF中提取内容能帮助我们获取文件中的信息,以便进行进一步的分析和处理.此外,在遇到类似项目时,提取出来的文本或图片也能再次利用.要在Python中通过代码提取PDF文件中的文本和图片,可以使用 S ...
- idea修改默认maven配置
idea修改默认maven配置 方法一 (不推荐) 打开project.default.xml文件,在其中加入如下几行配置. 代码如下 保存修改之后新建一个maven项目查看效果 方法二 新增Proj ...
- docker本地仓库-registry
Docker本地私有仓库实战: docker仓库主要用于存放docker镜像,docker仓库分为公有仓库和私有仓库,基于registry可以搭建本地私有仓库,使用私有仓库的优点如下: 节省网络带宽, ...
- 舞会(lgP1352)
写了一个多小时,本来觉得 bfs 能过然后码了好久发现不会确定顺序,又重新写了一遍 dfs /kk 好吧其实是因为我记得上次做这题的时候写的是 bfs 设 \(f[i][0]\) 表示以 \(i\) ...
- .Net中的内存泄露
.Net中的内存泄露 说明: 虽然已经有GC垃圾回收器在工作,但是还是会出现内存泄露. 内存碎片 费托管内存泄露比托管内存泄露更加严重.GC可以移动托管内存,为其他对象腾空间.但是非托管内存将永远的卡 ...
- Java比赛常用API总结
1.栈和队列 1.1 栈的常用方法 //1.栈顶插入元素 push(element) //2.返回栈顶元素并弹出栈顶元素 pop() //3.返回栈顶元素但不弹出 peek() //4.清空栈 cle ...
- UML类图(最重要的三个关系)
关联关系 ============= 关联关系:B是A的属性(A contains B),则A-->B:另外的: 都是特殊的关联关系 AB: 聚合(Aggregation)关系表示整体与部分的关 ...
- TechEmpower 22轮Web框架 性能评测:.NET 8 战绩斐然
自从2022年7月第21轮公布的测试以后,一年后 的2023年10月17日 发布了 TechEmpower 22轮测试报告 刚刚发布:Round 22 results - TechEmpower Fr ...
- (Good topic)回文数(3.13 leetcode每日打卡)
判断一个整数是否是回文数.回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数. 示例 1: 输入: 121输出: true 示例 2: 输入: -121输出: false解释: 从左向右读, ...
- 记一次在线客服系统用户遭勒索,索要茶水费事件的 Windbg 分析与应对
本文记录了几个月前,客户在使用在线客服系统过程中,遭到勒索威胁,索要茶水费 的事件.经过应对,快速的化解了攻击威胁,并继续安全使用至今. 讲故事 威胁次日,收到报警,服务器 CPU 使用率持续超过 8 ...