MRS大企业ERP流程实时数据湖加工最佳实践
本文分享自华为云社区《MRS大企业ERP流程实时数据湖加工最佳实践》,作者:晋红轻 。
本文将以ERP流程实践为例介绍MRS实时数据湖方案的演进
案例实践需求解析:
业务描述
- AE表:会计分录表,主要记录财务相关信息,可用于成本核算等业务计算。为业务最主要的表,称驱动表。
- 四通道表:实际为四个门店业务系统,主要记录销售记录信息。为成本核算、科目报表分析等业务提供信息佐证。可称为维表。
业务痛点
- 科目分析报表业务供数慢的痛点,数据时延高。
- 实际业务数据有内容更新,保证数据严格一致。
- 科目分析报表查询仅支持公司、科目、时段等少量查询条件。
实时数据湖方案优势
- 实时数据湖方案做增量加工,将传统供数压力卸载到每天、每小时、每分钟,100万数据查询只需要2min。
- 使用Hudi作为数据湖天然支持数据更新。
- 提供所有数据归档,可随时回溯。
- 支持科目、批名、凭证名、合同号等31个查询条件,大幅度减少用户导出数据后筛选过滤时间。支持用户基于页面直接分析。
实时数据湖方案实施挑战
- 流计算基于内存,峰值数据量过大会影响作业稳定性。
- 多流时延大,数据等待耗费大量内存资源,需考虑业务需求与使用资源的平衡。
流加工模型一:
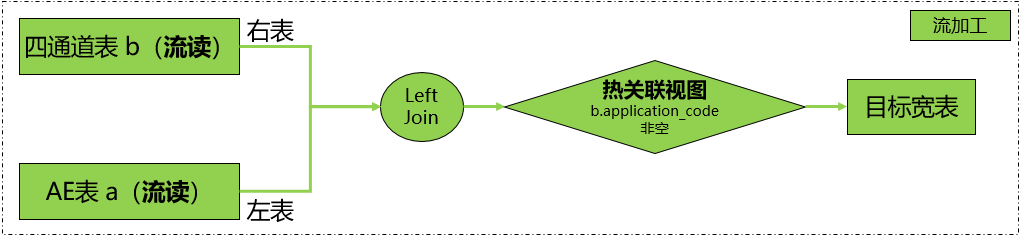
模型一特点
•Hudi表流读能够减少整体内存开销,提高作业稳定性。
•以其中一条流为基准(左表),去比较另一条流(右表)
•会出现关联缺失的情况,以驱动表(AE表)的视角(新增&更新)
•1)四通道流早到,并且ttl到期后数据丢失
•2)四通道流晚到,AE流ttl到期后数据丢失
模型一局限:
•目标宽表数据会出现不准的情况
•源端新增因为关联不出有效结果造成目标宽表缺数 -> missing
•源端更改因为关联不出有效结果造成目标宽表延时 -> delay
流加工模型二:
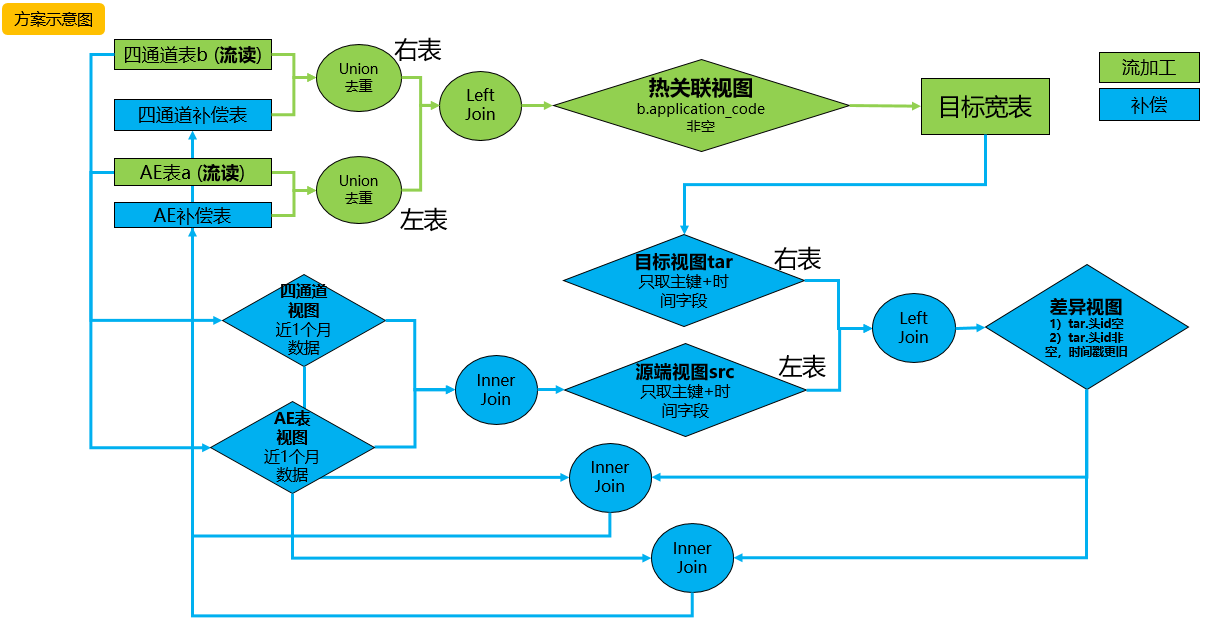
补偿目的:
补偿目的:基于业务逻辑,对比源端流表和目的端宽表数据内容,发现目标宽表缺失数据主要字段,关联源表完整内容找出缺失数据,并写回源端表补偿层。
missing&delay补偿模拟:
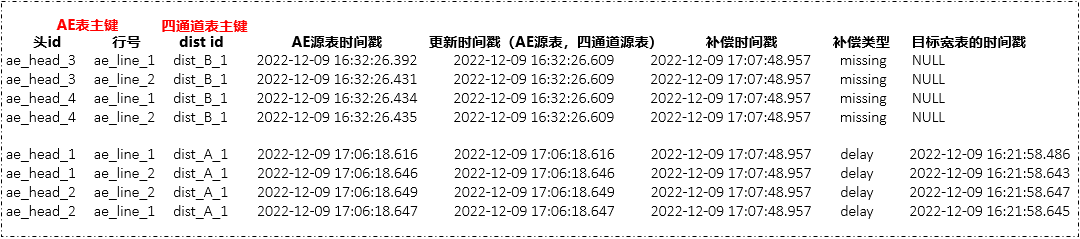
模型二特点:比较方案一增加补偿机制,能够对比源表(AE表,四通道表)以及目标宽表,找出缺失数据missing, delay。
模型二局限:实际情况双流之间时延可能较大、对齐较难,虽然能够使用补偿机制找回缺失数据,但是这样流加工任务主要角色会被弱化,同时会对补偿任务造成更大压力,数据时延会变大 。
流加工模型三(最终):
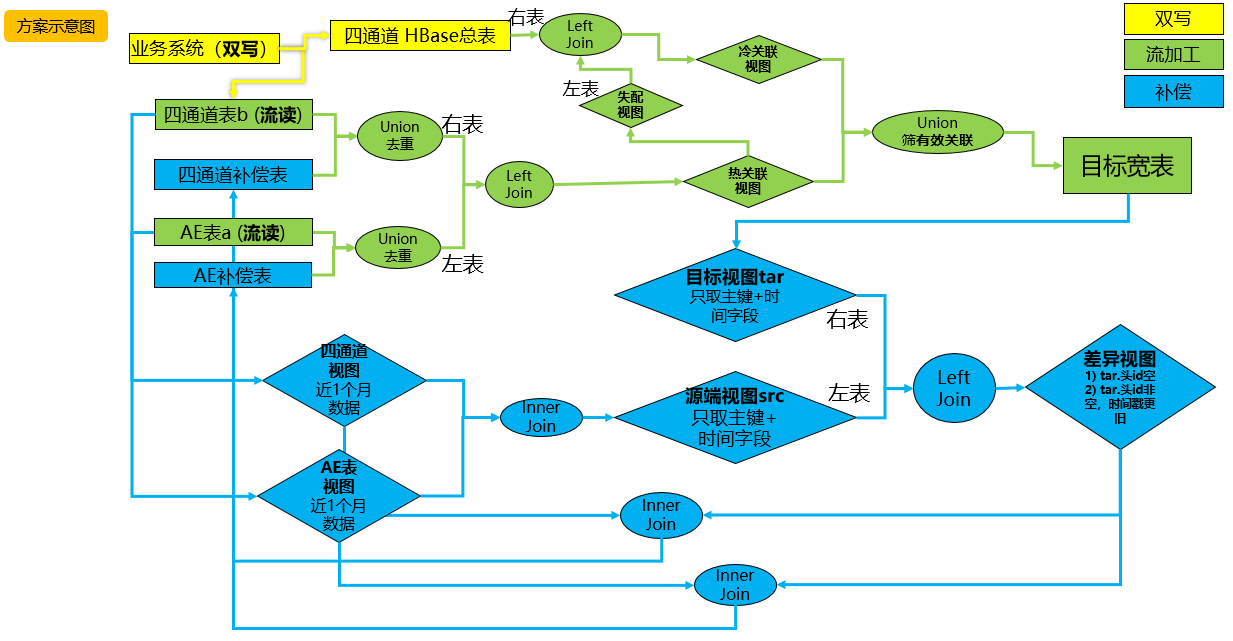
双写目的:业务系统持续向Hudi表,HBase表双写数据。Hudi表流读,提供主要热关联数据,HBase存储所有历史数据,技术上就是维度表,为热关联失败之后进行快速点查补数(lookup join)得到有效关联。提高双流关联的命中率。减少流加工整体数据时延。
维表选型:

模型总结:

MRS大企业ERP流程实时数据湖加工最佳实践的更多相关文章
- 移动App測试实战:顶级互联网企业软件測试和质量提升最佳实践
这篇是计算机类的优质预售推荐>>>><移动App測试实战:顶级互联网企业软件測试和质量提升最佳实践> 国内顶级互联网公司測试实战经验总结.阿里.腾讯.京东.携程.百 ...
- 【翻译】ScyllaDB数据建模的最佳实践
文章翻译自Scylla官方文档:https://www.scylladb.com/2019/08/20/best-practices-for-data-modeling/ 转载请注明出处:https: ...
- Salesforce 大量数据部署的最佳实践
本文参考自官方文档.原文链接 大量数据部署对Salesforce的影响 当用户需要在Salesforce中部署大量数据的时候,部署的过程往往会变慢.这时就需要架构师或开发者设计出更好的过程来提高大量数 ...
- Springboot 配置文件、隐私数据脱敏的最佳实践(原理+源码)
大家好!我是小富- 这几天公司在排查内部数据账号泄漏,原因是发现某些实习生小可爱居然连带着账号.密码将源码私传到GitHub上,导致核心数据外漏,孩子还是没挨过社会毒打,这种事的后果可大可小. 说起这 ...
- Mongo实战之数据空洞的最佳实践
问题背景: 某天,开发部的同事跑过来反映: mongodb数据文件太大,快把磁盘撑爆了!其中某个db占用最大(运营环境这个db的数据量其实很小) 分析: 开发环境有大量测试的增/删/改操作,而由于Mo ...
- Kafka数据迁移MaxCompute最佳实践
摘要: 本文向您详细介绍如何使用DataWorks数据同步功能,将Kafka集群上的数据迁移到阿里云MaxCompute大数据计算服务. 前提条件 搭建Kafka集群 进行数据迁移前,您需要保证自己的 ...
- 小白到大神,你需要了解的 sqlite 最佳实践
本文微信公众号「AndroidTraveler」首发. 背景 本文是对一篇英文文档的翻译,原文请见文末链接. 并发数据库访问 假设你实现了自己的 SQLiteOpenHelper. public cl ...
- 华为云FusionInsight MRS:助力企业构建“一企一湖,一城一湖”
摘要:华为云FusionInsight MRS新一代的数据湖,让大数据越用越快.越用越易.越用越稳.越用越省!让数据价值近在眼前! 10月30日,以"携手共赢·数创未来"为主题的第 ...
- Kafka ETL 之后,我们将如何定义新一代实时数据集成解决方案?
上一个十年,以 Hadoop 为代表的大数据技术发展如火如荼,各种数据平台.数据湖.数据中台等产品和解决方案层出不穷,这些方案最常用的场景包括统一汇聚企业数据,并对这些离线数据进行分析洞察,来达到辅助 ...
- 从 Delta 2.0 开始聊聊我们需要怎样的数据湖
盘点行业内近期发生的大事,Delta 2.0 的开源是最让人津津乐道的,尤其在 Databricks 官宣 delta2.0 时抛出了下面这张性能对比,颇有些引战的味道. 虽然 Databricks ...
随机推荐
- 深入理解 Python 虚拟机:协程初探——不过是生成器而已
深入理解 Python 虚拟机:协程初探--不过是生成器而已 在 Python 3.4 Python 引入了一个非常有用的特性--协程,在后续的 Python 版本当中不断的进行优化和改进,引入了新的 ...
- Kubernetes:kube-apiserver 之 scheme(二)
接 Kubernetes:kube-apiserver 之 scheme(一). 2.2 资源 convert 上篇说到资源版本之间通过内部版本 __internal 进行资源转换.这里进一步扩展介绍 ...
- Unity - UIWidgets 5. Redux接入(一) 基本接入
对响应式的数据组织结构不太熟, 直接尝试Redux走起 参考资料 Redux的基本概念 state 一个字段用于存储状态 存储state的地方称为"store", 类似Model\ ...
- 详述Java内存屏障,透彻理解volatile
一般来说内存屏障分为两层:编译器屏障和CPU屏障,前者只在编译期生效,目的是防止编译器生成乱序的内存访问指令:后者通过插入或修改特定的CPU指令,在运行时防止内存访问指令乱序执行. 下面简单说一下这两 ...
- 关于虚拟机的IP地址经常改变问题的解法
主要解法就是配置静态IP地址 首先了解一下IP和子网掩码,网关的含义:IP 是标识计算机特定地址的二进制数,子网掩码用于和IP组合划分子网;网关是将信息传送到网关进行收发 开始配置:首先打开Linux ...
- idea debug jboss 应用遇到到问题记录
idea run Jboss是没有问题的,能启动Jboss成功:但是debug Jboss时,报ERROR: Cannot load this JVM TI agent twice, check yo ...
- LeetCode-Java:88合并两个有序数组
题目: 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目. 请你 合并 nums2 到 nums1 中 ...
- 记一次在线客服系统用户遭勒索,索要茶水费事件的 Windbg 分析与应对
本文记录了几个月前,客户在使用在线客服系统过程中,遭到勒索威胁,索要茶水费 的事件.经过应对,快速的化解了攻击威胁,并继续安全使用至今. 讲故事 威胁次日,收到报警,服务器 CPU 使用率持续超过 8 ...
- IIS安装与配置
一.环境介绍 Windows Server 2019 64位 标准版 二.IIS安装 2.1.打开服务器管理器,单击添加角色和功能 在Windows Server 2019 服务器管理中,点击角色和功 ...
- SpringCore完整学习教程4,入门级别
本章从第4章开始 4. Logging Spring Boot使用Commons Logging进行所有内部日志记录,但保留底层日志实现开放.为Java Util Logging.Log4J2和Log ...