ROMA集成关键技术:增量数据集成
摘要:本文将详解ROMA集成关键技术-增量数据集成技术。
本文分享自华为云社区《ROMA集成关键技术(2)-增量数据集成技术》,作者:华为云PaaS服务小智 。
1.概述
ROMA平台的核心系统ROMA Connect源自华为流程IT的集成平台,在华为内部有超过15年的企业业务集成经验。依托ROMA Connect,可以将物联网、大数据、视频、统一通信、GIS等基础平台及各个应用的服务、消息、数据统一集成适配以及编排,屏蔽各个平台对上层业务的接口差异性,对上提供服务、消息、数据集成使能服务,以支撑新业务的快速开发部署,提升应用开发效率。适用于平安园区、智慧城市、企业数字化转型等场景,图1展示了ROMA Connect的功能视图。
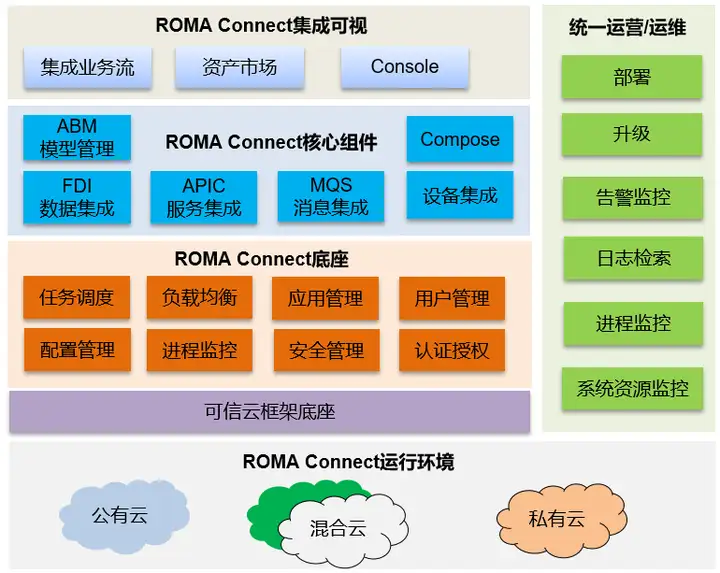
图1 ROMA Connect功能视图
FDI(Fast Data Integration)通过应用间的数据交换从而达到集成,主要解决数据的分布性和异构性的问题,FDI应用场景如下:
- 跨异构数据源集成
- 跨应用间集成
- 跨云数据集成
- 跨网络数据集成(B2B、集团分子公司跨域集成)
FDI功能视图如图所示:
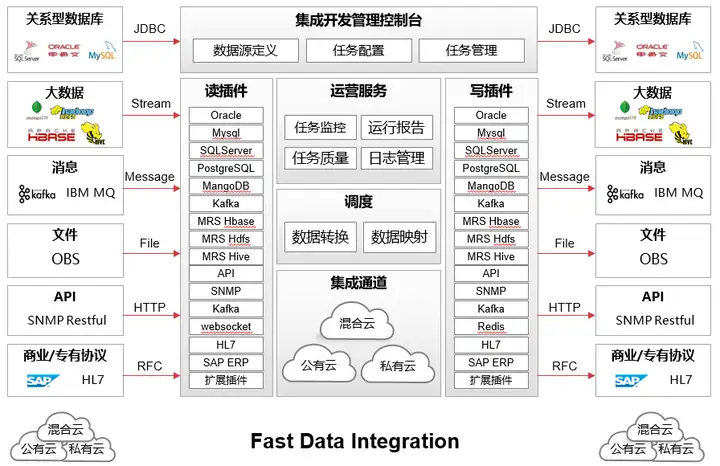
图2 FDI功能视图
本文将介绍FDI的关键技术-增量数据集成技术。
2.技术背景
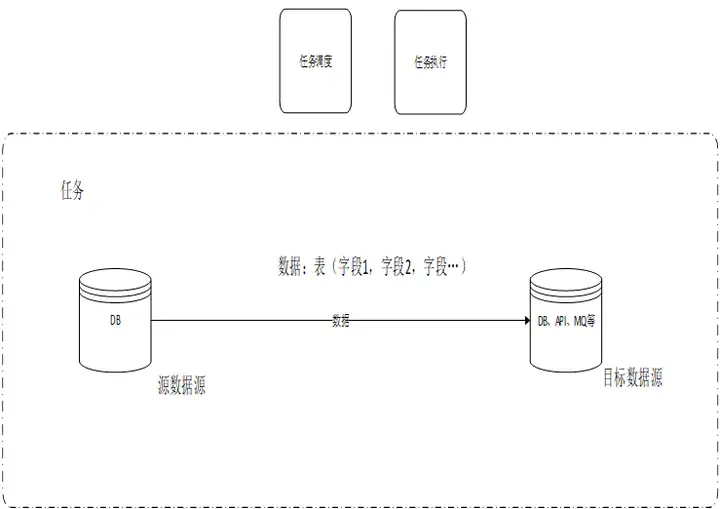
在数据集成场景,将一个数据源中的数据定时或者实时方式同步到其他异构数据源。
数据源类型可以是API、MQ(Message queue)、DB、大数据、文件存储等。
当源端是DB,一个任务通常调度一个或几个表的部分字段数据。同时有几百上千个任务需要调度。
3.常见技术
在介绍ROMA FDI增量数据集成技术之前,我们先了解下当前业界主要采用的数据集成技术。
常见技术一:
定时方式进行数据集成任务,根据时间周期进行调度,如根据年、月、日、小时、分等为周期进行调度,每周期执行一次。每个任务可以分别设置自己的任务调度周期策略。
针对增量的数据,一般通过时间戳或者增量ID进行过滤,每次执行只同步新产生的数据,针对删除数据的同步,通过时间戳一般无法支持同步。
另外也有通过触发器记录所有变化数据到一张辅助表,定时从辅助表拉取数据进行同步。
常见技术一缺点:
机械的调度执行,不管实际有没有增量数据产生,会浪费调度资源,也会增加不必要的执行,对源数据源资源产生浪费。
调度针对每个任务调度进行调度,一般是一张数据库表一个任务,如果表的数量特别多的话,调度的负担比较大。且如果多个表之间有主外键关联关系的话,无法保证同步时实际数据的先后依赖关系,容易产生冲突导致同步失败。
采用时间戳或者增量ID同步增量数据要求表中必须有时间戳字段或者增量ID字段,用户的表不一定能满足这样的要求。
针对源表中delete的数据,通过查询方式无法获取,导致无法同步到目标数据源。
采用触发器记录所有数据的方式,由于触发器与用户的sql执行是同步执行方式,会对系统性能造成比较大的影响。存储也造成比较大的浪费。
常见技术二:
实时任务,主要面向对时延要求比较高的场景。一般调度调度一次,一直在后台执行,有增量数据产生时,可以比较及时同步到目的数据源。
针对增量数据,通常通过解析数据库的增量日志(如MySQL的binlog)来进行同步。
常见技术二缺点:
不同数据库的增量日志格式和获取接口均不同,如果需要支持多种数据库难度会比较大。
由于数据库的增量日志一般包括该数据库实例下的所有库表,不能在源端进行过滤和清洗。只能在任务执行时接收完全部数据后才能进行过滤清洗,所以会造成巨大的网络流量浪费。
4.ROMA FDI增量数据集成技术
我们再回顾总结一下前面提到的现有技术问题:
1、任务调度有很多非必须的调度,即无实际增量数据的任务调度
2、非必须的数据迁移造成的网络流量浪费
3、时间戳或者增量ID对用户表结构的侵入性,无法同步delete数据。
4、对表的主外键约束关系的无法很好的支持
4.1增量数据集成技术思路
1、通过触发器在元数据表记录数据变化信息,分割时间段记录关键元数据信息,并不记录所有数据内容,有时间戳记录时间戳,无时间戳记录主键/ddl。
2、通过元数据表的信息以及主外键关系来针对所有表进行统一任务调度排序
3、增量数据的高效获取和写入方式
4.2处理流程
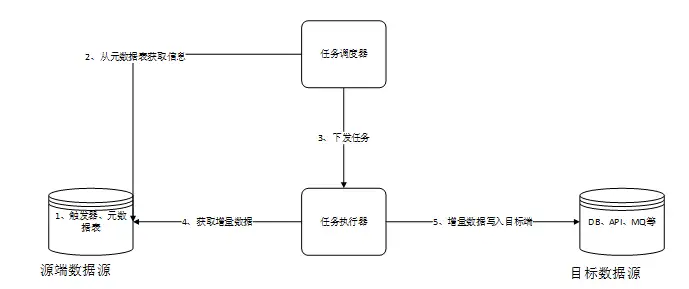
在数据集成场景,将一个数据源中的数据定时或者实时方式同步到其他数据源。数据源类型可以是API、MQ、DB、大数据平台、文件等。
本方案主要面向源端数据源是数据库类型,其他数据源类型可以根据本思路进行相应的适配。
总体步骤概述如下:
- 调度器在源端数据库中创建本发明所需要的元数据表和触发器。数据库中的数据发生变化时,通过触发器写入关键元数据到元数据表中。
- 调度器从元数据表获取所有表的变化元数据,进行依赖分析,然后调度排序
- 调度器根据策略下发任务到任务执行器进行实际任务的执行。
- 任务执行器从源端数据源中获取数据
- 任务执行器讲源端获取到的数据写入目标端数据源
4.3元数据表结构设计
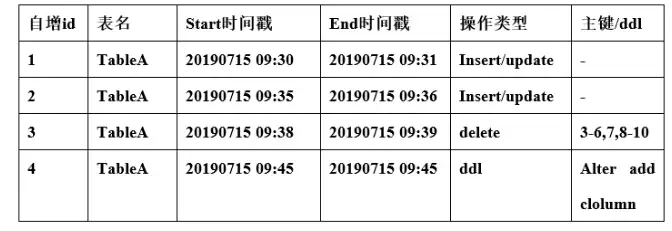
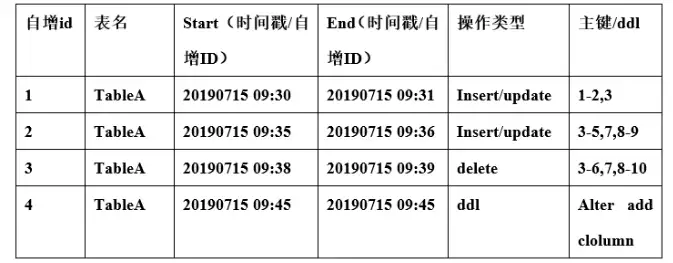
在源端数据库元数据表结构主要包括如下关键元素:
自增ID:代表元数据表的主键,主要用来在调度器中排序时使用。
表名:用来存储实际业务表的名称或者唯一标识。
Start时间戳:将所有时间进行分段,分的时间段的起始值。
End时间戳:将所有时间进行分段,分的时间段的结束值。
操作类型:用来标识对数据的操作类型,如insert、update或者对表结构的DDL操作。
主键/ddl:用来记录主键或者ddl。主键值能按范围则按照范围来存,用以节省空间。
以下针对源表是否有时间戳字段给出两张场景下的数据的示例。
1.针对有时间戳字段
2.针对无时间戳字段
4.4触发器逻辑
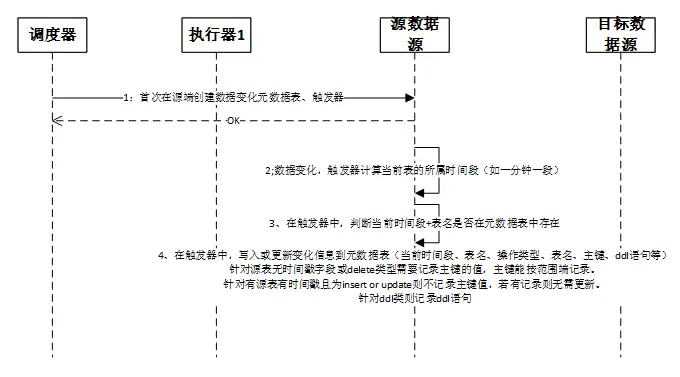
流程详细描述如下,其中流程1负责触发器和元数据表的创建,2到4流程主要描述触发器的内部逻辑:
1、触发器和元数据表的创建
调度器在首次连接源端数据源时,需要进行触发器和元数据表的创建。可选的也可以调度器下发任务给执行器,由执行器去执行创建任务。
2、当源端数据库的数据产生变化时,如新增数据、修改数据、删除数据、修改表结构等。触发器会先获取当前时间所属的时间段,其中时间段是指根据一定的时间长度将所有时间切分成很多的段。
3、触发器计算出当前时间段后,会在元数据表中根据时间段和表名查询对应的记录是否存在。是否存在决定了后续是要insert还是update数据入元数据表。
4、在触发器中,写入或更新变化信息到元数据表,主要包括当前时间段、表名、操作类型、表名、主键、ddl语句等信息。更新时需要带上原有的主键/ddl等信息保证数据不能丢失。
- 针对源表无时间戳字段或delete类型需要记录主键的值。
- 针对源表有时间戳且为insert 或update则不记录主键值,若有记录则无需更新,可以降低对源数据库的影响。
- 针对ddl类操作则记录ddl语句或者也可以根据需要自定义格式进行记录。
其中主键属于数字类型等能按范围划分时则按照范围存储记录,不能按照范围则直接拼接主键进行存储,这样可以最大可能降低对存储空间的占用和对性能的影响。
注意不同类型操作间隔开的,不能合并到一个时间段里记录里。只有同一种类型且连续在一个一个时间段内才可以合并为一条记录。如果在同一个时间段内先执行表A的两条insert,然后执行delete,之后再执行insert,那么这两次的insert不能合并。
4.5调度迁移流程
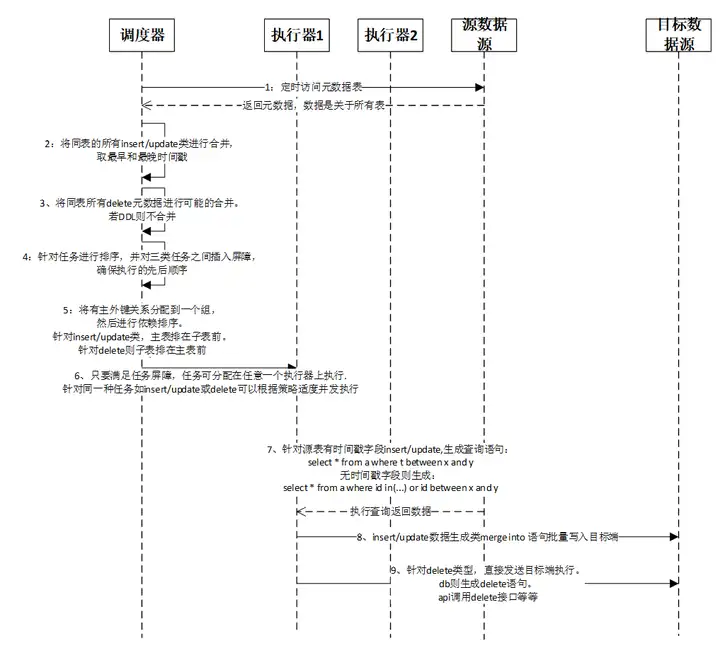
流程详细描述如下:
- 调度器定时访问源端数据源中的元数据表,获取关于所有表的源数据变化信息。由于是针对所有表,通常实现的定时周期一般设置比较短。根据元数据表的时间戳字段每次只取最新的未处理过的数据。针对已调度处理过的数据可以进行一定周期进行老化删除。
注意获取数据需要严格排序,根据自增主键值进行排序,一般不能根据时间戳排序,除非时间戳可以保证前后顺序。 - 针对同一个表的连续的多个insert/update类型操作合并,时间段取并集,如有主键也同样取并集。中间有其他类型如delete等间隔开的则不能做合并操作。
- 针对同一个表的连续的多个delete类型操作进行合并,同样时间段取并集,主键也同样取并集。有其他类型间隔开非连续的情况下则不能做合并。
ddl类型操作不做合并处理。 - 针对上述步骤2、3中已经合并排序好的任务记录之间插入屏障,确保最终的执行先后顺序一定按排序好的执行。
- 从源数据源获取表结构的数据,根据主外键依赖关系,将前述已经排序好的任务分配任务组。有主外键依赖分配在同一个任务组。一个任务组内根据主外键关系进行排序,针对insert/update类,主表排在子表前。针对delete则子表排在主表前。针对ddl则按原有顺序,不另外排序。
- 调度器将排序好的任务下发到执行器进行执行。执行器执行任务时需要满足任务屏障和依赖先后关系,在此前提基础上,任务可分配在任意一个合适的执行器上执行。针对同一种任务如insert/update或delete可以根据策略适度并发执行。
- 执行器执行任务时,根据不同场景生成不同的获取数据的sql语句。针对源表有时间戳字段insert/update,生成查询语句:select * from 表 where 时间戳 between 最早起始时间 and 最晚结束时间。无时间戳字段则生成:
select * from 表 where 主键 in(主键值1,主键值2……) 或者 主键 between 最小主键值 and 最大主键值。 - 执行器将查询到数据通过生成特定语句写入目标端数据源。insert/update数据生成类merge into语句,可以批量执行,当确定目标数据源中无此数据会由数据源自动做insert操作,有此数据则自动进行update。如此可以保证该任务是幂等执行,即可以重复执行,在任务执行失败时可以安全的重试。此外该语法可以将insert和update两类操作进行合并后批量执行。Oracle、SQL SERVER的语法是merge into,MySQL的类似语法是replace或 insert into on duplicate key update,PostgreSQL的语法是UPSERT,其他数据源可以参考此原理,若不支持该语句则用原生的insert或者update语法或者相对应的接口等。
- 如果是delete类型操作,执行器则无需到源端获取数据,直接根据元数据表获取到的主键来进行同步。目标端数据源如果是数据库类型,则生成delete from 表 where 主键 in(主键值1,主键值2……) 或者 主键 between 最小主键值 and 最大主键值。如果目标端是其他类型则调用其删除接口传入主键值。
ROMA集成关键技术:增量数据集成的更多相关文章
- CDC+ETL实现数据集成方案
欢迎咨询,合作! weix:wonter 名词解释: CDC又称变更数据捕获(Change Data Capture),开启cdc的源表在插入INSERT.更新UPDATE和删除DELETE活动时会插 ...
- 阿里云DataWorks实践:数据集成+数据开发
简介 什么是DataWorks: DataWorks(数据工场,原大数据开发套件)是阿里云重要的PaaS(Platform-as-a-Service)平台产品,为您提供数据集成.数据开发.数据地图.数 ...
- DataPipeline丨构建实时数据集成平台时,在技术选型上的考量点
文 | 陈肃 DataPipeline CTO 随着企业应用复杂性的上升和微服务架构的流行,数据正变得越来越以应用为中心. 服务之间仅在必要时以接口或者消息队列方式进行数据交互,从而避免了构建单一数 ...
- Tapdata 肖贝贝:实时数据引擎系列(六)-从 PostgreSQL 实时数据集成看增量数据缓存层的必要性
摘要:对于 PostgreSQL 的实时数据采集, 业界经常遇到了包括:对源库性能/存储影响较大, 采集性能受限, 时间回退重新同步不支持, 数据类型较复杂等等问题.Tapdata 在解决 Pos ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
- DataPipeline CTO陈肃:从ETL到ELT,AI时代数据集成的问题与解决方案
引言:2018年7月25日,DataPipeline CTO陈肃在第一期公开课上作了题为<从ETL到ELT,AI时代数据集成的问题与解决方案>的分享,本文根据陈肃分享内容整理而成. 大家好 ...
- Kafka ETL 之后,我们将如何定义新一代实时数据集成解决方案?
上一个十年,以 Hadoop 为代表的大数据技术发展如火如荼,各种数据平台.数据湖.数据中台等产品和解决方案层出不穷,这些方案最常用的场景包括统一汇聚企业数据,并对这些离线数据进行分析洞察,来达到辅助 ...
- Oracle 数据集成的实际解决方案
就针对市场与企业的发展的需求,Oracle公司提供了一个相对统一的关于企业级的实时数据解决方案,即Oracle数据集成的解决方案.以下的文章主要是对其解决方案的具体描述,望你会有所收获. Oracle ...
- Solr与MongoDB集成,实时增量索引
Solr与MongoDB集成,实时增量索引 一. 概述 大量的数据存储在MongoDB上,需要快速搜索出目标内容,于是搭建Solr服务. 另外一点,用Solr索引数据后,可以把数据用在不同的项目当中, ...
- DataPipeline CTO 陈肃:我们花了3年时间,重新定义数据集成
目前,中国企业在大数据流通.交换.利用等方面仍处于起步阶段,但是企业应用数据集成市场却是庞大的.根据 Forrester 数据看来,2017 年全球数据应用集成市场纯软件规模是 320 亿美元,如果包 ...
随机推荐
- 从一次Kafka宕机说起(JVM hang)
一.背景 时间大概是在夏天7月份,突然收到小伙伴的情报,我们线上的一个kafka实例的某个broker突然不提供服务了,也没看到什么异常日志,反正就是生产.消费都停了.因为是线上服务,而且进程还在,就 ...
- 手动添加winform的combobox和listbox名称和值
先定义一个ListItem类,工程内其他窗体都可以用的. public class ListItem : Object { public string Text { get; ...
- 差异行压缩算法(C#实现)
private byte[] DifferenceRowOrder(int offset, int count, byte[] inbyte)//差异行命令(此处的offset和count都从1开始) ...
- 银河麒麟V10 修改文件夹权限
并不建议修改系统文件夹的权限,防止终端失效 指令:获取所有权限 指令:写入可执行权限 chmod +x filename//filename 是文件路径 TRANSLATE with x Englis ...
- File --JAVA
File --JAVA 构造方法 方法 说明 public File (String pathname) 根据文件路径创建对象 public File (String parent, String c ...
- Nacos有几种负载均衡策略?
Nacos 作为目前主流的微服务中间件,包含了两个顶级的微服务功能:配置中心和注册中心. 1.配置中心扫盲 配置中心是一种集中化管理配置的服务,通俗易懂的说就是将本地配置文件"云端化&quo ...
- html笔记重点
第五周-周二 一.视频和音频 <video src="路径" controls="controls"></video> 1.加contr ...
- .NET周刊【11月第1期 2023-11-09】
国内文章 C#/.NET/.NET Core优秀项目和框架2023年10月简报 https://www.cnblogs.com/Can-daydayup/p/17804085.html 本文主要介绍了 ...
- 什么是oa软件?oa软件能做什么?
什么是OA软件? OA软件是办公自动化软件(Office Automation Software)的简称,是一种通过计算机技术,对办公业务流程进行管理和自动化处理的软件系统.它主要用于协调和管理企业内 ...
- 月薪3w的报表工程师要会哪些技能?报表工程师的招聘要求解读
对于月薪3w的报表工程师,通常需要具备以下技能: 1. 数据分析与处理 - 数据仓库:了解数据仓库的设计原则和架构,能够构建和优化数据仓库结构. - SQL语言:熟练掌握SQL查询语言,能够编写复杂的 ...