Python 动态网页Fetch/XHR爬虫——以获取NBA球员信息为例
Python 动态网页Fetch/XHR爬虫——以获取NBA球员信息为例
动态网页抓取信息,一般利用F12开发者工具-网络-Fetch/XHR获取信息,实现难点有:
动态网页的加载方式
获取请求Url
编排处理Headers
分析返回的数据Json
pandas DataFrame的处理
我们本次想获取的信息如下: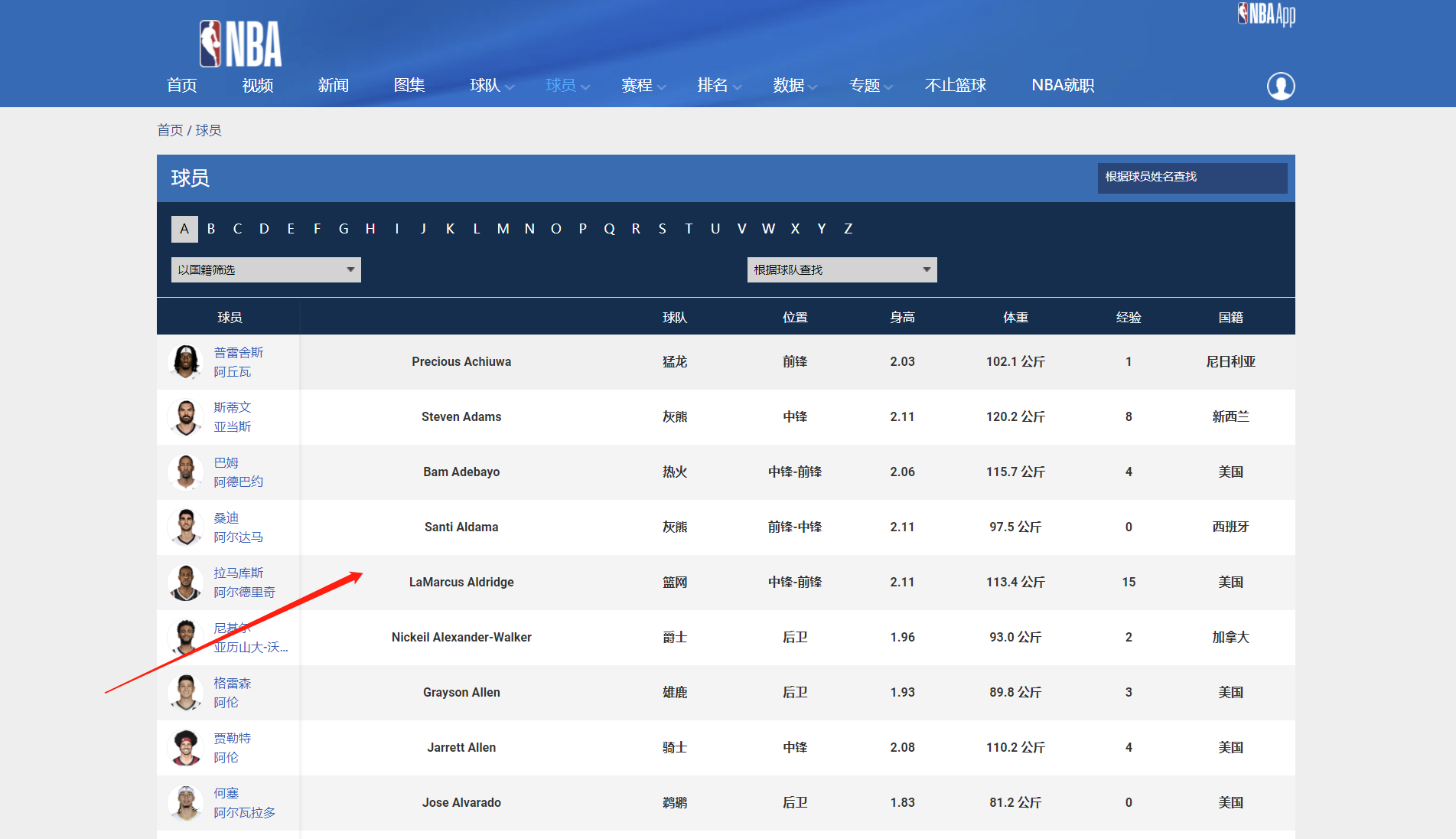
成功获取到的csv一共506位球员,具体如下:
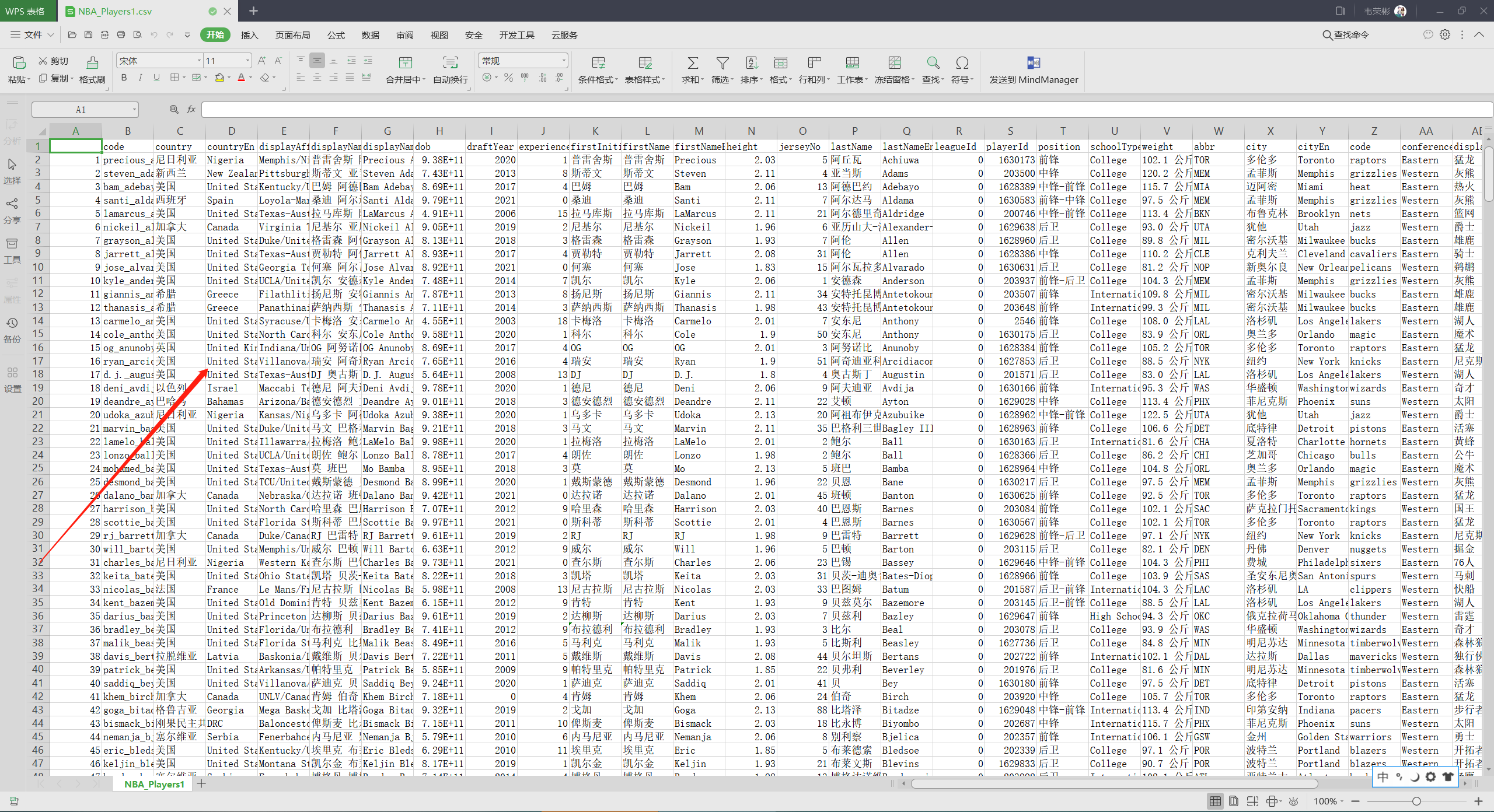
实现代码:
import requests
import pandas as pd
def get_headers(header_raw):
return dict(line.split(": ", 1) for line in header_raw.split("\n") if line != '')
# 设置headers
headers_str = '''
accept: application/json, text/plain, */*
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
referer: https://china.nba.cn/playerindex/
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
sec-fetch-dest: empty
sec-fetch-mode: cors
sec-fetch-site: same-origin
cookie: sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22182d0029f842fc-0d281a685dd4e08-4303066-2400692-182d0029f85406%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTgyZDAwMjlmODQyZmMtMGQyODFhNjg1ZGQ0ZTA4LTQzMDMwNjYtMjQwMDY5Mi0xODJkMDAyOWY4NTQwNiJ9%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%22%2C%22value%22%3A%22%22%7D%2C%22%24device_id%22%3A%22182d0029f842fc-0d281a685dd4e08-4303066-2400692-182d0029f85406%22%7D; privacyV2=true; i18next=zh_CN; locale=zh_CN
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36
'''
headers = get_headers(headers_str)
# print(headers)
# requests请求
param = {'locale': 'zh_CN'}
url = 'https://china.nba.cn/stats2/league/playerlist.json'
response = requests.get(url=url, headers=headers, params=param)
print('返回状态码:', response.status_code)
print('编码:', response.encoding)
# json解码成字典
myjson = response.json()
# 保存为pandas DataFrame
# print(players_dicts['playerProfile'])
# print(players_dicts['teamProfile'])
# 遍历选手信息
players_info = []
for players_dicts in myjson['payload']['players']:
players_info.append(pd.DataFrame([players_dicts['playerProfile']]))
# 遍历队伍简介信息
teams_info = []
for players_dicts in myjson['payload']['players']:
teams_info.append(pd.DataFrame([players_dicts['teamProfile']]))
# 得到两个DataFrame
players_pandas = pd.concat(players_info)
teams_pandas = pd.concat(teams_info)
# 合并得到最终DataFrame
result = pd.concat([players_pandas, teams_pandas], axis=1)
result.to_csv(r'C:\Users\WeiRonbbin\Desktop\NBA_Players1.csv')Python 动态网页Fetch/XHR爬虫——以获取NBA球员信息为例的更多相关文章
- Python动态网页爬虫-----动态网页真实地址破解原理
参考链接:Python动态网页爬虫-----动态网页真实地址破解原理
- python动态网页爬取——四六级成绩批量爬取
需求: 四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页. ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- Python 爬虫修养-处理动态网页
Python 爬虫修养-处理动态网页 本文转自:i春秋社区 0x01 前言 在进行爬虫开发的过程中,我们会遇到很多的棘手的问题,当然对于普通的问题比如 UA 等修改的问题,我们并不在讨论范围,既然要将 ...
- python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网页 ...
- 第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求 selenium模块 selenium模块为 ...
- 在python使用selenium获取动态网页信息并用BeautifulSoup进行解析--动态网页爬虫
爬虫抓取数据时有些数据是动态数据,例如是用js动态加载的,使用普通的urllib2 抓取数据是找不到相关数据的,这是爬虫初学者在使用的过程中,最容易发生的情况,明明在浏览器里有相应的信息,但是在pyt ...
- python网络爬虫-动态网页抓取(五)
动态抓取的实例 在开始爬虫之前,我们需要了解一下Ajax(异步请求).它的价值在于在与后台进行少量的数据交换就可以使网页实现异步更新. 如果使用Ajax加载的动态网页抓取,有两种方法: 通过浏览器审查 ...
- Python爬虫 使用selenium处理动态网页
对于静态网页,使用requests等库可以很方便的得到它的网页源码,然后提取出想要的信息.但是对于动态网页,情况就要复杂很多,这种页面的源码往往只有一个框架,其内容都是由JavaScript渲染出来的 ...
随机推荐
- C# 多线程与线程扫描器
多线程是一种复杂的编程技术,可以同时运行多个独立的线程来处理各种任务.在C#中,可以使用Thread类和ThreadPool类来实现多线程编程.Thread类用于创建和控制线程.可以使用Thread. ...
- vue + elementui 分页切换页面,缓存页码
问题场景 列表页面输入查询条件,选择第3页,点击详情进入详情页,从详情页返回时,默认列表页面页码重置为1:此时想要缓存该页码,有两种方式:可按业务场景使用 方式一:用vue自带的 keep-alive ...
- laravel生成二维码,并添加背景图片,图标logo
1.安装组件 composer require simplesoftwareio/simple-qrcode 1.3.* 在 config/app.php 注册服务提供者: SimpleSoftwar ...
- Laravel使用es
1.es是什么呢? ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发 ...
- ”动态“修改MAC地址
一:获取MAC地址 1.自定义的MAC地址 这里是例程中存放自定义MAC地址的位置,如果想修改MAC地址可以在此处修改.一般例程这里是灰色的需要在工程预编译处配置. 可以看到MCU.c文件中此处代码生 ...
- 不同网段之间实现GDB远程调试功能
前言 在开发过程中,使用gdb远程调试时,会碰到 Linux 服务器的网段和板载设备的网段不是一样的,不能正常使用 gbd 远程调试功能. 板载设备和电脑连接路由器,属于同一个网段,如192.168. ...
- 小知识:Exadata平台去掉密码输错延迟10分钟登录
生产环境不评价,若是测试环境实在受不了偶尔一次因为密码输错就要等待10分钟才能登陆的限制. 那测试环境下,如何关闭这个限制呢?很简单: # vi /etc/pam.d/sshd --找到并注释掉下面这 ...
- NC14352 旅行
题目链接 题目 题目描述 小z放假了,准备到R城市旅行,其中这个城市有N个旅游景点.小z时间有限,只能在三个旅行景点进行游玩.小明租了辆车,司机很善良,说咱不计路程,只要你一次性缴费足够,我就带你走遍 ...
- 在nginx 服务器部署vue项目
以人人快速开发的开源项目:renren-fast-vue 为例 注:这里开始认为各位都会使用nginx 打包vue项目 npm run build 测试打包的项目是否可以运行 serve dist 可 ...
- sensitive-word v0.13 特性版本发布 支持英文单词全词匹配
拓展阅读 sensitive-word-admin v1.3.0 发布 如何支持分布式部署? sensitive-word-admin 敏感词控台 v1.2.0 版本开源 sensitive-word ...