[转帖]《Linux性能优化实战》笔记(八)—— 内存是怎么工作的
一、 内存映射
我们通常所说的内存容量,指的是物理内存。物理内存也称为主存,大多数计算机用的主存都是动态随机访问内存(DRAM)。只有内核才可以直接访问物理内存。那么,进程要访问内存时,该怎么办呢?
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样,进程就可以很方便地访问内存,更确切地说是访问虚拟内存。
虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同字长(单个 CPU 指令可以处理数据的最大长度)的处理器,地址空间的范围也不同。比如最常见的 32 位和64 位系统,我画了两张图来分别表示它们的虚拟地址空间,如下所示:

可以看出,32 位系统的内核空间占用 1G,位于最高处,剩下的 3G 是用户空间;而 64 位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
既然每个进程都有一个这么大的地址空间,那么所有进程的虚拟内存加起来,自然要比实际的物理内存大得多。所以,并不是所有的虚拟内存都会分配物理内存,只有那些实际使用的虚拟内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的。
内存映射,其实就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系,如下图所示:

页表实际上存储在 CPU 的内存管理单元 MMU 中,这样,正常情况下,处理器就可以直接通过硬件,找出要访问的内存。
而当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
MMU 并不以字节为单位来管理内存,而是规定了一个内存映射的最小单位,也就是页,通常是 4 KB 大小。这样,每一次内存映射,都需要关联 4 KB 或者 4KB 整数倍的内存空间。
页的大小只有 4 KB ,导致的另一个问题就是,整个页表会变得非常大。比方说,仅 32 位系统就需要 100 多万个页表项(4GB/4KB),才可以实现整个地址空间的映射。为了解决页表项过多的问题,Linux 提供了两种机制,也就是多级页表和大页(HugePage)。
多级页表就是把内存分成区块来管理,将原来的映射关系改成区块索引和区块内的偏移。由于虚拟内存空间通常只用了很少一部分,那么,多级页表就只保存这些使用中的区块,这样就可以大大地减少页表的项数。Linux 用的正是四级页表来管理内存页,如下图所示,虚拟地址被分为 5 个部分,前 4 个表项用于选择页,而最后一个索引表示页内偏移。
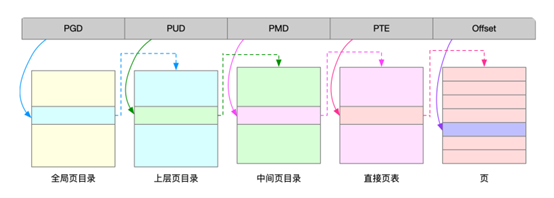
大页,顾名思义,就是比普通页更大的内存块,常见的大小有 2MB 和 1GB。大页通常用在使用大量内存的进程上,比如 Oracle、DPDK 等。
通过这些机制,在页表的映射下,进程就可以通过虚拟地址来访问物理内存了。那么具体到一个 Linux 进程中,这些内存又是怎么使用的呢?
二、 虚拟内存空间分布
最上方的内核空间不用多讲,下方的用户空间内存,其实又被分成了多个不同的段。以 32 位系统为例,我画了一张图来表示它们的关系。

通过这张图你可以看到,用户空间内存,从低到高分别是五种不同的内存段
- 只读段,包括代码和常量等。
- 数据段,包括全局变量等。
- 堆,包括动态分配的内存,从低地址开始向上增长。
- 文件映射段,包括动态库、共享内存等,从高地址开始向下增长。
- 栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB
在这五个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。其实 64 位系统的内存分布也类似,只不过内存空间要大得多。那么,更重要的问题来了,
内存究竟是怎么分配的呢?
三、 内存分配与回收
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk()和 mmap()。
1. brk()
对小块内存(小于 128K),C 标准库使用 brk() 通过移动堆顶的位置(对应上图第三层)来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。
- 优点:可以减少缺页异常的发生,提高内存访问效率
- 缺点:在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片
2. 内存映射 mmap()
对于大块内存(大于 128K),直接使用内存映射 mmap() 来分配,也就是在文件映射段(对应上图第四层)找一块空闲内存分配出去。
- 优点:分配的内存会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常,使内核的管理负担增大
- 缺点:不容易有内存碎片问题
当这两种调用发生后,其实并没有真正分配内存。内存都只在首次访问时才分配,也就是通过缺页异常进入内核中,再
由内核来分配内存。Linux 以页为单位来管理内存,并且会通过相邻页的合并,减少内存碎片化。
3. 内存回收
在应用程序用完内存后,还需要调用 free() 或 unmap() ,来释放不用的内存。当然,系统也不会任由某个进程用完所有内存。在发现内存紧张时,系统就会通过一系列机制来回收内存:
- 回收缓存,比如使用 LRU算法,回收最近使用最少的内存页
- 回收不常访问的内存,把不常用的内存通过swap直接写到磁盘中
- 杀死进程,内存紧张时系统还会通过 OOM,直接杀掉占用大量内存的进程。
Swap 其实就是把一块磁盘空间当成内存来用。它可以把进程暂时不用的数据存储到磁盘中(换出),当进程访问这些内存时,再从磁盘读取这些数据到内存中(换入)。不过通常只在内存不足时才会发生 Swap 交换,并且由于磁盘读写的速度远比内存慢,Swap 会导致严重的内存性能问题。
OOM其实是内核的一种保护机制。它监控进程的内存使用情况,并且使用 oom_score 为每个进程的内存使用情况评分:
- 一个进程消耗的内存越大,oom_score 就越大,越容易被 OOM 杀死
- 一个进程运行占用的 CPU 越多,oom_score 就越小。
当然,为了实际工作的需要,管理员可以通过 /proc 文件系统,手动设置进程的 oom_adj,从而调整进程的 oom_score。
oom_adj 的范围是 [-17, 15],数值越大,进程越容易被 OOM 杀死,其中 -17 表示禁止 OOM。
比如用下面的命令,可以把 sshd 进程的 oom_adj 调小为 -16,sshd 进程就不容易被 OOM 杀死
echo -16 > /proc/$(pidof sshd)/oom_adj
[转帖]《Linux性能优化实战》笔记(八)—— 内存是怎么工作的的更多相关文章
- 深挖计算机基础:Linux性能优化学习笔记
参考极客时间专栏<Linux性能优化实战>学习笔记 一.CPU性能:13讲 Linux性能优化实战学习笔记:第二讲 Linux性能优化实战学习笔记:第三讲 Linux性能优化实战学习笔记: ...
- Linux性能优化实战学习笔记:第五十八讲
一.上节回顾 专栏更新至今,咱们专栏最后一部分——综合案例模块也要告一段落了.很高兴看到你没有掉队,仍然在积极学习思考.实践操作,并热情地分享你在实际环境中,遇到过的各种性能问题的分析思路以及优化方法 ...
- Linux性能优化实战学习笔记:第十八讲
一.内存的分配和回收 1.管理内存的过程中,也很容易发生各种各样的“事故”, 对应用程序来说,动态内存的分配和回收,是既核心又复杂的一的一个逻辑功能模块.管理内存的过程中,也很容易发生各种各样的“事故 ...
- Linux性能优化实战学习笔记:第三十六讲
一.上节总结回顾 上一节,我们回顾了经典的 C10K 和 C1000K 问题.简单回顾一下,C10K 是指如何单机同时处理 1 万个请求(并发连接 1 万)的问题,而 C1000K 则是单机支持处理 ...
- Linux性能优化实战学习笔记:第四十五讲
一.上节回顾 专栏更新至今,四大基础模块的最后一个模块——网络篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,热情地留言和互动.还有不少同学分享了在实际生产环境中,碰到各种性能 ...
- Linux性能优化实战学习笔记:第五十二讲
一.上节回顾 上一节,我们一起学习了怎么使用动态追踪来观察应用程序和内核的行为.先简单来回顾一下.所谓动态追踪,就是在系统或者应用程序还在正常运行的时候,通过内核中提供的探针,来动态追踪它们的行为,从 ...
- Linux性能优化实战学习笔记:第五十五讲
一.上节回顾 上一节,我们一起学习了,应用程序监控的基本思路,先简单回顾一下.应用程序的监控,可以分为指标监控和日志监控两大块. 指标监控,主要是对一定时间段内的性能指标进行测量,然后再通过时间序列的 ...
- Linux性能优化实战学习笔记:第五十六讲
一.上节回顾 上一节,我带你一起梳理了,性能问题分析的一般步骤.先带你简单回顾一下. 我们可以从系统资源瓶颈和应用程序瓶颈,这两个角度来分析性能问题的根源. 从系统资源瓶颈的角度来说,USE 法是最为 ...
- Linux性能优化实战学习笔记:第五十七讲
一.上节回顾 上一节,我带你一起梳理了常见的性能优化思路,先简单回顾一下.我们可以从系统和应用程序两个角度,来进行性能优化. 从系统的角度来说,主要是对 CPU.内存.网络.磁盘 I/O 以及内核软件 ...
- 《Linux 性能优化实战—倪朋飞 》学习笔记 CPU 篇
平均负载 指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,即平均活跃进程数 可运行状态:正在使用CPU或者正在等待CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态 (Run ...
随机推荐
- 面试Java时碰到过的那些问题
项目终于忙完了,难得不加班,但回到家中却不知道干啥,打开自己的云笔记,看到了以前面试时碰到的一些面试题,下面将会把以前面试时被问到的问题都分享出来,下面的题看看小伙伴们可以答的怎样吧 HashMap实 ...
- react 事件函数中 this 绑定问题
在使用类方式创建组件时,类中定义一个函数,并且绑定到元素的点击事件上,此时这个函数中this指向并不是当前这个组件. 组件代码如下: class App extends React.Component ...
- 27、flutter Dialog 弹窗
AlertDialog //放在State<>之下 void _alertDialog() async { var result = await showDialog( barrierDi ...
- Java 创建/编辑/删除Excel迷你图表
迷你图是Excel工作表单元格中表示数据的微型图表.使用迷你图可以非常直观的显示数据变化趋势,突出最大值.最小值,放在数据表格中可起到很好的数据分析效果.本文将通过Java代码示例介绍如何在Excel ...
- 云图说|新一代Serverless应用托管引擎——CAE
本文分享自华为云社区<云图说|新一代Serverless应用托管引擎--CAE>,作者:阅识风云. 开发运营一个应用软件,面临种种挑战:软件栈厚重.开发上线慢.资源易浪费.运维投入高.突发 ...
- 三步实现BERT模型迁移部署到昇腾
本文分享自华为云社区 <bert模型昇腾迁移部署案例>,作者:AI印象. 镜像构建 1. 基础镜像(由工具链小组统一给出D310P的基础镜像) From xxx 2. 安装mindspor ...
- 云图说|图解开天企业工作台MSSE
摘要:开天企业工作台是面向企业用户的一站式数字工作台. 本文分享自华为云社区<[开天aPaaS]图解开天企业工作台MSSE>,作者:开天aPaaS小助手. 开天企业工作台(MacroVer ...
- 规模化敏捷框架何从入手?这篇文章把SAFe讲透了!
摘要:敏捷软件开发理念已渐渐被业界普遍接受,越来越多的公司和团队不得不面对一个新的问题,就是规模化敏捷的引入和实现.目前市场上规模化框架主要有SAFe,Less,Scrum of Scrums, Sp ...
- 云图说|每个成功的业务系统都离不开APIG的保驾护航
摘要:华为云API网关(APIG)是为企业开发者及合作伙伴提供的高性能.高可用.高安全的API托管服务, 帮助企业轻松构建.管理和部署不同规模的API. 本文分享自华为云社区<[云图说]第243 ...
- ElasticSearch 实现分词全文检索 - filter查询
目录 ElasticSearch 实现分词全文检索 - 概述 ElasticSearch 实现分词全文检索 - ES.Kibana.IK安装 ElasticSearch 实现分词全文检索 - Rest ...