将强化学习引入NLP:原理、技术和代码实现
本文深入探讨了强化学习在自然语言处理(NLP)中的应用,涵盖了强化学习的基础概念、与NLP的结合方式、技术细节以及实际的应用案例。通过详细的解释和Python、PyTorch的实现代码,读者将了解如何利用强化学习优化NLP任务,如对话系统和机器翻译。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

1. 强化学习简介
强化学习是机器学习的一个分支,涉及智能体(agent)如何在一个环境中采取行动,从而最大化某种长期的累积奖励。
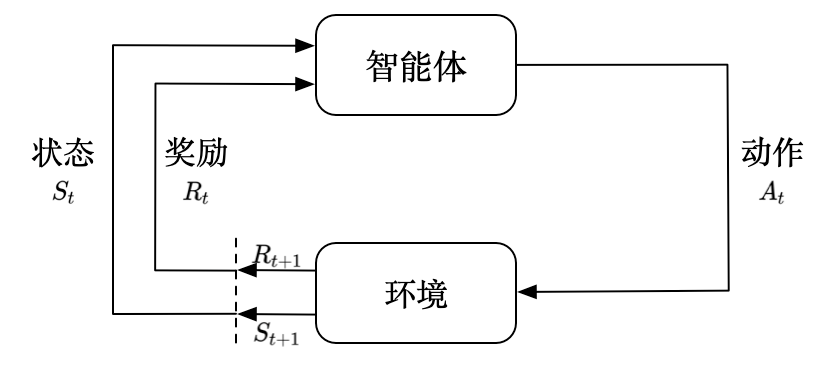
1.1 什么是强化学习?
强化学习的核心思想是:一个智能体在一个环境中采取行动,每个行动会导致环境的某种反馈(通常是奖励或惩罚)。智能体的目标是学习一个策略,该策略指定在每个状态下应该采取什么行动,从而最大化未来的累积奖励。
例子:想象一个训练机器人在迷宫中寻找出口的场景。每当机器人走到一个新的位置,它都会得到一个小的奖励或惩罚,取决于这个位置距离出口的远近。机器人的目标是学习一个策略,使其能够最快地找到迷宫的出口,并累积最多的奖励。
1.2 强化学习的核心组件
1.2.1 智能体 (Agent)
智能体是在环境中采取行动的实体,其目标是最大化长期奖励。
例子:在玩电子游戏(例如Flappy Bird)的强化学习模型中,智能体是一个虚拟的“玩家”,它决定什么时候跳跃,以避免障碍物。
1.2.2 状态 (State)
状态描述了环境在某一时刻的情况。它是智能体采取决策的基础。
例子:在国际象棋的游戏中,状态可以是棋盘上每个棋子的位置。
1.2.3 动作 (Action)
动作是智能体在给定状态下可以采取的行为。
例子:在上述的迷宫机器人例子中,动作可以是向上、向下、向左或向右移动。
1.2.4 奖励 (Reward)
奖励是对智能体采取某个动作后,环境给予其的即时反馈。它旨在指导智能体做出有利于其长期目标的决策。
例子:在自动驾驶车的强化学习模型中,如果车辆遵循交通规则并平稳驾驶,则可能获得正奖励;而如果车辆撞到障碍物或违反交通规则,则可能获得负奖励。
2. 强化学习与NLP的结合

当我们谈论自然语言处理(NLP)时,我们通常指的是与人类语言相关的任务,如机器翻译、情感分析、问答系统等。近年来,强化学习已成为NLP领域的一个热门研究方向,因为它为处理一些传统困难的NLP问题提供了新的视角和方法。
2.1 为什么在NLP中使用强化学习?
许多NLP任务的特点是其输出是结构化的、顺序的,或者任务的评估指标不容易进行微分。传统的监督学习方法可能在这些任务上遇到挑战,而强化学习提供了一个自然的框架,使得模型可以在任务中进行探索,并从延迟的反馈中学习。
例子:考虑对话系统,其中机器需要生成一系列的回复来维持与用户的对话。这不仅需要考虑每一句的合理性,还要考虑整体对话的连贯性。强化学习允许模型在与真实用户互动时探索不同的答案,并从中学习最佳策略。
2.2 强化学习在NLP中的应用场景
2.2.1 对话系统
对话系统,特别是任务驱动的对话系统,旨在帮助用户完成特定的任务,如预订机票或查询信息。在这里,强化学习可以帮助模型学习如何根据上下文生成有意义的回复,并在多轮对话中实现任务的目标。
例子:一个用户向餐厅预订系统询问:“你们有素食菜单吗?”强化学习模型可以学习生成有助于预订过程的回复,例如:“是的,我们有素食菜单。您想预订几位?”而不是简单地回答“是的”。
2.2.2 机器翻译
尽管机器翻译经常使用监督学习,但强化学习可以优化那些与直接翻译质量评估相关的指标,如BLEU分数,从而提高译文的质量。
例子:考虑从英语翻译到法语的句子。“The cat sat on the mat”可能有多种合理的法语译文。强化学习可以帮助模型探索这些可能的译文,并根据外部评估器的反馈来优化输出。
2.2.3 文本生成
文本生成任务如摘要、故事生成等,要求模型生成连贯且有意义的文本段落。强化学习为这类任务提供了一个自然的方式来优化生成内容的质量。
例子:在自动新闻摘要任务中,模型需要从长篇新闻中提取关键信息并生成一个简短的摘要。强化学习可以帮助模型学习如何权衡信息的重要性,并生成读者喜欢的摘要。
3. 技术解析
深入探讨强化学习与NLP结合时所使用的关键技术和方法,理解这些技术是如何工作的、它们如何为NLP任务提供支持。
3.1 策略梯度方法
策略梯度是一种优化参数化策略的方法,它直接估计策略的梯度,并调整参数以优化期望的奖励。
概念
策略通常表示为参数化的概率分布。策略梯度方法的目标是找到参数值,使得期望奖励最大化。为此,它估计策略关于其参数的梯度,并使用此梯度来更新参数。
例子:在机器翻译任务中,可以使用策略梯度方法优化译文的生成策略,使得翻译的质量或BLEU分数最大化。
3.2 序列决策过程
在许多NLP任务中,决策是序列性的,这意味着在一个时间点的决策会影响后续的决策和奖励。
概念
序列决策过程通常可以用马尔可夫决策过程(MDP)来描述,其中每一个状态只依赖于前一个状态和采取的动作。在这种情况下,策略定义了在给定状态下选择动作的概率。
例子:在对话系统中,系统的回复需要考虑到之前的对话内容。每次回复都基于当前的对话状态,并影响后续的对话流程。
3.3 深度强化学习
深度强化学习结合了深度学习和强化学习,使用神经网络来估计价值函数或策略。
概念
在深度强化学习中,智能体使用深度神经网络来处理输入的状态,并输出一个动作或动作的概率分布。通过训练,神经网络可以从大量的交互中学习到有效的策略。
例子:在文本生成任务中,可以使用深度强化学习来优化生成的文本内容。例如,使用神经网络模型根据当前的文章内容预测下一个词,而强化学习部分可以根据生成内容的质量给予奖励或惩罚,从而优化模型的输出。
4. 实战案例 - 对话系统
对话系统的核心目标是与用户进行有效的交互,为用户提供所需的信息或协助。在此,我们将通过一个简单的对话系统示例,展示如何利用强化学习优化对话策略。
4.1 定义状态、动作和奖励
4.1.1 状态 (State)
对话系统的状态通常包括当前对话的历史记录,例如前几轮的对话内容。
例子:如果用户问:“你们有素食菜单吗?”,状态可以是["你们有素食菜单吗?"]。
4.1.2 动作 (Action)
动作是系统可以采取的回复。
例子:系统的可能回复包括:“是的,我们有。”、“不好意思,我们没有。”或“你想要预定吗?”等。
4.1.3 奖励 (Reward)
奖励是基于系统回复的效果给出的数值。例如,如果回复满足用户需求,可以给予正奖励;否则,给予负奖励。
例子:如果用户问:“你们有素食菜单吗?”,系统回复:“是的,我们有。”,则可以给予+1的奖励。
4.2 强化学习模型
我们可以使用PyTorch来实现一个简单的深度强化学习模型。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络策略
class DialoguePolicy(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(DialoguePolicy, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
return torch.softmax(self.fc2(x), dim=1)
# 初始化模型和优化器
input_size = 10 # 假设状态向量的大小为10
hidden_size = 32
output_size = 3 # 假设有三个可能的回复
policy = DialoguePolicy(input_size, hidden_size, output_size)
optimizer = optim.Adam(policy.parameters(), lr=0.01)
# 模型的输入、输出
state = torch.rand((1, input_size)) # 假设的状态向量
action_probabilities = policy(state)
action = torch.multinomial(action_probabilities, 1) # 根据策略选择一个动作
print("Action Probabilities:", action_probabilities)
print("Chosen Action:", action.item())
4.3 交互和训练
模型与环境(用户模拟器)交互,获取奖励,然后根据奖励优化策略。在实际应用中,可以使用真实用户的反馈来优化策略。
5. 实战案例 - 机器翻译
机器翻译的目标是将一种语言的文本准确地转换为另一种语言。强化学习可以优化生成的翻译,使其更为流畅和准确。接下来,我们将探讨如何使用强化学习来优化机器翻译系统。
5.1 定义状态、动作和奖励
5.1.1 状态 (State)
机器翻译的状态可以是原文的部分或全部内容,以及已生成的翻译。
例子:原文:“How are you?”,已生成的翻译:“你好”,状态可以是["How are you?", "你好"]。
5.1.2 动作 (Action)
动作是模型决定的下一个词或短语。
例子:基于上面的状态,可能的动作包括:“吗?”、“是”、“的”等。
5.1.3 奖励 (Reward)
奖励可以基于生成的翻译的质量,例如BLEU分数,或其他评价指标。
例子:如果生成的完整翻译是:“你好吗?”,与参考翻译相比,可以计算出一个BLEU分数作为奖励。
5.2 强化学习模型
使用PyTorch实现简单的深度强化学习策略模型。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络策略
class TranslationPolicy(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(TranslationPolicy, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
return torch.softmax(self.fc2(x), dim=1)
# 初始化模型和优化器
input_size = 100 # 假设状态向量的大小为100 (原文和已生成翻译的嵌入表示)
hidden_size = 64
output_size = 5000 # 假设目标语言的词汇表大小为5000
policy = TranslationPolicy(input_size, hidden_size, output_size)
optimizer = optim.Adam(policy.parameters(), lr=0.01)
# 模型的输入、输出
state = torch.rand((1, input_size)) # 假设的状态向量
action_probabilities = policy(state)
action = torch.multinomial(action_probabilities, 1) # 根据策略选择一个动作
print("Action Probabilities:", action_probabilities[0, :10]) # 打印前10个动作的概率
print("Chosen Action:", action.item())
5.3 交互和训练
模型生成翻译,并与环境(这里可以是一个评价系统)交互以获得奖励。之后,使用这些奖励来优化翻译策略。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
将强化学习引入NLP:原理、技术和代码实现的更多相关文章
- 强化学习_Deep Q Learning(DQN)_代码解析
Deep Q Learning 使用gym的CartPole作为环境,使用QDN解决离散动作空间的问题. 一.导入需要的包和定义超参数 import tensorflow as tf import n ...
- 【转载】 “强化学习之父”萨顿:预测学习马上要火,AI将帮我们理解人类意识
原文地址: https://yq.aliyun.com/articles/400366 本文来自AI新媒体量子位(QbitAI) ------------------------------- ...
- 强化学习(二)马尔科夫决策过程(MDP)
在强化学习(一)模型基础中,我们讲到了强化学习模型的8个基本要素.但是仅凭这些要素还是无法使用强化学习来帮助我们解决问题的, 在讲到模型训练前,模型的简化也很重要,这一篇主要就是讲如何利用马尔科夫决策 ...
- [Reinforcement Learning] 强化学习介绍
随着AlphaGo和AlphaZero的出现,强化学习相关算法在这几年引起了学术界和工业界的重视.最近也翻了很多强化学习的资料,有时间了还是得自己动脑筋整理一下. 强化学习定义 先借用维基百科上对强化 ...
- 【转载】 强化学习(二)马尔科夫决策过程(MDP)
原文地址: https://www.cnblogs.com/pinard/p/9426283.html ------------------------------------------------ ...
- 强化学习(十九) AlphaGo Zero强化学习原理
在强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)中,我们讨论了MCTS的原理和在棋类中的基本应用.这里我们在前一节MCTS的基础上,讨论下DeepMind的AlphaGo Zero强化学 ...
- 强化学习之二:Q-Learning原理及表与神经网络的实现(Q-Learning with Tables and Neural Networks)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译.(This article is my personal translation for the tutor ...
- 深度学习Anchor Boxes原理与实战技术
深度学习Anchor Boxes原理与实战技术 目标检测算法通常对输入图像中的大量区域进行采样,判断这些区域是否包含感兴趣的目标,并调整这些区域的边缘,以便更准确地预测目标的地面真实边界框.不同的模型 ...
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- David Silver 强化学习原理 (中文版 链接)
教程的在线视频链接: http://www.bilibili.com/video/av9831889/ 全部视频链接: https://space.bilibili.com/74997410/vide ...
随机推荐
- 王道oj/problem7(判断数字是否为对称数)
网址:http://oj.lgwenda.com/problem/7 思路:用temp保存原数: 不断对原数进行/10及取余运算,并加到num2中: 最后判断num2是否与temp相等. 代码: #d ...
- 开源.NetCore通用工具库Xmtool使用连载 - XML操作篇
[Github源码] <上一篇> 介绍了Xmtool工具库中的发送短信类库,今天我们继续为大家介绍其中的XML操作类库. XML操作是软件开发过程中经常会遇到的情况:包括XML内容的遍历解 ...
- 12、Mybatis之分页插件
12.1.引入依赖 <!--分页插件--> <dependency> <groupId>com.github.pagehelper</groupId> ...
- Robot 框架学习笔记
Robot 框架学习笔记 为了更好地让读者理解快速学习新框架的思路,笔者接下来会继续介绍另一个名为 Robot 的自动化测试框架,希望读者能参考笔者从零开始讲解一个开发/测试框架的流程,从中总结出适合 ...
- 用ChatGPT三分钟免费做出数字人视频- 提升自媒体魅力
本教程收集于:AIGC从入门到精通教程汇总 操作指引 ChatGPT产生文案=>腾讯智影数字人播报=>粘贴文案=>导出视频. 说明:部分资源只有会员才能用~,非会员可生成5分钟视频. ...
- 数据api接口就是应用集成吗?
数据 API 接口和应用集成是两个不同的概念,但是它们之间有一定的联系.数据 API 接口是一种用于访问和传输数据的标准化接口,而应用集成则是将不同的应用程序和系统整合在一起,实现数据和业务流程的 ...
- WPF学习 - 闭坑(持续更新)
坑1:自定义控件设计原则: 既然称之为控件,那么就必定有界面与行为两部分. 界面就是展示给用户看的,用于承载类的属性.方法.事件等. 行为就是类的方法,以及这些方法需要用到的属性.字段等. WPF设计 ...
- C#结合OpenCVSharp4图片相似度识别
OpenCVSharp4图片相似度识别 需求背景:需要计算两个图片的相似度,然后将相似的图片进行归纳 1. 图片相似度算法 由于我是CRUD后端仔,对图像处理没什么概念.因此网上调研了几种相似度算法分 ...
- 关于oop的一点回忆
昨天在一个程序员行业群里看到别人发了一条消息, 大意是:要做好封装啦,不要随便用public啦,不要随便改别人代码啦. 说的好像就是我,因为,我这辈子最后悔的一件事情之一就是手贱改动别人代码. 那大概 ...
- POI 操作sheet.shiftRows注意点
sheet.shiftRows后使用getRow/getCell会导致NullPointException 正确使用应该是CreateRow CreateCell