深度解析 PyTorch Autograd:从原理到实践
本文深入探讨了 PyTorch 中 Autograd 的核心原理和功能。从基本概念、Tensor 与 Autograd 的交互,到计算图的构建和管理,再到反向传播和梯度计算的细节,最后涵盖了 Autograd 的高级特性。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人

一、Pytorch与自动微分Autograd
自动微分(Automatic Differentiation,简称 Autograd)是深度学习和科学计算领域的核心技术之一。它不仅在神经网络的训练过程中发挥着至关重要的作用,还在各种工程和科学问题的数值解法中扮演着关键角色。
1.1 自动微分的基本原理
在数学中,微分是一种计算函数局部变化率的方法,广泛应用于物理、工程、经济学等领域。自动微分则是通过计算机程序来自动计算函数导数或梯度的技术。
自动微分的关键在于将复杂的函数分解为一系列简单函数的组合,然后应用链式法则(Chain Rule)进行求导。这个过程不同于数值微分(使用有限差分近似)和符号微分(进行符号上的推导),它可以精确地计算导数,同时避免了符号微分的表达式膨胀问题和数值微分的精度损失。
import torch
# 示例:简单的自动微分
x = torch.tensor(2.0, requires_grad=True)
y = x ** 2 + 3 * x + 1
y.backward()
# 打印梯度
print(x.grad) # 输出应为 2*x + 3 在 x=2 时的值,即 7
1.2 自动微分在深度学习中的应用
在深度学习中,训练神经网络的核心是优化损失函数,即调整网络参数以最小化损失。这一过程需要计算损失函数相对于网络参数的梯度,自动微分在这里发挥着关键作用。
以一个简单的线性回归模型为例,模型的目标是找到一组参数,使得模型的预测尽可能接近实际数据。在这个过程中,自动微分帮助我们有效地计算损失函数关于参数的梯度,进而通过梯度下降法更新参数。
# 示例:线性回归中的梯度计算
x_data = torch.tensor([1.0, 2.0, 3.0])
y_data = torch.tensor([2.0, 4.0, 6.0])
# 模型参数
weight = torch.tensor([1.0], requires_grad=True)
# 前向传播
def forward(x):
return x * weight
# 损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
# 计算梯度
l = loss(x_data, y_data)
l.backward()
print(weight.grad) # 打印梯度
1.3 自动微分的重要性和影响
自动微分技术的引入极大地简化了梯度的计算过程,使得研究人员可以专注于模型的设计和训练,而不必手动计算复杂的导数。这在深度学习的快速发展中起到了推波助澜的作用,尤其是在训练大型神经网络时。
此外,自动微分也在非深度学习的领域显示出其强大的潜力,例如在物理模拟、金融工程和生物信息学等领域的应用。
二、PyTorch Autograd 的核心机制

PyTorch Autograd 是一个强大的工具,它允许研究人员和工程师以极少的手动干预高效地计算导数。理解其核心机制不仅有助于更好地利用这一工具,还能帮助开发者避免常见错误,提升模型的性能和效率。
2.1 Tensor 和 Autograd 的相互作用
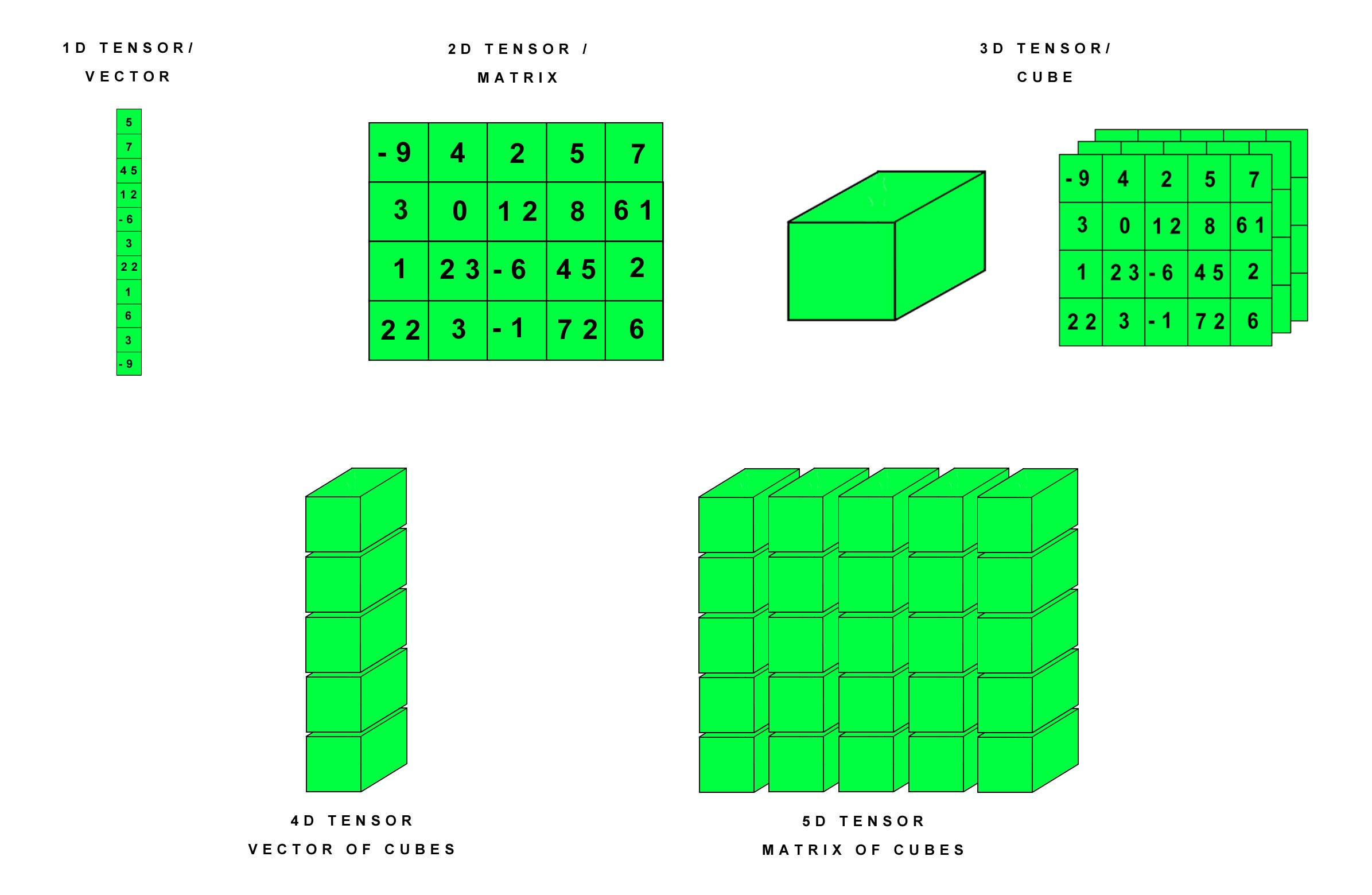
在 PyTorch 中,Tensor 是构建神经网络的基石,而 Autograd 则是实现神经网络训练的关键。了解 Tensor 和 Autograd 如何协同工作,对于深入理解和有效使用 PyTorch 至关重要。
Tensor:PyTorch 的核心
Tensor 在 PyTorch 中类似于 NumPy 的数组,但它们有一个额外的超能力——能在 Autograd 系统中自动计算梯度。
- Tensor 的属性: 每个 Tensor 都有一个
requires_grad属性。当设置为True时,PyTorch 会跟踪在该 Tensor 上的所有操作,并自动计算梯度。
Autograd:自动微分的引擎
Autograd 是 PyTorch 的自动微分引擎,负责跟踪那些对于计算梯度重要的操作。
- 计算图: 在背后,Autograd 通过构建一个计算图来跟踪操作。这个图是一个有向无环图(DAG),它记录了创建最终输出 Tensor 所涉及的所有操作。
Tensor 和 Autograd 的协同工作
当一个 Tensor 被操作并生成新的 Tensor 时,PyTorch 会自动构建一个表示这个操作的计算图节点。
示例:简单操作的跟踪
import torch # 创建一个 Tensor,设置 requires_grad=True 来跟踪与它相关的操作
x = torch.tensor([2.0], requires_grad=True) # 执行一个操作
y = x * x # 查看 y 的 grad_fn 属性
print(y.grad_fn) # 这显示了 y 是通过哪种操作得到的
这里的
y是通过一个乘法操作得到的。PyTorch 会自动跟踪这个操作,并将其作为计算图的一部分。反向传播和梯度计算
当我们对输出的 Tensor 调用
.backward()方法时,PyTorch 会自动计算梯度并将其存储在各个 Tensor 的.grad属性中。# 反向传播,计算梯度
y.backward() # 查看 x 的梯度
print(x.grad) # 应输出 4.0,因为 dy/dx = 2 * x,在 x=2 时值为 4
2.2 计算图的构建和管理
在深度学习中,理解计算图的构建和管理是理解自动微分和神经网络训练过程的关键。PyTorch 使用动态计算图,这是其核心特性之一,提供了极大的灵活性和直观性。
计算图的基本概念
计算图是一种图形化的表示方法,用于描述数据(Tensor)之间的操作(如加法、乘法)关系。在 PyTorch 中,每当对 Tensor 进行操作时,都会创建一个表示该操作的节点,并将操作的输入和输出 Tensor 连接起来。
- 节点(Node):代表了数据的操作,如加法、乘法。
- 边(Edge):代表了数据流,即 Tensor。
动态计算图的特性
PyTorch 的计算图是动态的,即图的构建是在运行时发生的。这意味着图会随着代码的执行而实时构建,每次迭代都可能产生一个新的图。
示例:动态图的创建
import torch x = torch.tensor(1.0, requires_grad=True)
y = torch.tensor(2.0, requires_grad=True) # 一个简单的运算
z = x * y # 此时,一个计算图已经形成,其中 z 是由 x 和 y 通过乘法操作得到的
反向传播与计算图
在深度学习的训练过程中,反向传播是通过计算图进行的。当调用 .backward() 方法时,PyTorch 会从该点开始,沿着图逆向传播,计算每个节点的梯度。
示例:反向传播过程
# 继续上面的例子
z.backward() # 查看梯度
print(x.grad) # dz/dx,在 x=1, y=2 时应为 2
print(y.grad) # dz/dy,在 x=1, y=2 时应为 1
计算图的管理
在实际应用中,对计算图的管理是优化内存和计算效率的重要方面。
图的清空:默认情况下,在调用
.backward()后,PyTorch 会自动清空计算图。这意味着每个.backward()调用都是一个独立的计算过程。对于涉及多次迭代的任务,这有助于节省内存。禁止梯度跟踪:在某些情况下,例如在模型评估或推理阶段,不需要计算梯度。使用
torch.no_grad()可以暂时禁用梯度计算,从而提高计算效率和减少内存使用。with torch.no_grad():
# 在这个块内,所有计算都不会跟踪梯度
y = x * 2
# 这里 y 的 grad_fn 为 None
2.3 反向传播和梯度计算的细节
反向传播是深度学习中用于训练神经网络的核心算法。在 PyTorch 中,这一过程依赖于 Autograd 系统来自动计算梯度。理解反向传播和梯度计算的细节是至关重要的,它不仅帮助我们更好地理解神经网络是如何学习的,还能指导我们进行更有效的模型设计和调试。
反向传播的基础
反向传播算法的目的是计算损失函数相对于网络参数的梯度。在 PyTorch 中,这通常通过在损失函数上调用 .backward() 方法实现。
- 链式法则: 反向传播基于链式法则,用于计算复合函数的导数。在计算图中,从输出到输入反向遍历,乘以沿路径的导数。
反向传播的 PyTorch 实现
以下是一个简单的 PyTorch 示例,说明了反向传播的基本过程:
import torch
# 创建 Tensor
x = torch.tensor(1.0, requires_grad=True)
w = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(3.0, requires_grad=True)
# 构建一个简单的线性函数
y = w * x + b
# 计算损失
loss = y - 5
# 反向传播
loss.backward()
# 检查梯度
print(x.grad) # dy/dx
print(w.grad) # dy/dw
print(b.grad) # dy/db
在这个例子中,loss.backward() 调用触发了整个计算图的反向传播过程,计算了 loss 相对于 x、w 和 b 的梯度。
梯度积累
在 PyTorch 中,默认情况下梯度是累积的。这意味着在每次调用 .backward() 时,梯度都会加到之前的值上,而不是被替换。
- 梯度清零: 在大多数训练循环中,我们需要在每个迭代步骤之前清零梯度,以防止梯度累积影响当前步骤的梯度计算。
# 清零梯度
x.grad.zero_()
w.grad.zero_()
b.grad.zero_()
# 再次进行前向和反向传播
y = w * x + b
loss = y - 5
loss.backward()
# 检查梯度
print(x.grad) # dy/dx
print(w.grad) # dy/dw
print(b.grad) # dy/db
高阶梯度
PyTorch 还支持高阶梯度计算,即对梯度本身再次进行微分。这在某些高级优化算法和二阶导数的应用中非常有用。
# 启用高阶梯度计算
z = y * y
z.backward(create_graph=True)
# 计算二阶导数
x_grad = x.grad
x_grad2 = torch.autograd.grad(outputs=x_grad, inputs=x)[0]
print(x_grad2) # d^2y/dx^2
三、Autograd 特性全解
PyTorch 的 Autograd 系统提供了一系列强大的特性,使得它成为深度学习和自动微分中的重要工具。这些特性不仅提高了编程的灵活性和效率,还使得复杂的优化和计算变得可行。
动态计算图(Dynamic Graph)
PyTorch 中的 Autograd 系统基于动态计算图。这意味着计算图在每次执行时都是动态构建的,与静态图相比,这提供了更大的灵活性。
示例:动态图的适应性
import torch x = torch.tensor(1.0, requires_grad=True)
if x > 0:
y = x * 2
else:
y = x / 2
y.backward()
这段代码展示了 PyTorch 的动态图特性。根据
x的值,计算路径可以改变,这在静态图框架中是难以实现的。
自定义自动微分函数
PyTorch 允许用户通过继承 torch.autograd.Function 来创建自定义的自动微分函数,这为复杂或特殊的前向和后向传播提供了可能。
示例:自定义自动微分函数
class MyReLU(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
return input.clamp(min=0) @staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
grad_input[input < 0] = 0
return grad_input x = torch.tensor([-1.0, 1.0, 2.0], requires_grad=True)
y = MyReLU.apply(x)
y.backward(torch.tensor([1.0, 1.0, 1.0]))
print(x.grad) # 输出梯度
这个例子展示了如何定义一个自定义的 ReLU 函数及其梯度计算。
requires_grad 和 no_grad
在 PyTorch 中,requires_grad 属性用于指定是否需要计算某个 Tensor 的梯度。torch.no_grad() 上下文管理器则用于临时禁用所有计算图的构建。
示例:使用
requires_grad和no_gradx = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) with torch.no_grad():
y = x * 2 # 在这里不会追踪 y 的梯度计算 z = x * 3
z.backward(torch.tensor([1.0, 1.0, 1.0]))
print(x.grad) # 只有 z 的梯度被计算
在这个例子中,
y的计算不会影响梯度,因为它在torch.no_grad()块中。
性能优化和内存管理
PyTorch 的 Autograd 系统还包括了针对性能优化和内存管理的特性,比如梯度检查点(用于减少内存使用)和延迟执行(用于优化性能)。
示例:梯度检查点
使用
torch.utils.checkpoint来减少大型网络中的内存占用。import torch.utils.checkpoint as checkpoint def run_fn(x):
return x * 2 x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = checkpoint.checkpoint(run_fn, x)
y.backward(torch.tensor([1.0, 1.0, 1.0]))
这个例子展示了如何使用梯度检查点来优化内存使用。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
深度解析 PyTorch Autograd:从原理到实践的更多相关文章
- 深度解析 Vue 响应式原理
深度解析 Vue 响应式原理 该文章内容节选自团队的开源项目 InterviewMap.项目目前内容包含了 JS.网络.浏览器相关.性能优化.安全.框架.Git.数据结构.算法等内容,无论是基础还是进 ...
- 深入解析SQL Server并行执行原理及实践(上)
在成熟领先的企业级数据库系统中,并行查询可以说是一大利器,在某些场景下他可以显著的提升查询的相应时间,提升用户体验.如SQL Server, Oracle等, Mysql目前还未实现,而Postgre ...
- 深入解析SQL Server并行执行原理及实践(下)
谈完并行执行的原理,咱们再来谈谈优化,到底并行执行能给我们带来哪些好处,我们又应该注意什么呢,下面展开. Amdahl’s Law 再谈并行优化前我想有必要谈谈阿姆达尔定律,可惜老爷子去年已经驾鹤先 ...
- 深度解析synchronized的实现原理(并发一)
一.synchronized实现原理 1.synchronized实现同步的基础: 1).普通同步方法:锁是当前实例对象 2).静态同步方法:锁是当前类的class对象 3).同步方法块:锁是括号里面 ...
- 深度解析HashMap集合底层原理
目录 前置知识 ==和equals的区别 为什么要重写equals和HashCode 时间复杂度 (不带符号右移) >>> ^异或运算 &(与运算) 位移操作:1<&l ...
- 深入解析SQL Server并行执行原理及实践
http://dbaplus.cn/news-21-431-1.html
- 深入解析SQL Server并行执行原理及实践(上) ---高继伟
http://www.cnblogs.com/shanksgao/p/5497106.html
- java8学习之收集器枚举特性深度解析与并行流原理
首先先来找出上一次[http://www.cnblogs.com/webor2006/p/8353314.html]在最后举的那个并行流报错的问题,如下: 在来查找出上面异常的原因之前,当然得要一点点 ...
- 【进阶3-5期】深度解析 new 原理及模拟实现(转)
这是我在公众号(高级前端进阶)看到的文章,现在做笔记 https://github.com/yygmind/blog/issues/24 new 运算符创建一个用户定义的对象类型的实例或具有构造函数的 ...
- [源码解析] PyTorch 分布式(14) --使用 Distributed Autograd 和 Distributed Optimizer
[源码解析] PyTorch 分布式(14) --使用 Distributed Autograd 和 Distributed Optimizer 目录 [源码解析] PyTorch 分布式(14) - ...
随机推荐
- Linux离线安装Mysql-5.7
1.背景描述 在真实业务场景下,Linux服务器一般位于内网,所以无法直接访问互联网资源: 特别是安装数据库的Linux服务器,在网络方面的管控只会更加严格: 因此,需要提前下载好相关资源,再传输到内 ...
- Record - Dec. 2st, 2020 - Exam. REC
Prob. 1 Desc. & Link. 有一个基础想法,即一次操作三可以用一次操作一加上一次操作二来实现,然后他又没让我们最小化操作次数,所以我们令 \(M=\min\{A+R,M\}\) ...
- Redis系列24:Redis使用规范
Redis系列1:深刻理解高性能Redis的本质 Redis系列2:数据持久化提高可用性 Redis系列3:高可用之主从架构 Redis系列4:高可用之Sentinel(哨兵模式) Redis系列5: ...
- 个人理解strcpy
char * strcpy(char *dst,const char *src) { if((dst==NULL)||(src==NULL)) return NULL; char *ret = dst ...
- Ubuntu更新软件的命令
更新软件源 apt-get update 更新升级所有软件 apt-get upgrade 更新某个软件 apt-get upgrade 名 列出可更新的软件 apt list --upgradabl ...
- vue 基于原生动画的自动滚动表格
前言 公司展示大屏需要写滚动表格,通过滚动播放数据,自己随便摸了一个基于动画的自动滚动表格 原理 根据每行的大小和设置的每行滚动时间设置滚动位置,动态添加动画,并把数组第一项移动到最后一项,并订阅该动 ...
- TopCoder 15903 EllysNim
TopCoder 15903 EllysNim(https://vjudge.net/problem/TopCoder-15903) \(n\)看似有点东西,实际上就只是一个贪心... 设\(i\)表 ...
- 漫谈C#的定时执行程序
1.写法1 task的lambda表达式 #region 写法1 task的lambda表达式 //static void Main() //{ // // 创建并启动两个任务 // Task tas ...
- chatgpt镜像站汇总 - 聚合GPT【即时更新】
自荐下由我开发的聚合GPT网站,这边的GPT镜像站均为免费.无登录.无次数限制的!会及时剔除失效.添加可用地址[欢迎STAR.PR] 地址:https://ele-cat.gitee.io/comp- ...
- 队列(c++源码)
queue.h #ifndef QUEUE_H_ #define QUEUE_H_ #include<iostream> template<class T> struct No ...