分享6个SQL小技巧
原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,非公众号转载保留此声明。
简介
经常有小哥发出疑问,SQL还能这么写?我经常笑着回应,SQL确实可以这么写。其实SQL学起来简单,用起来也简单,但它还是能写出很多变化,这些变化读懂它不难,但要自己Get到这些变化,可能需要想一会或在网上找一会。
各种join
关于join的介绍,比较流行的就是这张图了,如下:
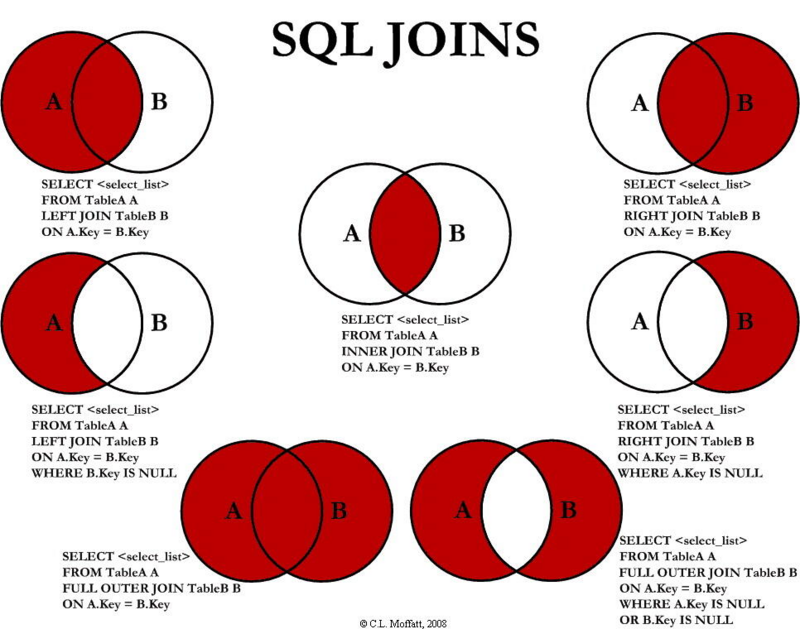
简单的解释如下:
- join:内联接,也可写成inner join,取两表关联字段相交的那部分数据。
- left join:左外联接,也可写成left outer join,取左表数据,若关联不到右表,右表为空。
- right join:右外联接,也可写成right outer join,取右表数据,若关联不到左表,左表为空。
- full join:全联接,也可写成full outer join,取左表和右表中所有数据。
但注意上图,里面还有几个Key is null的情况,它可以将两表相交的那部分数据排除掉!
也正是因为这个特性,一种很常见的SQL技巧是,用left join可替换not exists、not in等相关子查询,如下:
select * from tableA A
where not exists (select 1 from tableB B where B.Key=A.Key)
-- 使用left join的等价写法
select * from tableA A
left join tableB B on B.Key=A.Key where B.Key is null
也比较好理解,只有当左表的数据在右表中不存在时,B.Key is null才成立。
查询各类别最大的那条数据
比如在学籍管理系统中,有一类很常见的需求,查询每学科分数最高的那条数据,有如下几种写法:
select * from stu_score s
where s.course_id in ('Maths','English')
and s.score = (select max(score) from stu_score s1 where s1.course_id = s.course_id)
比较好理解,考分最高其实就是过滤出分数等于最大分数的记录。
在不能使用子查询的场景下,也可转换成join,如下:
select * from stu_score s
left join stu_score s1 on s1.course_id = s.course_id and s1.score > s.score
where s.course_id in ('Maths','English') and s1.id is null
这和前面用left join改写not exists类似,通过s1.id is null过滤出left join关联条件不满足时的数据,什么情况left join关联条件不满足呢,当s表记录是分数最大的那条记录时,s1.score > s.score条件自然就不成立了,所以它过滤出来的数据,就是学科中分数最大的那条记录。
一直以来,我看到SQL的join的条件大都是a.field=b.field这种形式,导致我以为join只能写等值条件,实际上,join条件和where中一样,支持>、<、like、in甚至是exists子查询等条件,大家也一定不要忽视了这一点。
上面场景还有一种写法,就是使用group by先把各学科最大分算出来,然后再关联出相应数据,如下:
select * from
(select s.course_id,max(s.score) max_score stu_score s where s.course_id in ('Maths','English') group by s.course_id) sm
join stu_score s1 on s1.course_id = sm.course_id and s1.score=sm.max_score
查询各类别top n数据
比如在学籍管理系统中,查询每学科分数前5的记录,类似这种需求也很常见,比较简单明了的写法如下:
select * from stu_score s
where s.course_id in ('Maths','English')
and (select count(*) from stu_score s1 where s1.course_id = s.course_id and s1.score > s.score) < 5
很显然,第5名只有4个学生比它分数高,第4名只有3个学生比它分数高,依此类推。
LATERAL join
MySQL8为join提供了一个新的语法LATERAL,使得被关联表B在联接前可以先根据关联表A的字段过滤一下,然后再进行关联。
这个新的语法,可以非常简单的解决上面top n的场景,如下:
select * from stu_course c
join LATERAL (select * from stu_score s where c.course_id = s.course_id order by s.score desc limit 5) s1 on c.course_id = s1.course_id
where c.course_name in ('数学','英语')
如上,每个学科查询出它的前5名记录,然后再关联起来。
统计多个数量
使用count(*)可以统计数量,但有些场景想统计多个数量,如统计1天内单量、1周内单量、1月内单量。
用count(*)的话,需要扫描3次表,如下:
select count(*) from order where add_time > DATE_SUB(now(), INTERVAL 1 DAY)
union all
select count(*) from order where add_time > DATE_SUB(now(), INTERVAL 1 WEEK)
union all
select count(*) from order where add_time > DATE_SUB(now(), INTERVAL 1 MONTH)
其实扫描一次表也可以实现,用sum来代替count即可,如下:
select sum(IF(add_time > DATE_SUB(now(), INTERVAL 1 DAY)), 1, 0) day_order_cnt,
sum(IF(add_time > DATE_SUB(now(), INTERVAL 1 WEEK)), 1, 0) week_order_cnt,
sum(IF(add_time > DATE_SUB(now(), INTERVAL 1 MONTH)), 1, 0) month_order_cnt
from order where add_time > DATE_SUB(now(), INTERVAL 1 MONTH)
IF是mysql的逻辑判断函数,当其第一个参数为true时,返回第二个参数值,即1,否则返回第三个参数值0,然后再使用sum加起来,就是各条件为true的数量了。
数据对比
有时,我们需要对比两个表的数据是否一致,最简单的方法,就是在两边查询出结果集,然后逐行逐字段对比。
但是这样对比的效率比较低下,因为它要两个表的数据全都查出来,其实我们不一定非要都查出来,只要计算出一个hash值,然后对比hash值即可,如下:
select BIT_XOR(CRC32(CONCAT(ifnull(column1,''),ifnull(column2,'')))) as checksum
from table_name where add_time > '2020-02-20' and add_time < '2020-02-21';
先使用CONCAT将要对比的列连接起来,然后使用CRC32或MD5计算hash值,最后使用聚合函数BIT_XOR将多行hash值异或合并为一个hash值。
这个查询最终只会返回1条hash值,查询数据量大大减少了,数据对比效率就上去了。
总结
SQL看起来简单,其实有很多细节与技巧,如果你也有其它技巧,欢迎留言分享讨论
分享6个SQL小技巧的更多相关文章
- SQL小技巧小知识
1.[ ]的使用 当我们所要查的表是系统关键字或者表名中含有空格时,需要用[]括起来,例如新建了两个表,分别为user,user info,那么select * from user和select * ...
- 谈谈如何用eoLinker管理各类API接口及分享API接口管理小技巧教程
在前后端分离的开发模式下,前后端往往需要接口文档来进行交互.我的上一篇随笔中已经写到用传统的文档写接口时,由于需求经常变动,接口文档也会随之变动.一开始,某接口信息已经写入文档,但后期因为需求变动,发 ...
- 手拼SQL小技巧,WHERE 1=1
由于项目要求,要手动拼接SQL,(不知道领导们怎么想的--),然后就再次回到原始时代,append(SQL). 但后面查询牵扯到动态多条件,如果是mybatis的话就直接 可以用<if>标 ...
- sql小技巧 group by datetime类型字段,只取其中的日期部分
工作中经常会遇到,要在sql中查询报表,查询结果要求按照日期来罗列, 或按照天, 或按照月,年. 这个时候我们经常会苦恼,datetime是精确到毫秒的,如果单纯的group by datetime就 ...
- SQL Server Profiler 跟踪sql小技巧
使用Profile监控sql时候经常会有很多很多的sql,想查询那条是自己的sql很困难,但是连接字串有个参数可以解决这个问题这个参数是Application Name例如说 我们在需要的数据库连接中 ...
- APP Store审核太慢?大神分享快速审核的小技巧
这节课要来跟大家讲讲怎样可以快速的有效的通过苹果的审核,大家可能也有听说过苹果的快审,苹果的审核流程除了机器审核还有一个人工的审核,以前的苹果审核时用到的时间也是不短,一些有经验的开发者可能也会发现在 ...
- SQL小技巧(一)拼音首字母的模糊查询
基于Microsoft SQL Server 的标量值函数fun_GetPy,借鉴其他优秀的博主文章,此处贴出源码,以及使用方法 1.打开新建查询,贴如下代码,F5 /****** Object: U ...
- sql小技巧
--实际只会更新一条.可有效防止误操作.特别是操作线上正式数据时. UPDATE TOP(1) Table2 SET Culumn1='value'WHERE id IN(269102,269104) ...
- 13个mysql数据库的实用SQL小技巧
此文章为转载 使用CASE来重新定义数值类型 SELECT id,title, (CASE date WHEN '0000-00-00' THEN '' ELSE date END) AS date ...
- sql 小技巧
declare @pids varchar(max)='' ),pid)+','+@pids from product where pname like '%red%' select @pids
随机推荐
- 自己动手从零写桌面操作系统GrapeOS系列教程——1.2 GrapeOS真机演示
学习操作系统原理最好的方法是自己写一个简单的操作系统. GrapeOS操作系统之前一直运行在模拟器和虚拟机中,今天我们来演示一下GrapeOS在真机上运行的情况. 一.物理机真机 今天演示用的真机是一 ...
- pandas之画图
Pandas 在数据分析.数据可视化方面有着较为广泛的应用,Pandas 对 Matplotlib 绘图软件包的基础上单独封装了一个plot()接口,通过调用该接口可以实现常用的绘图操作.本节我们深入 ...
- pysimplegui之使用多线程,避免程序卡死
这个问题我也遇到过,就是还需要一个while循环的时候,放到gui本身循环会卡死,这时候就需要启动多线程 需要"长时间"的操作 如果您是 Windows 用户,您会在其标题栏中看到 ...
- [Git]解决GIT冲突问题:git pull failed
1 文由 花了很长时间一次性修改了项目的一大堆文件,准备最后git pull同步一下本地仓库代码,再一次性git commit,git push新代码的. but天不遂人愿,git pull时产生冲突 ...
- Android ViewGroup的事件分发机制-源码分析
为了更好的理解ViewGroup的事件分发机制,我们在自定义一个MyLinerLayout. public class MyLinearLayout extends LinearLayout { pr ...
- 会使用ChatGPT写作业找工作会不会加分啊!!!代码问题直接问ChatGPT不比CSDN好多了吗
1.使用reactnative写一个数字游戏 2.MySQL问题
- 【LeetCode动态规划#07】01背包问题一维写法(状态压缩)实战,其二(目标和、零一和)
目标和(放满背包的方法有几种) 力扣题目链接(opens new window) 难度:中等 给定一个非负整数数组,a1, a2, ..., an, 和一个目标数,S.现在你有两个符号 + 和 -.对 ...
- Linux系统如何查看内核版本信息
使用如下命令: cat /etc/os-release 显示结果如下,系统内核不同,信息不同.
- Rails 中的布局和渲染
Templates, Partials, and Layouts 在 Rails 中,视图是用于呈现 HTML.XML.JSON 等响应的模板.Rails 的视图系统支持模板.局部模板和布局模板,它们 ...
- 笔记二:进程间的通信(fork、孤儿进程,僵死进程等)
以下是以前学习<unix环境高级编程>时的一些笔记和测试代码,好久没看过了,没有再次验证,存在错误的话,希望见谅,分享下主要是!!! ps 查看系统中的进程 ps– ...