Daph:新一代流批一体数据集成与数据处理工具
Daph源码位于gitee,地址是https://gitee.com/dasea96/daph
概述
Daph的中文名称是大副,大副是职位仅低于船长的船舶驾驶员,甲板部(驾驶部)负责人,船长的主要助手。
Daph的英文名称,取自【有向无环图Directed Acyclic Graph】的第一个字母与最后三个字母。
Daph是一个通用的数据集成与数据处理平台级工具,可用于构建可视化配置化的数据集成与数据处理平台。
Daph,大道至简。
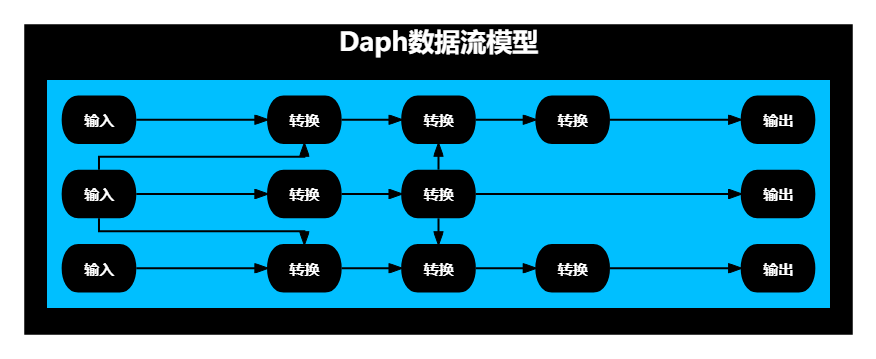
Daph的核心概念是节点,节点具有输入线与输出线,每条线中承载数据,节点承载任意数据处理逻辑。
Daph的核心构件是一个自创的通用DAG数据流引擎,可以流转任意Java/Scala数据结构,可以引入任何基于Java平台或具有Java客户端的数据计算组件作为数据流底层数据计算引擎。
Daph的核心功能是联接多个节点构成DAG图,并流转数据。
功能
- 全量增量整库整表数据集成:以极简配置方式,完成全量增量整库整表数据集成
- 已支持50多种数据源类型的全量整表同步
- 已支持Flink-cdc所支持的所有数据源类型的cdc整表同步
- 已支持mysql/postgresql/oracle/sqlserver/doris/starrocks到mysql/postgresql/oracle/sqlserver/doris/starrocks/hive/iceberg/kafka的全量增量整库同步
- 流批一体复杂数据处理:以极简配置方式,完成流批一体任意复杂多表sql处理逻辑
价值
- 统一数据开发视图:Daph既具有丰富的数据集成能力,又具有强大的数据处理能力
- 降低数据开发门槛:通过配置文件,完成数据开发
- 缩短数据开发周期:开箱即用的海量数据集成与数据处理能力,极简的安装部署方式,极简的二次开发过程
特点
- 通用:可连接任意JVM类型的节点,构成DAG图,并流转任意Java/Scala数据结构。因此,不仅目前能够用于构建DAG数据流,而且具有潜在的任意粒度的DAG任务调度的潜力,可基于一个daph-core,统一任务开发与任务调度,实现一体化的可视化任务开发与任务调度平台。
- 简单:概念简单,配置简单
- 基于开源计算引擎,不引入新的复杂概念
- 节点配置简单,比如daph-spark节点配置项,与Spark配置项几乎完全一致,不增加学习开销。
- 强大:架构强大,功能强大
- 架构层面具有多层环绕运行体系,可定制任意Job级/DAG级/节点级/方法级功能,比如节点数据预览功能、节点监控功能、前置后置SQL功能。目前所有节点均已支持前置后置建表功能,daph-spark所有节点已支持前置后置SQL功能
- daph-spark仅有5个连接器、6个转换器,却已支持44种数据源的流批读写,且能随时扩充更多数据源;已支持对单表的map、filter、sql处理,对多表的join及任意复杂sql处理;且支持spark能支持的任何catalog
- daph-flink仅有2个连接器、1个转换器,却已支持任何flink-sql支持的数据源的流批读写;已支持对单表与多表的任意复杂sql处理;且支持flink能支持的任何catalog。
- 聚焦:聚焦于可视化配置化的数据集成与数据处理,聚焦于简化开源计算引擎的使用,不增加学习开销。
- 流转任意数据结构:可流转任意JVM数据结构,比如Java/Scala List、Spark DataFrame、Flink DataStream。
- 支持多种计算引擎:可引入任何基于Java平台或具有Java客户端的数据计算组件作为数据流底层数据计算引擎,比如Java/Scala/Spark/Flink,等等。
- 快速扩展节点:可方便地扩展与部署具有任意逻辑的节点,比如扩展新的连接器节点,以支持读写新的数据库类型;比如扩展新的转换器节点,以便引入特定数据处理逻辑处理数据。只需要完成以下三点,即可完成:
1)实现一个配置接口与一个功能接口
2)将扩展的节点对应的jar放在服务器目录
3)json文件中配置扩展节点信息。
对比业界类似软件
Daph:
- 既能用于数据集成,又能用于复杂的数据处理
- 极致通用的DAG模型,能够流转任意JVM对象,引入任意符合Spark/Flink编程模型的计算引擎
- 不重复造轮子,专注于简化开源计算引擎的使用,配置项几乎与开源计算引擎一一对应
- 完美运用开源计算引擎的各项能力,包括且不限于流批处理能力、catalog能力、sql能力
- 能够及时从开源计算引擎的生态系统中获益
- 比如Spark,一旦新出现一种数据库连接器,在Daph中只需要在pom.xml中添加依赖,就能立刻使用
| 对比维度 | Daph | SeaTunnel | StreamSets | StreamX | Kettle | Chunjun |
|---|---|---|---|---|---|---|
| 通用性 | 高 | 低 | 低 | 低 | 低 | 低 |
| 易用性 | 高 | 中 | 高 | 高 | 高 | 中 |
| 开源 | 是 | 是 | 否 | 是 | 是 | 是 |
| 数据结构流转能力 | 所有JVM对象 | Dataset[Row]/DataStream[Row]/Zeta数据结构 | 无 | 无 | 无 | 无 |
| 计算引擎接入能力 | 任意符合Spark/Flink编程模型的计算引擎 | Spark/Flink/Zeta | Spark | Spark/Flink | Java | Flink |
| 流水线模型 | DAG | 线 | DAG | 点 | DAG | 线 |
| 功能扩展性 | 高 | 中 | 低 | 中 | 低 | 中 |
| 学习成本 | 低 | 高 | 高 | 中 | 中 | 中 |
| 开发成本 | 低 | 高 | 高 | 中 | 高 | 中 |
| 运维成本 | 低 | 高 | 低 | 中 | 低 | 中 |
架构模型
数据流模型
Daph的数据流模型是DAG数据流模型,如下图所示:
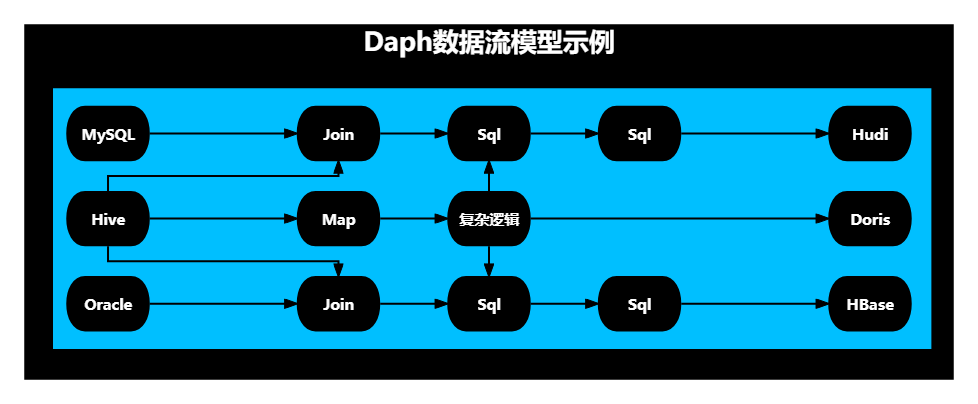
例如一个数据集成与数据处理综合场景,如下图所示:
- 输入是一张MySQL表、一张Hive表,一张Oracle表
- 处理逻辑包含map、join、sql、自定义复杂逻辑
- 输出是一个Hudi表、一个Doris表、一个HBase表
运行模型
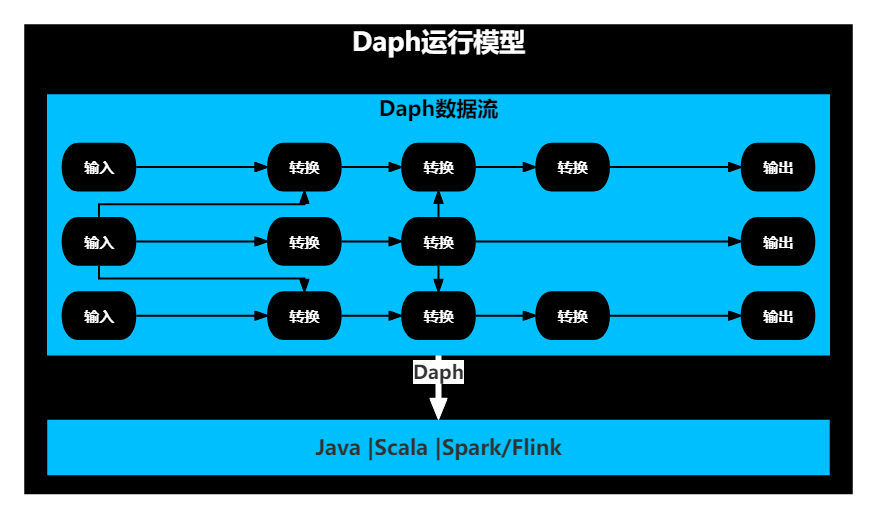
Daph通过节点包裹代码片段,将节点连成一个DAG图,并最终将DAG图形成一个完整的应用程序。
- 一个DAG图就是一个完整运行逻辑,比如当使用Spark作为底层计算引擎,一个DAG图就是一个完整的Spark应用程序。
- 一个DAG图中可以同时包含Java节点、Scala节点、Spark节点,也可以同时包含Java节点、Scala节点、Flink节点,但不能同时包含Spark与Flink节点。
- 底层计算引擎决定了应用程序的类型。
JVM引擎对应的就是原生Java/Scala应用程序;
Spark引擎对应的就是Spark应用程序;
Flink引擎对应的就是Flink应用程序。
Daph运行模型如下图所示:
部署模型
Daph目前的部署模型非常简单,
- daph-jvm,就是部署原生java程序
- daph-spark,就是部署spark应用程序
- daph-flink,就是部署flink应用程序
Daph:新一代流批一体数据集成与数据处理工具的更多相关文章
- OnZoom 基于Apache Hudi的流批一体架构实践
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创 ...
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
- Arctic 基于 Hive 的流批一体实践
背景 随着大数据业务的发展,基于 Hive 的数仓体系逐渐难以满足日益增长的业务需求,一方面已有很大体量的用户,但是在实时性,功能性上严重缺失:另一方面 Hudi,Iceberg 这类系统在事务性,快 ...
- 官宣 | Apache Flink 1.12.0 正式发布,流批一体真正统一运行!
官宣 | Apache Flink 1.12.0 正式发布,流批一体真正统一运行! 原创 Apache 博客 [Flink 中文社区](javascript:void(0) 翻译 | 付典 Revie ...
- 带你玩转Flink流批一体分布式实时处理引擎
摘要:Apache Flink是为分布式.高性能的流处理应用程序打造的开源流处理框架. 本文分享自华为云社区<[云驻共创]手把手教你玩转Flink流批一体分布式实时处理引擎>,作者: 萌兔 ...
- Apache Flink 1.12.0 正式发布,DataSet API 将被弃用,真正的流批一体
Apache Flink 1.12.0 正式发布 Apache Flink 社区很荣幸地宣布 Flink 1.12.0 版本正式发布!近 300 位贡献者参与了 Flink 1.12.0 的开发,提交 ...
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
- 数据集成工具—Sqoop
数据集成/采集/同步工具 @ 目录 数据集成/采集/同步工具 Sqoop简介 Sqoop安装 1.上传并解压 2.修改文件夹名字 3.修改配置文件 4.修改环境变量 5.添加MySQL连接驱动 6.测 ...
- Kafka ETL 之后,我们将如何定义新一代实时数据集成解决方案?
上一个十年,以 Hadoop 为代表的大数据技术发展如火如荼,各种数据平台.数据湖.数据中台等产品和解决方案层出不穷,这些方案最常用的场景包括统一汇聚企业数据,并对这些离线数据进行分析洞察,来达到辅助 ...
- DataPipeline CTO 陈肃:我们花了3年时间,重新定义数据集成
目前,中国企业在大数据流通.交换.利用等方面仍处于起步阶段,但是企业应用数据集成市场却是庞大的.根据 Forrester 数据看来,2017 年全球数据应用集成市场纯软件规模是 320 亿美元,如果包 ...
随机推荐
- Android 中的 perfboot工具
背景 开机首先加载bootloader,由bootloader启动kernel,然后运行init程序,有init启动Zygote,Zygote进程启动SystemServ进程,在SystemServe ...
- Freertos学习:06-任务通知
--- title: rtos-freertos-06-task-notify date: 2020-06-22 15:49:29 categories: tags: - ipc - freertos ...
- C# Linq俩个list<Datarow> 取差集,并自定义字段
可以自定义类 ,也可以从参考官网文档:Enumerable.Except 方法 (System.Linq) | Microsoft Learn List<DataRow> list1 = ...
- 【资料分享】RK3568开发板规格书(4x ARM Cortex-A55(64bit),主频1.8GHz)
1 开发板简介 创龙科技TL3568-EVM是一款基于瑞芯微RK3568J/RK3568B2处理器设计的四核ARM Cortex-A55国产工业评估板,每核主频高达1.8GHz/2.0GHz,由核心板 ...
- 量子算法抛转(以及Oracle函数初步)
接下来要接触量子算法了,我们会看到怎么利用量子并行机制和干涉原理.干涉在算法对结果进行测量求值时举足轻重. Deutsch-Jozsa 算法 DJ算法是量子算法的入门算法,就像编程界的"He ...
- react懒加载,减少首屏加载时间
最近在写一个react-ant-admin的集成框架用于快速搭载中后台项目.其中遇到很多问题,最重要的应该是访问速度了.我就想 react 可不可以和 vue 一样用路由懒加载来减少首页渲染所花费的时 ...
- axios和AJAX的区别
axios和ajax的区别 Axios和Ajax都是用于处理网络请求和与服务器进行通信的技术,但它们之间存在一些关键的区别:12 一.技术基础:Ajax(Asynchronous JavaScript ...
- 全网最适合入门的面向对象编程教程:11 类和对象的Python实现-子类调用父类方法-模拟串口传感器和主机
全网最适合入门的面向对象编程教程:11 类和对象的 Python 实现-子类调用父类方法-模拟串口传感器和主机 摘要: 本节课,我们主要讲解了在 Python 类的继承中子类如何进行初始化.调用父类的 ...
- Git常用命令汇总以及其它相关操作
--文件目录操作命令 1 mkdir * 创建一个空目录 *指目录名 2 pwd 显示当前目录的路径. 3 cat * 查看*文件内容 4 git rm * 删除**文件 --git初始化操作 1 g ...
- 记录一次在欧拉(openEuler22.03LTS-SP4)系统下安装(踩坑)Freeswitch1.10.11的全过程
目录 前言 安装环境 1. 下载Freeswitch 1.1 git clone 下载freeswitch库 1.2 官网下载 2. 开始安装前的工作 2.1 安装编译时需要的环境[先安装这个!] 2 ...